Rolf Kalbermatter
-
Posts
3,975 -
Joined
-
Last visited
-
Days Won
283
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-
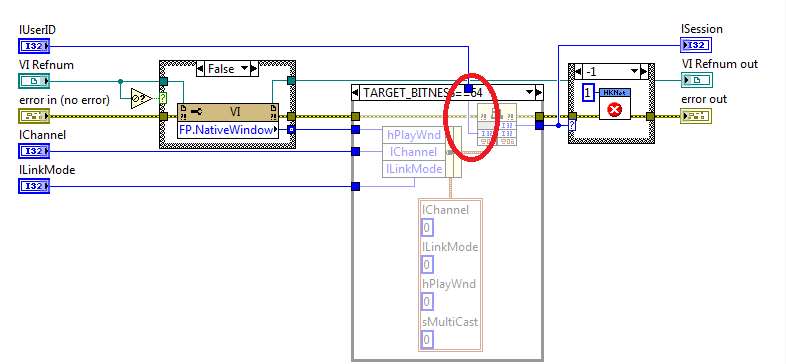
 Sigh! That ini file setting has absolutely nothing to do with your video streams. It unhides some VI server properties and methods that NI considers not for end user consumption, either because they are highly special, or not fully tested and only meant for internal use. Also it clutters your VI server property and method hierarchy in a way, that it gets very difficult to find anything. With that setting you should be able to see the FP.NativeWindow property in the property list (And your property node for that property should get a dirty (poopy) brown color to indicate that this is an non-public property that you should not expose to end users if you work at NI). Yes but that is not helpful information. But did you also check that the Start.vi has no error in?
Sigh! That ini file setting has absolutely nothing to do with your video streams. It unhides some VI server properties and methods that NI considers not for end user consumption, either because they are highly special, or not fully tested and only meant for internal use. Also it clutters your VI server property and method hierarchy in a way, that it gets very difficult to find anything. With that setting you should be able to see the FP.NativeWindow property in the property list (And your property node for that property should get a dirty (poopy) brown color to indicate that this is an non-public property that you should not expose to end users if you work at NI). Yes but that is not helpful information. But did you also check that the Start.vi has no error in? -
Well, this is clearly the problem. Somehow the FP.NativeWindow does not return a valid handle. There are three possible reasons. 1) NI disabled that node in later LabVIEW versions but I have no idea why they would have done that. It is an undocumented property of course, but that doesn't mean that it should suddenly stop to work. 2) The other is that the front panel of the Empty.vi is not open. But looking at the scrollbars inside the subpanel, it definitely looks like the panel is loaded. Also the Insert VI method for the subpanel did obviously not return an error either. So I'm a bit at a loss. The FP.NativeWindow property simply returns non-0 value on my system. 3) There is an error in on the Start vi. but you of course obscured that part of the VI, so we can't say if that is the reason. lUserID being 0 looks slightly suspicious but of course it could be a valid value since the documentation for the NET_DVR_Login_V30() function states that this is 0 or higher on success, and -1 indicates an error. And I take issue with your comment about the example code I provided being a mess. 😆
-
That shows nothing! What is the value of the FP.NativeWindow indicator? It should be something else than 0. You can change the value of the hPlayWnd control in that cluster to whatever you would like, it should be overwritten by the Bundle by Name node above with the handle value retrieved from the FP.NativeWindow property. You really should take some of the LabVIEW tutorials first. You try to play with guns and canons but haven't really understood how to operate the basics of using the matches.
-
It's documented in the SDK help file although I did not find it in the menu tree. But when you are looking at NET_DRV_RealPlay_v30() there is a reference to it at the end of that page. It's probably the original RealPlay function in V1.0 of the SDK, then they added V30 and later V40 of these functions and most likely each older version calls in fact the latest V40 with the unused values set to NULL or some default. "Not executed" in your probe window means that the code in that frame was not executed. It's as simple as that! And if it was not executed, you have probably not pressed the "start" button (after creating that probe). Then the probe [5] indicates that you apparently did execute the "start" frame and the output of the NotARefnum function is correctly False, since NOT being NotARefnum means that it was a valid refnum and therefore we can try to retrieve its native window handle to pass to the RealPlay function. That native window handle should then be something else than 0.
-
No! My example tries to replicate your posted Preview code. In there is only the exception callback which is used for error reporting to the user application and which I dutifully ignored to make the example more simple. Instead I did try to implement proper error handling by using the return value of each API call and requesting the last error information if that return value indicates an error. This should be more than enough for simple example code, most example code out there simply ignores any and all errors, which I find a very bad practise as when something doesn't work you have no idea where it starts to fail. The SDK documentation seems to indicate that this exception callback is optional so it should not affect the operation of the sample. That code does a number of things and some are completely wrong. 1) Forget about trying to write to that PS file in the callback. If you really wanted to have such a file you could simply just call NET_DVR_SaveRealData_V30() on the handle returned from NET_DVR_RealPlay() or NET_DVR_RealPlay_V30() and be done with it without having to bother about setting your own callback. 2) PostLVUserEvent() expects a valid native LabVIEW memory buffer to be passed to and that needs to match the event data type EXACTLY! For a LabVIEW array this is a LabVIEW array data handle. 3) The dwDataType parameter of the callback function is important in order to determine what type of data is in the buffer. You need that when trying to interpret the contents of the buffer, so you need to pass that to LabVIEW as well somehow. 4) Rather than storing the EventRefnum in a global to be referenced from the callback function I would instead pass that information through the user data pointer when installing the callback. LVUserEventRef *pUE; void SendEvent(LVUserEventRef *rwer) { pUE = rwer; } 5) This code stores the address where LabVIEW placed the refnum when passing it to the SendEvent() function. That address is almost 100% certainly used for something else by the time your callback function comes around to try to use it. You need to store the refnum instead, not the reference to it!. But this probably saved you from nasty crashes because PostLVUserEvent() does verify that the user event refnum is valid before doing anything. If it had tried to process the passed in data according to the user event data type your code for sure would have crashed immediately!!! This is a simple example of how a proper callback implementation would look like: #include "extcode.h" #include "hosttype.h" #include "HCNetSDK.h" #define LibAPI(retval) __declspec(dllexport) EXTERNC retval __cdecl #define Callback(retval) __declspec(dllexport) EXTERNC retval __stdcall // Define LabVIEW specific datatypes to pass data as event // This assumes that the LabVIEW event datatype is a cluster containing following elements in exactly that order!!! // cluster // int32 contains the current live view handle // uInt32 contains the dwDataType (NET_DVR_SYSHEAD, NET_DVR_STD_VIDEODATA, NET_DVR_STD_AUDIODATA, NET_DVR_PRIVATE_DATA, // or others as documented in the NET_DVR_SetStandardDataCallBack() function // array of uInt8 contains the actual byte stream data #include "lv_prolog.h" typedef struct { int32_t size; uint8_t elm[1]; } LVByteArrayRec, *LVByteArrayPtr, **LVByteArrayHdl; typedef struct { LONG realHandle; DWORD dataType; LVByteArrayHdl handle; } LVEventData; #include "lv_epilog.h" Callback(void) DataCallBack(LONG lRealHandle, DWORD dwDataType, BYTE *pBuffer, DWORD dwBufSize, DWORD dwUser) { LVEventData eventData = {0}; MgErr err = NumericArrayResize(uB, 1, (UHandle*)&(eventData.handle), dwBufSize); if (!err) { LVUserEventRef userEvent = (LVUserEventRef)dwUser; MoveBlock(pBuffer, (*(eventData.handle))->elm, dwBufSize); (*(eventData.handle))->size = (int32_t)dwBufSize; eventData.realHandle = lRealHandle; eventData.dataType = dwDataType; PostLVUserEvent(userEvent, &eventData); DSDisposeHandle(eventData.handle); } } typedef BOOL(__stdcall *Type_SetStandardDataCallBack)(LONG lRealHandle, fStdDataCallBack cbStdDataCallBack, DWORD dwUser); LibAPI(BOOL) InstallStandardCallback(LONG lRealHandle, LVUserEventRef *refnum) { HANDLE hDLL = LoadLibraryW(L"HCNetSDK.dll"); if (hDLL) { Type_SetStandardDataCallBack installFunc = (Type_SetStandardDataCallBack)GetProcAddress(hDLL, "NET_DVR_SetStandardDataCallBack"); if (installFunc) { return installFunc(lRealHandle, DataCallBack, (DWORD)(*refnum)); } FreeLibrary(hDLL); } return FALSE; } Compile this with your favorite C/C++ compiler. Do not pass .Net, C# or anything like that. They are a detour that can only complicate the matter even more for you but not solve any problems for you, even if you are afraid of C/C++ like the devil is afraid of holy water. The InstallStandardCallback() function is a convenience function. It tries to dynamically load the HCNetSDK.dll to avoid problems when this DLL containing the callback implementation is loaded before LabVIEW loaded the HCNetSDK.dll itself. Instead you could do a LoadLibrary("<yourDLLName>") call on this DLL in LabVIEW instead, then a GetProcAddress(hDLL, "DataCallBack") and then pass the according pointer as a pointer sized integer in LabVIEW to the Call Library Node that you created to call the NET_DVR_SetStandardDataCallBack() function. In that case you will also need to Typecast the LabVIEW user event refnum into an uInt32 integer and pass that as third parameter to the NET_DVR_SetStandardDataCallBack() function which has this parameter configured as uInt32 Numeric. You can not use pass Native Data Type here, since LabVIEW insists on passing a reference to the refnum in that case and then you start to get the same problem as is explained in point 5) above. And before you cry victory, consider another very important point: The SDK library will push data down your callback no matter if you process them in LabVIEW or not. If your user event loop serving that user event is not ready or can't keep up with that data stream, the user event queue in LabVIEW will get stuffed with event data messages with potentially huge byte array data in them and after some time it will simply post a threaded Out Of memory dialog that gives you exactly one option, to abort everything and lose whatever work you have not yet stored. So beware!!!! You are trying to bite off chunks from a cake, that is in many areas far beyond your knowledge. - Callback functions are complicated even for very seasoned C programmers. - Memory management is complicated, also for pretty experienced C programmers. - LabVIEW uses a very specific memory management that is required to allow it to optimize its operations. This memory management contract is not any more complicated than what a .Net library would use, but it is different. And no LabVIEW is not the problem here to not follow .Net. LabVIEW was invented in 1986 and its current memory management system was created somewhere around 1990, give or take a year. .Net was first introduced in 2003 so there is no way the LabVIEW developers could have anticipated what Microsoft will invent about 15 years later. LabVIEW shields you away from these difficulties almost completely but only if you stay within LabVIEW. Once you start interfacing to external code you have to consider and understand all these things fairly intimately, and in addition to that you have to understand the memory management requirements of the library you are interfacing to, which may or may not be well designed, but never designed to be compatible with LabVIEW, unless developed by a LabVIEW developer such as the IMAQ Vision library is. - And last but not least: Image handling is complicated, and video handling even more so, even if you stay with LabVIEW ready made libraries. If I had access to a HikVision camera, even one somewhere officially published on the internet as I do not want to hack anyones private door bell or security camera, I could do more testing, but I'm for obvious reasons not feeling inclined to pay 150 Euro or more, just to buy such a camera to do these tests.
-
My library does not use ANY callbacks. That was not the aim of it! Instead I tried to implement the Preview example code that you showed in a LabVIEW way. There is a callback in your Preview example code but it is NOT meant for receiving image data but to send exceptions to an app. Exceptions are when the library sees abnormal things such as errors happening and then it will send an according exception message through this callback. I completely omitted this callback as it does not seem that important to me. Instead I implemented proper error handling for all SDK functions that get called. That should be more than enough for now and that exception callback could be added once everything else is working perfectly. This SDK seems to have a number of different options. You can simply connect to the camera and retrieve an image occasionally and save it to disk. You can pass a windows handle in the lpClientInfo struct and the driver then is supposed to draw its image data into that window. This is what I tried to implement. And you can install a number of callback functions which are then continuously called by the driver to pass the image data frames to it. This callback function is the hard part and not just because you have to provide it. This will require you to write some C code to implement that function and then you have to find a way to pass this data back to LabVIEW, which the PostLVUserEvent() function MIGHT help with. But the data that this function receives is in a, let's say barely documented format. They talk a little about a proprietary format, and mention repeatedly that it can also contain simply network packets, which would be the H264 encoded data stream and you are back at square one. Also the SDK documentation is a little hard to read. Sometimes the text is hilarious, but sometimes it is simply confusing Extra note: are you by any chance using 64-bit LabVIEW? If so check your HKNetSDK:Start function. In there is a conditional compile structure and the 64-bit case is missing a very important wire.

-
Nope. That is something entirely different! I'm not making use of any message hooking library here that you might need to prime a some point. I'm simply using that empty VI to get a front panel whose window handle I can use to pass to the RealPlay function so it has a graphics port to draw its image into. That's it. I could have used the main VI instead but that would then cause the RealPlay function to attempt to draw into that and by doing so fight with LabVIEW trying to update the button areas as you press them. With this empty VI there is no LabVIEW trying to fight with the RealPlay task and you can insert it into a subpanel anywhere on a front panel and have other things besides it on that front panel However the logic is such that you have first to connect and only in start is the windows handle then passed to the SDK function, so your crash during the connect function has nothing to do with it since that VI is not yet active at that point.
-
The connect function failing is something that is a bit unexpected to be honest, I was more expecting problems with Start. But there could be many reasons. For instance it seems that this SDK requires the two HCCore and HCNetSDK shared libraries. I tried to make sure they are both loaded, but that may have been wrong and make things worse. Where did you have them in your LabVIEW example? It seems logical that the HCNetSDK also requires many of the other DLLs that the SDK comes with and it is totally undocumented how it will try to find them if at all. It may simply try to load them and not even check if that loading was successful and then trying to call functions in them, which of course would fail catastrophically. Without having a camera to test in real this is basically as much as I can do and then you are on your own.
-
Your still missing an important point here. The problem solved in that link is about calling an arbitrary function interface. That is "easily" solved with libffi, and the other solution mentioned in there is with the boost library, which does it with C++ templates and overrides. This is the same what the Call Library Node already provides in LabVIEW too and there are many other solutions out there. C# has P/Invoke for that for instance. If given the choice I would go with libffi before boost at anytime. It's a much more limited and self contained dependency than the whole boost library and also supports many more architectures, OSes and compilers than the boost library ever could. But what you want is the opposite, you want a function implementation that needs to provide an arbitrary interface that is not defined at compile time. That is basically turning the glove inside out, so to speak. Now I can't vouch about boost having that capability, it may have but I don't know. I know that it can be done with libffi since Python ctypes supports callback function declarations that call back into Python functions. P/Invoke also supports callback function declarations that then call C# functions, but there are very few examples out there how to do it (as are for Python ctypes too by the way). And I have not yet used libffi myself to implement callback functions but it is a fairly different class of problem than building a dynamic definition to call an arbitrary function, which libffi was mostly built for in the first place. The capability to also support building function pointer definitions that can be called from other code only came later to it, as you can also see from the comment from Basile Starynkevitch in your linked thread, who still claims that it can not be done with libffi. It can nowadays but the way it does it is by using quite some platform specific assembly code and I would hesitate to expect the more exotic platforms that libffi supports to have fully working code for that. There is also the very likely possibility that doing that will possibly fail on future CPU platforms outside of highly privileged contexts, such as inside the kernel, as they tend to crack down more and more on dynamic modification of executable memory segments or turning normal heap memory into executable memory segments. It's basically self modificating code and that can be used for very evil purposes. Any modern OS is almost obligated to prevent such things at all costs if it wants to have the necessary security certificates to be allowed to be used in various government and high security environments. libffi and other such libraries still can work for supporting callback function pointers, but that may simply end sometimes in the future.
-
No no. That is only one part of the problem and not the biggest one. The biggest problem is providing a callback function pointer that is matching exactly what the library expects. If you compile a C source code that implements that function then you can let the C compiler do all that work, but I was under the impression that you were looking for a solution that avoids the need to have the end user of the solution to compile a C code file that has to be also specifically adapted to the callback interface that library expects. You need to have a memory pointer that can be used as function pointer and that provides a stack frame that is exactly compatible to the expected interface from the library you want to pass this pointer to. On the other side you need an interface that can adapt to the data type that your PostLVUserEvent() needs. By fixing this PostLVUserEvent() interface to one or two datatypes, you solve one of the problems but you still need to provide an adaptable function pointer that can match the function interface of the library for that callback pointer. And that is were C itself simply won't help you. Why should it try to do that? The C compiler is much better at figuring this out so why spend time to develop a standard that lets you do C compiling at runtime? Yes such libraries exist but that is not something a C compiler would ever consider supporting itself. Therefore variadic and pack extension were never developed for such use cases. and simply couldn't help with that. If you don't want to have a C compiler involved in the end user solution, you need a way to express your callback function interface in some strict syntax and a translation layer that can comprehend this interface description and then prepare a call stack frame and function prolog and epilog to refer to that stack frame and at the end clear up the stack frame properly too. That's the really hard part of your proposed solution. And the user of such a solution also needs to understand the description syntax to have your library build the correct stack frame and function epilog and prolog for that function pointer. Then you could have it call into a common function that receives the stack frame pointer and stack parameter description and translate that into whatever you need. This translation from anything to something else that LVPostUserEvent() needs, can be as elaborate as you want. It's not really very difficult to do (if you really know C programming and twiddling with bits and bytes efficiently of course), just a lot of work as you need to be prepared to handle a lot of data types on either side of that translation. You can reduce that complexity by specifying that the LVPostUserEvent() interface always has to be one and only one specific datatype but it is still a lot of work. This second part of translating a known stack frame of datatypes is in complexity similar to those LabVEW libraries out there that parse a variant and then try to convert it back into LabVIEW native data themselves. It's complicated, a lot of work and I seldom saw a library that did a really decent job at that beyond serving some basic datatypes but it can be done with enough determination. The REAL problem is however to let the user build a callback pointer that matches the expected calling interface perfectly without having him to execute a C compiler. This is only really possible with a library like libffi or similar, if you do not intend to go and start playing assembler yourself. There is no compiler support for this (unless maybe if you would like to repurpose llvm into your own library) since it makes little sense to let the compiler externalize its entire logic into a user library. The gcc developers have no interest to let a user create another gcc like thing, not because they shy the competition but because the effort would be enormous and they have enough work to churn on to make the compiler work well and adapt to ever increasing standard proposals. libffi allows to build callback pointers, but it needs of course a stack frame description and other attributes such as calling convention to be able to do so. And it needs a user function pointer to which it can forward control after it has unraveled the stack and which after this function has done its work it will execute its epilog to do any stack cleanup that may be required. If LabVIEW had an officially documented way to call VIs from exernal code, I would have long ago tried to do something like that, as it would be very handy to have in Lua for LabVIEW. Currently Lua for LabVIEW does all kinds of very involved gymnastics that also involve a background LabVIEW VI deamon to which the shared library passes any requests from the Lua code to execute VIs (well the VIs are really registered in Lua as simply other Lua functions so the Lua script has no idea that it is effectively calling a LabVIEW VI), which in turn then calls that VI from its LabVIEW context and passes any return values back. Since this is such a roundabout way of doing things it has to limit the possibilities. A LabVIEW VI can execute Lua code which calls back into LabVIEW VIs but after that it gets to complicated to manage the necessary stack frames across calling environments and the Lua for LabVIEW shared library has specific measures to detect such calls and simply forbids them categorically for any further round turn. It also has a very extensive function to translate Lua data to LabVIEW data based on the LabVIEW typedescriptor and an according reverse function too that handles almost all the data types that LabVIEW and Lua know. But I can't directly invoke a VI from within the external code since there is no documented function to do so. Yes I know that there are functions that can do it but without a full documentation about them I will not embark on using them in any project that will leave my little office ever. Basically your desired solution has two distinct areas that need a solution: 1) Create a function pointer with correct prolog and epilog according to some user specified interface description that will then call the function in 2) 2) Create a function that receives the stack frame information and datatype description and then uses another user specification that defines which of those stack frame parameters should be used and how and in what kind of datatype they should be translated to pass to PostLVUserEvent() 1) can be solved by using libffi, but it is not going to be easy. libffi is anything but trivial to use but then it does solve a problem that is also anything but common in programming. 2) is simply a more or less complex function that can be developed and tested independently from the rest. It is NOT the big problem here, just quite a bit of work. If the callback allows to pass a user data pointer, you can repurpose that to pass all the information from about how the stack frame is build and how to translate from the stack frame to the PostLVUserEvent() from the setup function that prepares the callback pointer through this pointer. If it has not such a user data pointer , you have an additional problem of how to provide the necessary information to your translation function. It may be possible to prepare the callback pointer with some extra memory area to hold that pointer such as prepend it directly in front of the actual entry point and dereference it with a negative offset inside the callback but that is going to be highly hacky and has quite a big chance off breaking on some platforms, CPUs or OSes.
-
Only one “little” problem: You need to build the datatype to pass to the PostLVUserEvent() function absolut bit exactly according to the datatype used for the event and after the call cleanup any allocated memory. And define the stack frame your callback function pointer should have and translate between the two. A variadic function could help with some aspects of this but only in a very limited way. I haven't studied the pack expansion but don't see how that would be significantly better for this particular situation. These all do their magic mostly at compile time, but we need here something that can adapt at runtime to user specified parameters or you're back at square one as they have to compile their own C code again and using features like template classes that most C programmers makes their toes curl. 😆 You have the problem that your callback function pointer you need to provide must be able to dynamically adapt to both the calling interface (your library expecting a callback pointer has a very specific idea what parameters it wants to pass on the stack and you can't change that as it pleases you) and on the other hand it needs to be able to create a proper memory buffer to pass to PostLVUserEvent(). Variadic functions are helpful if you can define the parameter interface for it but absolutely terrible to try to make adapt to a given interface even if it does not change, which we can't expect here at all. It sort of can be hacked on some compilers to work since the va_arg is really just a memory pointer that you can actually walk but even then it is a nightmare as you have to deal with memory alignment rules that are often obscure at least. Other platforms completely hide the implementation details of va_arg and trying to hack into that is completely impossible. The better approach here would be to use libffi instead but that is going to be a very painful exercise to implement too. 😀 I don't believe that libffi already existed when NI developed the Call Library Node. If it had they certainly would have used it. It is THE library to use when a programming language tries to call other components from other languages. It is what makes Python ctypes work, and also what lets Lua access external shared libraries dynamically. Trying to do anything like this nowadays without using libffi is not just trying to reinvent the wheel, but also fire and water. 😃 I have used libffi in the past for other things. It works and can do almost anything about calling dynamic functions and providing dynamic stubs that can be used as callback pointers but that is just half of the problem you have here! And already very painful. Your computer crashes zillion times during development of this part and sometimes really hard where not just your test process crashes but your whole OS. And then you pass in the typedescriptor of the event data type and parse it and build the memory structure, pass in another descriptor of how to map the callback stackframe parameters to this memory structure, build the callback stub pointer according to this and then refer its invocation to your translation function that does the actual memory translations and then calls PostLVUserEvent() and afterwards deallocate everything that you just allocated. Bonus points for smart memory caching of that memory that won’t ever leak memory. And yes if your callback function doesn't allow for a pUser data pointer of some sorts that you can use to pass all the management information your callback needs to walk its stack, build the PostLVUserEvent() data and translate the stack parameters to it you are pretty much hosed, or have to devise a very complicated scheme of a global registry that your callback function can use to refer to the according translation information. I'm not even considering the option to use a global variable in such a shared library for this as it would limit the library to only ever implement one callback in the entire program. You could of course also resolve to build the whole callback function from scratch through creating assembly code on the fly and then do a little more gymnastics to mark that memory pointer as executable so your CPU won't bomb on you when you pass that pointer to the function as callback pointer. 😁 That's in a nutshell what it would take for such a solution. Each part of it is a challenge in itself. Making it all work together won't be trivial either. How many man month did you plan to spend on this? 😆 Why NI hasn't provided that already? Aside from the very significant work that this takes, such a configuration is a few magnitudes more complex to get just right, and considering how most LabVIEW users totally and completely struggle with simple function interface configuration already, you can for sure see where that would lead. It would have been a very unsupportable burden even back in the days when NI technical support still was top of the notch in the industry. Any manager who had been offered such a proposal would probably shoot the proposer. 💣
-
This is a somewhat rough attempt to try to resemble your Preview sample code in LabVIEW. No callback is used, instead I use a dummy VI that is inserted in a sub panel and then use its window handle to pass to the RealPlay function. This "might" work but without anything to test with it is a shot in the dark. HKNetSDK LabVIEW.zip
-
Yes time is money and I like to kill some time sometimes. 😜 More specifically I have learned a lot by investigating those questions before I could post an answer or example how to solve something. As we are speaking I was actually trying to find an open hikvision camera on the net to try to do a few things. Rather than having to hack a camera, or find a hacked private one, which seems rather easy for HikVision cameras if my googling didn't fail me, I would like to have an officially open camera somewhere instead. But that proofs not so easy to find. There are several sites that list open cameras of various types that can be simply accessed but none so far seems to be a HikVision camera. Most of what I see are Panasonic, Axis, Mobitix and a few others. 😆
-
You don't. C# does not understand C syntax and therefore the only thing that trying to add the extcode.h header file will achieve is to create compile errors. If you want to access unmanaged APIs in C# you have to do P/Invoke and/or Marshalling. And that PostLVUserEvent function is an unmanaged API in terms of .Net. But that's not all! You need to tell the C# compiler where it can find that API by specifying the DLL it is in. However that depends on if your code is called in the LabVIEW Development system (LabVIEW EXE is exporting that function) or if you try to call your code later in a build application (lvrt.dll or possibly another DLL is exporting that function). So your C# code has to start to find out if it is called from a LabVIEW VI in the IDE or from a build LabVIEW executable!!! And that is still not all. Basically it is not feasible to try to go this route if your external wrapper DLL is written in C#, just as simple as that. Since your actual API is also not a .Net API you are starting to build a tower by mounting a stick on a beam that is balancing on a pencil and everything is kept up by strings going everywhere. Take a step back for a moment. Basically your API is a standard DLL which is unmanaged, and you could write a C(++) DLL that directly interfaces this and then use PostLVUserEvent(). Or if that proofs to intimidating to you you definitely should forget about PostLVUserEvent(). Instead write a real .Net assembly that exports a proper class which has a .Net event. Then interface to this .Net assembly using the LabVIEW .Net nodes. Now you can connect to this .Net event with LabVIEW functions by registering a callback VI that is called whenever that .Net event is triggered in your assembly. That's the only feasible approach if you want to stay with a .Net assembly.
-
And someone downloading Moon Knight in addition gives them like what? Eternal gratefulness? I know what torrents are and have played around with it's predecessor eMule a little. eMule still exists as I found out recently but its servers are mostly taken over by people who want to push things down your throat that you would never ever want to touch with a ten foot pole. I'm not sure why torrents would be that much better to be honest. 😀
-
Almost certainly not a PostScript file. That PS probably stands for something the developer ate that day or maybe it could be his initials or the initials of his girl friend. We likely will never know. 😀 Are you able to even receive the JPEG file yet? Remember what Shaun said. Try to walk before you run. And I would say getting the JPEG download work yourself without someone doing all the work for you is already advanced walking training. To get the Callback function to work is Marathon style running on Olympic levels. 😆
-
They and others have repeatedly provided installer downloads that are supposedly cracked to circumvent the serial number license check. If that is true or if they are actually modified with other less friendly hacks that may install a backdoor on your system instead, or maybe a nice cryptolocker ransomware, is always the big question. 😝 As long as they just mirror the standard offline installer image, not even NI would likely have any problems with it, but why would someone sacrifice server space and internetbandwidth on their system without wanting to get something back in return? 😀
-
I"m not even sure they still have USB sticks. CD's and DVD's definitely are not available anymore (with software bundle downloads with the size of 40 to 50 GB that would be also unpractical) 😀 Most likely the USB sticks sank on the way from China to the European warehouse, so there is something like a 50 weeks delivery time for them. And who said that WITH MEDIA means a physical tangible item. A download could just as much be considered media and since you have a valid SSP you should be certainly able to download it. The challenge might be to assign that serial number to your user account, especially if you are one of those who explicitly likes to never register your products with the manufacturer. Unlike most other products, where such a registration is just to collect email addresses for marketing purposes, the LabVIEW serial number registration actually makes a huge difference. 😀
-
No! The function mentioned will simply return a single JPEG image frame (probably only if an acquisition is running). Still it is useful to get this working first to actually get the interface at least exercised. Before you can do a Snap with this function you can do whatever acrobatics you would like but it is useless. Start with easier things and get them working, then move on to play with the dangerous tools. 😀
-
1) You don't, since it is not code. It is the function prototype (actually the function pointer declaration) of a function that YOU have to implement. And then you pass the name of that function as parameter to the other function that wants this callback function. Whenever that other function thinks it wants to tell YOU something it calls that callback function with the documented parameters and YOUR callback function implementation does then something with that data. But your function is called in the context of the other function at SOME time after you called the original function that you passed your callback function too. Are you still with me? If not, don't worry, most people have big trouble with that. If yes then you might have a chance to actually get this eventually solved. But don't expect to have this working tomorrow or next week. You have a steep learning curve in front of you. 2) The iCube Camera in is simply a LabVIEW class that handles the whole camera management in LabVIEW, and in some of its internal methods accesses the DLL interface, and creates the event message queue, and starts up an event handler, and ..., and ..., and .... 3) The RegEventCallback function is a LabVIEW node that you can use to register events on CERTAIN LabVIEW refnums. One of them are .Net refnums, IF the object class behind that refnum implements events. .Net events are the .Net way of doing callbacks. It is similarly complex to understand and implement but avoids a few of the more nasty problems of C callback pointers such as datatype safety. But to use that node you will need a .Net assembly that exposes some object class which supports some events of some sort. Since .Net uses typesafe interface descriptions, LabVIEW can determine the parameters that such an event has and create automatically a callback VI and connect it behind the scenes with the .Net event. It works fairly good but has a few drawbacks that can be painful during development. Once the callback VI has been registered and activated, it is locked inside LabVIEW and there are only two ways to get this VI back into an editable state. Restart LabVIEW or after the object classes on which the event occured have been properly closed (Close Reference node) you need to explicitly call the .Net Garbage Collector in LabVIEW to make .Net release the proxy caller that LabVIEW created and instantiated to translate between the .Net event and the LabVIEW callback VI. If you have a .Net assembly that exposes events for some of its object classes, it is usually quite a bit easier to interface from LabVIEW than trying to do callback pointers in a C(++) DLL/shared library. Writing an assembly in C# that implements events is also not really rocket science but definitely neither a beginners exercise. 4) If you interface to C(++) in LabVIEW there is no safety net, sturdy floor, soft cushions and a few trampolines to safe your ass from being hurt when something doesn't 100% match between what you told LabVIEW that the external code expects and what it really does expect. It's in the best case a hard crash with error message, the next best case is a hard crash with no error message and after that you are in the lands of maybes, good luck and sh*t storm. A memory corruption does not have to immediately crash your process, it could also simply overwrite your multimillion dollar experiment results without you noticing until a few hours later when the whole factory starts to blow up because it is operating on wrong data. So be warned, thread safely and make sure to have your C(++) solution tested by someone who really understands what the potential problems are, or don't use your code ever in a production environment. This is the biting in your ass that dadreamer talked about, and it is not really LabVIEW that did it, but you yourself! 5) Which video screen output are you talking about? Once you managed to get the camera data into your LabVIEW program without blowing up your lab? Well you could buy IMAQ Vision or start another project where you will need to learn a lot of new things to do it yourself. 🙂
-
There is a reason why so many pleas for support of camera access are out there and no single properly working solution except paid toolkits: Actually it's not one but a plethora of reason. - cameras use lots of different interfaces - they often claim to follow a certain standard but usually don't do so to the letter - there are about several dozen different communication standards that a camera manufacture can (try) to follow - it involves moving lots of data AFAP which requires good memory management from the end user application down to the camera interface through many layers of software often from different manufacturers - it costs time, time and even more time to develop - it is fairly complex and not many people have the required knowledge to do it beyond a "Look mom it keeps running without needing to hold its hands (most of the time)" Callback function are not really magic, but there is a reason they are only mentioned in the advanced section of all programming textbooks I know (if they are mentioned at all). Most people tend to have a real hard time to wrap their mind around them. It starts for many already with simple memory pointers but a call back function is simply a memory pointer on steroids. 😀 And just when you think you mastered them you will discover that you haven't really started, as concurrency and multithreading try to not only throw a wrench in your wheels but an entire steam roller.
-
It's a good thing. Unfortunately NI seemed to have stopped in various areas to fully implement features at the moment they got barely usable, not implementing certain fundamental things for some reason and concentrating their efforts on others that are highly specialistic and obscure. And documentation is pretty minimal to say the least.
-
Standard error output can't show anything either when you make the wait for completion false. So that would not indicate anything. With wait for completion set to false the process is launched and forgotten by LabVIEW. If it runs a millisecond or infinitely doesn't matter for LabVIEW. It has long continued and that process may still be running, or may have died or normally terminated. So the only thing that remains is: Does the LED toggle anyhow and does it show some progress in the command window? If so then the only difference is that with wait for completion set to true LabVIEW will wait for the process to terminate and then copy the standard output and standard error information into the string indicators of that function. With wait for completion set to false LabVIEW will NOT connect the standard input, standard output and standard errors in any way and whatever your program writes to those either is shown on the command window or lost forever in the /dev/null world of computers.
-
That's almost like asking if you can install a GM engine into a Toyota. 😀 Answer is yes you can if you are able to rework the chassis, and make just about a few thousand other modifications. But don't expect support from either of the two if you ran into a snag. More seriously, you may also run into license issues.
-
LabVIEW 2021 Mac M1 ARM Parallels -- Virtual Machine Keeps Bricking
Rolf Kalbermatter replied to Jacob7's topic in GCentral
Don't try to install drivers! They typically contain kernel components and Rosetta 2 is not able to emulate x64 code in kernel space. This was a conscious decision by Apple, as trying to support that would likely have turned Rosetta 2 development into a never ending crashing story.