Rolf Kalbermatter
-
Posts
3,973 -
Joined
-
Last visited
-
Days Won
282
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-
 Yes it would work, if you make sure to call the DSDisposeHandle function on EVERY event, without inhibiting its call through some intermediate error cluster handling AND without having other programming errors AND without trying to single step through the code AND, AND, AND. I prefer to make it as stable as possible rather than as unmaintainable as possible. 😆 Your approach is fine if you get it fully debugged and then slap a password on the VI to prevent the uninhibited from peaking into your VI and mess with its inner workings. Giving the average LabVIEW user even the possibility to tinker with any pointers, is a sure way to make them create a mess. You mean to say it is their fault if they do that? Sure it is, but many do not have the knowledge to understand that it is. 😀 And if you want to make it 32-bit and 64-bit compatible you have to choose between two uglies that way: 1) define the handle explicitly as U64 on the C side and typecast it to that to pass it to LabVIEW. And treat it as U64 on the LabVIEW side just as any pointer sized integer. 2) create conditional compile code with the event cluster definition. This would be über-ugly.
Yes it would work, if you make sure to call the DSDisposeHandle function on EVERY event, without inhibiting its call through some intermediate error cluster handling AND without having other programming errors AND without trying to single step through the code AND, AND, AND. I prefer to make it as stable as possible rather than as unmaintainable as possible. 😆 Your approach is fine if you get it fully debugged and then slap a password on the VI to prevent the uninhibited from peaking into your VI and mess with its inner workings. Giving the average LabVIEW user even the possibility to tinker with any pointers, is a sure way to make them create a mess. You mean to say it is their fault if they do that? Sure it is, but many do not have the knowledge to understand that it is. 😀 And if you want to make it 32-bit and 64-bit compatible you have to choose between two uglies that way: 1) define the handle explicitly as U64 on the C side and typecast it to that to pass it to LabVIEW. And treat it as U64 on the LabVIEW side just as any pointer sized integer. 2) create conditional compile code with the event cluster definition. This would be über-ugly. -
First the DataCallback() wasn't "created" but "exported. It needs to be present in the DLL so you can pass its address to the according SDK function. But it does not need to be exported from the DLL for that. As long as the Calling convention is configured correctly it will work without exporting it. And the thing that causes the linker to add that function to the DLL export table is your extern "C" __declspec(dllexport) in front of the DataCallback declaration. It is unnecessary and only helps to confuse you. Simply defining is like this should be enough: void CALLBACK DataCallBack(LONG lRealHandle, DWORD dwDataType, BYTE * pBuffer, DWORD dwBufSize, DWORD dwUser) { ... } Your nose really is barely above the water level. Take a break, and a deep breath! You simply need to create a VI that calls the SetCbState() function. And ohhhhhhhhhhhh my God!!!!!! You defined the event data cluster totally wrong. That "handle" is not an integer value. It is a full and complete LabVIEW byte array!! It shouldn't cause your crash .. at least not immediately! But since you don't tell LabVIEW that it is a handle it can't manage its memory. Meaning with every message that is sent to your event loop, you simply leak that handle each time. That will drive your application into out of memory in no time, just as the incorrect handling of the cbState boolean did. You not only were leaking handles when the cbState boolean was false but with EVERY single callback!!!!!!!!
-
But you do realize that once you got the callback reliably posting binary data to your event loop, all the problems up to now are pretty much peanuts in comparison? That bytestream is compressed, with a format that depends on the parameter dwDataType and some information in the data stream, likely not in every package but at specific moments that you have to detect based on the context of earlier packages (which you hopefully haven't suppressed with your inhibit boolean). And that compression is H264 or maybe MPEG4 or similar for the video data and G722 or such for the Audio packages, but the documentation also talks about other possible formats, most likely depending on the camera model and/or its settings. Going to decode H264 or MPEG4 in LabVIEW itself is going to be a no-no. It may technically be possible but I would not consider being able to write a video decompressor in C and even less in LabVIEW. the math and programming needed for that is simply to complicated. Which leaves only one option: finding an external DLL and interfacing to it and believe me, interfacing to a video decompressor is no easy feat. Your exercises so far would seem almost trivial in comparison, and you are already swimming with your nose barely at the surface.
-
I would do it like this: First it is important to move the NumericArrayResize() call into the same condition level as the DSDisposeHandle() call. Your code currently leaks a handle every time the callback is called while the cbState boolean is on LVBooleanFalse, which is VERY bad. The fact that it does unnecessary work is not perfect bad a very minor problem in comparison. // cbstate does a state reassessment.True or False extern "C" __declspec(dllexport) void __stdcall DataCallBack(LONG lRealHandle, DWORD dwDataType, BYTE * pBuffer, DWORD dwBufSize, DWORD dwUser) { if (cbState == LVBooleanTrue) { LVEventData eventData = { 0 }; MgErr err = NumericArrayResize(uB, 1, (UHandle*)&(eventData.handle), dwBufSize); if (!err)// send callback data if there is no error and the cbstatus is true. { LVEventData eventData = { 0 }; MgErr err = NumericArrayResize(uB, 1, (UHandle*)&(eventData.handle), dwBufSize); LVUserEventRef userEvent = (LVUserEventRef)dwUser; MoveBlock(pBuffer, (*(eventData.handle))->elm, dwBufSize); (*(eventData.handle))->size = (int32_t)dwBufSize; eventData.realHandle = lRealHandle; eventData.dataType = dwDataType; PostLVUserEvent(userEvent, &eventData); DSDisposeHandle(eventData.handle); } } } //If the above if condition does not occur, the LVUserEventRef here does not take a value. typedef BOOL(__stdcall* Type_SetStandardDataCallBack)(LONG lRealHandle, void(CALLBACK* fStdDataCallBack) (LONG lRealHandle, DWORD dwDataType, BYTE* pBuffer, DWORD dwBufSize, DWORD dwUser), DWORD dwUser); extern "C" __declspec(dllexport) BOOL __cdecl InstallStandardCallback(LONG lRealHandle, LVUserEventRef * refnum) { HMODULE hDLL = LoadLibraryW(L"HCNetSDK.dll"); if (hDLL) { Type_SetStandardDataCallBack installFunc = (Type_SetStandardDataCallBack)GetProcAddress(hDLL, "NET_DVR_SetStandardDataCallBack"); if (installFunc) { if (refnum && *refnum) return installFunc(lRealHandle, DataCallBack, (DWORD)(*refnum)); else return installFunc(lRealHandle, NULL, 0)); } FreeLibrary(hDLL); } return FALSE; } Then write an Uninstall Callback.vi that is essentially the same as the Install Callback.vi but don't pass in any user event refnum. Simply pass a NotARefnum to the second parameter of the Call Library Node.
-
The eventData declaration is harmless. This is a stack variable space and gets allocated anyhow on function entry by reserving the according stack space. In the worst case it adds a single MOV rrx, sp+x call before the condition calculation, but it might do that even if you put it inside the if statement because of C compiler optimization to prevent CPU pipeline stalling. The call to NumericArrayResize() is a different story. This can be a potentially relatively expensive call, so should indeed only be done when necessary.
-
That pch.h file is for "PreCompiled Header" its an option where the compiler creates a precompiled header file for all the different headers in your project. Can be useful when you have a project that has "zillions" of source files that include "quadrillions" of header files to reduce the compilation time as the compiler doesn't have to process each header file over and over again. For a project of this size it is useless and only causes extra trouble. There should be a setting in the compiler settings called "Use Precompiled Header file" or something like that. Disable that! Then you can also remove that include.
-
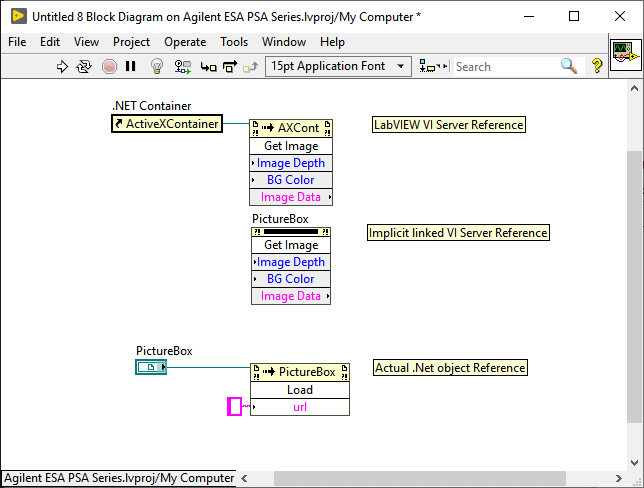
I do. PrintWindow sends a window message to the window function to redraw itself (WM_DRAW). The PictureBox has installed that windows function when creating the window for its drawing canvas and that function dutifully does redraw its empty PictureStream into the provided graphics context. It does not know about the bitmap that the SDK driver sneakily blitted into its window behind its back! And therefore that bitmap does not show in the PrintWindow result.
-
It wasn't me who brought that back into the discussion. I was under the strong impression that we were already working for some time on the PictureBox solution as drawing canvas area. alvise suddenly brought this Empty.vi subpanel solution back into the picture.
-
That callback will almost certainly never get triggered! The SDK is not aware about that it is drawing into a .Net PictureBox. It only sees the window handle that is used by the PictureBox for its drawing canvas. And that works on a level way below .Net in the Windows window manager inside the kernel. If you would try to do anything with that PictureBox such as drawing lines or anything into, it you would get very nasty flickering as the SDK function trying to bitblit into the windows device context (HDC) will fight with the PictureBox functions who tries to do GDI drawing into the same HDC. We are abusing here the PictureBox simply as a container to provide a window handle. In this way we can let Windows window clipping handle all the issues about making sure that the SDK can't draw beyond that area provided by the PictureBox control. But for the rest we are not really using any functionality from the PictureBox .Net control. Respectively when we tried to retrieve the image, that failed since the PictureBox control is not aware about what was drawn into its window. And the same applies for the LabVIEW Get Image control function.
-
I would not recommend you to do it. But It is your time and frustration.
-
That's bad luck.
-
There definitely is data in the "Image Data" Cluster. Of course you forgot again to show the part of the screen where it would display the "new picture" to proof your claim that there is nothing shown. So we can not tell what is captured but something for sure is captured. You may also want to remove the Draw Unflattened function. It adds nothing anymore.
-
Leaving NI (for real this time)... for SpaceX
Rolf Kalbermatter replied to Aristos Queue's topic in LAVA Lounge
Fun! Good luck in your new endeavor. But the LabVIEW development team loses a very valuable and important member for sure. -
Of course you do as you use the VI refnum. Right click on your PictureBox control in the LabVIEW front panel and select Create->Reference. Connect that reference to the Method node instead of the VI reference. And of course you need to use the VI with the PictureBox that you had earlier, not the one trying to use the subPanel.
-
That code does not exist yet (in a public location)! So yes it is impossible. More precise: That code does not exist yet in a public location! It for sure has been developed numerous times for various in house projects, although almost 100% certainly not for the HikVision SDK. But in-house means that it is not feasible or even possible to publish it because of copyright, license and other issues. And even if those issues would not exist, nobody is going to search his project archives for the code to post here.
-
Doesn't matter. The SDK draws asynchonously into the Picture Box window. No matter which window handle you use, the moment you cause the screen capture from the window handle to occur is totally and completely asynchronous to the drawing of the SDK. And there is a high chance that the screen capture operations BitBlit() or PrintWindow() will capture parts of two different images drawn (blitted into the window) by the SDK function. So yes after all these troubles we may have to consider that what we did so far is perfectly fine for displaying the camera image on a LabVIEW panel. You can also cause the SDK to write the image data into a file on disk. But if you want to get at the image data in realtime into LabVIEW memory to process as an image, you won't get around the callback and that is where I stop. This would be a serious development effort even if I did it all here on my own system for a real project. With the forum back and forth and the fact that it is advanced callback programming that even seasoned C programmers usually struggle with, it's simply unfeasible to continue here. And I already see the next request: You did it with IMAQ Vision images but that comes with a license cost. Please I want to do it with OpenCV to save some dollars! And a multiday development job turns into a multi week development job with one single sentence!
-
The LabVIEW Get Image method may look slightly better since LabVIEW has minimal control over when someone may draw into that control. But it most likely won't avoid the problem completely.
-
Yes, this choppyness is of course expected and there is nothing you can do about it with this method. The SDK function draws into that window handle when it pleases and how it pleases. Your Get Image function copies the screen pixel into its own buffer when it pleases and how it pleases. No synchronization whatsoever. And there is no trivial synchronization possible. If you were old enough you would know a similar effect from television when a TV screen was captured by a TV camera. Since the two never ever work exactly with the same picture frequency you get stripes and flickers across the screen as the camera picture takes part of one image and then part of the next image in each image shot and the dysonchron frequency causes the stripes and flickers to wander up or down on the screen.
-
The problem is that the .Net PictureBox does not contain an image. It is just used to get a window handle to pass to the SDK library which then draws the image data directly onto the window surface. And the PictureBox knows nothing about that and therefore won't return any pixel images for the non existing image it has. The LabVIEW control method Get Image on the other hand should simply take a screen shot of the control screen area. It's the only way to get an image for LabVIEW as it does not know what object control is displayed in it and most classes do not have a GetBitmap method anyways. For native controls it may use a control method, which redraws the control into a bitmap, but for the .Net and Active X Control that certainly won't work and the only way to get an image is by doing a screen capture of the area.
-
That's definitely the case. He only passes the window handle of the Picture box into the HikVision camera. And the SDK then directly bitblits into that window surface. It does not know about PictureBox or anything, only the window handle. The PictureBox really just is placeholder to provide a handle. It would likely better work if you actually called the LabVIEW VI Server Method "Get Image" on the LabVIEW .Net Container Refnum rather than the PictureBox .Net refnum. Yes it is not exactly intuitive but fairly consistent with other LabVIEW controls. The terminal is the data (for a .Net control its contained object class refnum) but the VI server interface has to be retrieved either from a Reference node or the Property/Method needs to be implicitly linked to the control

-
Well, a handle is in terms of the C signature simply a pointer sized integer. typedef void * HANDLE; That it is "usually" a 24-bit index into a Windows object table specific to your handle type, doesn't mean that every API that "exports" a HANDLE data type also uses this. For one it only applies to objects that the Windows kernel manages. Second, the functions to create such handles for your own handle type are located in ntoskrnl and as such considered non-public Windows APIs. While you can call them directly and in some cases some of those APIs are documented at least in the Windows DDK, using them is at your own risk and potentially a compatibility liability as Microsoft does specifically not guarantee these APIs to not change in their signature or behaviour, nor simply disappear at any point in a new Windows version. Also that 24 bit index is only part of the truth, the rest of the standard 32-bit value is used to encode the type of handle and allows to verify that the handle is actually for the object table the caller claims it to be. As such it is almost exactly like a LabVIEW refnum which implements pretty much the same semantics. Only that LabVIEW refnums are also guaranteed to be always 32-bit entities as that is how NI publically defined them and they did not change that definition in the published API code when adding support for 64-bit LabVIEW in 2009. Microsoft on the other hand declared a HANDLE to be a pointer sized entity since many moons ago. Only very early Windows SDKs did define the HANDLE to be an alias for a DWORD. At some point they consistently changed that to a LPVOID, respectively a pointer to an anonymous struct (and in some scenarios even a pointer to a struct containing an int value). So while in most cases a HANDLE indeed is simply a 32-bit integer under the hood, that is always an implementation specific detail that you rely on for that specific type of handle. It may not hold true for every handle, especially APIs that to not refer to kernel objects itself but simply use the HANDLE data type as an opaque parameter to pass their own object identifier between API calls, which in many cases can be a pointer to a struct. And since a HANDLE is defined to be an anonymous identifier whose implementation is implementation specific, that is all very legal. And in programming it is always a bad idea to rely upon implementation specific details behind abstract interfaces. So if you want to treat your HANDLEs as 32-bit value because it USUALLY works, that is up to you. I prefer to work according to the published definition and if that wastes 32-bit of memory on a 64-bit platform because the higher significant 32-bit are never used, so be it. It will guarantee that the software will keep working when the underlying API one day decides that the private and hence undocumented implementation detail of what the handle really means will change. Will that cause a compatibility nightmare for all the software which never bothered to follow the actual spec rather than private implementation specific details? You bet. Is it likely to happen? Maybe not. And for any API using the HANDLE for anything else than Windows kernel objects, it really and absolutely can matter already today. And you may not always know if an API uses this data type for a real kernel object or something entirely different for its internal implementation.
-
Are you sure the handle can not get negative? In fact I'm pretty sure the handle could get 64 bit on LabVIEW 64-bit. It usually shouldn't as Microsoft tried to keep the handle values below the 32 bit boundary by somehow not directly making it a pointer, but I have seen cases where Windows handles did use the upper 32-bit for something and failed if you treated the handle only as 32-bit, effectively clearing out the top most 32 bits. I think the safest here would be to use ToUInt64(). It shouldn't hurt even if Windows never uses more than 32-bit but it may prevent potential problems in the future.
-
Interesting Announcements from NI Connect?
Rolf Kalbermatter replied to Reds's topic in LabVIEW General
Those properties and methods are part of the object manager interface. This is despite its name not the same as LabVIEW classes. It was introduced with NI VISA back in LabVIEW 4 or 5 and later improved for other software interfaces. The according files have the ending .rc and .rch and are located in the resources/objmgr directory in LabVIEW. They define the menu hierarchy in the property and method nodes and the connection between them and the actual shared library (DLL) implementation for that interface. The same object manager infrastructure is in fact also used for Active X, .Net and in some way the LabVIEW VI Server interface but these are not defined by external .rc files but directly in the c++ source code of LabVIEW. If you want to change what methods and properties are available for a certain class you need to change these files too, but of course the properties and methods that are defined in those files need to connect to correct selectors in the according shared library, so adding new entries in the .rc file alone yourself makes little sense. You also need to have the shared library version that implements them. On the other hand only changing the shared library doesn't add new properties and methods to the object manager resources. You also need to copy the according .rc and .rch files. But beware, those files can implement different versions of object manager resource formats and there is a chance that if you copy one meant for a much newer LabVIEW version, it will make an older LabVIEW version not recognize the file at all as the version is to new for it to know about it. And the actual interface implementation for this interface is in most cases a separate shared library on top of the more generic driver library. The driver library implements the real business logic and the low level C interface that can be also used from other programming software. The higher level library is very much LabVIEW specific as it needs to directly provide LabVIEW native datatypes such as string handles to plug easily into the object manager interface. For the more esoteric features such as events it even must provide very specific functionality that connects the event to the LabVIEW user event mechanisme. -
Interesting Announcements from NI Connect?
Rolf Kalbermatter replied to Reds's topic in LabVIEW General
I know it is. But I'm not involved in that project. Still find that webpage on the NI site much less than overwhelming! 😀 -
Could this be the Linux kernel wanting to refuse to load non-GNU blessed kernel drivers to be loaded. This was a pretty controversial topic some time ago. In an effort to force graphic card manufacturers to release open source versions of their driver, the kernel folks decided that you only could load GNU marked drivers, but in order to mark your driver with the necessary symbols you had to somehow link it to some library that made your driver fall under the GNU GPL license by design. Neither at least one of the graphic chip manufacturers nor NI were happy nor willing to do that!