Rolf Kalbermatter
-
Posts
3,975 -
Joined
-
Last visited
-
Days Won
282
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-

Pyhton or C to do For Daq and DSP?
Rolf Kalbermatter replied to Mahbod Morshedi's topic in Calling External Code
Despite having created LabPython about two decades ago, I always prefered to go with C. LabPython (and Python itself too) are also written in pure C. One reason I think is that Python is also a high level programming language like LabVIEW. What I could do in Python I could also always do in LabVIEW, but certain things are simply not really possible (or at least not with reasonable effort) in both of them and require a lower level language. But C(++) is quite a different thing to work in for sure. It gives great power and control but that comes with great responsibilities too. While you have to really try hard to crash a LabVIEW or Python program, it's a matter of seconds to do that in C(++). This means programming in C is a little different than doing the same in LabVIEW or Python. If something goes wrong in your C program or library it is often not just an error code that is returned, but your test program simply dies without any warnings, questions or dialogs if you would maybe like to save your intermediate data results. In LabVIEW you get typically an error cluster out, look at it, determine where the problem is, fix it and start your program again, without any need to completely start LabVIEW itself again or sometimes even restart the whole computer just to be sure. Once you are used to that, it is not really much different anymore, but it is certainly something to be aware of before making the decision. -
We have noticed in the last few years that the outstanding support from NI technical support quickly detorated to the level of standard untrained technical support that call centers located in some low income countries often provide. However I have to say that this trend seems to have been reversed in recent times. I had three technical support questions in the course of about one year now, non was standard and included things that were simply not possible because the feature was officially not present. The support people were very helpful in trying to find workarounds and in two cases provided even solutions that were based on information that was gained directly from the product owners and developers to access the feature through direct behind the scene configuration files and APIs. In both cases with the strong warning that this was not the officially sanctioned way to do things and that there was a real chance that it may break in future versions, but that it was at the moment the best that could be done.
-
NI-DAQmx Error -50103: The Specified Resource is Reserved
Rolf Kalbermatter replied to Jim Kring's topic in Hardware
It's still the same. You can not have multiple tasks accessing the same DAQ card for Analog input. You need to combine the channels into one task and one scan rate and then pick out the data as needed and distribute it to the different subsystems as needed. -
Most likely that compile worker is a 32-bit application and you only have 64-bit libgdiplus installed? Or another possibility, the /usr/local/natinst/mono/lib64 directory was not properly added to the /etc/ld.so.conf file and/or ldconfig was not executed afterwards
-
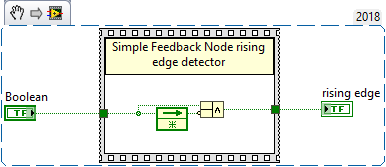
Couldn't view your VI as I don't have LabVIEW 2020 installed on this machine but you want to basically detect that the boolean you use to find out if you want to write to the file has switched from false to true. An edge detector is very simple to do with a feedback register like this. Change the boolean inputs inversion to detect the falling edge. When the rising edge boolean is true, write your header and then the data, otherwise only write the data.

-
It's not entirely without its own pitfalls. Different network controller chips support different support for jumbo frame, some older do not support it at all, and all your routers, hubs and whatever in between needs to support it too. It's definitely helpful for full HD and higher resolution cameras and/or when you need to use multiple GigE cameras in parallel, but it makes your setup more sensible to quickly switching to a different ethernet port or replacing intermediate network infrastructure suddenly causing issues.
-
As mentioned, the cvirte.dll is not version specific. The CVI developers apparently tried to avoid that version incompatibility shenigan. So a newer CVI runtime engine install should work. There is a small chance of a version compatibility bug in a much never version, but as long as it works, it works. 😀
-
Dynamically generate installer UpgradeCode
Rolf Kalbermatter replied to Benjamin R's topic in LabVIEW General
The private method is also available in earlier LabVIEW versions, although not as a VI in vi.lib. I checked for it in 2018 and 8.6 but suspect that it may have been present as early as 8.2 0r even 8.0. -
Well I started in April 1992, went to the US for 4 months in May and heard there that there was this big news about LabVIEW not being for Macintosh only anymore, but telling anyone outside of the company would be equivalent to asking to be terminated 😀. They were VERY secretive about this and nobody outside the company was supposed to know until the big release event. In fall of 1992 LabVIEW for Windows 3.1 was announced and the first version shipped was 2.5. It was quickly followed by 2.5.1 which ironed out some nasty bugs and then there was a 2.5.2 release later on that made everything more stable, before they went to go to release the 3.0 version which was the first one to be really multiplatform. 2.2.1 was the last Mac version before that and 2.5.2 was the Windows version. They could not read each others files. This was Windows 3.1 which was 16-bit and still just a graphical shell on top of DOS. LabVIEW used the DOS/4GW DOS Extender from Tenberry Software, that was part of the Watcom C development environment used to compile LabVIEW for Windows to provide a flat 32-bit memory model to the LabVIEW process, without nasty segment:offset memory addressing. It was also the reason that interfacing to Windows DLLs was quite a chore because of the difference in memory model between the LabVIEW environment and the underlying OS and DLLs. Only when LabVIEW was available for true 32-bit environments like Windows 95 and NT, did that barrier go away. NI was at that time still predominantly a GPIB hardware company. A significant part of support was for customers trying to get the various GPIB boards installed on their computers and you had at that time more very different computers architectures than you could count on both hands and feet. There was of course the Macintosh and the IBM compatible computers, with all of them running DOS which Windows computers still were. Then you had the "real" IBM computers who had abandoned the ISA bus in favor of their own, more closed down Microchannel bus and also were starting to run OS/2 rather than Windows and about a dozen different Unix based workstations all with their totally incompatible Unix variant. And then even more exotic beasts like DEC VAX computers with their own expansion slots. Supporting those things was often a nightmare as there was literally nobody knowing how these beasts worked except the software driver developer in Austin and the customers IT administrator. NI had just entered the data acquisition marked and was battling against more established manufacturers like Keithley, Data Translation, and some other small scale speciality market providers. The turning point was likely when NI started to create their own ASICS which allowed them to produce much smaller, cheaper and more performant hardware at the fraction of the cost their competitors had to pay to build their own products and still selling them at a premium as they also provided the full software support with drivers and everything for their own popular software solutions. With other manufacturers you usually had to buy the various drivers, especially for NI software, as an extra and some of them just had taken the blueprints of the hardware and copied them and blatantly told their customers to request the software drivers from their competitor as the hardware was register for register compatible with theirs. The NI ASICS made copying of hardware by others pretty much impossible so NI was never concerned about making their drivers available for free.
-
When I started at NI Switzerland in 1992, things were indeed very different. For 4 months I went to Austin and I would get technical support calls that I of course had no idea how to solve. But we could walk up one floor or two and talk directly with the software or hardware engineers that were responsible for the product in question. As NI grew, this support model wasn't quite supportable anymore. Engineers still usually started out in support and often moved rather sooner than later to another position and walking up to the developers wasn't as simple as they weren't always just one floor higher but in a different building. Support still was handled by inside engineers though, usually with a tiered level, first support was handled by first line supporters who would respond to the standard problems, and if it got to complicated it moved up to 2nd or 3rd line support. Then it was outsourced to some extend to telephone support somewhere in Costa Rica or wherever and from then on it was often pretty much impossible to get any meaningful response. The answers we would get were sometimes so abysmal that I could have asked my son and would have gotten more meaningful information and it was often impossible to explain to them the problem, as they understood nothing but what their onscreen step for step problem solving tutorials told them. Then a few years back, like 2 or 3, NI recognized that this was not really working and changed to a more professional support infrastructure with a dedicated Technical Support Engineering model that actually deserved that name. If someone has a support contract or maintenance software contract, then this support works again very well, although in comparison to 25 years ago, it is practically impossible to get non official solutions that are just gathered by the support person from walking up to the actual developer who would throw together a quick (and sometimes dirty) solution to achieve the goal. Things are much more formalized, and unless someone is from a huge multi-million $ account, it's impossible to get a bugfix release of software or something like that, before the official release.
-
LabVIEW realtime and LabVIEW FPGA are pure Windows (32-bit only before 2021) extensions. The Linux downloads you found are for the Xilinx toolchain. You can install them under Linux, then setup your Windows FPGA compile interface to interface to them just as it does when you use the NI cloud compile solution.
-
Date/Time To Seconds Function and Daylight Savings
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in LabVIEW General
ISO8601 just as it's semi-sibling RFC3339 also supports an optional timezone offset identifier. Mr. Powels library deals with that and you should probably use his library. Basically if it is not present you need to treat the timestamp as being in local timezone (which can be tricky if interpreting data that was acquired somewhere else). Local Timezone offset means using the -1 indicator for the DST value in the cluster, and yes LabVIEW still needs to learn to listen to the OS message WM_SETTINGCHANGE that indicates among many other things a date/time attribute change as requesting that information every time from the OS when it deals with time conversions would be to costly. -
They also support a shared library interface!
-
Typically, writing such a beast isn't exactly rocket science. But validating it is, and whoever could send you some code doing this, it would be: - Just implementing as much as they needed at that point and everything else might be not there or wrong - Almost certainly not validated: "Look mam it works, without hands!" "Great son, now don't touch it!" So the major part of the work would still be on you unless someone had a real product that they did some good validation on, and will cost considerable money. Writing your own will be unsexy: Who the heck is still writing assembly binary files anymore? 😀, but it is most likely unavoidable in this case and the real work is in the validation that you mention and that will have to be done anyhow if your product is in such a regulated industry.
-
A good remark. I didn't immediately think of this.
-
It's pretty unclear what you really try to do. You mention CLNF and all that and have a DLL but you talk like you would like to implement everything in LabVIEW. My suspicion is that you still want to call UA_server_run(), but from LabVIEW and the bad news in that case is that you can't do what you try to do. LabVIEW is dataflow driven. While it allows to call C functions, it doesn't and can't implement the full C semantics. Once it passes control to the UA_server_run() function in the Call Library Node, this code executes on its own until it decides to return. But since LabVIEW is dataflow driven and doesn't know pointers like in C, you do not have access to the memory location the running boolean is stored at that you pass to the function. If you branch the wire, LabVIEW will very "helpfully" create a seperate copy of that variable, not just pass a pointer around, since passing pointers around would completely go against the entire dataflow paradigm. You will have to create a wrapper DLL that implements and exports the stopHandler() function as well as a function that calls UA_server_run(), passing it the DLL global "running".
-
That's quite a blanket statement. I'm sure it can be done, not directly but the myRIO does have a Wifi interface, and all cRIO have wired Ethernet. So if you have a Wifi router that you can let the myRIO connect to, you can certainly connect it to the cRIO which all have wired Ethernet in one way or the other. It also support Ethernet over USB but that is generally only easily usable to connect from a computer to the device. In order to connect this to another device like a cRIO connected to the network, you would have to somehow bridge the virtual USB network adapter with the normal network interface. It's possible but not straightforward.
-
Since you have already experience with network communication in LabVIEW I would strongly suspect that this is on the short and medium term less than what you will have to put up with to make this current external shared library work fully reliable. Basically writing the readValue() function in LabVIEW is pretty straightforward and the underlaying readLong(), readDouble() and readString() should be even simpler. As long as you have the C source code of these all available I would think it is maybe 1 or two days of work. The only tricky things I see are: - we haven't seen the sendCHARhandle() function nor what the CharacteristicHandle datatype is. It's likely just an integer of some size, so shouldn't be really difficult. - it's not clear how the protocol sends a string. ideally it would first send a byte, or integer that indicates the number of bytes that follow, then everything is very easy. If it rather uses a zero termination character you would need to go into a loop and read one character after the other until you see the zero character, that's more of a hassle and slows down communication a bit, but that would be similar in the C code.
-
Then you need to deallocate this pointer after you are done with it! Any you can not just call whatever deallocation function you would like, it MUST be the matching function that was used to allocate the buffer. Windows knows several dozen different functions to do something like that and all ultimately rely on the Windows kernel to do the difficult task of managing the memory, but they do all some intermediate thing of their own too. To make matters worse, if your library calls malloc() you can't just call free() from your program. The malloc() the library calls may not operate on the same heap than the free() you call in your calling program. This is because there is generally not a single C runtime library on a computer but a different version depending on what compiler was used to compile the code. And a DLL (or shared library) can be compiled by a completely different C compiler (version) than the application that calls this shared library. On Linux things are a little less grave since libc is since about 1998 normally always accessed through the libc.so.6 symbolic link name which resolves to the platform installed libc.x.y.so shared library but even here you do not have any guarantee that it will always remain like this. The fact that the libc.so soname link is currently already at version number 6 clearly shows that there is a potential for this library to change in binary incompatible ways, which would cause a new soname version to appear. It's not very likely to happen as it would break a lot of programs that just assume that there is nothing else than this version on a Linux computer, but Linux developers have been known to break backward compatibility in the past for technical and even just perceived esthetical reason. The only safe way is to let the library export an additional function that calls free() and use that from all callers of that library. And to make matters worse, this comment here: typedef struct Value { union /* This holds the value. */ { long l; unsigned long ul; double d; char *s; /* If a string user is responsible for <<<<<------------ * allocating memory. */ } v; long order; valueType type; /* Int,float, or string */ valueLabel label; /* Description of characteristic -- what is it? */ } Value; would be in that case totally and completely false and misleading!! It would be more logical to let readString() allocate the memory as it is the one which knows that a string value is actually to be retrieved and it also can determine how big that string will need to be, but adding such misleading comments to the library interface description is at best negligent and possibly even malicious.
-
Strictly speaking is the v nothing in itself. It's the unions name and does not really occupy any memory in itself. It's just a container that contains the real data which is one of the union elements, so the l, ul, d, or s. And yes the s is a string pointer, so according to the comment in the declaration, if you request a string value you have to preallocate a pointer and assign it to this s pointer. What size the memory block needs to have you better also know beforehand! And when you don't need it anymore you have to deallocate it too or you cause a memory leak! Now LabVIEW does not know unions so we can't really make it like that. Since the union contains a double, its memory size is always 8 byte. But!! So if the type is Double, we need to Typecast the uint64 into a Double. But the LabVIEW Typecast does Big Endian swapping, so we rather need to use the Unflatten to string and specify Native Byte Order If the type is Long or ULong we need to know if it was sent by a Linux or Windows remote side. If it was Linux we just convert it to the signed or unsigned int64, otherwise we need to split the uint64 into 2 uint32 and take the lower significant one. If it was (or rather really is going to be a string) we first need to allocate a pointer, and assign it to the uint64, but only if we run in 64 bit LabVIEW, otherwise we would strictly speaking need to convert the LabVIEW created pointer which is always an (U)Int64 on the diagram into an (U)int32 and then Combine it with a dummy (U)Int32 into an uint64 and assign that to the union value then pass that to the readValue() function, retrieve the data from the string pointer and then deallocate the pointer again. Since we nowadays always run on Little Endian, unless you want to also support VxWorks targets, you can however forget the (U)Int64 -> (U)Int32 -> (U)Int64 conversion voodoo and simply assign the LabVIEW (U)Int64 pointer directly to the union uint64 even for the 32-bit version. And if that all sounds involved, then yes it is and that is not the fault of LabVIEW but simply how C programming works. Memory management in C is hard, complicated, usually under documented when using a library and sometimes simply stupidly implemented. Doing the same fully in LabVIEW will almost certainly be less work, much less chance for memory corruptions and leaks (pretty much zero chance) and generally a much more portable solution. The only real drawback will be that if the library implementer decides to change how his communication data structures are constructed on the wire, you would have to change your LabVIEW library too. However seeing how thin the library implementation really is it is almost certain that such a change would also cause a change to the functional interface and you would have to change the LabVIEW library anyhow. That is unless the readString() function allocates the pointer, which would be more logical but then the comment in the Value typedef would be wrong and misleading and your library would need to export also a function that deallocates that pointer and that you would have to call from LabVIEW after you are done converting it into a LabVIEW string.
-
But someone has to allocate the pointer. If it is not readString() it has to be done by you as shown in Shauns last picture. Otherwise it may seem to work but is in fact corrupting memory.
-
That code is in itself neither complete nor very clear. And it is not clear to me why you would even need to interface to the so library. It seems to simply read data from a socket and put it into this artificial variant. Rather than using a so that does such low level stuff to then call it from LabVIEW on an only slightly higher level, it would seem to me much more logical to simply do the entire reading and writing directly on a LabVIEW TCP refnum. The problem likely is in the readString() function which is not shown anywhere how it is implemented. It supposedly should allocate a buffer to assign to the c_ptr variable and then fill that buffer. But that also means that you need to call the correct memory dispose function afterwards to deallocate that buffer or you will create nice memory leaks every time you call the getValue() function for a string value. Doing the whole thing directly with LabVIEW TCP functions would solve a lot of problems without a lot more work needed. - You don't depend on a shared library that needs to be compiled for every platform you use. - You don't end up with the long difference between Windows and Unix. Most likely this library was originally written for Windows and never tested under Unix. What he calls long in this library is likely meant to be always an int32. Alternatively it was originally written for Linux and that value is really meant to be always an int64. As it is programmed now it is not platform interoperable, but that doesn't need to bother you if you write it all in LabVIEW. You simply need to know what is the intended type and implement that in LabVIEW accordingly and you can leave the library programmer to try to deal with his ignorance. - You have one LabVIEW library that works on all LabVIEW platforms equally, without the need to distribute additional compiled code in the form of shared libraries. - You don't have to worry about buffers the C library may or may not allocate for string values and deallocate them yourself. - You don't have to worry about including the LabVIEW lvimpltsl.so/dll file in a build application.
-
Definitely not the same. A 32-bit process simply can't address more than 4GB in total so it makes no sense to have a variable that can specify a size of more than that. Usually the maximum amount of memory that can be allocated as a single block is much smaller than that too. According to the 1999 ISO C standard (C99) it is at least 16-bit but meant to represent the size of an object. Library functions that take or return sizes expect them to be of this type or have the return type of size_t. As such it is most commonly defined to be the address size for the current platform. In most modern compilers this is the same as the bitness for that platform. Your reasoning would be correct if you wanted to write a general completely target platform independent library. But we work in the confines of LabVIEW here. And that supports several platforms but not that very exotic ones. Under Windows size_t is meant to be the same as the unsigned bitness value. Under Linux the same applies as can be easily verified in the stddef.h file. So in terms of LabVIEW it is safe to assume that size_t is actually always the same as the unsigned pointer sized integer. Of course once we have 128-bit CPUs (or God help us, 64/64 segmented addresses) and LabVIEW chooses to support them, this assumption may not hold anymore. Also the specification only says that size_t must be able to at least address SIZE_MAX (which is probably the same as UINT_MAX under Windows) elements but not how big it actually is. Pretty much all current implementations except maybe some limited embedded platforms use a size_t that can address a lot more than that. And that is the nature of standards, they use a lot of at least, must, can, should and at most and that are usually all constraints but not exact values. C is especially open in that sense as the C designers tried to be as flexible as possible to not put to much constraints on C compiler implementation on specific hardware.
-
size_t is usually according to the platform bitness since it makes little sense to have size parameters that would span more than 4GB on a 32-bit platform. If you need a 64-bit value regardless you need to use the explicit uint64_t. time_t is another type that can be 64-bit even on 32-bit platforms, but it doesn't have to be. It often depends on the platform libraries such as the libc version used or similar things.
-
This doesn't make much sense. His example points nowhere, it simply takes the pointer and interprets it as a Zero terminated C string and converts it to a LabVIEW String/Byte array. If this doesn't return the right value, your v value is not what you think it is. And the Get Value Pointer xnode does in principle nothing else for a string type. But without an example to look at, that we can ideally test on our own machines, we won't be able to tell you more.