A Scottish moose
-
Posts
52 -
Joined
-
Last visited
-
Days Won
2
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by A Scottish moose
-

TCP/IP or GPIB to Thermotron?
A Scottish moose replied to Gan Uesli Starling's topic in LabVIEW General
It looks like those drivers haven't been updated in a while. 7.1. That's before my time... They uses the IVI standard, which is fine, but it will require you to install the IVI driver as seen in the readme.... In my opinion that's about 1 step away from abandon-ware unless they give you some installation examples. The IVI requirement really drives your options here, you'll need to set up a driver session and go through that process under Max. I am not of fan of IVI, and it's not because of lack of experience. Once you get your IVI driver installed for the Thermotron you'll see it listed in the driver sessions under MAX. Then you'll create a logical name for your device and connect it to the driver with the physical connection information (IP address). Honestly this is a LOT of work to just get a temperature update. See if you can get away with the basic GPIB route and avoid using that driver. I think that will be way easier. Cheers, Tim
-
TCP/IP or GPIB to Thermotron?
A Scottish moose replied to Gan Uesli Starling's topic in LabVIEW General
Either option ends up being pretty easy, although I would say the GPIB route would be more simplistic with VISA. Does your device provide any midlevel drivers for output? Looks like the Thermotrons are soft panels, so I would expect those tools would be provided. I'm sure either way the process will be simple. If you have a TCP driver that abstracts out the commands and packet parsing for you go that route for sure. Otherwise GPIB is a pretty quick up and run with VISA commands. I've done both and most basic drivers come together in less than a day. Cheers, Tim -
I might start looking into more JSON based solutions. Thanks for the tip
-
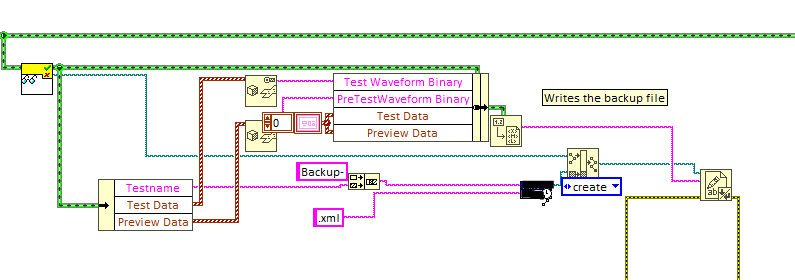
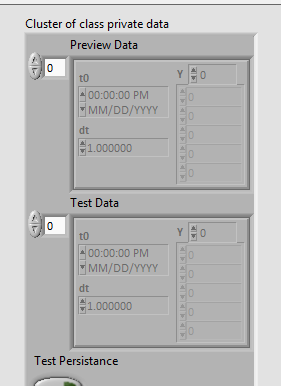
Hey everyone, I am working on a backup function for a test executive. The backup uses the 'class to XML' vi to create an XML string and then save it to a file to be reloaded later. All of my test specific information lives in the class (or one of it's children). I like this functionality because it makes backup and reload brainless. It just works.... until now... I've got a test class for my current tester that's grown rather large. Everything works fine, until the tester loads some waveform data into either of the waveform arrays. Without data in this field the class reloads just fine, otherwise if fails and says the XML is corrupted. As you can see in my backup vi I have built in a work around that flattens the waveform arrays to strings, drops them back into the class private data, deletes the waveform arrays and then writes the class. This works! Much to my surprise both waveform data and the rest of the class data are written to file and reloaded without error. Does anyone have any knowledge or experience with this? Cheers, Tim
-
On the topics of edit time performance.... Over the last month I've been developing a test system that is now around 650 custom Vis in memory at one time. I started to notice a quickly increasing load on windows from LabVIEW towards the end of the project that disappeared after removing the SVN toolkit. I'm sure it depends on the processing power of your machine but I find that the 500+ VI projects start to see some major impact from the Viewpoint add on. It's a fantastic tool, but that's the trade off. Cheers, Tim
-
Out of memory error when using Picture Control
A Scottish moose replied to Neil Pate's topic in User Interface
I did a project recently that had quite a few large pictures that I convert to Pixmap during initialization. The images were static throughout the program so there wasn't a lot of access to this function, just at the beginning. I have not seen this problem with my program. Do you do this often during your execution perhaps frequency has an impact? I haven't seen this issue in my case. Hope that information is helpful, Cheers, Tim Edit: I use 2016 SP1 -
what is this 'user manual' you speak of?
- 9 replies
-
- 1
-

-
- over budget
- over time
- (and 2 more)
-
Is this a simple installer package? Do you have any add-on installers in your installer file? Might be worth checking the 'additional installers' page and see if there's something checked there that might contribute. If so try removing all additional installers and retrying the install to see if it'll take.
-
This is an interesting point. I haven't worked in an agile environment yet. As I've started to get some projects under my belt I can see how it would be valuable and how it would help to avoid some of those traditional pitfalls. Agile also forces an interaction more often (than a waterfall or gated model) between developer and customer and reduces the 'please let this work so I don't look like an idiot' situations. Or perhaps it just makes them lower stakes? Either way I think it makes the process better for all parties involved. Thanks for the thought!
-
Currently working on the last few features of a tester and had an idea to ask about projects that either took way longer than they should have or when you reached burnout and still had tons of implementation and testing work to be completed. What's the longest project you've worked on or projects where you hit burnout way before the end. How did you keep up motivation and keep slogging through it to completion? Might be interesting to hear peoples thoughts on getting through those long projects or the last few weeks/months of a project when things seem to take forever. Cheers, Tim
-
Labview class recompile and source controll
A Scottish moose replied to pawhan11's topic in Object-Oriented Programming
I went through the same problem when I started implementing OOP a couple years ago and Rick's answer is the correct solution. -
Were you able to find your solution to this problem? Not familiar with signal express; happy to help if you are still looking for some kind of solution. Cheers, Tim
-
Kinda like asking if infinity is equal to infinity.... yes?... and no... no it's not.
-
Create Database application In Labview for CSV files
A Scottish moose replied to Huqs's topic in LabVIEW General
Hello Huqs, Looked at your VI for a bit... Perhaps you could elaborate on exactly what you'd like some advice on? Cheers, Tim -
I've used Tortoise SVN since 2010 and really like it. I recommend it to everyone. used the Viewpoint tool for a little over a year and really enjoy it as well. As mentioned above it's very useful when having to do the same rename/delete function on a file and your SVN repo at the same time. Saves a lot of conflict and missing file dialog headaches. If you don't mind me asking... at what size of project do you start to see these problems? Most of my projects are in the 200-500 VI range. I haven't noticed any major impact at this point... On second thought I have noticed LabVIEW using a lot more processor time than I would expect it too lately but didn't attribute it to the VP-SVN add-on. Perhaps I should do some testing on that.
-
CLA Summit Austion 2017
A Scottish moose replied to Chris_Collier's topic in Certification and Training
That makes sense. I figured you were probably aware of it. It's everything I've seen so far. I haven't bought tickets yet either. I would assume Jim will have more before the end of summer. Cheers, Tim -
CLA Summit Austion 2017
A Scottish moose replied to Chris_Collier's topic in Certification and Training
You may have seen this already but worth mentioning: http://forums.ni.com/t5/Certified-LabVIEW-Architects/Americas-CLA-Summit-2017-Tentative-Date/td-p/3458178 To my knowledge this is still current. Don't know much on content but I would guess dates would be 18-22nd Sometimes the session has only run for 3 days but I believe the last two years has had a half day on Thursday. That's everything I know right now. I hope it's helpful. Cheers, Tim -
How do you organize your custom error code files?
A Scottish moose replied to A Scottish moose's topic in LabVIEW General
I can see there being some value in the centralized option and this might be what I end up going with. The point about putting in some time to search for existing error codes is also good. I can see how there's probably a lot of errors that fall into just a few different categories: task a broken, file is broken, code is broken. Thank you for the comments so far. Tim -
How do you organize your custom error code files?
A Scottish moose posted a topic in LabVIEW General
Hello everyone, I am working on putting together a test executive that pulls from a lot of external code libraries. I'm at the point now that I have a fair number of custom error codes generated by different DAQ libraries and keeping track of all of them is becoming increasingly difficult. I've been using error rings for custom error generation and while not ideal has served well enough until now. Keeping track of the codes hasn't been hard because they are few and far between. I've been thinking about transitioning to a custom error file instead of using ring constants because keeping track of it all is not realistic anymore. My question arises from the fact there are ~10 different libraries in this current project all pulling from 3-4 different source control locations and creating a single error file that covers all the errors from these libraries seems incorrect. I would think custom error records would travel with the library that uses them, but does this create file reference headaches when you start pulling in libraries and external references, PPLs, etc? Question: How do you keep track of your custom error codes? Some options that I could see being viable: A single company wide error code file that gets pulled down with your version control. A blanket approach would make sense and also would prevent error code conflicts from one library to another by forcing communication during modification and addition. Error code files packaged with each individual library and pull them all into projects when they are getting developed. This seems the most modular and portable but could result in conflicts with error code numbers if developers don't communicate about the ranges they are using; also how does LabVIEW do with referencing lots of different error files. Cheers, Tim -
The Test & Validation labs I support work with various hazardous materials (mostly combustible/volatile but the occasional chemical or health hazard shows up now and then). Because of this my team tries to make our test boxes as inert as possible. Dust and weather proof NEMA boxes with circular connectors is our standard. Since we are small on space we've been transitioning to micro PCs; Intel's NUC is a great option that we recommended to IT. Many of them are fan-less (a plus if combustible material does get in the box) and they are ~5x5". Perfect! The IT department balked at the idea. 'they aren't safe!, Virus protection?!, it doesn't look like a normal computer, we can't support it!" When we explained that it's just a tiny windows 10 PC they basically said they didn't want to support a new ghost image (Dell supports the Ghost images for all our standard issue machines) for these boxes because it was too much work... ya I know... So they offered a different micro PC that was about 2x the surface area. My NEMA box was starting to get pretty tight. IT agreed to support it (Read: it's under corp's Dell contract so dell will support it) and so we went with it and I redrew all my CADs to make it fit. It was cozy, I was frustrated, but all in all everyone was appeased with the deal so I considered it a successful bargain. After getting the box built IT guy came down to take a look at it.... First thing he said.... It's a little tight in there don't you think?
-
If my comments are confusing it might be related to our corporate implementation of Git. Perhaps I'm assuming some local habits are Git procedures and this is where the confusion comes from. At our shop the source control, bug tracking, code reviews, and release tracking are all incorporated into the cloud service collab.net. The Git rules are written as such that all these tools must be used. SVN rules are not written as strict so it's more to my decision on implementation. If I switched our LV libraries over to the Git system I'd have to take the whole system together, code reviews, bug tracking, and all. Since I'm the only developer here this is a little more than my development needs at this point. A git commits here requires 3 sets of eyes to agree to the quality of code. Since I'm the only LV developer it gets tough to find two people to say 'ya that actor framework implementation looks great!' I do see the value but LV hasn't quite gotten to that point for our office. Let me know if this clears up your questions. Cheers,
-
I would be interested in a deeper discussion on a LabVIEW implementation of Git source control. I am the primary developer here so the overhead doesn't make sense... yet... I can see where it would start to shine in a multi-developer environment. A discussion on the pros/cons of SVN vs. GIT would be an interesting (if geeky) discussion.
-
Storing/Importing DAQmx Task Configurations
A Scottish moose replied to A Scottish moose's topic in LabVIEW General
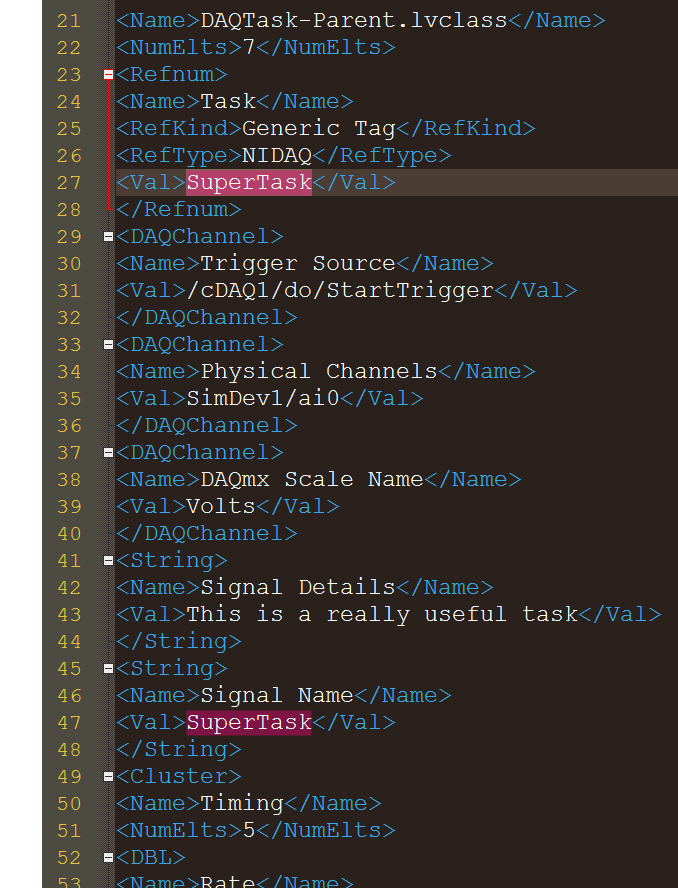
Update: I can't take credit for this one, as it was recommended to me. Here's a solution that I believe would work for those wanting a quick and dirty xml solution. Create a class, add the task to the class private data, and dump the class to xml. If you do this with just the task you get a nondescript task header, if you do it with a class you get the full task. Not really sure why this is the case. Perhaps there is someone with more knowledge of the XML parser who could shed some light on this.
-
I would agree with the above statements. The CLD carried less weight than I expected; the CLA carried quite a bit more. As a vehicle to get you to the next level I think it's worth it. If that's where you plan to stop perhaps not. Cheers,
-
SVN, GIT is popular among the rest of the company (text based dev) but I haven't found any limitations in SVN that make the extra overhead of the GIT workflow worth it.