mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by mje
-
Perhaps. All in, I'm still skeptical any LabVIEW code will run with any predictable schedule if the process is working so hard, regardless of priority or timing construts. I seem to be having luck with 120 second ping intervals and a corresponding 120 second timeout (the default for a VI server connection appears to be 10/10). However given that the builds for this project take considerable time, it will be weeks if not months before I feel confident of the reliability of such a timeout.
-
I'm attempting to set up a build server architecture such that I can execute my builds in parallel in remote application instances of LabVIEW. Initial tests are successful insomuch as the builds complete on the servers but there's an issue of the server becoming unresponsive (error 1130) during the build, preventing my client application from gathering results. My initial hack is to set the ping delay on the connection to greater than the expected build time. This seems to work-- I haven't seen a timeout yet-- but is hardly elegant. Should something go wrong I now need to wait an hour for things to timeout. Is there a way to get LabVIEW to prioritize its TCP stack a little more? I really don't like the idea of blindly assuming things are working just fine for an hour at a time, especially if a real network is involved. I'm not sure if there's anything to be done code-wise: if the build is taking up so many resources that the main server loop isn't servicing ping requests I have a hard time believing anything I do in LabVIEW would be reliable because I imagine the scheduler won't exactly be doing so well either...
-

Call Library Function Node fails depending on run location
mje replied to russellb78's topic in Calling External Code
How are you calling the DLL? I imagine you must be passing a path to the Call Library Function node? Is that dialog something you generate or the DLL? -
How do you make your application window frontmost?
mje replied to Michael Aivaliotis's topic in User Interface
Referenced thread: http://lavag.org/topic/13803-getting-the-window-handle-for-a-fp-with-no-title-bar/ -
How do you make your application window frontmost?
mje replied to Michael Aivaliotis's topic in User Interface
For what it's worth, there is a private VI property that returns the OS window handle so you don't need to use FindWindow. It's somewhere on lava but I can't link to it via the mobile site. I think it's called OSNativeWindow or something. The thread has a VI containing the property node which can be dropped in any other VI (it's a private property). That should fix any issue with window titles not matching. FindWindow has a lot of limitations, some of which include conflicts with other windows, or inability to find Windows without a title bar. I tend to use the property exclusively when I need an hWnd. -
Is it really a 1D vs 2D problem? I didn't try with a 2D numeric array. I was under the impression it was the indirection in the array of strings that was causing issue- that is how the array is really just an array of handles to other data.
-
Coming from someone who has had to tackle memory barriers a few times in LabVIEW before, I agree the memory manager can be a little aggravating at times, but I don't see a bug here. As beefly presented the VIs when executing the main I can do a single string create operation and watch the memory allocation soar. When I follow up with a release operation memory decreases by a size that seems to correlate to the number of elements (approximately N*4 bytes), but leaves a larger portion of memory allocated to LabVIEW which appears to be the actual string data, consistent with Darin's observations. This is a good example, kudos. However as Hooovahh pointed out, I don't believe the memory is leaked. It is not lost track of. I can indefinitely do create/release pairs with a stable peak memory allocation. The peak will only increase if I hang onto multiple references at a time which is required to support the multiple independent data spaces. This is definitely not ideal. It would be nice if LabVIEW released the memory to the host operating system so, for example a LabVIEW process which has a tendency to balloon from time to time can restore itself to a small memory footprint when idle. While I don't like the behavior, I think it's still managed in a defined way so don't see a bug here.
-
Google v Oracle -- appeal may interest LV programmers
mje replied to Aristos Queue's topic in LAVA Lounge
While there have been some positive moves in recent history by the courts and various federal agencies in the USA regarding technology, I think they are more the exception than the norm. I am not optimistic on the future of technology policy [in the USA]. -
Suppose we limited 1 event structure per block diagram?
mje replied to Aristos Queue's topic in LabVIEW Feature Suggestions
Well yes, it is a weird restriction. I can't think of any language which restricts say one "switch" construct per function call or the like. Flip side to that though is you can see it in languages like the C flavors where functions can't be nested, whereas in other languages like javascript you can. Also agreed on that if there's no good reason to take it away, I don't think it should be. There is a smell to the proposal I can't place. I'm just saying that it wouldn't affect me personally, and don't really buy in to a lot of the arguments presented here, except breaking existing code. -
Suppose we limited 1 event structure per block diagram?
mje replied to Aristos Queue's topic in LabVIEW Feature Suggestions
I'm late to the party on this one, and largely unable to contribute due to being mid-vacation, but... I understand all the arguments in this thread, and while the points you all raise are valid, I feel that if reuse, decoupling, or the like are the motivations for arguing against AQ's proposal, I'd have to say I think you may wish to reconsider. I generally agree with the ideas you have all raised, but if you end up just slapping all these loops/structures on the same diagram to get these gains, you have just shot yourself in the foot. Put them in a sub VI, and the single ES limitation would not affect you. That subVI may well then prove reusable, will be decoupled, and open other doors that come along with being a subVI if desired (reentrancy, dynamic loading). I like the idea. It can likely reduce mistakes many new programmers make, and for the advanced programmer I don't see it imposing any real restriction-- to the contrary I see it promoting good practice. -
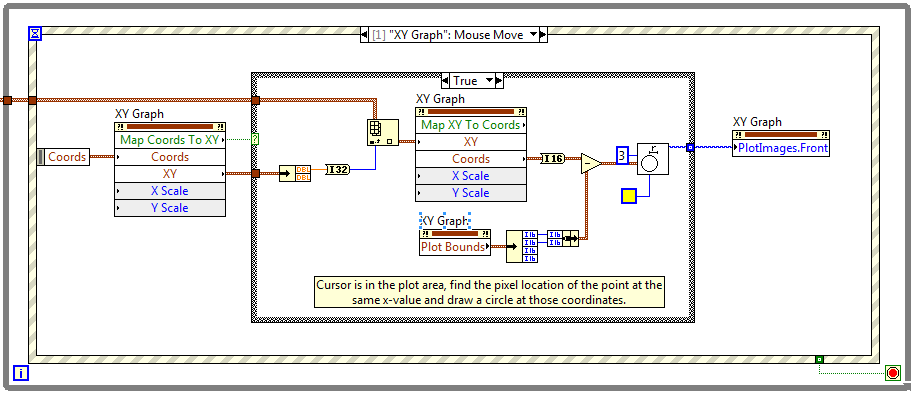
The picture functions are nearly as old as time itself, I'm not sure how far back the plot image properties go back, but at least as far as 2009. I've saved the VI for 2012: Mouse Tracking LV12.vi
-
Here's a brief example how to draw your own images on plots. The VI simply tracks the x-location of the mouse and draws a circle around the corresponding data point. You could use whatever logic you want (closest Cartesian point, tracking multiple plots, whatever) and draw any info you'd like, but this should get you started if the built in functionality doesn't suffice. Mouse Tracking LV13.vi

- 16 replies
-
- 3
-

-
- plot
- point label
- (and 1 more)
-
There is built in functionally to do this but I find it lacking. Instead I use the graph method to translate the point coordinate to a pixel coordinate, then use the picture primitives to draw text, arrows, or other features, and place the resulting picture in one of the graph's plot image layers.
-
Since there's interest, I'll post a more up to date library I've been working with for the last few years, ported back to LV9. This library focuses on producing version 1 timestamp based GUIDs and is incapable of producing the same GUID twice assuming OS clock settings are not fiddled with. The caveat being if you somehow manage to run out of GUIDs for a given timestamp, the VI will yield to obtain a new timestamp, so this method can't be used in FPGA applications. It also fixes a subtle issue with random number generation. Note I have no idea if current hardware would even be able to exhaust GUIDs for a timestamp (it would require 16383 GUIDs to be generated within the resolution of the value returned by the LabVIEW time primitive), but suspect that if anything could, an FPGA may be able to. The non-timestamp methods have been removed-- I didn't see a use for them since there was the possibility of collision with those (however small it may be). LabVIEW.GUID LV9.zip Edit: sorry, originally posted the wrong zip. Fixed.
-
Haven't looked at your code because I'm on mobile but the beauty of enumerated types in any language are how under the hood they're just numbers. Attach names at design time for convenience, but in the end still numeric when operating. I don't see how you can get this benefit with objects?
-
This is my beef with PID control theory reference material as well. I find it's pretty trivial to do PID if I have a well characterized plant and can get "close enough" with a model calculation, leaving the PID to take up the slack. The "intuition" part comes in when I'm working with systems where the plant is not well understood.
-
2013 is the first version of LabVIEW in a long time I have not had any major problems with.
-
I don't have an answer, I'm in much the same situation. I've gotten pretty good at tuning but I'd be hard-pressed to explain it or put down any solid methodology. Just chiming in, you're not the only one.
-
I hate to say it, but I've given up on this behavior-- the invisible changes that LabVIEW makes automatically yet refuses to identify. I have many projects that show the same "An attribute of the project was changed" simply by opening them. Even on the same system: I can save, close, and re-open and voila, that oh-so-important-and-so-very-obvious-that-I-won't-even-bother-to-tell-you-what-it-is attribute is changed once again. The same project in the thread Paul referenced has since developed a related behavior which is equally helpful. It is perfectly stable on any given machine (aside from the attribute modified problem). But move it to another and suddenly "Type Definition modified" comes up which throws hundreds of VIs off and source code control into a tizzy. Two physical machines and two virtual machines, and there's no pair of which the code can be moved between (yes, I've actually tried each permutation). Seriously, I've lost all patience. I'm done. LabVIEW has won. When I need to work on that project outside of my office, I fire up my home virtual machine, in which I fire up a VPN, through which I work via remote desktop to my office desktop, then code as much as I can before I get too frustrated by doing graphical coding over a relatively high latency channel. I can't be bothered to use my notebook, or my home VM directly because it's too difficult to decouple the changes I make to those LabVIEW makes automatically because of that darned type definition.
-
Can't wait to get my hands on one of these. Didn't know they had even announced price yet let alone availability.
-
getting the name of a class - speed improvements
mje replied to John Lokanis's topic in Object-Oriented Programming
Don't know if this is so much a speed improvement so much as a first implementation. Several of us have been wishing for an efficient way of retrieving the qname of an object's class at run-time, along with a way of getting a default value from a qname. These native implementations make roll-your-own serialization methods way faster. No doubt the hacks AQ had to put in place for his framework led to this, and I for one am very glad to see this bit of functionality-- it was one of the glaring omissions in LVOOP up until now in my opinion. -
getting the name of a class - speed improvements
mje replied to John Lokanis's topic in Object-Oriented Programming
I see about 15x difference. Curious why, I wouldn't expect one. More importantly though the new method returns qualified names. That alone would make me prefer it even if it was slower. -
Preventing System-Style Controls From Resizing With OS Font Settings
mje replied to mje's topic in User Interface
Sweet. I was aware of those ini keys but had no idea that they would keep LabVIEW from honoring the OS font scaling settings. Kudos to you, sir! I do however wish I knew what the "0", "1", etc meant in place of the font name, I hadn't seen that syntax before. I'll add that the settings don't appear to solve the issue with the ring controls clipping however, but that I can live with. -
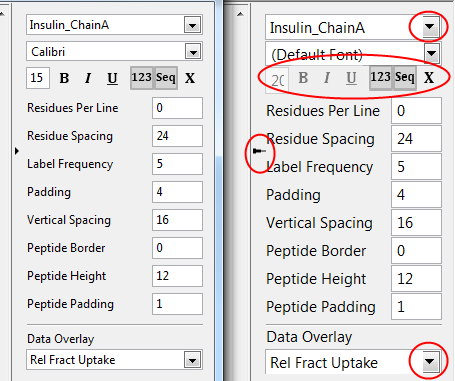
I'm annoyed by a particular behavior of LabVIEW in that it seems to resize controls from the system palette if the operating system's font settings are changed, and how sometimes this resizing is handled rather poorly. For example: The left half is the intended UI, and the right is what happens if the OS is set to a font size of 125%. Don't even get me started on 150%, the amount of whitespace a UI needs to leave at 100% to support a 50% increase in size is just rediculous. There's really two things going on here that I don't like. The system ring controls clip when font size is not 100%. This is visible in the controls that have the strings "Insulin_ChainA" or "Rel Fract Uptake" displayed. Note however the combo box renders correctly. Doubt I can do anything about this, but this behavior strikes me as unintended. The other issue is the resizing of my image based controls. They're derived from system palette controls because I wanted the hover effect on them. All of them are set to not show the boolean text (even so boolean text properties are left empty), yet still they are resized by the font settings. Is there any way to prevent this? As I see it with the image control resizing I can either go back and re-create them such that they're bigger and won't be resized at 125%, or maybe force them into submission by programmatically setting their size, or just ditch system controls (thus losing the automatic hover effects) and hope other controls don't have this resize behavior (confirmation anybody?). Vector based graphics would also help but...
-
Updating a middle element of a variant tree
mje replied to John Lokanis's topic in Application Design & Architecture
I don't have time to review this whole thread, but I thought I'd lob this one over to see if it makes sense to your situation. When I posted that idea I was contending with variant tables that were creeping into the multiple GB realm, the size of an individual attribute could reach up to 100 MB and itself not be "flat" data. The ultimate solution was to migrate to a database, but that's beside the point. What I ended up doing before I landed there was to flatten the structure to a single variant and use a syntax for key naming to resolve the "hierarchy". For example rather than storing a variant with a collection of keys ["A", "B", "C", "D"] in a top level variant under the key "X", instead store four keys in the top level variant ["X.A", "X.B", "X.C", "X.D"]. This removes the need for the copy when you need to access any of the child elements and may help you. Unfortunately it adds a whole mess of other requirements that aren't so attractive depending on the nature of your data. Do you need to be able to reference the hierarchy at any level, as in "Get me all of the subkeys that fall under "X"? You'll either need secondary data structures to manage queries like that or do some painful searches over all key names. Also you'll need to manage your syntax to avoid parent keys from stomping on lower level keys. Never mind the headache of having all of your data management at a single non-extensible level. All of those drawbacks quickly moved me away from variants as a means to store large amounts of hierarchical data. In my opinion variants are unmatched at storing large amounts of flat associative data, but until we can get in-place access to attributes they are awful for hierarchical structures if your data is significant.