mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by mje
-

"force" delegation? <no idea what to call this topic>
mje replied to GregFreeman's topic in Object-Oriented Programming
I think this may be your problem. I'd tackle it like so: class SpectrumData{ public virtual DoSomething();}// Each type inherits from the SpectrumData classclass FAT : SpectrumData{ // Implement the must-override public DoSomething();}// Other implementations...class FAT2 : SpectrumData;class GAG : SpectrumData;class STA : SpectrumData;class RDB : SpectrumData;// Note no inheritanceclass SpectrumData_TAG{ SpectrumData Data; DoSomething();}SpectrumData_TAG::DoSomething(){ // The TAG class delegates to the appropriate implementation of the contained type. Data.DoSomething();} That is the TAG class wouldn't share the same ancestor as each individual type. I'm assuming there's a good reason you're looking to preserve this union-like behavior. -
Absolutely. I'm curious though, how realistic of a use case is it where the bottleneck would be the actual copying of an element from the buffer such that allowing independent tasks to simultaneously operate on different buffer elements will actually give a measurable return relative to the execution time of whatever is making these calls? I just don't now the answer to this. I completely get how in other languages you can get gains by using pointers and such and avoiding copies for large data structures by operating directly in the buffer's memory space, but in LabVIEW there's just no way to do that and you'll always need to copy an element into a scope local to each reader. I mean if the index logic is separated from the buffer access logic, does it really matter if only one task can actually access the buffer at a time when it comes time to actually read/write from the buffer? I completely understand that yes, you may get a few hundered nanoseconds out by having one task modify an element while another task reads a different element, but if any real implementation that uses this fast access consumes a hundred times more time, I'd argue there's no real point. What are the relative gains that can be had here? How do those gains scale with the frequency of hitting that buffer, which depend on the number of readers and how fast the cycle time of each reader is? All in, fun stuff. Please don't mind my poking about, the theory of this discussion fascinates me. I doubt I can offer any real insight as far as implementtion goes which any of you haven't already considered.
-
Correction: you can't do this in LabVIEW without locking the whole array or some shared reference which contains the array. Reading a single element from an array or updating a single element can easily be done with the existing primitives, but to be able to operate in place would require some sort of synchronization mechanism. DVR, LV2, SEQ can easily replace only a single element, but each requires the lockdown of the whole containing construct.
-
Was the memory manager the first place you looked? There are definitely ways to do this in native LabVIEW code...
-
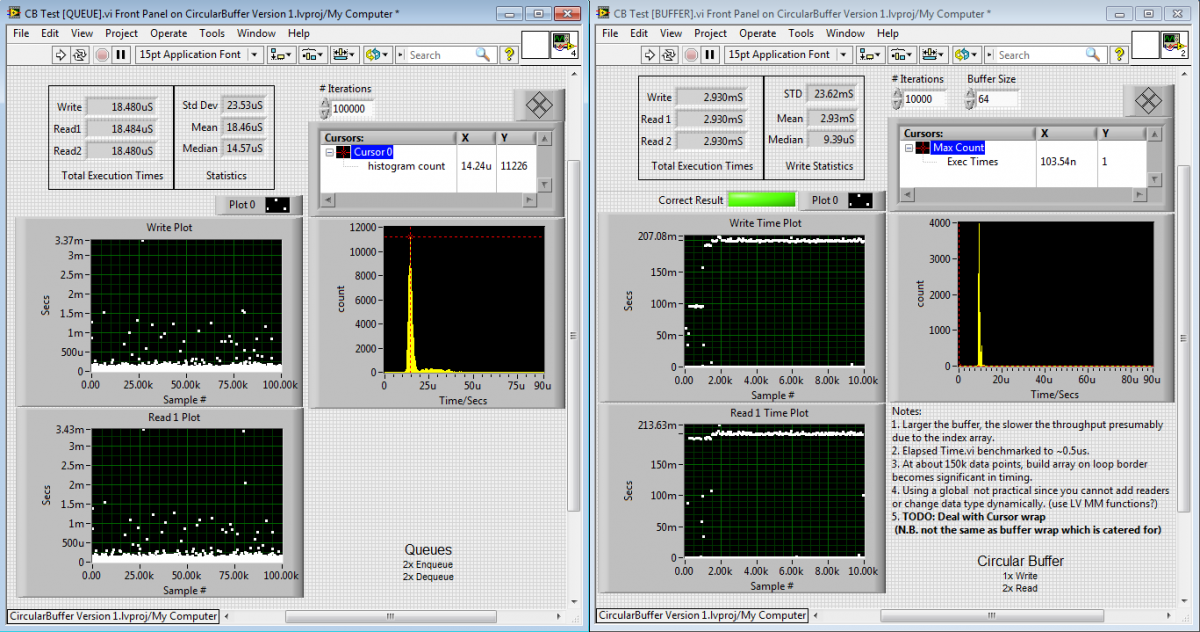
My only criticism of the benchmarks is the queue consumers go until the queue is released, which does not mean they consumed all the data. I think it would be best to handle releasing each queue only after the consumer has finished, don't stop on error, stop on fixed number of iterations. I suspect that's what AQ was getting at. I don't expect it will make much difference when sample sizes are large. I'm also concerned about CPU exhaustion. Correct me if I'm wrong, but if a reader tries reading an empty buffer, it will spin in an unthrottled loop until data is ready? I worry that should there not be enough cores to accommodate all the end points, how much time will be spent spinning waiting for the cursor to advance that could otherwise be executing other endpoints? Worse would the subroutine priority lead to complete starvation? Similar arguments for writers, though I haven't poked under the hood there. Changing the VI from a subroutine and letting it yield should it ever not get a valid cursor did not seem to change my metrics.

-
Neat. This is a 64-bit Win7 virtual machine which has access to 2 cores and 4 GB RAM. I see 15 us for queues versus 9 us for buffer when looking at medians. The mean and standard deviations are useless metrics on this platform because of the occasional hideously long access times on the buffer implementation. Note the chart for the buffers has been scaled to remove the outliers. Observed a moderate dependence on buffer size, which I expect is a consequence of using globals-- copy the whole array to read only a single element. I can see up to 12 us for the buffers if I increase the buffer size by even a factor of 2, but it levels off after that, I never saw more than 12 us. Haven't looked at the guts of it yet, but does the system ensure that old elements aren't overwritten if one of the consumers hasn't read them? Or is that "OK" in this pattern? I'm not surprised the buffers do better than the queues considering the lack of any synchronization in the buffers however I am surprised at how close the results were. I was half expecting an order of magnitude gain by circumventing the refnum locks that need to be run using queues. Perhaps the polling is starving some processing, or the buffer copies, or a combination of the two?
-
<blockquote class='ipsBlockquote'data-author="Aristos Queue" data-cid="103871" data-time="1372301245"> <p>That is *exactly* what made me pause: if at any point you make a copy of the data, you have lost the advantage of this system over the parallel queues. Since you *must* make a copy of the data in order to have two separate processes act on it at the same time, there's no way to get an advantage over the parallel queues mechanism.</p></blockquote> I would argue otherwise. If you're implementing parallel queues to pass data directly, you've avoided making two distinct buffers. Yes, each element ultimately gets copied for each consumer, but there's only ever a copy for a single element per consumer floating around. If on the other hand your parallel queues are passing indices to the shared buffer, it allows you to get in and out of that buffer-- you make your copy and do your work, no need to maintain a lock while you operate in place. I have a really hard time believing their architecture doesn't use some sort of locking mechanism. At some point they need to read that circular buffer, and either they maintain a lock on an element while its being operated on, or they only lock it briefly while it's being copied. There's just no other way to ensure an old element doesn't get overwritten when the circular buffer flows around. Aside: I wish lava would fix posting from mobile browsers...
-
Interesting topic, and I can't say I anticipate being able to formulate a full reply so I'm just going to lob this one over the fence and see where it lands. I can't say I'm really convinced it's a matter of "Queues vs Ring Buffers". Queues after all provide a whole synchronization layer. Perhaps arguing "Sequential vs Random Access Buffers" might be more apt? Also it seems to me the underlying challenge here is how do you contend with multiple consumers which might be operating at different rates. Without delving too deep down the rabbit hole, it appears they've done only a handful of things that distinguish this Disruptor from the traditional producer-consumer pattern we all use know of in LabVIEW. Obviously there are huge differences in implementation, but I'm referring to very high level abstraction. Replace a sequential buffer with a random access buffer. Make the buffer shared among multiple consumers. Decouple the buffer from the synchronization transport. We definitely have the tools to do this in LabVIEW. Throw your data model behind some reference-based construct (DVR, SEQ, DB, file system...), then start to think about your favorite messaging architecture not as a means of pushing data to consumers, but as a way of signalling to a consumer how to retrieve data from the model. That is not "Here's some new data, do what you will with it", but rather "Data is ready, here's how to get it". Seems like a pretty typical model-view relationship to me, I've definitely done exactly this many times in LabVIEW. Of course I may have completely missed the point of their framework. I probably spent more time over the last day thinking about it than I have actually reading the referenced documents...
-
Built Application Occasionally Freezes on Windows Open/Save Dialog
mje replied to mje's topic in LabVIEW General
Yeah, I'm afraid it might be a Windows and not a LabVIEW problem as well. Afraid because then there's probably nothing I can do about it. The default path in my case likely isn't a network drive, but it could be a USB location. I say "probably" because for my various file dialogs I store the last used path in a feedback node so each dialog starts in the last used location, so I can't say where that dialog was trying to point to initially. When this happens the first thing I do is rush to another application and see if I can reproduce the issue, but I'm never able to. -
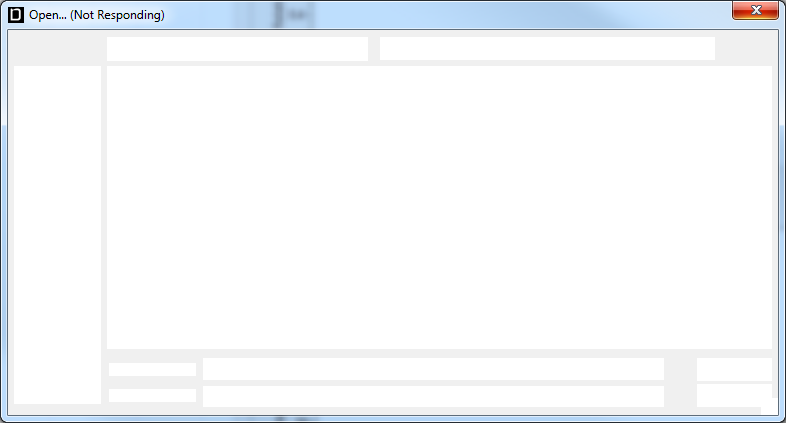
I'm wondering if any of you see this behavior. I have an application that from time to time locks up when attempting to show the Windows open/save dialog: As far as I can tell if this happens I'm at a permanent deadlock: I've never seen the application recover. This happens very rarely so I don't have a use case to reproduce or troubleshoot, but I've seen it happen a few times and some of our customers have complained about it as well. I only mention it now because it just happened to me today... I'm using the File Dialog express VI (cough) to get the prompt. Has anyone else seen this behavior or possibly know how to prevent it?
-
Best way to mimic fixed-size array use in clusters?
mje replied to RCH's topic in Object-Oriented Programming
I don't think you can do exactly what you want. Easiest way is to probably break out the array data from the cluster and send it down it's own FIFO. Reassemble the cluster on the receiving end from the data received from each FIFO if need be. The RT FIFO create primitive has an input that allows you to specify array size. -
What so bad about 'thread safe' singletons anyway?
mje replied to viSci's topic in Application Design & Architecture
Indeed. I'm still not sure I catch what you were originally trying to do. You seemed to be going to a great deal of effort to avoid passing a class wire around in favor of a semaphore and other type definitions along with the class reference. You now seem to be on a different track-- just using traditional class methods and sharing a DVR around via a FGV. Remember what Shaun pointed out, a FGV is a singleton. There are several issues that can creep up with implementations similar to where I think you were going (the DVR + semaphore). These cautionary points aren't necessarily critical of your original strategy as there are far too few details above, rather they're more what I've learned from my own experience. I've made these mistakes before and now settled on not designing classes which use DVRs of their own type on their connector panes. Keep everything by-value. If a framework needs a DVR, be it for a singleton other reasons, keep the DVR entirely out of scope of the class. One reason is data copies. Take a good look at some of the example code posted above and spot where data copies are being made. This may or may not be a problem depending on the nature of your model, but bear in mind the quantities and reentrancy of your class methods also factor in. Even a modest sized model can use orders of magnitude more memory than the actual model size if you have to make copies of it in many VIs, multiply it even more if some of these methods are reentrant and they're used in many places in your code. Using class based DVRs as I/O terminals on the class' own VIs also pretty much kills any idea of extending code as everything needs to be statically linked. Frankly, if you can't use dynamic dispatch, you really just have fancy type definitions and you've more or less neutered the main reason to use objects in my opinion. Yes, I'm oversimplifying the argument, but it's late. I'm already losing my train of though here, so finally I'll just say it's so much simpler if you forget about the DVR entirely when writing your class. I'm not saying ditch the DVR, just don't consider it from the class' perspective. I used to hate the idea of using IPEs everywhere in my code. Granted, I still don't particularly like the aesthetic of them, but they are very functional, and I really think it's not the responsibility of the class in most cases to dictate what needs to be atomic or not. You may think you know what operations need to be atomic now, but if a year later you need to string together a pair of previously atomic operations in a new composite atomic operation, you can't do so without re-factoring the original class. That should set off alarms. m -
What so bad about 'thread safe' singletons anyway?
mje replied to viSci's topic in Application Design & Architecture
Why do you use an additional semaphore when the DVR has a built-in one by virtue of the in-place element structure you need to operate on the DVR? -
All I can say is, I feel your pain John. Splitters help make amazing interfaces that automatically scale, but being zero (or even 1 px) wide is not one of their tricks.
-
Interested in hearing from programmers who work remotely.
mje replied to Mike Le's topic in LabVIEW General
Oh, it's hardly nightmarish, it's just the latency of having to track the mouse over a network gets in the way of my normal cadence when coding in LabVIEW. Compare that to a keyboard only environment, where I don't care if there's a fraction of a second delay between when I press the action happens on screen. It's totally usable, but definitely requires a conscious slow down when working over a network. For anything beyond trivial edits while debugging, I revert to the local machine and resync when done so productivity doesn't suffer. -
Interested in hearing from programmers who work remotely.
mje replied to Mike Le's topic in LabVIEW General
It should be pointed out if you're doing any remote coding that the LabVIEW IDE requires a bit more finesse over a remote desktop connection since it's (obviously) more graphic based than other languages. Ideally its best to keep your code development local and just drop the final product onto the remote machine, but If you need run a debugging session remotely because of an interface to some piece of hardware, you're probably going to grow annoyed. I have to do this from time to time, and usually do one of two things: open the code remotely, probe and take notes, then go back to my local machine to modify the code, commit/build/whatever then finally update the remote copy and iterate as need be. Or code in a plethora of debugging displays into your application so you can just distribute it and have access to as much debug info as needed. -
Negative, that will only work if the chart is set to sweep mode and the chart is full since the scale maximum value doesn't necessarily correspond to the last used x-value. I've attached a VI that demonstrates the behavior I'm after. Note "Method 2" does exactly what I want to do, it just seems redundant to have to duplicate this state information, so I'm wondering if there's a better way? Chart Reset.vi (LV 2012 SP1)
-
I'm stumped here. I have a situation where at run time I need to wipe a chart's history clean and start it anew, but I want all future updates to appear continuous with the x-scale established by previous updates. Basically I need to empty the history array and set an appropriate offset value to the x scale such that all future points are measured relative to my new origin, all the while preserving the existing scale's range. Problem is I can't figure out how to get the last x-value used when only given a chart's refnum. The x scale offset and multiplier properties seem like they would help, but the problem is once the chart history is exhausted, the offset value is never updated. Hence the Offset + Multiplier * History.Length formula only works up until the point the history begins to roll around, after which the calculation returns a constant value. I can't assume the scale's range property reflects the last possible element either...the chart could be in the process of "filling" up rather than scrolling, never mind how the update mode is configured. Surely there's a way of determining the last x value from a chart refnum? I mean the chart needs to either be aware of it or be able to calculate it to render properly, am I blind or is this value not accessible? Note: I know I can get this functioning by using my own counter for number of updates the chart has seen instead of using the length of the history array, but it seems ridiculous to have to carry around duplicate state data like this. Surely I'm missing some obvious property?
-
I don't see any technical barrier to doing this. Stylistically I'd argue to look at a different way. I have a general aversion to using features/constructs/widgets clearly outside of their intended purpose. For me VI descriptions are the singular most important piece of documentation a VI can have that is guaranteed to always come along for the ride. Using it to provide end user visible text is not at all what I think any LabVIEW programmer would expect.
-
So I finally had time to play more with Feedly, this time on the PC. I like it now, it just seems the Android app is a little limited/unintuitive as far as feed management goes. Now that I have things set up the way I expect I like it. I really like being able to drop related feeds into a category, then browse the category as a whole or look at individual feeds. I dislike that the PC version isn't just a webpage and that I need to have a browser extension to use it-- one that runs in the background even after I close out all Chrome windows. Final verdict is it's an aesthetically beautiful application but I'm not too impressed with the intuitiveness or some of the core decisions they've made. Undecided if it'll stick for the long term.
-
I'm also disappointed Reader is going away. My two requirements are synchronization across devices and looking at a single feed at a time, so nothing Yair didn't cover. Tried Feedly. We'll designed app but fails my requirements. Haven't gotten around to trying others yet.
-
Waveform chart X scale not matching time correctly
mje replied to patufet_99's topic in Application Design & Architecture
Thank you! -
Waveform chart X scale not matching time correctly
mje replied to patufet_99's topic in Application Design & Architecture
Patufet, did NI give you have a CAR number for this bug? I've seen my horizontal scale falling out of sync with the data and grid (as posted here) and think the issue you posted could be related. I'm looking to track this defect in future releases. -
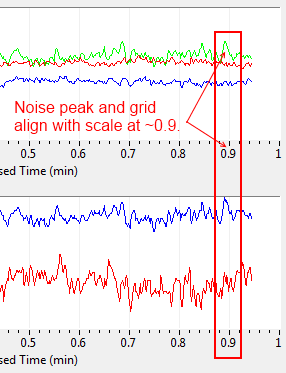
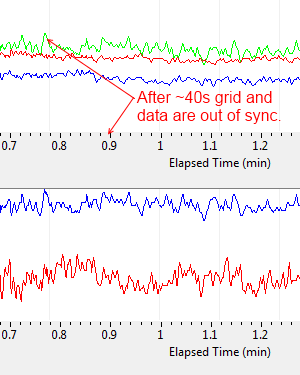
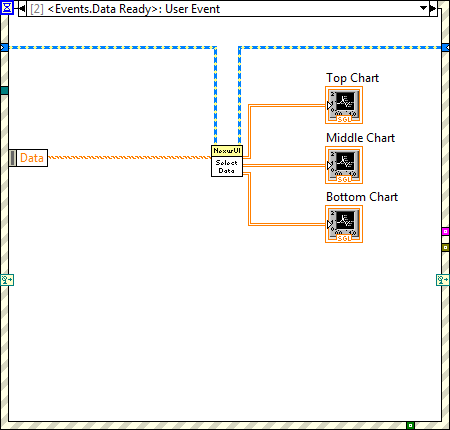
Have any of you ever seen behavior like this? I have a series of charts which as far as I can tell plot data normally if they're not scrolling, but once the horizontal axis begins to move, the data and grid lose synchronization with the scale. For example, at first I have charts that look like this: Notice how the noise spike is approximately at the 0.9 minute mark on the horizontal axis. However after about 40 seconds, the scale is no longer aligned with the grid and data. Note the grid does follow the data. The behavior is perhaps better visualized in a video. The code that updates the charts is really simple, I'm not fidgeting with property nodes or anything: The VI in the middle simply extracts relevant data from the Data object that comes in as event data. The blue wire only contains state information so the the UI knows which data to extract to each chart, it doesn't contain refnums or anything like that which get operated on when the chart is updated. Any ideas? m
-
parent class wants to be saved after creating child
mje replied to John Lokanis's topic in Object-Oriented Programming
Well done on defining a case that causes this. I wonder if it can be reproduced with an example project? I've seen this many times over the years but never been able to pin it down to a case that I could post or even ship off to NI. This and similar behavior continue to cause us enough grief with source code control that I still can't fathom working on LabVIEW projects with more than a very small team of developers.