ShaunR
-
Posts
5,020 -
Joined
-
Days Won
312
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
I sit firmly on the other side of the fence with things like this. When it's a choice between form over function; function wins - especially if the spec can be interpreted ambiguously via tortured semantics. Adhering to specs by observing a strict negative of a positive statement (it doesn't say they cannot be ordered, rather, I expect it was stated thus so it didn't restrict) is why the native 2013 JSON is inferior (IMHO) to this library - speed aside. This library works when the native one throws errors because the native one adheres even more strictly, word for word, to the spec. inf and NAN are examples of where some libraries have implemented function over form. In that case, it was in spite of the spec which specifically disallowed it. There is precedence here if there is enough benefit. Would it really hurt that much to make the output look exactly like the input which is what we all kind of expect and know to be right? Relying on a specs throw away description about an unordered list seems a bit of a cop out to me and it would probably make testing much easier and simpler as you could do a straight input/output compare. It wouldn't break existing code, either. So I'm not sure what the resistance is apart from the effort required which has already been done.
-
 Oh, I don't know. I think we appreciate it here but condemn most of these things because NI will do something about it now they know for sure it's been compromised
Oh, I don't know. I think we appreciate it here but condemn most of these things because NI will do something about it now they know for sure it's been compromised -
REx - Remote Export Framework and Remote Events
ShaunR replied to Norm Kirchner's topic in Application Design & Architecture
Hmmm. I just sat down and attempted to give Rex websocket capabilities since it is already event driven, follows the Open. Write/Read and Close structure and *should* have slotted straight in with a simple wrapper (I'm updating the Websocket API to use HTTPS and thought this would be a great use case). The only issue I found was that there is no background "service", so to speak, that could monitor the TCPIP to generate the events since VI Server methods evoke directly remotely (via the ACBR). Did you add a background VI service, or did you go through the web service interface to get to the users webservice VIs? -
Once the buffer has every point written to, continue writing at buffer[usersize+1] wrapping back around to buffer[0] after buffer[usersize+usersize] is written Nearly.. After i=usersize, you wrap around to buffer[0] all the while writing to buffer and buffer[i+usersize]. Then, if you read at index i for a length usersize, you will get what you need.
-
It doesn't prevent wrap-around from happening. It means that you can read a contiguous array of data at any point in the buffer without having to chop and concatenate.
-
Not so trivial in native labview since to read contiguous bytes using the array subset, you need to split and wrap the array by making copies and sewing them together again. You'll be lucky of it doesn't get a lot slower than a rotate. There is one that uses direct calls to the LV memory manager though, but a rotate is much easier.
-
No and you can't (nor should you want to) LabVIEW Threading Model. For a detailed technical description see section 9.7 of this document
-
I would suggest you look into SQLite.There are a couple of LabVIEW libraries for it and you will be able to query the remote database and update your local (on-disk) one and pretty much run the same queries on it as you would do remotely. Really, though. It is an infrastructure problem, not a programming one. Your IT department should be offering you solutions rather than passing the buck.
-
I think event refnums are fairly well documented and there was a good presentation by Jack that demonstrated the issues. What is not clear and unintuitive is what happens if you place two event structures and connect them to the same FP control. This is THE rookie mistake, after all, I just wanna add another function to operate in parallel when I press that button, right?
-
How to keep track of multiple UI control references
ShaunR replied to doradorachan's topic in User Interface
Now you know how to make all your string controls/indicators URL aware without faffing around with xControls or cluttering up yer main diagram -
How to keep track of multiple UI control references
ShaunR replied to doradorachan's topic in User Interface
I'm rather fond of applying behaviours en masse via callbacks. Ctrl CB.zip
- 4 replies
-
- 6
-

-
- control references
- ui references
- (and 1 more)
-
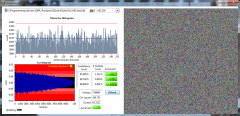
From the album: ShaunR
SQLite database statistical analysis with AES 256 CBC encryption. N.B. 1. Multiple encoding runs produce new database byte-map. - differential analysis resistant. 2. Statistically indistinguishable from random data. - statistical analysis resistant. -
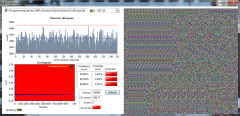
From the album: ShaunR
SQLite database statistical analysis with AES 128 ECB encryption. N.B. 1. Multiple encoding runs produce identical database byte-map - susceptible to differential analysis. 2. Information leakage and correlation especially for zero values - susceptible to statistical analysis.. -
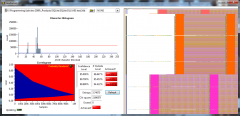
From the album: ShaunR
SQLite database statistical analysis without encryption -
Unwrap Phase VI
-
I can't be the first one to have tried this. XD
ShaunR replied to Sparkette's topic in LabVIEW General
I expect you are. When you program for machines and instruments from the real world. Edge cases of the programming tool are pretty dull -
Not quite since you can only build one "Top Level Vi" according to the Application Builder (so it's not a "hint") and "sub VI" has a definite dependency hierarchy (only appears in the hierarchy window if tied by the diagram) - pedantry prevails! 1. All VIs have front panels and diagrams at design time. 2. What does "Top Level" mean? (top level of application? top level of a hierarchy of other VIs? Top level of a notional design partition?) 3. If one VI calls another VI dynamically then exits, is that called VI a sub vi of the caller that has now exited? Currently, the only unambiguous parlance is that if a VI has another VI on it's diagram, then the VI on the diagram is a sub vi of the VIs diagram. I'm suggesting that if you define "Top Level VI" as being the pinnacle of a stack of VIs tied by its diagram, then everything fits nicely and you don't need all the other nomenclature. You just need to rename what the application builder calls the application entry point (which is currently Top Level VI) and that removes all ambiguity and AQ can name his "Not-Top-Level-Vi" as a "Top Level Vi". That IS simple and can be explained with the VI hierarchy window to the confused.
-
Possible to dedicate an entire CPU core to software timing?
ShaunR replied to Sparkette's topic in LabVIEW General
I think you are thinking of the myRIO. The myDAQ is A/D IO only and what they used to call Elvis. -
Possible to dedicate an entire CPU core to software timing?
ShaunR replied to Sparkette's topic in LabVIEW General
I believe you can create a counter using the DIO on a MyDaq. If you are doing it as a technical exercise - fine. If it is for a real project then I would just get a USB to serial cable and be done with it -
SubVI is the term since the "Top Level VI" is descriptive of a pyramidal hierarchy and the expectation is for all other VIs to be SubVIs of this. Historically Top Level VI has been the equivalent of "Main" in other languages and is a monolithic application viewpoint. If we view this as a tree, it seems clearer where you question arises from. Classical labview hierarchy terminology basically defines the hierarchy tree as being: Root = Top Level VI (Singular) Node = Sub VIs. and you are saying "but yes, we also have these other sub VIs that are more cohesive than other sub VIs so lets have" Root = Top Level VI (Singular) Leaf = Non-Top-Level Node = Sub VIs. In this case, I suppose you could call them "Leaf VIs" or "Subordinate" VIs or lemons but it isn't really clear what they are or how they differ from Root and Node. However I don't consider a "Top Level Vi" to really be the top level of the application. Rather, the Top Level of a module, process and/or grouping and I tend to talk in terms of a hierarchy tree where Root = Root VI, Leaf = Top Level VIs (not singular) Node = Sub VIs. Here, the Root is just an entry point so can be a Top Level VI, a dynamic launcher or the IDE and there is no need for a notional distinction between sub VIs and non-top-level VIs since it is already understood that a top level VI is the pinnacle of a hierarchy of sub VIs, but Root VI is the pinnacle of the application. My though process
-
According to the spec 13 bit is the resolution, not the data format. If you want to get sense out of the raw 13 bit register, I think you will need to calculate it via the following formula if its not already done for you. g = (register_value-4096) * 0.00390625 where the "register_value" is the UINT16 provided by your high and low bytes. That should map the 13 bit register onto the +16 to -16 g range..
-
It's a gift. Or at least you should look at it like that. I call it the Aura of Technical Doom - an innate ability to break anything technical sometimes just by mere presence. If you are a quality engineer with this special power, you are feared by corner-cutting engineers far and wide. These special people are also the bane of demonstrations and usually illicit the phrase "it was working earlier" from other engineers and sales people
-
Confirmed. Introduced in LV 2013 and doesn't affect LV 64 bit...
-
I have seen something eerily similar as it rings a lot of bells, but it was quite a while ago now so it's a bit fuzzy as to the exact symptoms I saw. It was down to a full path of the class in an lvlib instead of a relative one. It may also have had the same in the class itself for a couple of methods; like I said, it is a bit fuzzy Once I manually edited the full path to a relative one, the problem went away. Might be worth seeing if you have something similar. It's easy to spot using a text editor
-
That's because the first VI is his virus payload delivery VI It might have created a directory somewhere with a load of picture control files in it before disappearing (if you are lucky) or it may have uploaded pictures of your partner to facebook along with escort details . You should always open individual VIs in a project,when you don't know what they are. Then they won't run when opened and you can inspect the diagram.