LogMAN
-
Posts
720 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by LogMAN
-
I'm not familiar with FPGAs so this might not work, but there is a Timed Loop in LabVIEW: https://www.ni.com/docs/en-US/bundle/labview-api-ref/page/structures/timed-loop.html Edit: Just noticed this note in the article linked above: This might be relevant too: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z000000P8sWSAS&l=en-US
-
Yes! It is so much better now. Excellent work!

-
Unfortunately, it seems that the site upgrade did not fix the spam issue. Are there any new options at your disposal?
-
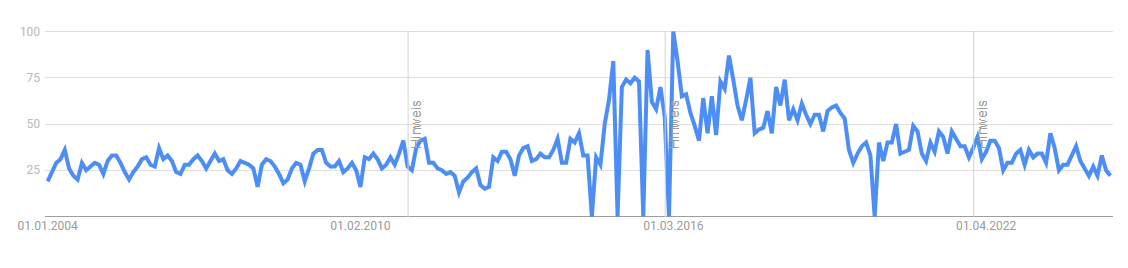
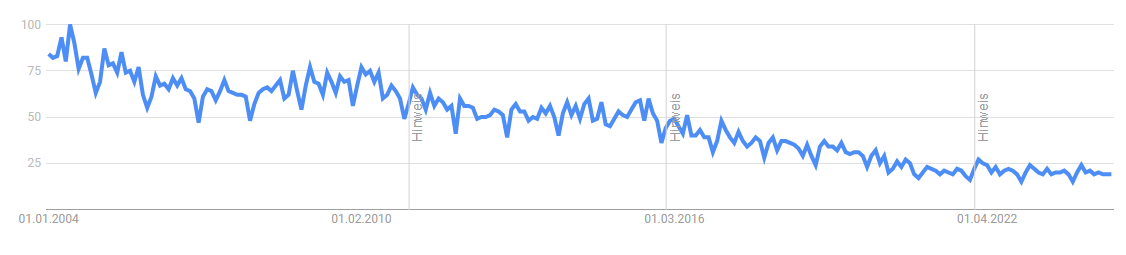
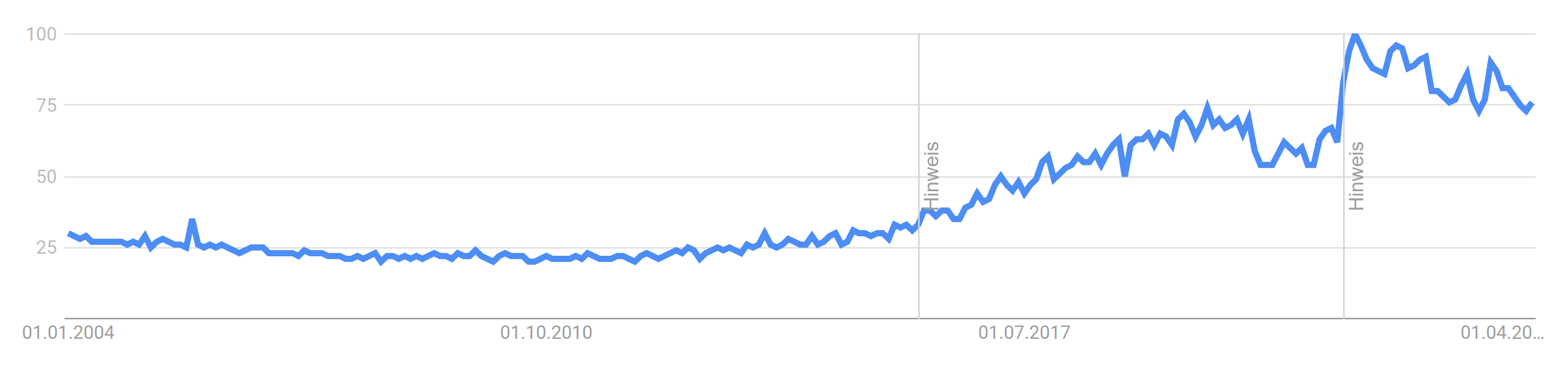
Completely agree. I wonder how the number of people with internet access affect the data. In the past the percentage of technology-agnostic people was probably higher on average than nowadays. Especially for niche topics like LabVIEW. It also makes a difference whether you look at global data or just a specific area. For example, interest for LabVIEW in China and USA are somewhat distinct: China USA There are also distinct changes to the slope when Google decides to improve their categorization systems. We may also see a sudden decline for languages with the adoption of AI assistants as most developers don't need to search the internet anymore and instead rely on the answers produced by the Copilot integrated in their IDEs. Maybe this is what's happening to the Python chart?
-
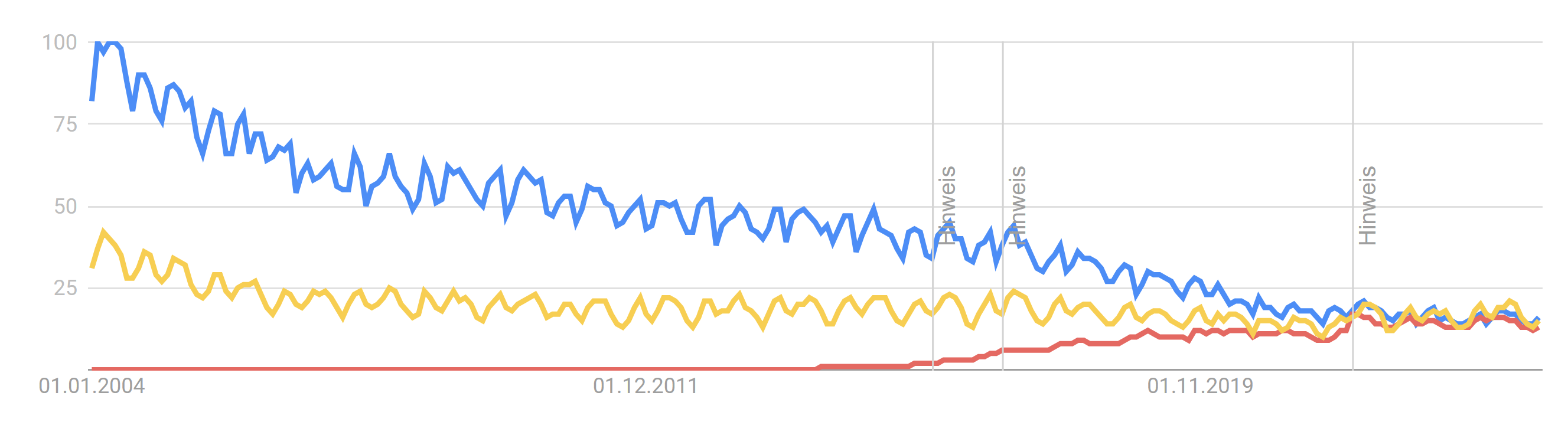
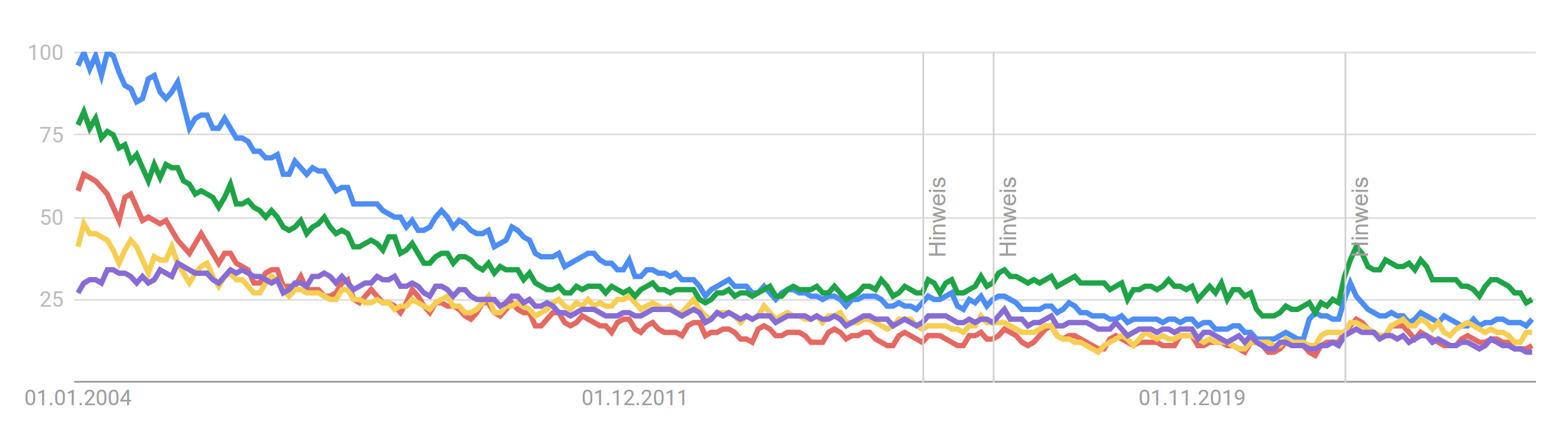
These statistics can be very misleading as they show interest over time and cannot easily be compared. For example, this is a comparison between LabVIEW (blue), Simulink (yellow), and Node-RED (red): Here is another comparison between PHP (blue), C++ (red), C (yellow), JavaScript (green), and C# (purple): Relatively, each of these languages shows considerable less interest over time and converge towards a similar value. Unfortunately, we can't get the full picture as we do not have earlier data. Otherwise, it would probably show pretty much the same curve as Python does. We are just further along the curve (the hype is over 🙁). For the sake of completeness, this is the graph for Python: While everyone is clearly interested in Python, this doesn't mean that any of the other languages is suddenly going to be obsolete or non-functional. People (and businesses) will always follow the hype train, of course. Though, we should certainly not fall victim to ignorance as clearly the LabVIEW community is not quite as enthusiastic as it used to be. I wonder if we should pitch a Python port of LabVIEW to NI... 😈
-
Oh that's hilarious 🤣
-
Well, yes. There is only so much we can do on the client side. It also appears that some of the bots have recently figured out how to reply to their own posts. It is probably just a matter of time before our notification areas get bombarded...
-
I have opted to custom uBlock filters for certain keywords and specific user accounts to hide those entries from the activity stream. Not a perfect solution but it makes the page somewhat usable... at least I don't have to see that wall of crap all the time.
-
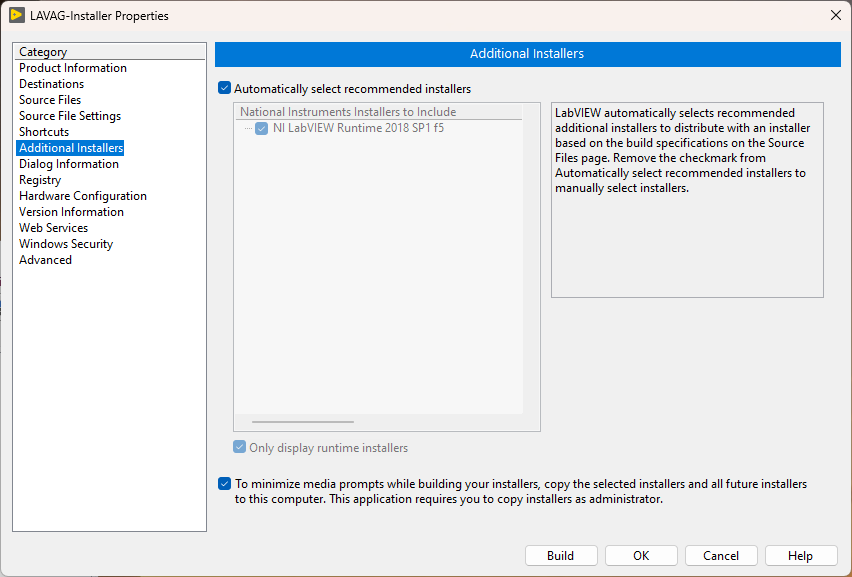
 I can confirm that LabVIEW 2018 SP1 f4 (32-bit) automatically selects LabVIEW Runtime 2018 SP1 f5 when "automatically select recommended installers" is checked and LabVIEW Runtime 2018 SP1 f5 is installed. Though, it does not ask for the installer source. There used to be SFX installers that were extracted to "C:\National Instruments Downloads". When such an installer was used, the destination folder must not be deleted as it is used as a source location when creating installers in LabVIEW. Perhaps you installed the runtime engine through an old SFX installer and deleted those files at some point?
I can confirm that LabVIEW 2018 SP1 f4 (32-bit) automatically selects LabVIEW Runtime 2018 SP1 f5 when "automatically select recommended installers" is checked and LabVIEW Runtime 2018 SP1 f5 is installed. Though, it does not ask for the installer source. There used to be SFX installers that were extracted to "C:\National Instruments Downloads". When such an installer was used, the destination folder must not be deleted as it is used as a source location when creating installers in LabVIEW. Perhaps you installed the runtime engine through an old SFX installer and deleted those files at some point?
-
Spoiler: don't do that on the weekend 😭
-
Well, it makes one feel so professional. Though, commit signing is probably not enforced, right? Perhaps you can get together with this person and discuss a setup that works for all parties? Even if the person does not integrate with Python, it may only be a matter of time. It also gives the argument more weight, especially if it hinders your progress and reduces productivity. One suggestion would be to enable commit hooks only for the main branch. That way the team responsible for merging PRs may take the honor of running said tools and maintain code quality throughout the repository. If you are using any of the typical systems to host and manage your repositories (e.g., GitHub, GitLab, etc.) they can squash and rebase on merge with the click of a button, which is typically less error prone than doing it locally through the command line. Of course, merge conflicts still need to be resolved locally. Or scare them 😇
-
Considering that git has been the de-facto standard for source control for years, there is simply no way avoiding it anymore. I presume you are not the one who setup this nightmare. As someone who has worked with repositories on both ends of the spectrum, my general advise is to avoid nested repositories, pre-commit hooks and overly complex pull-request strategies unless all members of the team are intimate familiar with the workflow and understand the implications (which is pretty much never the case). If you have some control over the process, I suggest rethinking the strategy. Here are a few pointers: Use simple repositories (no commit hooks, no special features, no enforced rules, just a repo) It all starts with "git init" -- no more, no less. Create a single-page document with all the necessary git commands (5-10 at most). It should include the initial setup of user name and email, cloning, committing, pushing, pulling, branching, and merging. => search "git cheat sheet" for some examples (ignore all the stuff you don't need) If you are eager to keep the history clear of merge commits, then rebasing should be included. But it might require some assistance when there are merge conflicts (if it's too complex, just don't use it) If you have a team member who is experienced with git, they should be available to help users with topics like rewriting history, stashing, fixing, etc. (it's not needed 99.9% of times that people think they need it) -- they should also have a positive attitude, access to the coffee machine, and preferably some sweets to keep morale up 😉 Avoid squashing and all the shenanigans. Instead, emphasize (but do not enforce) good commit habits (write useful commit messages, etc.). Document your guidelines and tooling. Do not enforce them with commit hooks! Keep it as short and concise as possible Avoid documenting industry standards (makes the document annoying to read and unnecessarily long) Tools like black and flake8 should be called manually when the developer finds it necessary and convenient. More advanced git users can make their own private commit hooks to automate the process if they are eager to suffer. Don't be afraid to commit Don't be afraid to commit "ugly" code (it can always be cleaned up with another commit) Most importantly: think of your team as colleagues that work towards a common goal and not as inmates that must be forced to do thy bidding. In case that you are familiar with TortoiseSVN, then TortoiseGit may be interesting to you. Though, the command line is where git shines.
-
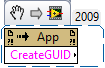
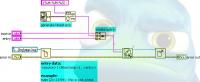
Good stuff! LabVIEW also has a private built-in method "CreateGUID", which is available from at least LV2009. It was probably also available in earlier versions. Create GUID.vi
-
It is defined in mine: Edit: I believe it is also defined in the product documentation but NI's website is down again.
-
Thanks for keeping up the fight! I don't even want to imagine your inbox on a Monday...
-
There is an option in your profile settings to disable individual blocks on the profile page. Perhaps it was disabled on the accounts you checked. Yeah that's a good idea. It appears that some visitors/guests find their ways through search engines, but if anyone is asking questions there is just no way to see them through all the spam. I'd be happy to help block spammers but the way it is now just isn't sustainable and makes the site literally unusable. I hope Michael intervenes soon while it is still manageable.
-
You mean this? It's still visible for me.
-
While that may be true, the current spam posts are clearly not using any advanced technologies like that. At the very least, enabling captchas will force them to invest much more processing power to solve them, which either reduces the number of posts they can send, or discourages them from pursuing it any further. In conjunction with IP blocking, this can be very effective against these kinds of script kiddies. Second that!
-
Since user creation is disabled anyways, this should sufficiently prevent any spam posts from being displayed to regular users. Although, it probably will flood the moderator inbox. Perhaps CAPTCHA could be a viable option? Especially for newly created posts like the ones currently being spammed. Not sure if there are options to require CAPTCHA for new users and relax the requirement for users of higher ranks, but that could be something worth looking into.
-
Sounds good 👍
-
Thanks again for taking care of the mess! Is it easier if we report every spam account or does it only put more spam in your inbox?
-
They apparently took that as a challenge. Quick! We need stronger memes!
-
-
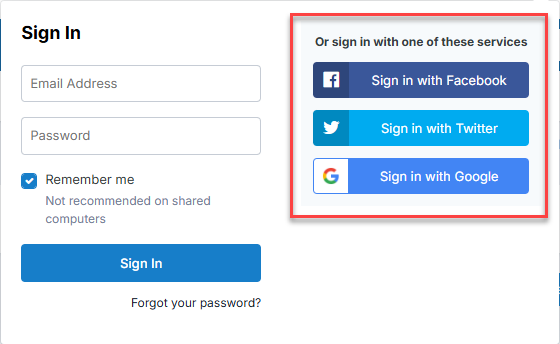
It appears that, although registration is disabled, social sign-in is still possible and allows for account creation (even if registration is disabled). For example, Twitter - Social Sign In - Invision Community. Maybe turning those off will put us in a walled garden 🤔
-
Why doesnt TCP listen listen to my IP address
LogMAN replied to govindsankarmr's topic in LabVIEW General
Did you unblock the port in your firewall settings to allow inbound connections from the client?