LogMAN
-
Posts
720 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by LogMAN
-

Malleable Buffer (seeing what VIMs can do)
LogMAN replied to drjdpowell's topic in Code In-Development
It appears to be working when unchecking the "Remove unused polymorphic VI instances" option in the build specification. Not sure why because the library does not seem to include any polymorphic VIs 🤔 -
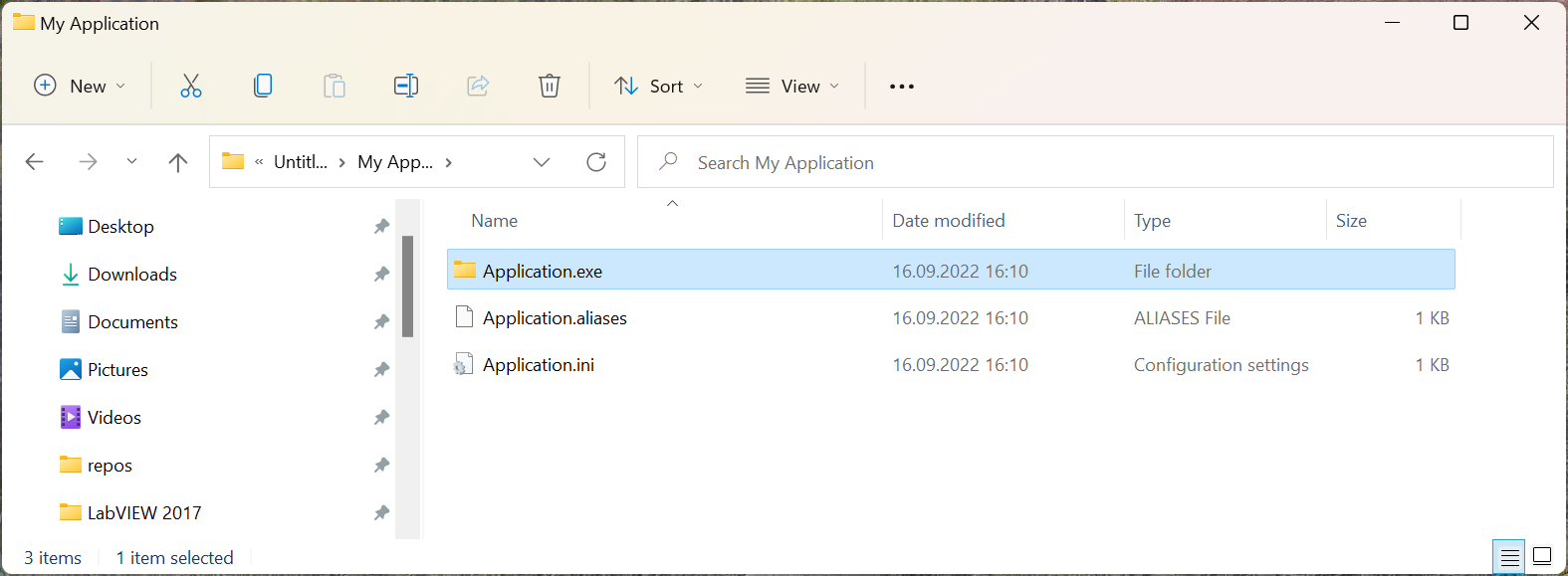
The latter. Just like @hooovahh explained, the files are copied to a temporary location which can result in longer paths. The output directory for your application determines the location of the temporary folder, which is actually just the name of the executable as a folder (i.e. "Application.exe" but it's a folder). EDIT: Regarding vi.lib, these files also reside inside the "Application.exe" folder. Here is an example for JSONtext: "C:\Code\Repository\builds\Untitled Project 1\My Application\Application.exe\1abvi3w\vi.lib\JDP Science\JSONtext\LVClass Serializer" Here is an example of what it looks like during build.

-
This error happens when one of the files exceeds the maximum path length of 256 characters on Windows. While the file path can be short enough in your source repository, it might exceed the maximum path length during build. Find attached a VI that extracts the longest path in a folder. Point it to the working directory of your project and see how long the longest path is. Find Longest Path.vi
-
Download link for OpenG library compatible with LabVIEW 7.1
LogMAN replied to KumarB's topic in OpenG General Discussions
This is not the right place to ask for legal advice. You should read the license terms and check with your legal department. Here is a link to the full license text for version 2.1 of the license: GNU Lesser General Public License v2.1 | Choose a License -
-
-
To what end? NI will never go back to perpetual licenses, no matter how many offers we reject. Mainstream support for LabVIEW 2021 ends in August 2025, which means no driver support, no updates, and no bug fixes. By then you should have a long-term strategy and either pay for subscriptions or stop using LabVIEW. As a side note, if you own a perpetual license you can get up to 3 years of subscription for the price of your current SSP. This should give you enough time to figure out your long-term strategy and convince management Of course, if you let your SSP expire and are later forced to upgrade, than you have to pay the full price...
-
Issues with PostgreSQL and packed libraries
LogMAN replied to Dpeter's topic in Database and File IO
You cannot directly create PPLs from classes. Instead, put the class inside a project library to create a PPL. -
Powered by LabVIEW NXG 😋
-
Using the DLL files of an application compiled with C# with labview
LogMAN replied to alvise's topic in LabVIEW General
In C#/.NET, memory usage can fluctuate because of garbage collection. Objects that aren't used anymore can stay in memory until the garbage collector releases them. https://docs.microsoft.com/en-us/dotnet/standard/garbage-collection/ This could explain why your memory usage goes up and down. There is a way to invoke the garbage collector explicitly by calling GC.Collect(). This will cause the garbage collector to release unused objects.
-
Don't tell him about Excel...
-
-
No subscription = no money = no support I believe this is the case for most software products.
-
You need an active subscription to download previous versions. This has been the case for many years.
-
Welcome to LAVA @jorgecat 🏆 As a matter of fact, there can be two files depending when you installed NIPM for the first time. \%programdata%\National Instruments\NI Package Manager\Packages\nipkg.ini \%localappdata%\National Instruments\NI Package Manager\nipkg.ini According to this article, the location changed from %programdata% to %localappdata% in later versions of NIPM but both locations are still supported.
-
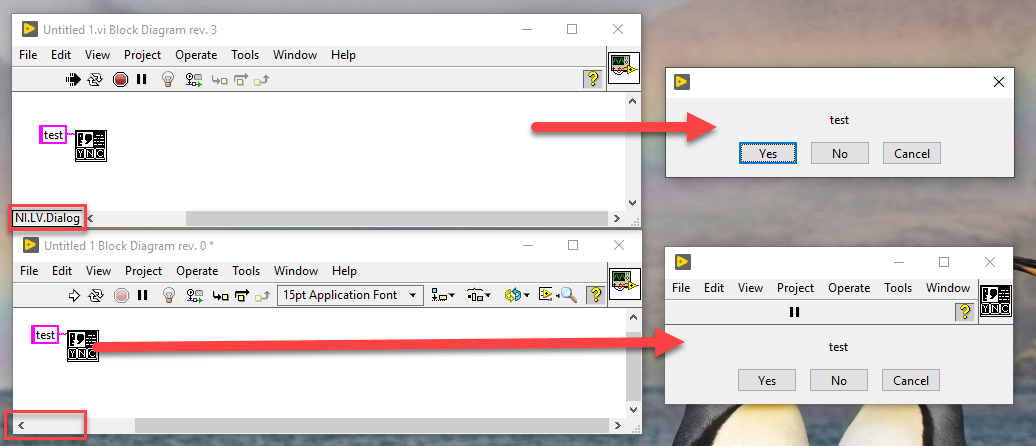
By any chance, is your main VI launched in a different application context (i.e. from the tools menu or custom context)? Here is an example where the dialog is called from the tools menu (top) while the front panel is open in standard context (bottom).
-
Porting LabVIEW code to another language
LogMAN replied to infinitenothing's topic in LabVIEW General
Good question. There are different kinds of prototypes that serve different purposes. The one I'm referring to is a throwaway prototype. It serves as a training ground to try out a new architecture and/or refine requirements early in the process. The entire point of this kind of prototype is to build it fast, learn from it, then throw it away and build a better version with the knowledge gained. -
Porting LabVIEW code to another language
LogMAN replied to infinitenothing's topic in LabVIEW General
Even without porting to a different language, a small prototype is a good idea if you aren't sure about your architecture. That way you can test your ideas early in the project and refine it before you begin the actual project. Just don't forget to throw away the prototype before it gets too useful 😉 -
Porting LabVIEW code to another language
LogMAN replied to infinitenothing's topic in LabVIEW General
I had to do that once. Moved from LV to C++ A translation doesn't make sense as many concepts don't transfer well between languages, so it was rewritten from scratch. It's actually funny to see how simple things become complex and vice versa as you try to map your architecture to a different language. I assume by "done" you mean feature parity. We approached it as any other software project. First build a MVP and then iterate with new features and bug fixes. We also provided an upgrade path to ensure that customers could upgrade seamlessly (with minimal changes) and made feature parity a high priority. The end result is naturally less buggy as we didn't bother to rewrite bugs 😉 It certainly took a while to get all features implemented but reliability was never a concern. We made our test cases as thorough as possible to ensure that it performs at least as well as the previous software. There is no point in rewriting software if the end result is the same (or even worse) than its predecessor. That would just be a waste of money and developer time. -
Perhaps consider using separate Hardware Configuration classes instead of JSON strings. That way your Hardware classes are independent of the configuration storage format (which may change in the future). All of your Hardware Configuration classes could inherit from a base class that is then cast by each Hardware at runtime. Sounds reasonable. From what you describe, it sounds more like a registry than a manager. Could you imagine using a Map instead? Your hardware manager also has a lot of responsibilities. First of all, it should not be responsible for creating classes. This should be responsibility of a factory (Hardware Factory). If you want to load classes on-demand, then the factory should be passes to the manager. Otherwise, the factory should create all classes once on startup and pass the instances to the manager. It also sounds as if the Hardware Factory should receive the configuration data. In this case, the configuration data could be a separate class or a simple cluster. In either case, the factory should not be responsible for loading the data (for the same reason as for the Hardware above). A proxy could be useful here (a class that forwards calls to another class). In this case, "Kiethley DMM with a built-in switch card" could be passed directly to one of your operations. In the the case of "Kiethley DMM and a NI switch card", however, a proxy could hold the specific hardware instances and forward all calls to the appropriate hardware. You can load a class from disk and cast it to a specific type. See Factory pattern - LabVIEW Wiki for more details.
-
I suspect they did another one of their "approaches" and hired more consultants to completely miss the point... This is really sad and I fail to see how any of this makes LabVIEW a better product and not just more expensive to their current user base. Responses like this are also a good reason to seek alternatives. NI has made it clear for quite some time that LabVIEW is only an afterthought to their vision. Instead they are building new products to replace the need for LabVIEW ("it's not the only tool"). Customers will eventually use those products over writing their own solutions in LabVIEW, which means more business for NI and a weak argument for LabVIEW. In my opinion, higher prices are also a result of balancing cross-subsidization. In the past, other products likely added to the funds for LabVIEW development in order to drive business. With more and more products replacing the need for LabVIEW, these funds are no longer available. Eventually, when there are not enough customers to fund development, they will pull the plug and sunset the product. On the bright side, they might gain a large enough user base to invest in the long-term development of LabVIEW. They might listen to the needs of their users and improve its strengths and get rid if its weaknesses. They might make it a product that many engineers are looking forward to use and who can't await the next major release to engineer ambitiously I hope for the latter and prepare for the former.
-
Here is a video that showcases a logic designed by NI. It counts the number of iterations since the last state change and triggers when a threshold is reached.
-
My system is to put them in project libraries or classes and change the scope to private if possible. Anything private that only serves as a wrapper can then easily be replaced by its content (for example, private accessors that only bundle/unbundle the private data cluster). Classes that expose all elements of their private data cluster can also be refactored into project libraries with simple clusters, which gets rid of all the accessors. Last but not least, VI Analyzer and the 'Find Items with No Callers' option are very useful to detect unused and dead code. Especially after refactoring. What do you mean by "very little"? The 'Add' function does very little but it is very useful. If you have lots of VIs like that, your code should be very readable no matter the number of VIs.
-
You can find a lot of information on the type descriptor help page. The LabVIEW Wiki also has a comprehensive list of all known type and refnum descriptors. Feel free to add more details as you discover them 🙂 That said, I would use Get Type Information over type string analysis whenever possible. It's much easier and less error prone. A great example of this is the JSONtext library, which utilizes the type palette a lot.
-
The answer is in the title. NI will stop selling perpetual licenses by the end of this year. Any licenses renewed before that date will continue until they expire, after which NI will offer subscription-based licenses.