LogMAN
-
Posts
720 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by LogMAN
-
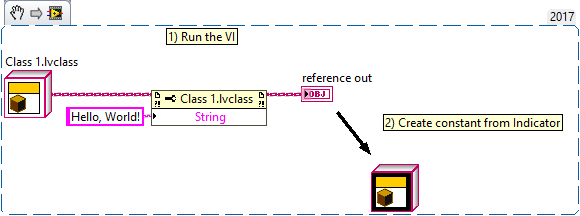
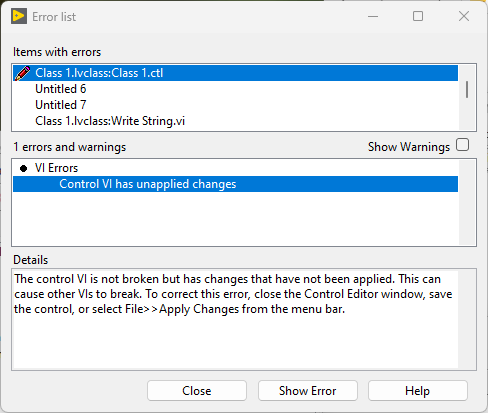
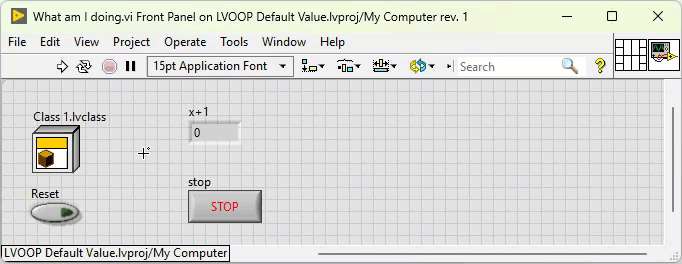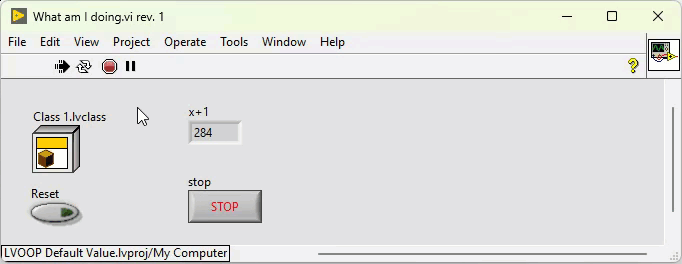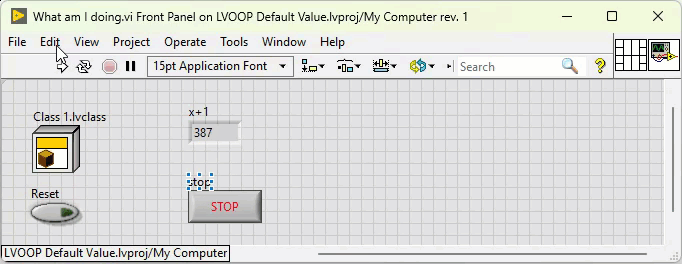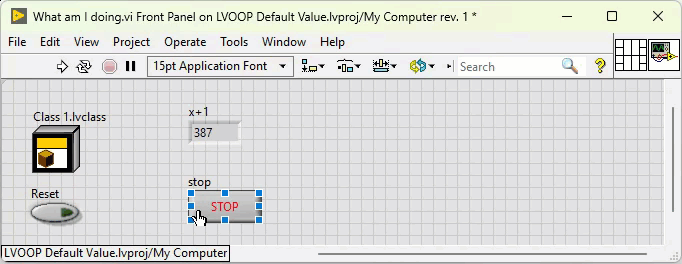
Class constants and controls have black background when they contain non-default values: Class constants (and controls) always have the default value of their private data control unless you explicitly create a non-standard constant like in the example above. It is updated every time the private data control is changed. This is why VIs containing the class are broken until the changes to the private data control are applied. That is correct. It does not. The default control does not actually contain a copy of the private data control, but a value to indicate that it returns the class default value. Even if you make this value its default value, it is still just a value that indicates that it returns the class default value. Only when the background turns black, you have to worry. By any chance, do you write values to class controls? This can result in undesired situations when combined with 'Make Current Values Default':

-

How to check if a class is an interface or a concrete?
LogMAN replied to bjustice's topic in LabVIEW General
That is very unlikely. It would turn classes into interfaces, which is a major breaking change. -
How to check if a class is an interface or a concrete?
LogMAN replied to bjustice's topic in LabVIEW General
Not sure about speed, but these VIs use features that aren't available in earlier versions. However, if backwards compatibility isn't an issue, this is probably the most native way to go about it. As for speed, perhaps caching is an option? -
How to check if a class is an interface or a concrete?
LogMAN replied to bjustice's topic in LabVIEW General
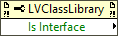
Just in case you are looking for a solution that doesn't have to work in runtime, there is this property for class libraries.
-
How to check if a class is an interface or a concrete?
LogMAN replied to bjustice's topic in LabVIEW General
How fast do you need it to be? Speaking about native solution, there is <vi.lib>\Utility\LVClass\Is Class Not Interface.vi <vi.lib>\Utility\LVClass\Is Class Not Interface Without Loading.vi However, these might not work at runtime. -
How to check if a class is an interface or a concrete?
LogMAN replied to bjustice's topic in LabVIEW General
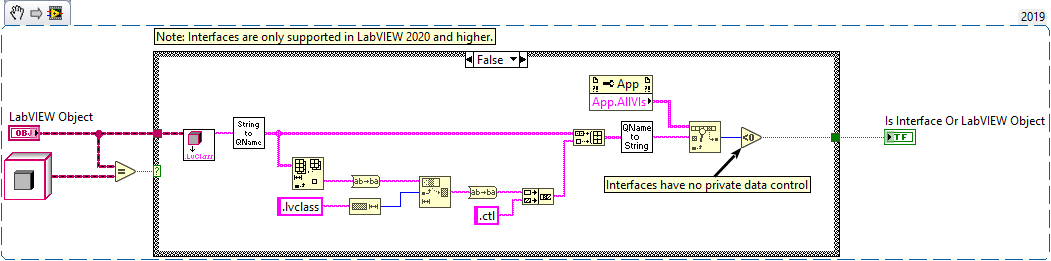
Interfaces have no private data control, which means you can just check if such control exists in memory. The original VI is available on GitHub: https://github.com/logmanoriginal/labview-composition ("Is Interface Or LabVIEW Object.vi")
-
Re-creating the property node should fix the immediate issue, but it may happen again in the future. Does your typedef contain sub-types? Changes to nested typedefs can have the same affect.
-
This can happen when a typedef changes from strict to non-strict or vice versa. In this case, the value returned by the property node will remain strict or non-strict, resulting in a coercion dot. Typedef Coercion.mp4
-
How deep is you inheritance tree?
LogMAN replied to Antoine Chalons's topic in Object-Oriented Programming
Further reading: LabVIEW Interfaces: The Decisions Behind the Design - NI Community -
Crash computeur => erase my configs files
LogMAN replied to Francois Aujard's topic in LabVIEW General
Just checked, my VIs are unprotected in all installed versions (English, 32-bit). They probably auto-protect them during translation. -
Crash computeur => erase my configs files
LogMAN replied to Francois Aujard's topic in LabVIEW General
I got several versions installed on my computer at home, including 2017, 2019, and 2021-2022Q3 and those VIs (at least 2017 and 2019) are unlocked. By any chance, are there differences in the language version installed? -
Crash computeur => erase my configs files
LogMAN replied to Francois Aujard's topic in LabVIEW General
They are unprotected in 2019. Was this changed in later versions? -
How deep is you inheritance tree?
LogMAN replied to Antoine Chalons's topic in Object-Oriented Programming
It's three at the deepest level, not counting LabVIEW Object. The class browser arranges some classes wrong, which makes it look like there are extra levels. -
Crash computeur => erase my configs files
LogMAN replied to Francois Aujard's topic in LabVIEW General
That makes sense. Thanks for clearing that up! A very similar issue happened to me a couple of month ago on multiple stations with broken power supplies. On those stations, the PC would sporadically turn off, sometimes (approx. 1-2 times a month) causing several of our configuration files to contain empty or garbage data (random bytes) after reboot. Those files are only written to at the start of a cycle that takes several minutes to complete. The likelihood of a power failure in that exact moment is very slim at best. On top of that, we currently update configurations sequentially, which means that only one file is open at any given time. However, often multiple files were affected. We never got to the bottom of it, as replacing the power supplies fixed the issue entirely. I'd be happy to know what is causing this issue... -
Crash computeur => erase my configs files
LogMAN replied to Francois Aujard's topic in LabVIEW General
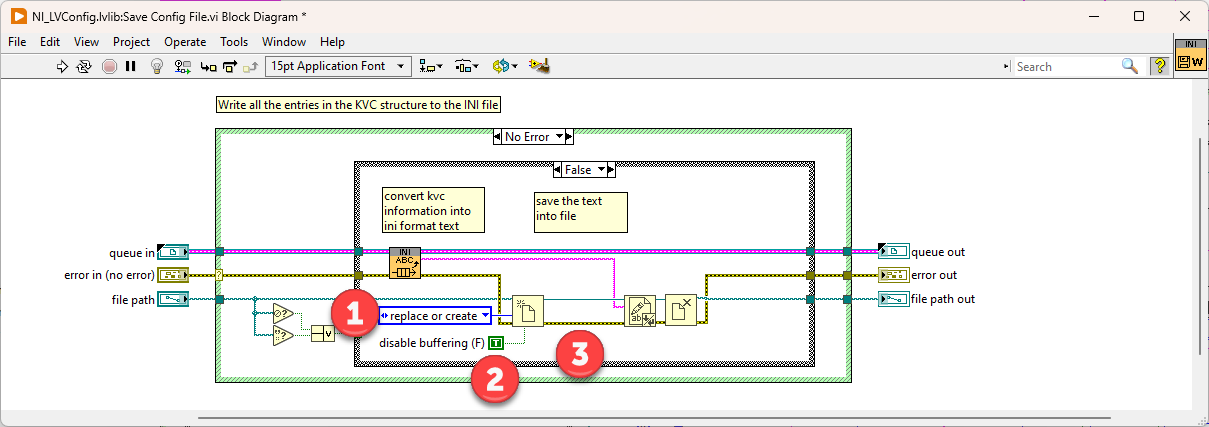
Something like that. The actual implementation takes several factors into account, for example, how frequently a file is accessed. Also, your disk has its own cache on top of that. If you have a virus scanner running, it might lock the file for processing. I believe the Set File Size function is to blame for that. By changing the file size to zero, the file is effectively cleared. The write function after that is cached and never gets flushed to disk because of power failure, which leaves the file empty after reboot. I'm not sure why it was implemented this way. The following will produce the same result without this issue:
-
How deep is you inheritance tree?
LogMAN replied to Antoine Chalons's topic in Object-Oriented Programming
Mine are between 1-3 levels
-
Crash computeur => erase my configs files
LogMAN replied to Francois Aujard's topic in LabVIEW General
Did you try disabling buffering as mentioned in my last post (2)? What do you mean by that? I don't think it makes a difference. If you dynamically call VIs using 'Call and collect' or 'Call and forget', then the 'Request Deallocation' function could free up memory earlier. That said, it is mostly useful when you work with large amounts of data.
-
Crash computeur => erase my configs files
LogMAN replied to Francois Aujard's topic in LabVIEW General
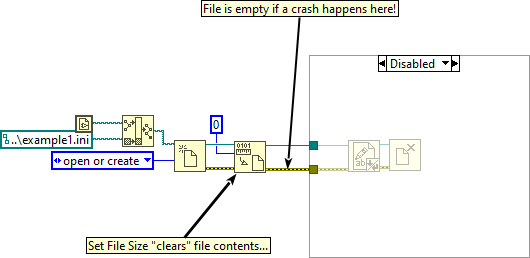
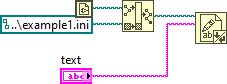
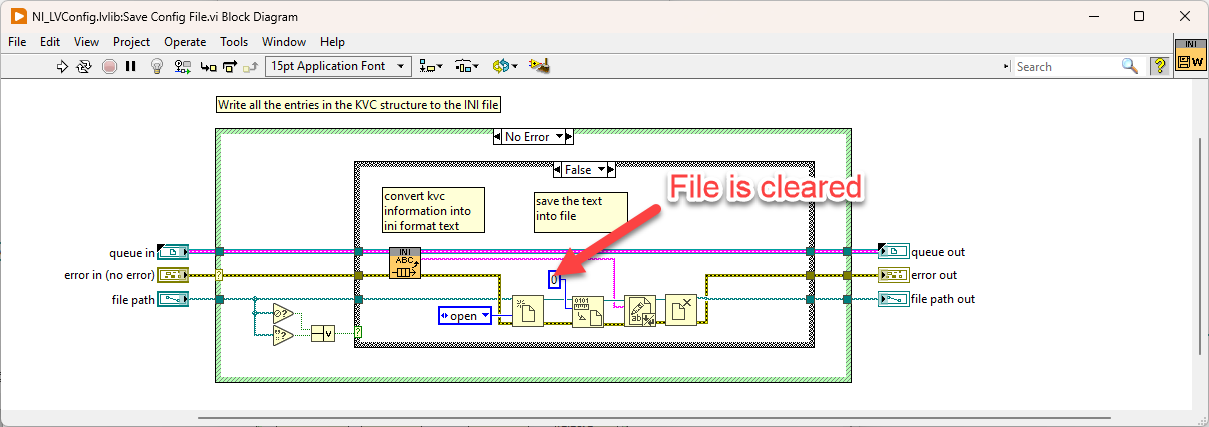
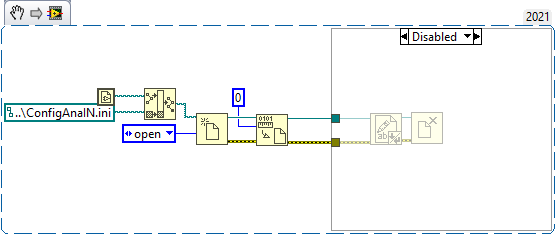
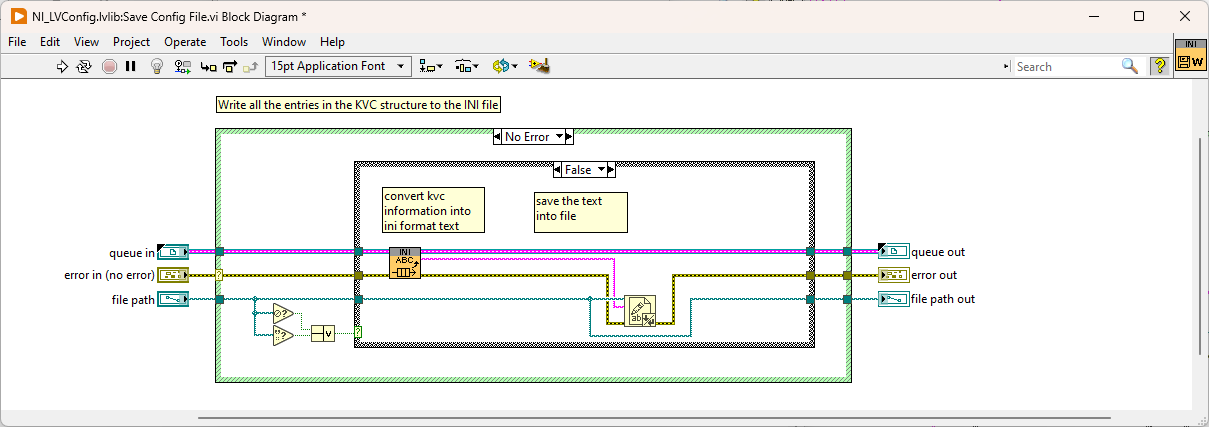
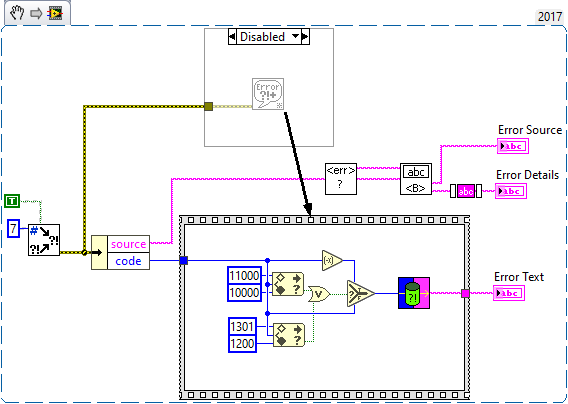
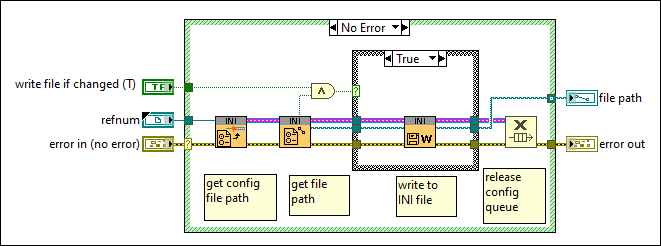
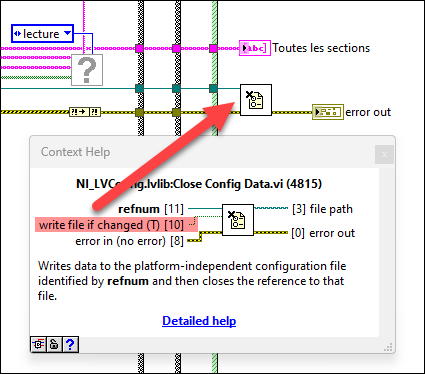
Are both files accessed at the same rate? I'd assume that the one you call more often is more likely to fail. --- Edit: It appears that the configuration file VIs clear the file size before they write new content. If your computer crashes at this moment, it will result in an empty file: Here is what could happen: To prevent this issue, try this: 1 - Use 'replace or create' instead of 'open' 2 - Disable buffering (this will directly write to disk without caching) 3 - Remove 'Set File Size' function Warning: This VI is installed with LabVIEW, so changing it will affect any project on your computer! Alternatively, it is also possible to just write the string to disk without opening the file explicitly. However, in this case caching will be used.
-
Crash computeur => erase my configs files
LogMAN replied to Francois Aujard's topic in LabVIEW General
Mise en cache des fichiers - Win32 apps | Microsoft Learn -
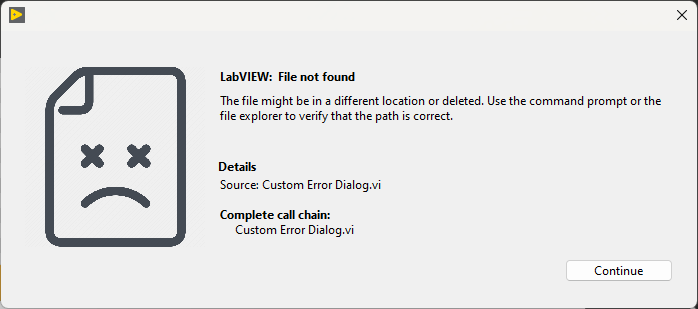
In that case, perhaps you can improve your error message with functions from the General Error Handler VI. It should allow you to achieve what you want. Another idea is to add images for well-known errors (file not found, error 1172, etc.). It helps users recognize issues they encountered before (and perhaps learned to fix on their own). Here is a complete example I just put together (it uses a picture ring for the image): Error Dialog.vi
-
It depends on the kind of error. If the error can be fixed by the user, we typically guide them through the process. In this case the error is handled as part of the regular operation cycle that we designed with the customer. If the error cannot (or should not) be fixed the user, then we typically block the process and wait for authorization by a supervisor. These are errors that we anticipated in the design, but whose root cause is not clear (i.e., failure to connect to hardware). Finally, if the error does not fall into the first two categories, we dump them in a log file and fail the operation with a simple error message like "An unhandled error occurred. Report this issue to your supervisor.". These errors often indicate a bug or a flaw in the original design.
-
Crash computeur => erase my configs files
LogMAN replied to Francois Aujard's topic in LabVIEW General
Does the issue also occur during normal operation or only during a power failure? If the files get cleared during normal operation, then there is probably a bug in your software. Otherwise, fix the power failure. Even if you do not intend to write data to disk, the configuration file VIs use an internal "dirty" flag to determine when data should be written to disk. This "dirty" flag is set to true during write operations. You can prevent it from writing any data using the optional input, but that input is not wired in your VI. This flag may get corrupted during power failure, causing it to write garbage data to disk. Then there is also file caching from the operating system which could play a role in this: https://learn.microsoft.com/en-us/windows/win32/fileio/file-caching
-
Crash computeur => erase my configs files
LogMAN replied to Francois Aujard's topic in LabVIEW General
This can happen when the computer turns off while it writes data to disk. I've had the same issue recently, which was caused by broken power supplies. Fortunately, we do automatic backups of all configurations, so it was an easy fix. Other than that, I don't think there is much you can do about it. A UPS might be a good idea. -
Done 🙂
-
It depends. Sources files link to each other using relative paths, except for items in well-known locations (vi.lib, user.lib, instr.lib, etc.), which are referenced relative to their well-known location. As long as you don't change the relative location of files, nothing changes. This is a side-effect of how the dependency tree is generated. Instead of re-computing linkage information, LabVIEW relies on linkage information that is stored in a VI. So, if you change a typedef and don't apply (and save) all its callers, then the callers will have outdated type information, which can result in "ghost" dependencies. Clearing the compiled object cache and mass-compiling your project should generally fix these issues. There are some exceptions where this doesn't work but let's just hope it doesn't apply here 🙂