LogMAN
-
Posts
720 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by LogMAN
-
Well, technically speaking that should be the case if you take their answer literally (and ignore the rest of the sentence) Most likely, though, it will allow you to use any version listed on the downloads page, which currently goes back to LV2009. You might also be able to activate earlier versions if you still have access to the installer but I'd be surprise if that went back further than perhaps 8.0. Only NI can tell.
-
It looks like the certificate was renewed today. According to the certificate, it is valid from 13/Dec/2021 to 13/Jan/2023. Have you tried clearing your cache? You can clear the cache in most browsers using the key combination <Ctrl> + <F5>. Hope that helps.
-
 Here is a similar post from the CR thread. The reason for this behavior are explained in the post after that. JSONtext essentially transforms the data included in your variant, not the variant itself. So when you transform your array into JSON, the variant contains name and type information. But this information doesn't exist when you go the other way around (you could argue that the name exists, but there is no type information). The variant provided to the From JSON Text function contains essentially a nameless element of type Void. JSONtext has no way to transform the text into anything useful. To my knowledge there is no solution to this. The only idea I have is to read the values as strings, convert them into their respective types and cast them to variant manually.
Here is a similar post from the CR thread. The reason for this behavior are explained in the post after that. JSONtext essentially transforms the data included in your variant, not the variant itself. So when you transform your array into JSON, the variant contains name and type information. But this information doesn't exist when you go the other way around (you could argue that the name exists, but there is no type information). The variant provided to the From JSON Text function contains essentially a nameless element of type Void. JSONtext has no way to transform the text into anything useful. To my knowledge there is no solution to this. The only idea I have is to read the values as strings, convert them into their respective types and cast them to variant manually. -
I don't have any experience with Macs, but there is a topic in the LabVIEW 2021 Beta Forum related to Apple M1 chips: [New Feature] macOS Big Sur Support - NI Community
-
Get Host Name performance issue
LogMAN replied to John Lokanis's topic in Remote Control, Monitoring and the Internet
You can use the shortcut menu on a property node to select the .NET class. The one you are looking for is in the mscorlib assembly. System.Environment.vi
-
Your issue could be related to these topics (I assume "glaring front issue" means blurry): Texts in Icon Editor Get Blurry - National Instruments
-
The best way is to report posts via the three dots in the upper right corner. That way moderators get notified.
-
This is expected behavior: Ensure That Event Structures Handle Events whenever Events Occur - LabVIEW 2018 Help - National Instruments (ni.com) You are probably right about compiler optimization for unreachable code. Changing the compiler optimization level most likely has no effect because it is still unreachable and therefore not included.
-
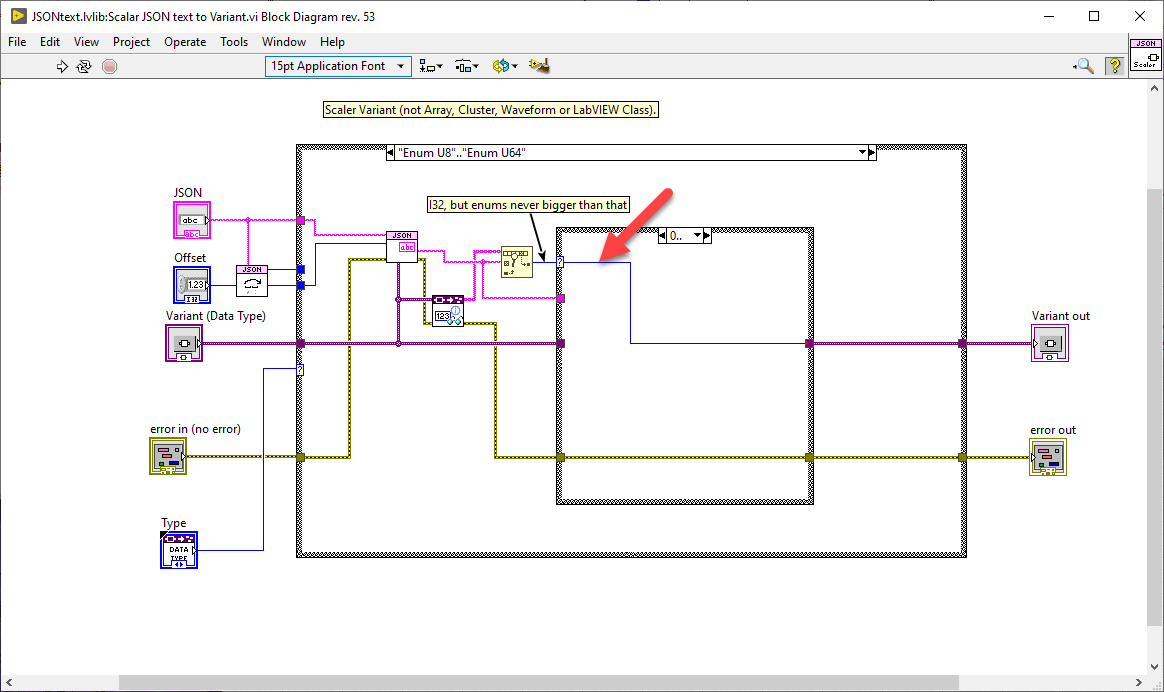
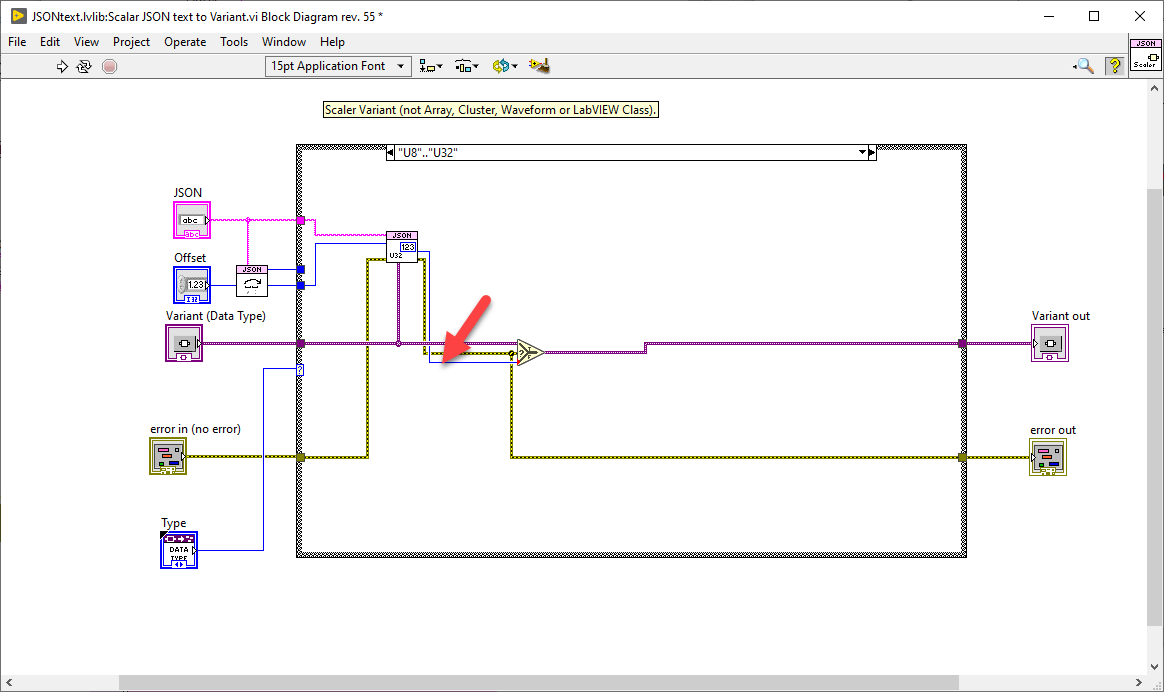
Here is what happens: Scalar JSON text to Variant.vi uses the index output of the Search 1D Array function (I32) for the Enum value (U16). JSON to Map.vi then uses Variant To Flattened String (special).vi to extract the data. Enum U16 has 2 Bytes but I32 has 4 Bytes of data, so the Map data gets offset by 2 Bytes for each Key. Scalar JSON text to Variant.vi uses the output of Get U32.vi for all unsigned integers. JSON to Map.vi then uses Variant To Flattened String (special).vi to extract the data. U16 has 2 Bytes but U32 has 4 Bytes of data, so the Map data gets offset by 2 Bytes for each value. The solution is to cast all values according to their respective types. Here are the two offending sections for your particular case:
-
Thanks for sharing and kudos to everyone involved! I did a few tests with a dummy project and it works like a charm. The fact that it provides all the tooling to automate the process is just mind-blowing. It looks like a very powerful tool to save and restore data, with precise control over data migration and versioning. Also, BlueVariantView - very insightful and handy. Have you ever explored the possibility of manipulating mutation history (i.e. removing older versions)? That could be useful for users with slow editor experience: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z0000015BLnSAM&l=en-US Fair enough. There are always tradeoffs to tools like this. There is one point I would like to address: "Pretty serious security risk. There is no way to protect private data when serializing/de-serializing". Scope is not the same as security. If you want to secure data, encrypt it. If you want to serialize only some data, but not all, this is not a security risk but an architectural challenge. You'll find that the same issue exists for the Flatten To XML function. It requires designing classes such that they include only data you want to serialize. A typical approach is to have separate data objects with no business logic. One point missing in this list is the lack of control over data migration and versioning. My library entirely depends on the ability of JSONtext to de-serialize from JSON. It will fail for breaking changes (i.e. changing the type of an element). Your library provides the means to solve this issue, but it has it's own limitations: There are two points users need to be aware of: When de-serializing, Serialized Text must include "Class" and "Version" data, which makes it difficult to interface with external systems (i.e. RESTful APIs). Classes must inherit from BlueSerializable.lvclass. This could interfere with other frameworks or APIs. What makes your library special is the way it handles version changes. We have been doing something similar with regular project libraries, using disconnected typedefs to migrate data between versions. Being able to do the same thing with our objects is very appealing (up to now we have considered them breaking changes and lived with it). I'll certainly bring this up in our next team meeting. Very cool project. Thanks again for sharing!
-
Git detatched head. All of a sudden this makes sense!
LogMAN replied to Neil Pate's topic in Source Code Control
I should have put a smiley at the end of my sentence 😅 -
Git detatched head. All of a sudden this makes sense!
LogMAN replied to Neil Pate's topic in Source Code Control
A few years ago I worked on a project that required private API keys. To make things easier, I simply created a private branch that had my keys hardcoded. This is one example of a branch that I certainly didn't want to push to a public server. At the same time it allowed me to regularly merge from master at no cost. You could create a custom git hook to push local changes on every commit but you are probably better of with a different VCS. -
Git detatched head. All of a sudden this makes sense!
LogMAN replied to Neil Pate's topic in Source Code Control
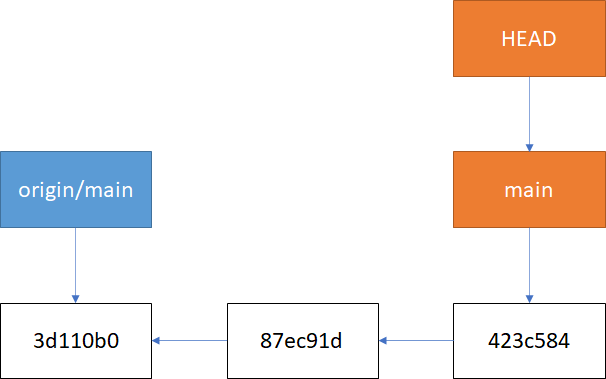
The common denominator in this case are the commits, each of which is uniquely identifiable by its commit hash. In ".git/objects" you'll find all commits. When you push or pull a repository, these are the objects that get exchanged. A branch simply points to one of these commits. If you know the commit id, you can create a branch for it. In ".git/refs/heads" you'll find all local branches. In ".git/refs/remotes/<remote>/" you'll find all remote branches (execute 'git fetch <remote>' to update the list). Finally, there is a file ".git/config" that specifies which local branch tracks which remote branch. In this example, local branch "main" tracks remote branch "origin/main": [branch "main"] remote = origin merge = refs/heads/main As you already discovered, it is possible to have different names for local and remote branches. This, however, is typically considered bad practice unless you have multiple remotes with the same branch name, in which case a typical approach is to prefix the local branch with the name of the remote (i.e. "origin_main", "coworker_main", ...). A general rule of thumb is to avoid this situation whenever possible. If a local branch does not track a remote branch, it won't get pushed to the remote. This is typically used for private feature/test/throwaway branches. Pretty useful in my opinion, but it also took me a while to wrap my head around this. Of course you can always push your local branches to the remote with 'git push -u <remote> <branch-name>'.
-
Git detatched head. All of a sudden this makes sense!
LogMAN replied to Neil Pate's topic in Source Code Control
When you add a commit to your local branch, it advances the branch pointer to that commit. The remote branch is not affected. Only when you push your changes to the remote does it forward the branch to the same commit. Here is an example, where a local branch (orange) is ahead of a remote branch (blue) by two commits. Pushing these changes will forward the remote branch to the same commit. Of course this also works the other way around, in which case you need to pull changes from the remote repository.
-
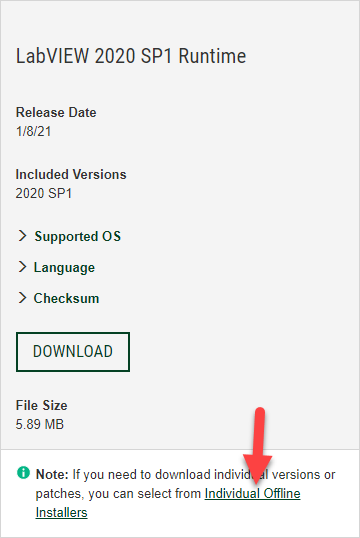
I too use InnoSetup to extract and install various products. Regarding the installer, I'm not sure if you are aware of this, but you can get offline installers from the downloads page. My installer also does a silent installation of NIPM and various packages. The details are explained in these KB articles: Automating the Unattended Installation of NI Package Manager (NIPM) - National Instruments How Can I Control NI Package Manager Through the Command Line? - National Instruments If I remember correctly, the parameters described in the first article should also work for other offline installers. Nevermind, here is the description for individual offline installers: Automating an Installer - NI Package Manager 20.7 Manual - National Instruments
-
You are right, I haven't thought it through. Source access is required to recompile, which makes any encryption/obfuscation/protection annoying to reverse engineer at best.
-
Here is a KB article with information about the design decision of password protection: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z0000019LvFSAU Not sure why strong encryption would be impossible. One way to do that is to store a private key on the developer(s) machine to encrypt and decrypt files. Of course loosing that key would be a disaster
-
Perhaps I'm missing something, but the way this works is when you move up one folder, that folder is "selected", so pressing OK will open the folder again. What makes it confusing is that the filename (and not the folder) is highlighted active (blue and not gray), so a user might think that pressing OK will confirm the filename, which is not the case. To my knowledge there is no way to change this behavior in Windows (the dialog is not actually part of LV). By the way, even if you deselect the folder, it will still enter the previous folder, which is certainly not intuitive to most users (including myself). The only way to make it work is to "change" the filename (even just replacing one character with the same letter will do the job). Here are the different scenarios I tested: 2021-06-04_21-15-40.mp4
-
The file still exists, only the link above is dead.
-
Why stop there? Magic Delay.vi
-
LabVIEW Call Library Function Node - Union Pointer handling
LogMAN replied to Ryan Vallieu's topic in Calling External Code
I'm no expert with CLFNs but I know this much: LabVIEW does not have a concept for unions but you can always pass an array of bytes or a numeric of appropriate size and convert later. Just make sure that the container is large enough to contain the largest member of the union (should be 64 bit from what I can tell). Conversion should be simple enough for numeric types but the pointer requires additional work. Here is some information for dereferencing pointers in LabVIEW (there is a section about dereferencing strings). https://forums.ni.com/t5/Developer-Center-Resources/Dereferencing-Pointers-from-C-C-DLLs-in-LabVIEW/ta-p/3522795 -
It creates a headless instance, so no dialogs. I haven't checked the unattended mode flag, but I'd assume it is set by default 🤷♂️
-
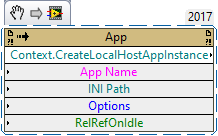
You could run the build in its own context, which (to my knowledge) does not save any changes unless option 0x2 is active (see Wiki for more details). Application class/Context.Create Local Host App Instance method - LabVIEW Wiki
-
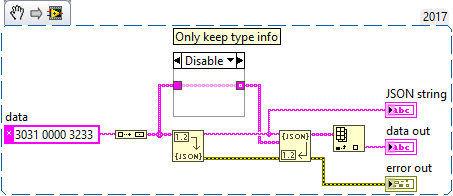
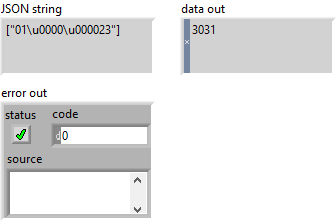
Unflatten From JSON breaks on NUL characters (LabVIEW 2017+)
LogMAN replied to LogMAN's topic in LabVIEW Bugs
Thanks, this is very helpful. One more reason to replace the built-in functions with your library. -
I recently stumbled upon this issue while debugging an application that didn't handle JSON payload as expected. As it turns out, Unflatten From JSON breaks on NUL characters, even though Flatten To JSON properly encodes them as ("\u0000"). I have confirmed the behavior in LabVIEW 2017, 2019, and 2020 (all with latest service packs and patches), currently waiting for confirmation by NI. Workaround: Use JSONtext