
Mads
-
Posts
471 -
Joined
-
Last visited
-
Days Won
33
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Mads
-

What do you think of the new NI logo and marketing push?
Mads replied to Michael Aivaliotis's topic in LAVA Lounge
If I have to say one positive thing about the new look, it's that the color palette is probably very very rare.... -
What do you think of the new NI logo and marketing push?
Mads replied to Michael Aivaliotis's topic in LAVA Lounge
My train of thoughts about it: Do I have a browser or display issue.... Someone must have hacked the site and messed it up really good - yuck... Wow, they are serious....this is even worse than NXG, someone should turn the ship... Is this an attempt to be appear more "green"? What screen resolution do they think people have? I have to double mine to read this properly... I wonder how this looks like for people who are color blind...(let me try on https://www.toptal.com/designers/colorfilter, nah the welcome dialog blocks that...) This is making me depressed, let me close this thing... -
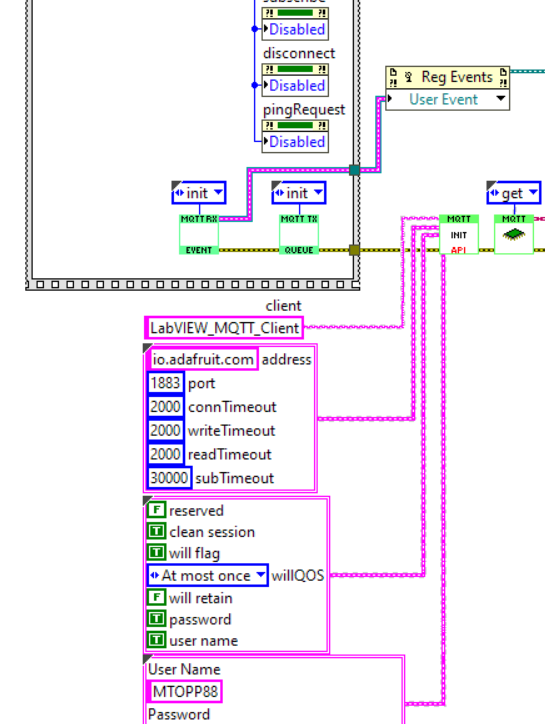
Port 8883 is usually used for TLS (1883 for non-TLS). There are a couple of examples of how to use TLS in 2020, if you search for TLS in the examples finder:

-
I have successfully used (unsecure) MQTT for LabVIEW, I have not tried it with the Azure IoT broker though. With this LabVIEW implementation for example: https://github.com/cowen71/mqtt-LabVIEW. The connection settings just had to be reconfigured slightly to get the link up and running. Here is a setup that works to connect to adafruit.io....you just need to change the user account and feed name of course, and the password (intentionally cropped out here): You may also need to open the firewall...In my case it allowed the connection, but blocked everything afterwards (producing error 66). I have not been able to use TLS with any of LabVIEW implementations though, but perhaps that can be remedied more easily now that TLS is supported in LabVIEW 2020...
-
NXG, I am trying to love you but you are making it so difficult
Mads replied to Neil Pate's topic in LabVIEW General
We might as well loop back to 2017 😉 -
Sounds like the extra VI that shows up has its "Show front panel when loaded"-flag set. If you open the VI, select File\VI Properties, and then select the Window Appearance category and click customize you can uncheck that option in the lower left corner. If you do not want it to show itself when it is called either, uncheck the Shwo front panel when called option as well (if not already unchecked).
-
NXG, I am trying to love you but you are making it so difficult
Mads replied to Neil Pate's topic in LabVIEW General
Nice examples. The CG code shows how a good graphical programming language allows you to express a "thousand words" with a simple picture. Not just due to the graphical code, but by the fact that the process of selecting an item, and the information from that selection process, is separated from the resulting code. NXG takes a step backwards, and operates closer to how it is/has to be in text programming (dot notation included). Seeing the rise of touchscreens, Microsoft thought we would all love Windows 8 and its Metro UI. Someone should have told them that if touchscreens were all we had, someone would make a hit inventing the mouse... -
NXG, I am trying to love you but you are making it so difficult
Mads replied to Neil Pate's topic in LabVIEW General
Most of the people that are shown a demo of SAP or Microsoft Dynamics will also say that it looks great.😄 It is only when they start to use it themselves for even the simplest things that they pull their hair out... Then they try to convince themselves, or at least the surveyor, that it is probably their own fault, just a transitional problem, or that everything will be better once the next version comes out. The latter will obviously be a strong influence here, combined with people trying to not come out as old fashioned naysayers. Did the analysis of these surveys take such social effects into account? Showing the System Designer to a hardware enthusiast will probably generate lots of smiles. -
NXG, I am trying to love you but you are making it so difficult
Mads replied to Neil Pate's topic in LabVIEW General
We used to have a poster in the office 20 years ago; it said that "For every existing customer you lose, you have to recruit 3 new ones just to make up for the loss". The difference between companies that grow and those that don’t is very often customer retention. The more customers that you can keep and continue to sell to, the more likely you are to achieve your business goals. Steve Jobs said; " “It's really hard to design products by focus groups. A lot of times, people don't know what they want until you show it to them.” The new users you refer to do not know better than the existing ones, because they do not yet know the gifts and challenges unique to graphical programming. Sure, give them (and us) fancier graphics, but do not reinvent the wheel by making it square. There are lots of things in CG that are the the way they are because of the original driving vision behind the product; making software an intuitive graphical data flow based - WYSIWYG - process. LabVIEW CG is unique because of how they solved the many unique challenges related to graphical programming. When I try NXG it makes me think that someone who loves text based programming and IDEs like Visual Studio (and/or secretly despises LabVIEW CG) has been given too much say*, and the driving force is now to make LabVIEW like every other (text based) tool. It does not just alienate existing users*, it is a loss of the original vision. That might make NXG The Last Generation.😬 (* Which might think that *we* are the ones that do not know what we want...😵) -
Caching did cross my mind during the testing earlier, so I tried running the tests on "fresh" data to get the worst case scenarios. It can mess thing up quite easily though I agree. Caching does improve both alternatives in this test case, and logically mostly for the non-sql solution, but on my machine not nearly as much as you observed during the mentioned test. PS: A similarly interesting performance nugget that can be nice to know about is the effect of branch prediction😃
-
Sure. I did not expect the same speed, I was just hoping that I would still be able to do such a retrieval fast enough for it to still feel near instantaneous to the users. That would allow for it to be maybe 10x slower than the chunk-based binary file format. Your library is the only one I have found that also runs on RT, and it is also, I see now, the fastest one, just 20x slower than my current solution. I might just need to adjust to that though, to enjoy the many other benefits 🙂
-
Managed to find an old copy of LVS's sqlte_api-V4.1.0 now, which I suspect is what I used when evaluating SQLite previously. Stripped down to just the query I see that it is actually 3x slower than your solution @drjdpowell for this query(!). I also tried SAPHIR's Gdatabase with similar slow results. I also did a test in python as a reference, and it ticked in at 0.44 seconds. So no reason to expect better after all...
-
Attached is an example VI and db-file where I just use a single sql execute to retrieve the data...On my Windows 10 computer (SSD) with LabVIEW 2018 a full retrieval, with or without a time clause, takes about 0,66 seconds this way. I have tried using the select many rows template, and it takes about the same time. Retrieval test.zip
-
Whether I use the timestamp as the primary key or not does not affect much. A select * from the table will also spend about as much time as one with an equivalent where clause on the timestamp.... 99% of the time is spent in the loop running the get column dbl node (retrieving one cell at a time is normally something I would think would be inefficient in itself, but perhaps not, I guess that is dictated by the underlying API anyway, or?).
-
I was thinking of replacing a proprietary chunk based time series log file format that we use with SQLite, using this library. From a test I did some time ago I thought read performance would not be an issue (unlike for TDMS for example, which performs really badly due to the fragmentation you get when logging large non-continuous time series ), but now that I redid the tests I see that the read times get quite high (writes are less of an issue in this case as we normally just write smaller batches of data once a minute). I expected the database to be much slower, but the difference is of a magnitude that could be troublesome (no longer a real-time response). To give a simple example; if I have a table of 350 000 rows containing a time stamp (real) and 3 columns of measurements (real), and I select a time (sub)period from this table; it takes up to 0,6 seconds to retrieve the measurements on my test machine (using either a single SQL Execute 2D dbl, or the Select many rows template). For comparison the current binary file solution can locate and read the same sub-periods with a worst case of 0,03 seconds. 20x times faster. This difference would not be an issue if the accumulated time per batch of request was still sub-second, but the end users might combine several requests, which means the total waiting time goes from less than a second ("instantaneous") to 5-30 seconds... Perhaps I was using @ShaunR 's library back when I was able to get this done "instantaneously", but that seems to no longer exist (?), and in this case I need a solution that will run on Linux RT too...Should it be possible to read something like this any faster, and/or do anyone have any suggestions on how to improve the performance? The data will have to be on disk, the speedup cannot be based on it being in cache / memory...
-
One thing we do to help during memory leak testing is to place exaggerated or artificial memory allocations at critical points in the code, to make it more obvious when a resource is created and destroyed (or not...) 🕵️♀️ That is not an option for the native functions...🙁 but, depending on the code, you might be able to run an accelerated life test instead...
-
We do this in most of our sensor monitoring applications; each sensor you add to your system for example is (handled by) such a clone. Every serial port we use for example is also shared between sensor clones through cloned brokers. Client connections with various other systems are another part handled by preallocated clones; dynamically spawned on incoming connections. Communication internally is mostly handled through functional globals (CVTs, circular buffers, Modbus registers etc), queues and notifiers. Externally it's mostly through Modbus TCP, RTU, OPC UA or application specific TCP -based protocols. These applications have run 24/7 for years without any intervention, on Windows computers (real or virtual), and sb(cRIO targets. In some of them we use DQMH, and have not run into any issues with that so far either. If a memory leak is too small to be detected within hours or a few days of testing, it is probably so small that it will not cause a crash for years either.
-
Coining a phrase: "a left-handed scissors feature"
Mads replied to Aristos Queue's topic in LabVIEW General
Security in the age of cloud computing and IoT is a huge challenge. I do not think we should start on that discussion here. But you guys seem to assume that that means we can resort to the old ways of doing business - That NI and others should not leverage these things fully, but try to guide their users to the old ways by making sure the new ones are intentionally crippled. The fact is that most of us are way down the rabbit hole already, ignoring the risks because the benefits are too enticing or the business or societal pressure too high. If people can make a business of delivering services that are at the same level of risk as the customer is already taking in other areas (in fact in the particular case that triggered my interest in this - the security would be improved compared to the current solution - imagine that), but NI is holding them back because they think the security challenges has to be 100% solved first...well...that is a recipe for a dwindling business. The starting point of my digression was something that the supplier in fact is already partly working on. They just have not gotten around to it yet. So it is not like you are defending something that they themselves think is the holy grail of security limitations either. Arguing that the current solution is as good as it gets is never really a winning strategy. -
Coining a phrase: "a left-handed scissors feature"
Mads replied to Aristos Queue's topic in LabVIEW General
I think I have outlined the complaints quite enough already, that part was just a digression. The main point was how far off the mark (or "left handed" in this context) SystemLink is as a solution for the mentioned request in the Idea Exchange. -
Coining a phrase: "a left-handed scissors feature"
Mads replied to Aristos Queue's topic in LabVIEW General
Oh, I know how to do it. With my left hand 😉 Not my preference. It can be done better. -
Coining a phrase: "a left-handed scissors feature"
Mads replied to Aristos Queue's topic in LabVIEW General
If sufficient security for many a use case is not possible to achieve without having to put each customer on a separate server, and the creation and licensing of those servers have to be a manual process repeated every time a new customer want such a service...*and* none of this can in be abstracted into a larger platform that makes the process of managing this a breeze for users at, in this case, two ends to use...I would argue the problem is mainly a lack of imagination. -
Coining a phrase: "a left-handed scissors feature"
Mads replied to Aristos Queue's topic in LabVIEW General
I think that is a very old fashioned way of thinking. -
Coining a phrase: "a left-handed scissors feature"
Mads replied to Aristos Queue's topic in LabVIEW General
This reminded me of this idea exchange thread: https://forums.ni.com/t5/LabVIEW-Idea-Exchange/Offline-Distribution-for-Real-Time-Application/idi-p/1415250 Sure, the fact that the offline installers idea was marked as in development due to SystemLink is probably just because someone though it might accidentally be a solution for that too, but in general it seems to me that NI is designing more and more "left-handed scissors features" 😞 (SystemLink Cloud is by the way is so crippled compared to the stand-alone solution that you cannot use it for trending data for different customers (Access control on tag groups is not available, only on applications for example). To get enough access control you have to create your own SystemLink servers for each customer and get those online yourself (no cloud hosting of those at the click of a button from NI). And if you need to do regular analysis on the incoming data in SystemLink you cannot insert a set of VIs to do that, no - you need Diadem or resort to python (because "Diadem is much more powerful than LabVIEW" (!))...) -
Not really, but that would be one way to attack it yes, if it was not for the classes.
-
Hahaha, both of them apply very nicely 😆 I had only thought of the first one.