drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
Thanks Neil, The toolkit gives off a “not quite ready for prime time†vibe to me (including that annoying partial implementation of events, poor documentation, minimal single example, etc.) so I’m glad you are happy with it. I suspect it is an incomplete version of OPC-UA (no method calls?) but probably sufficient for the simple server I need to make. Thanks again, — James
-

Actor Framework settings dialog
drjdpowell replied to chrisempson's topic in Application Design & Architecture
In case the OP wasn’t aware, there is an Actor Framework group on NI where there are more AF users who might respond. Waiting on things that are reliably quick is often the best thing to do, IMO, as it is often simpler. -
Hi Neil, I'm looking in to using LabVIEW's OPC UA implimentation, both client and server, and wondered what your experiences were with it. Would you recommend it? -- James
-
HI Rob, Have you looked at the example code (and video linked to) here? It’s a TCP example. Standard Request-Reply and Register-Notify should work seamlessly over TCP (as the various TCP actors route the messages back over the connection) without needing to do anything special.
-
I use composition instead of inheritance: actors with common behavior will all use some common class to get this behavior. You can change the “Default†message case from throwing an error to calling a “Handle Message†method of some common class. The “Pipeline Component†actor classes, in the example above, all contain a common class that handles common messages (the actors can “override†these messages by choosing to explicitly handle them). Note that you can inherit off of this common class and inject different behavior to your actors by having the caller send the common class to the launched actors. Below is an example that is as close as I’ve done to all-internal-data-in-one-object. All this actor does is receive a “Graph Augmentation†object from it’s caller, then it passes all events on a graph to methods of this object. It also passes any unknown message to the “Receive Msg†method. “Graph Augmentation†is a parent class of several children that actually do things, and 99% of the work is done in methods of this class. This is quite powerful, but it is also harder to figure out what is going on. You would have an easier time understanding my other example, because you can see high-level stuff happening on the diagram. Here it is just “Cursor Moved—> call 'Cursor Moved’ dynamic-dispatch method; Message Received—> call 'Receive Message’ DD methodâ€.

-
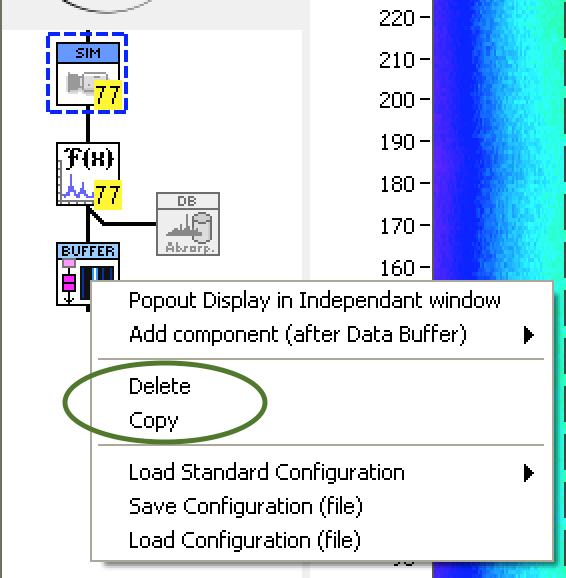
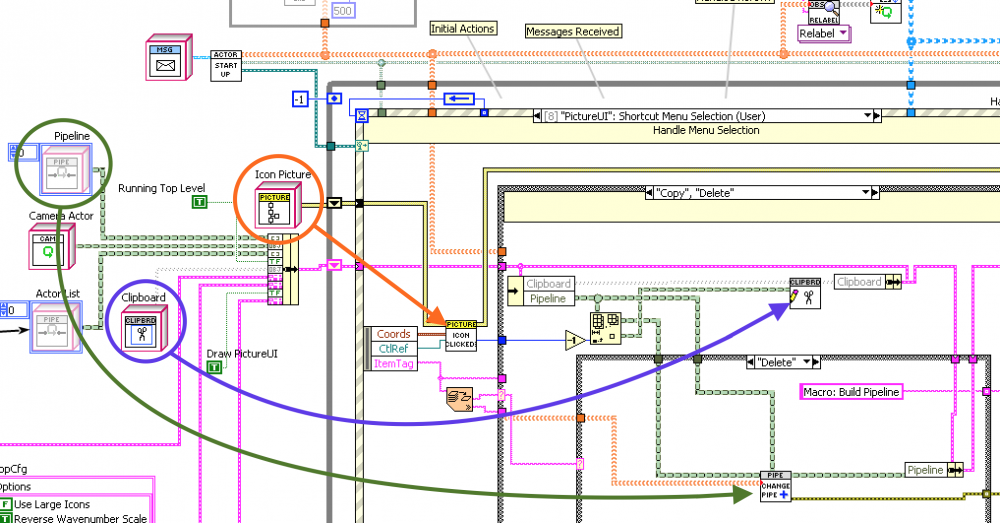
Personally, I tend to look to see if some of the actor’s data should really include one or more classes, then my subVIs are methods of these classes. I generally try not to have a class that is all the data of the actor, or have subVIs that pass in all the data (you’ll note I don’t even type-def the Internal-Data cluster). I like the high-level actions to be on the top-level block diagram, but the details hidden in more specific subVIs that only act on part of the date. For example, here is a Top-level actor that presents a picture to the User, showing a “pipeline†of analysis actors, where the User may modify the pipeline by adding, deleting, copying and pasting. The code for copy/delete is shown. This code is basically: If the User selects “Deleteâ€, then identify which icon was clicked on, write the deleted actor to the Clipboard (so the User has the option of pasting it elsewhere in the pipeline), and delete it from the Pipeline list of actors (calling "change pipeline.vi†to complete this). There are three complicated bits of detail here, but they each only need part of the Internal data. There is a method of the “Icon Picture†object that handles all the details of the picture (rather complex internally); a method of the (not so complicated) “Clipboard†object; and a subVI that acts on arrays of “Pipeline Component†Actors. No subVI needs all actor data. BTW, the actor class here (your “Solo_Msg.ctlâ€) is actually serving as the address of the actor to external processes, so I wouldn’t try and make it do double duty as an internal-data store. Instead, you could make a different class. You could even have the actor’s caller preconfigure such an object and send it to the actor after launch.
-
This link might be of interest. It redirects stout of System Exec.
-
Using a number of interaction queued message handlers (QMH) is quite a common architecture (sometimes known as “actor-oriented design"). There are multiple packages in the community that people have made available**, and I believe quite a few people have their own private implementations. Personally, I usually have a separate QMH for each independent bit of hardware. I have sometimes done an LVOOP driver (with child types) inside a QMH, which I think is what you are describing. ** Mine is Messenger Library (an introductory video); there is also the Actor Framework (part of LabVIEW), Delacor DQMH, and Aloha, just to name a few that are available on the LabVIEW Tools Network, and you’ll find a few other examples on LAVA such as Message Pump.
-
Do you have specifications for the different types of units? If so, you can query the unit for its type then load something specific to this type. Could be a special INI file for each type, or a child class if you are using LVOOP. The file/class would specify what settings are available. Are you testing these units, or just using them? With testing you should test to the spec, not query the unit for what it can do. Otherwise you won’t catch a unit that fails to support a setting that it actually should.
-
messenger library Instructional videos on YouTube
drjdpowell replied to drjdpowell's topic in Application Design & Architecture
I suspect you had some error in calculating the index. “Insert into array†will fail if you have the wrong index (so inserting at index 3 in a three-element array will produce a four-element array, but inserting at index 4 will silently fail). I would use Build Array instead. -
messenger library Instructional videos on YouTube
drjdpowell replied to drjdpowell's topic in Application Design & Architecture
Is your actor reentrant? The VI should be named “Actor.vi†(rather than ActorNR.vi) and set as shared-reentrant. If that isn’t the problem please post an image of your launch code. I use arrays of actors in some of my projects (and the library has VIs meant specifically to work with arrays) so it does work. -
messenger library Instructional videos on YouTube
drjdpowell replied to drjdpowell's topic in Application Design & Architecture
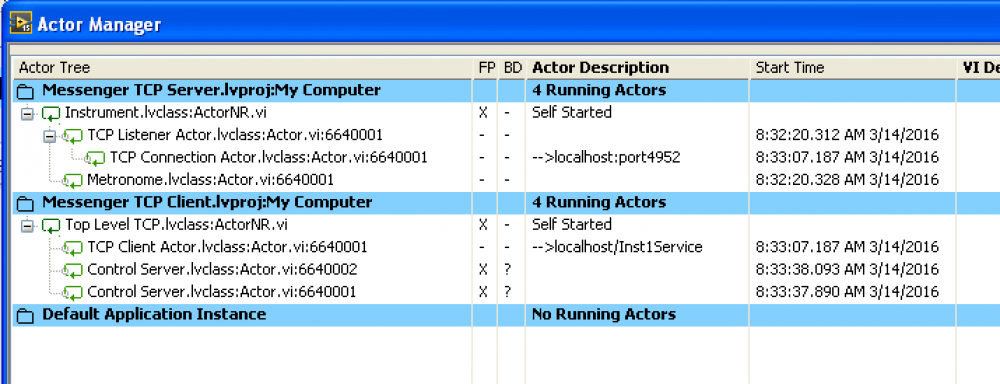
See this new video on youtube. I modified the demo so that 'Instrument' is running on a separate project behind a TCP server, with 'Top Level' connecting as a client via a Remote TCP Messenger. I also showed the use of an 'Address Watchdog' to shutdown 'Top Level' if ‘Instrument' disconnects. Here is the code (start the server first): Messenger TCP Server.zip Messenger TCP Client.zip I think I forgot to mention it in the video, but note that the Client project does not load the code of “Instrument", and the Server Project does not load the "Top Level" code. Thus, nothing is locked and you can edit freely (this is a problem in some architectures). This is done internally by the TCP server/client actors by keeping all reply addresses in flattened form on the remote target. If you use custom probes you will see most replies or registrations become something like "Route back to QueueMessenger and then to Flat", which is confusing but means "send back to the TCP actor running this connection, then via TCP to the remote system, and then to this address (unflattening it first)". Please note that only Reply Addresses are converted; you cannot send an address as data in a message and have it work on the remote system (attach it as a Reply Address instead). Please note that I have yet to do a Real-Time project with Messenger Library. I do have a current project using modified TCP actors to communicate with a non-LabVIEW client from another developer (using JSON messages), but that isn't the same. So please don’t be afraid to ask for help or to make suggestions. Please see if you can run this example with ‘Instrument' on the Real Time system. -- James Actor Manager for this TCP example. Note that the 'Control Server' actors are entirely unmodified, and have no knowledge that they are talking to 'Instrument' via TCP. Because everything is by message (no DVRs, no Action Engines) it is easy to convert things to remote operation.
-
messenger library Instructional videos on YouTube
drjdpowell replied to drjdpowell's topic in Application Design & Architecture
I’ve added a couple of more videos about the Register-Notify system used in Messenger Library. A couple of people identified Notifications as something I had not explained sufficiently (especially the difference between an “event†and a “state†notification). So I have added Register Notify and Notification “Hookup†of a dynamic actor (and generic messages). The later video also shows a technique of handling messages to do with multiple controls in a single Variant-based case. Updated example code:Messenger Library Demo.zip I’ve also made an initial Introductory video to SQLite in LabVIEW. -
In the later LabVIEW versions, one can open the original copy and select View>>Browse Relationships>>Reentrant Items, and that allows one to open the shared clones. In older LabVIEW Versions, one can (temporarily) set the VI to "show front panel when calledâ€. However, if your building a message-based architecture, you can just build in a “show front panel†message to your actors/processes/modules/whatever.
- 8 replies
-
- 3
-

-
- debug
- reentrancy
- (and 3 more)
-
Possibly. If one was sending a stream of JSON (including some scalar strings) then this would cause a failure. However, if some of those scalars were number, like 123.456, then there would be no way to be sure you had the full value as 12 or 123.4, etc. are valid JSON. So to guard against partial JSON one might have to require streams to use either an Object or Array.
-
Introductory video now available. I’ll try to make some videos on more advanced techniques when I get the chance.
-
Is anybody using this? I’m revisiting it for the first time in over a year to make some improvements in support of a client. If you have any suggestions, or added feature you would like, now is the time.
-
BLOBs are just a binary data type, same as TEXT but without the need to treat binary data for special characters. Use “Bind BLOB†when your LabVIEW string isn’t actually text. Have you considered just saving each waveform in a separate file, and storing the filename in SQLite? Then overwriting is easy.
-
I’m not sure SQLite is the best choice here. Large waveforms is something TDMS is built for. SQLite is better for structured data where one wants powerful filtering ability to pull out only the small subset of information one needs. TDMS already has useful features like the ability to store scaled U16 values rather than 8-byte DBL (I’ve done this is SQLite, but it more work). You could mix the two approaches, storing metadata about your waveforms in SQLite, along with a filename and waveform name pointing to the TDMS file with the waveforms itself. BTW, if you store your flattened waveforms as BLOB, then you don’t need to replace any special characters. But, as I said, once one is doing this one has lost to big benefit of SQLite, the ability to query your data, so I think you should consider TDMS.
-
Oh dear, that was amateurish. This is an unfinished VI that I obviously never tested. Sorry about that. I’ve only been using WITHOUT ROWID tables recently, and in the past I’ve only generated the rowID in LabVIEW and thus never used this dll call. Added later> fixed 1.6.3 version now in the LAVA-CR (note, LAVA will often have a later version than on the LabVIEW Tools Network)
-
I don’t have a system to test, but the library attempts to find the copy of libsqlite.so if it is installer on the Linux RT system (see the series of posts starting here). Stobber can give you better information, as he was trying to do this.
-
I’m happy to standardize on ISO8601, it being a standard, but I need time to write it.
-
Calling an subVI asynchronously
drjdpowell replied to Doug Harper's topic in Application Design & Architecture
‘Running†means “reserved for runningâ€. I don’t think the LabVIEW execution system, designed to handle very fast-finishing subVIs without overhead, can actually tell you if a VI is actually running at a specific point in time. What you can do is create a reference (a queue, say) in the async-called VI and pass that back into the caller (via another temporary queue). References like queues are automatically cleaned up when a VI hierarchy goes idle (each async-called VI runs in its own separate hierarchy), so this queue can be used to tell if a VI is still running. -
Anybody ever done a full ISO8601-timestamp parser in LabVIEW? There are lots of options in ISO8601, and our trial-and-error format method is a poor fit if we really want to support ISO8601.
-
Steven is referring to the array of supported time formats in "JSON Scaler.lvclass:Scan Timestampâ€. His timestamps are valid ISO-8601 format so we should support them. Note for Steven: That format is local time, plus an offset. LabVIEW Timestamps are in UTC, so I will have to apply the correction. PS> seems one can just use the format: %^<%Y-%m-%dT%H:%M:%S%12u>T and it will work for any smaller number of digits