drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-

Dataflow outputs and ParameterDirectionKind
drjdpowell replied to PaulL's topic in Object-Oriented Programming
Not used UML myself, but it seems to me that the terminals of a VI are much better specified in this way (not that available UML tools will support this ):
-
You only have one subpanel, and a subpanel only holds one VI at a time (dropping the previous VI if you insert a new one). You also seem to be only creating one copy of your subVI (but you opened four separate references to it). If you want four copies (“clones”) of your SubVI, you need to use option 0x8 (Reentrant run) in the Open Reference, and you need four subpanels.
-
Making a new “MoveStrategy” class tree is my first thought also, but another possibility is to create a HysteresisCapableAxis child class that by default has a Move method that just calls the parent method, but that can also enable hysteresis (via some “Enable” boolean). You can then enable or disable hysteresis without changing the class.
-
You mean it is too slow when the reference is invalid? When it is valid then this method takes less time than testing for an invalid refnum and then using it.
-
Even better than testing for an invalid refnum is actually trying to use the reference. Recreate it if you get an error. There is some post somewhere by AQ that points out the race condition in testing for refnum validity. Here’s an example of a “refnum created and maintained inside a non-reentrant VI” from one of my projects:
-
A minor warning about that technique. A reference is destroyed if the top-level VI under which it is created goes idle. The “First Call” primitive is reset when the subVI it is contained stops being reserved for execution. If you are working with multiple top-level VIs (such as if using dynamically “launched” VIs) then it is possible to invalidate the reference without resetting the first call.
-
LVOOP with DVRs to reduce memory copies - sanity check
drjdpowell replied to Troy K's topic in Object-Oriented Programming
It’s not a matter of “can be released”; all references owned by a top-level VI are required to be released as part of the process of going idle. This is a little-known but standard way LabVIEW treats all references. Changing this would break or introduce memory leaks into all sorts of old code. I use asynchronously launched VIs extensively and I actually find this feature very useful, though also quite complicating. -
LVOOP with DVRs to reduce memory copies - sanity check
drjdpowell replied to Troy K's topic in Object-Oriented Programming
Hi Neil, I don’t think that’s how it works. If you put a by-value object in a DVR, the data can’t disappear unless the DVR disappears. The DVR “owns” the object. Only if the DVR contains just a reference to something (another DVR, a queue, etc.) do you have to worry about its independent lifetime. The DVR, like other references in LabVIEW, is itself “owned” by the top-level VI of the subVI that created it (I think this might be called a “VI hierarchy”), and will become invalid if that VI hierarchy goes idle. This only matters if you are sharing the reference between multiple VI hierarchies (such as by asynchronously-called VIs). -
Check this conversation for info on the 2013 changes, and a subVI that can be used to fix the problem.
-
Hi, I’m thinking of submitting my SQLite package in the CR to the tools network. Is “Team LAVA” still active? — James
-
LVOOP with DVRs to reduce memory copies - sanity check
drjdpowell replied to Troy K's topic in Object-Oriented Programming
Oh dear, I think that paper must be badly written, at least when interpreted from your background (and the “copies on the wires” part isn’t strictly true). The whole point of by-value dataflow is NOT worrying about object lifetime. -
LVOOP with DVRs to reduce memory copies - sanity check
drjdpowell replied to Troy K's topic in Object-Oriented Programming
Yes, by-reference data allows one to be sure your not making copies. It can take a lot of experience before one starts to trust by-value data handling. Using in-place elements and always wiring straight through functions can give one confidence, even if those techniques are often unnecessary. But, a good by-value design can be at least as “copy-efficient”, if not more so, as a by-ref design even, while also having other advantages. Still says “queue”. Queue the data to the central analyzer and have it retain whatever info it needs to interpret further data (like the last battery voltage). — James -
LVOOP with DVRs to reduce memory copies - sanity check
drjdpowell replied to Troy K's topic in Object-Oriented Programming
You can’t have your cake and eat it too. If you want a low priority process to wait till later then you have to retain the data it needs. If you want no copies, then everybody else has to wait for that low priority process to finish with the data before overwriting it. “Passing wires” doesn’t make copies. Even branching wires doesn’t always make copies. Your app says “queues” to me, not “FGV” or “DVR". Queue all the measurements to a central analyzer. Queues are asynchronous, so can’t stall your acquisition loops. Access to a FGV or DVR is synchronous, so to avoid blocking acquisition you are forced to make a copy for lengthy analysis. Your description of the wide variety of measurements that can be produced definitely suggests LVOOP. A low-risk path would be to just start using classes in place of whatever type-def clusters you are using for measurements. That will force you to use the encapsulation that will allow you to extend using inheritance later on. To a copy. DVRs aren’t pointers; they have locking features that I don’t think could work for locks inside locks. Can you just use an array of DVRs to implement whatever it is your after? -
Matze, Can you probe to see what the pointer is when the error happens? The 1097 error happens if the pointer is zero.
-
LVOOP with DVRs to reduce memory copies - sanity check
drjdpowell replied to Troy K's topic in Object-Oriented Programming
Well, to prevent copies you must serialize access to the data. A DVR does that, but if you have already designed a structure that serializes access (Collect—>Analyze—>Graph—>Store) then you won’t gain anything by adding a DVR. BTW, an easy way to reduce copies in your example code is to put the analysis logic inside the Functional Global (an “analyze" step rather than “get”). You can also serialize the graphing and saving. A more major change is to not deal with all the data at once. Stream data to disk, and only read, analyze and present a subset at a time. -
Reentrant Global In Clones
drjdpowell replied to hooovahh's topic in Application Design & Architecture
You don’t need the “Open VI Ref” dynamic-launch complexity; just use a static, strictly-typed ref (each one of which refers to a separate clone):
-
Google translation: That error comes for the Call Library Node calling “MoveBlock” in “Pointer-to-C-String to String”. It’s writing into an array of bytes allocated by LabVIEW, so I can’t see how an error could occur. And I have not seen this error myself. Anyone else have this problem?
-
What influence how long it takes to launch an actor?
drjdpowell replied to QueueYueue's topic in Object-Oriented Programming
Which version of “Launch Actor” are you using? The newer version shouldn’t be closing the reference to “Actor.vi” at all (link). -
Out of order events is not a bug, sort of
drjdpowell replied to Aristos Queue's topic in LabVIEW Bugs
How did they fix this? Given that the dynamic registration queues are independent of the static queues, how can events be ordered, other than by a timestamp of some kind? -
Nicely done. I made a similar tool for my actor-like framework, and I experimented with something for the Actor Framework, but I couldn't see how to do it without changing Actor.lvclass (make a child class, of course!). Like the “ping” ability.
-
Feedback Requested: Daklu's NI Week presentation on AOD
drjdpowell replied to Daklu's topic in LabVIEW General
Are you actually working on a DB actor or is this just academic? Because you are in danger of spending a lot of time on redundantly recreating features that the database software already handles (and probably handles better; for example, a DB will only serialize transactions that actually need to be serialized). -
Feedback Requested: Daklu's NI Week presentation on AOD
drjdpowell replied to Daklu's topic in LabVIEW General
I disagree, if you mean you can update these lists of actors non-locally. For example, if Actor A launches Actor B, then only A has the address of B, and A cannot add B to any list of Actors held by any third actor, C, except via sending the address in a message. Having by-reference updatable lists shared between Actors is a definite violation of the Actor Model; the lists have to be by-value. Note that you can build structure on top of actors that do subscriptions or channel-like message routing, but these must all be built on top of messages. No by-ref data sharing. My “Observer Registry” Actor, for example, in my actor-like framework, holds by-value lists of addresses, and everything is done by messages. I say “my actor-like framework” because I can’t claim I don’t break the Actor Model rules, but I do try and know why I should be wary about breaking them. That isn’t using the names as a global link, so that is fine. Nothing wrong with not using the Actor Model for everything, but personally, I’d rather my missile not be mistakenly destroyed because of a bug is some forgotten unimportant subsystem that misspelled a queue name. If everyone needs to know it, then explicitly pass it to everyone. -
Feedback Requested: Daklu's NI Week presentation on AOD
drjdpowell replied to Daklu's topic in LabVIEW General
Actually, I think it is a property of the Actor Model (though descriptions of it are not very clear so I may be wrong); it’s part of something referred to as “locality", which I would restate as "instantaneous changes are local, and are transmitted through the system only via messages”. Being able to launch an actor and then have any other actor be immediately able to address it is a violation of locality. From Wikipedia: Unfortunately, “addresses that it already had” is too vague to definitively interpret. -
Feedback Requested: Daklu's NI Week presentation on AOD
drjdpowell replied to Daklu's topic in LabVIEW General
BTW, a Database is not a good example to use for considering “actors”; a database is already well-designed for handling concurrent access, so someone reading may not see much value in introducing actors. Instead, how about a piece of hardware that can only do one thing at once, but may be needed by multiple concurrent processes. A part-handling robot, for example. An actor that handles all interaction with the robot can rewritten to mediate concurrent requests, perhaps through some kind of “transaction” system. Eg: ProcessA —> Robot: “Request robot transaction" Robot—>A “Transaction Started" ProcessB —> Robot: “Request robot transaction" Robot—>B “Busy; you are in job queue" ProcessA—>”Do action 1" <robot working> ProcessC —> Robot: “Request robot transaction" Robot—>C “Busy; you are in job queue" <robot working> Robot—>A “Action 1 Finished" ProcessA —> Robot: “End transaction" Robot—>B “Transaction Started" etc. The Robot Actor would either refuse any “Do action” requests from a Process that doesn’t have an open transaction, or consider such a request as implicitly being equivalent to a combined “Request transaction; Do action; End transaction”. -
Feedback Requested: Daklu's NI Week presentation on AOD
drjdpowell replied to Daklu's topic in LabVIEW General
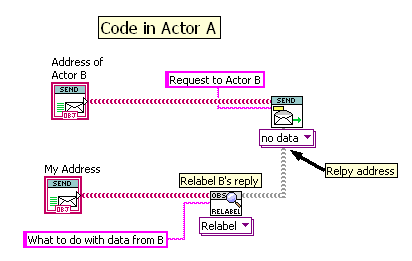
I would have Actor A attach some kind of token to its request to Actor B, that Actor B would send back attached to the requested data. This token would contain the next step for A to do. This way the code for A is all contained in A, and B can be more generic and service requests from multiple actors. In the framework I use, which like Lapdog uses text identifiers on messages, I usually do this by configuring A’s request to relabel the reply from B: Here, A will receive back a message containing B’s data, but with the label specified by A (overwriting the label set by B).