

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
I think you just need a better lookup and you'll be there! (with bells on)

A little free time this morning:
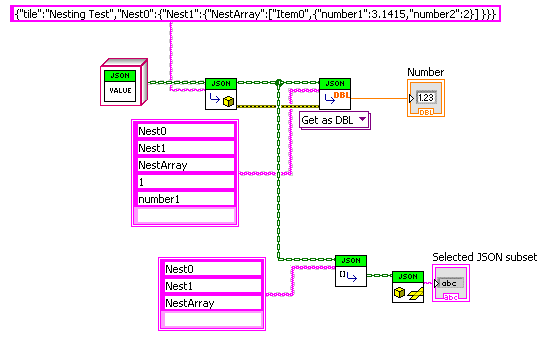
Used arrays, but you could use some parsable string format like “->”. The polymorphic VI currently has only one instance of the many, many it would need. The lower part shows selection of a subset of the JSON that can be passed generically to lower code layers.
— James
-
The code knows nothing. It doesn't know what a glossary IS only that It is a field name it should look up for the programmer- it just gets what the programmer asks for. If the JSON structure changes, no changes to the API are needed. It doesn't care what the structure of the JSON object is, it's just an accessor to the fields within the JSON object - any JSON object.
Rephrase as with respect to the programmer, then; the programmer shouldn't have to understand the entire application and data structure from high-level to low-level at the same time.
There is nothing stopping you doing this, but this isn't the responsibility of a parser. There is nothing to stop you creating an "object" output polymorphic case for your “experiment setup” (or indeed a whole bunch of them), you just need to tell it what fields it consists of and add the terminal. However. That polymorphic case will be fixed and specific to your application, and not reusable on other projects (as it is with direct conversion to variant clusters).Sorry, I ment JSON “Objects”, not application-specific LVOOP objects. No custom code needed.
I think you just need a better lookup and you'll be there! (with bells on)One could certainly write a multi-level lookup API on top of what I have already. Should be quite easy (though tedious with all the polymorphic instances). Wasted too many hours on this today, though. I don’t have any projects that actually need JSON.

— James
-
What I mean by “abstraction layers” is that no level of code should be handling that many levels of JSON. In your example the same code that knows what a “glossary” is also knows how “GlossSeeAlso” is stored, five levels down deep.
For example, imagine an “experiment setup” JSON object that contains a list of “instrument setup” objects corresponding to the different pieces of equipment. The code to setup the experiment could increment over this list and pass the "equipment setup” objects to the corresponding instrument code. The full JSON object could be very complex with many levels, but to the higher-level code it looks simple; just an array of generic things. And each piece of lower-level code is only looking at a subset of the full JSON object. No individual part of the code should be dealing with everything.
BTW> I see there is another recent JSON attempt here. They use Variants.
-
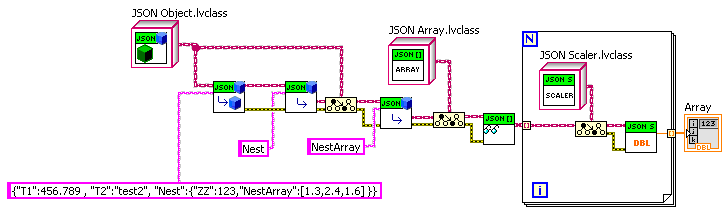
How about a slightly modified JSON of one of your examples? (Get the "NestArray" Values)
{"T1":456.789 , "T2":"test2", "Nest":{"ZZ":123,"NestArray":[1.3,2.4,1.6] }}
I don't think it is sufficient to simply have a look-up as you have here, but it is close.
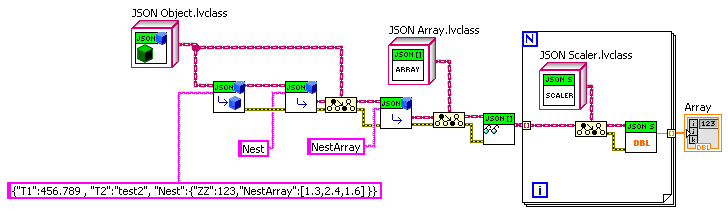
If one does a lot of digging things out multiple object levels deep, then one could build something on top of this base that, say, uses some formatting to specify the levels (e.g. "Nest>>NestArray” as the name). But if one is using abstraction layers in one’s code, one won’t be doing that very often, as to each layer of code the corresponding JSON should appear quite simple. And I think it is more important to build in the inherent recursion of JSON in at the base, rather than a great multi-level lookup ability.
Here, for example is another extension: a VI to convert any (OK, many) LabVIEW types into corresponding JSON. It leverages OpenG variant tools. It was very easy to make it work on nested clusters, because it just recursively walks along the cluster hierarchy and builds a corresponding JSON Object hierarchy.
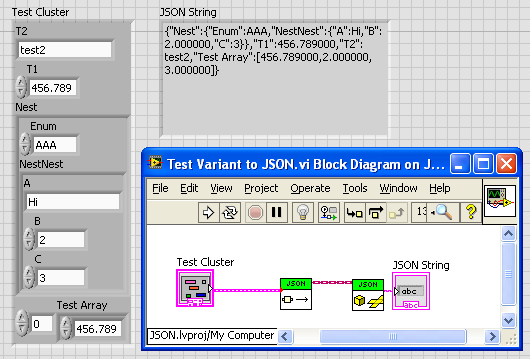
—James
-
Yup. Keep drinking the cool-ade
 It probably took me the same amount of time to write the concept as it did for you to read my posts...lol
It probably took me the same amount of time to write the concept as it did for you to read my posts...lolI must code pretty slow. This took me 2-3 whole hours:
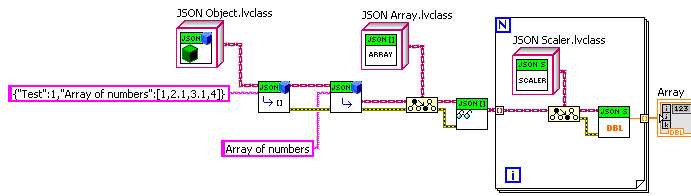
Reads in or writes out JSON of any type, with nesting. One would still need to write methods to get/set the values or otherwise do what you want with it. And add code to check for invalid JSON input.
— James
Added later with methods written to allow an example of getting an array of doubles extracted from a JSON Object:
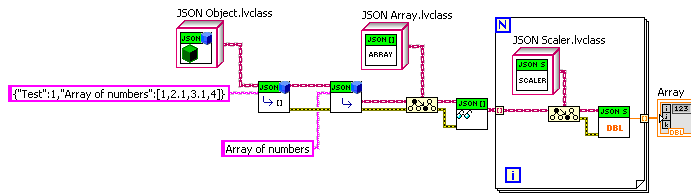
Rather verbose. But one can wrap it in a “Get Array of DBL by name” method of JSON Object if you want.
-
An advantage of Joe’s Variants, or the LVOOP deign, is that the nesting is pretty trivial (just recursion). I think the LVOOP design would be the simplest. Not that I have any time to prove it

— James
-
This is exactly what my example is (analogously - Classic LV to LVPOOP).
So’s Joe’s design, now that I look at it. Though your one seems more like his “flattened variant”; how are you going to do the nesting?
-
Thoughts:
If I were approaching this problem, I would create a LabVIEW datatype that matched the recursive structure of JSON. Using LVOOP, I would have the following classes:
Parent: "JSON Value”: the parent of three other classes (no data items)
Child 1: “JSON Scaler”: holds a “scaler” —> string, number, true, false, null (in string form; no need to convert yet)
Child 2: “JSON Array”: array of JSON Values
Child 3: “JSON Object”: set name/JSON Value pairs (could be a Variant Attribute lookup table or some such)
If I’m not missing something, this structure one-to-one matches the JSON format, and JSON Value could have methods to convert to or from JSON text format. Plus methods to add, set, delete, or query its Values. Like Shaun, I would have the user specify the LabVIEW type they want explicitly and never deal in Variants.
— James
-
Cameras showed up in MAX no problem, but both MAX names would, if selected, lead to images from only one of the cameras. It’s was driver issue, at a lower level than MAX.
-
Really? I've got it working just fine on my PC.
I wonder: are you using NI-IMAQdx? Or something different?
I think I’ve seen it with NI-IMAQdx. It’s only with some USB cameras, such as webcams. And it is only when using identical models; one can use multiple cameras of different models, because they go into the Registry under their model names.
-
It’s adapting to the type of the control it’s connected to, which I did not know it could do.
-
Had that problem. I believe it is because the Windows software was never made to work with multiple cameras at once. Each identical camera is listed in the Windows Registry under identical names. I believe you can modify the registry, but that is not a satisfactory solution.
-
I had the problem with an XControl which I was peppering with events to show that XControl value updates often lag behind the calling VI. Doing this I saw that when queuing up many events fast enough, the order became mixed up.
Actually, I’ve seen this same effect with an Xcontrol of mine. The same effect occurs if you set the control to “synchronous” and hit the terminal. Note, though that you aren’t directly firing events here; you’re triggering a property, and whatever code behind the scenes is firing “Data Changed” events into the Xcontrol. And the associated data isn’t packaged with the event, it’s provided via the “Data In” input terminal. It isn’t clear that the problem is in the event system itself.
-
From personal experience, whenever there is a problem somehow involving Xcontrols, my suspicion falls first on the Xcontrol.
-
Whilst the mechanics may be thought of in that way and indeed, both may be coerced to emulate the properties of the other, they are actually different topologies. Queues are "many-to-one" and events are "one-to-many".
You can use User Events "many-to-one” too. Create an Event, register for it yourself, then pass the Event to other processes so they can send you messages.
-
In rare cases the event queue can get muddled if the events are sent more quickly than the timestamp resolution can take care of. This leads to the events possibly being received IN THE WRO_NG ORDER. This is within the same event queue, and can be provoked even with the same event.
Can you provide a reference? I’ve only seen mention of that problem when the two events are in different event queues in the same event structure, such as a statically-registered event and a dynamically-registered one.
-
Hi jg,
Really like the tool, except, in addition to renaming, it also moves all the control labels: left centered for controls; right centered for indicators. I know this is a style preferred by many (but not me) and I wondered if this could be turned off? Or better yet, make it a separate tool.
— James
-
Random thoughts on User Events versus Queues:
— The event registration refnum is a queue, and it is more instructive to compare this queue to regular Queues rather than compare User Events to Queues. They have different extra features, but in basics they are the same; they serve up the enqueued items to one receiver in order. And one should not have more than one receiver per queue.
— The event structure itself can receive from multiple queues. In particular, the statically registered events are in a separate queue from any event reg. refnum attached dynamically. The order that items are served up from different queues is determined by timestamp. This means that near simultaneous events placed in different queues cannot be relied upon to be received in order. However, items from the same queue will always be in order, which means one can use a User Event to reliably carry messages to a process.
— A User Event can be thought of as an array of queues; firing the Event is the same as enqueuing to all the queues, and the Event Registration Node serves to add its queue to the array. When created, of course, the User Event is an empty array.
Random random thoughts:
— a “name” is a reference, the same as a refnum.
— “subpaneling” is a silly term

-
 1
1
-
-
I'm not sure where the claim comes from, about that understanding unsigned numbers is difficult.
From me. I find them a bit difficult. Just a bit.
-
1
-
-
The timers output unsigned U32 numbers, and the subtraction will produce the same U32. This cannot be less than zero so that code never executes. Which is not a problem since the subtraction will already handle the rollover satisfactorily; for example: 1 − 4294967295 = 2.
Understanding unsigned numbers and rollover is tricky; I usually have to experiment to remind myself how it works every time I have to do it.
— James
-
Welcome to the weird and wonderful frustrating world of Xcontrols.
Presumably they don’t bother to update the display when the FP is closed, but I would have thought that some event should be triggered when you open the FP so you could set the display state. But I couldn’t get your control to work.
-
Yeah, that's been int he LV help for years but to the best of my knowledge it's either simply wrong or hugely misleading. I work a lot with events and with subpanels and I've never encountered a problem. I hesitated for a long time because of this text in the LV help. I never understood what it meant.
I’m guessing this refers to a very limited list of events that could meaningfully belong to either VI, like “This VI>>Key down”, rather than the vast majority of events, like on controls, that only one VI can register for.
-
SDietrich, please see the updated package in the Code Repository. I have not tested it with an actual extension, so please report any problems. Thanks.
-
Good grief, why are there three?! Is there no functional overlap among them?
You only need to use one; they all wrap the C interface. SQLite itself is public domain, and such a valuable addition to LabVIEW that I feel there really needs to be a package that is free and unrestricted.
Shaun provides a high-level LabVIEW API for interacting with the database (with VIs like “Select”, “Create Table” and the like) which may be of interest (though personally I think it’s better to work with straight SQL).
SAPHIR’s… well, it’s a company and you pay for it so perhaps you get better tech support.
— James
BTW, you don’t need a database to do the other parts of my original suggestion. It just makes it easier.
Reading JSON into LabVIEW
in Code In-Development
Posted
Breaks parser:
Backslash quotes \” in strings (eg. "And so I said, \"Hello.\””)
Sort of breaks:
U64 and Extended precision numbers, since you convert numbers to DBL internally. Note that in both my and Shaun’s prototypes, we keep the numbers in string form until the User specifies the format required.
Possible issue?:
NaN, Inf and -Inf: valid numeric values that aren’t in the JSON standard. Might be an idea to add them as possible JSON values. Or otherwise decide what to do with them when you write code to turn LabVIEW numerics into JSON (eg. NaN would be “Null”).
— James