

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
I also looked into “public domain” and it seemed problematic.
I would be happy to get rid of the requirements on binaries (buried in some readme file that none ever reads). The attribution on source code, read by other developers, seems the only meaningful one, and this also create no burden on customers, since one just leaves the license in the code or documentation.
-
Repo is at: https://bitbucket.or...son-api-labview
Hi Ton,
This is my first use of Hg or bitbucket. I’ve got a bitbucket account, installed TortoiseHg and successfully downloaded the latest JSON version and created a small “change set” ready for “pushing” up to the repository, but my authorization fails. Do you need to add me to your “team”?
-
Can anybody explain about "Active Object: Queues to and from process" design pattern?

Haven’t use GOOP, but Daklu’s “Slave Loop” is an example of an active object with queues to and from the process. Actor Framework is another example, but Daklu’s design will be simpler to understand.
— James
-
To make the function faster and to avoid memory copy I use reference and controller/indicator is made "hade" on front panel to speed up.
Your deeper problem is one of abstraction; your taking the “wire branches make copies” abstraction too literally. Actually, the compiler will only make copies when necessary. And even if copies are made, it will take a lot of copies to match the low performance of storing data in UI elements (which mostly comes from necessary thread-switching into the UI thread). A DVR is what you should actually have chosen to avoid copies, although the best choice may have been to just let the compiler worry about about it.
-
I haven’t used this function, but I’ve done similar timing, and I find that both forms of timing ("since last", and “on schedule”) are both needed. There is no reason to prefer one over the other as default, and thus it would be simpler to stick with the current behavior as default, with the new one as an option.
-
First thing we could use are functions to convert between JSON-format strings and regular LabVIEW Text (escaped characters, encoding, add/remove the quotes). I’m weak on regex.
-
I’ve added a new version to the CR (sorry Ton, I will need to learn how to use Github).
I added a JSON to Variant function. Note that I’m trying to introduce as much loose-typing as possible (very natural when going through a string intermediate), so the below example shows conversion between clusters who have many mismatched types, as well as different orders of elements. It would be nice to think about what type conversion should be allowed without throwing an error.
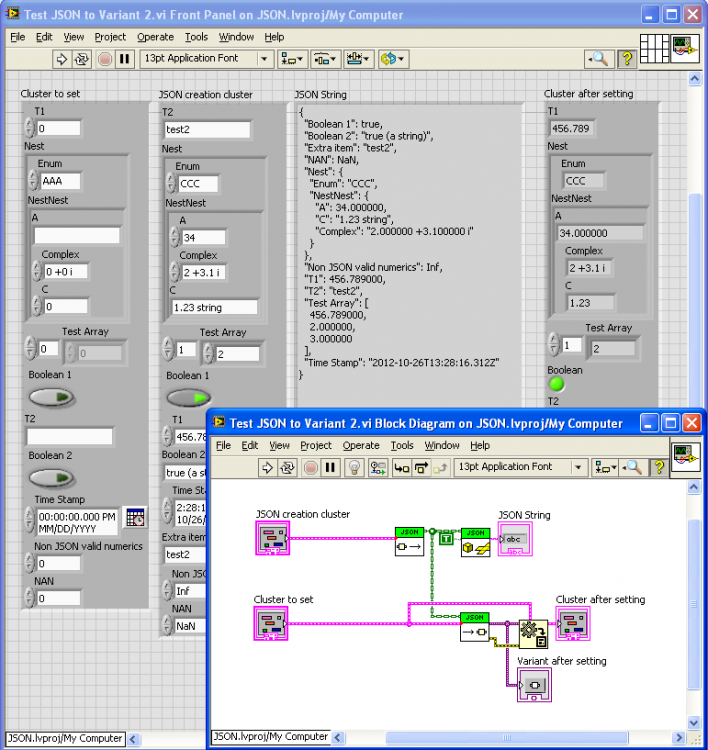
And I’ve started on a low-level set of Get/Set polymathic VIs for managing the conversion from JSON Scalers/Arrays to LabVIEW types (very similar to Shaun’s set but without the access by name array). I’ve reformatted two of Shaun’s VIs to be based of the new lower-level ones. The idea is to restrict the conversion logic (which at some point will have to deal with escaped characters, special logic for null (==NaN), Inf, UTF-8 conversion, allowed Timestamp formats, etc.) to be in only one clearly defined place. At some point, I will redo the Variant stuff to work off of these functions rather than relying on the OpenG String Palette as they do now).
-
That's what the law requires... you're the copyright owner. You have to do something to allow NI to use it. There's nothing NI can do on its own to appropriate the rights -- and you wouldn't want there to be a way to do that.
Could NI legal not just mail us a simple form to sign?
-
 1
1
-
-
You can be sued for anything you post to LAVA also if you didn't have the legal right to post it.
Oh, copyright violations. Thought you meant I could be sued for damages due to a very unfortunate manifestation of a bug in Trim Whitespace.
-
That one person then becomes the lightening rod for NI in the event that the others want to sue.
Uh, wait, what? Can I be sued for stuff I post on NI.com? Sounds like an argument to not post anything on NI.com. Ties back to my previous point about the NI.com Terms of Use containing disclaimers to protect NI but not posters; do I need to add a legal disclaimer to every post and uploaded sample VI?
And if something is adopted into LabVIEW, it becomes NI’s responsibility, surely?
Trim Whitespace is a prime example of a VI that cannot be BSD when it goes into the palettes... we can't require every user of LV to remember to thank the authors of that VI everytime they clean up a string.That’s why I like the “1 clause BSD”, dropping the binary requirement. The source code requirement is trivially satisfied by placing the license in the FP or BD or hidden away in the documentation.
Edit added later: found this link: The Amazing Disappearing BSD License
BTW to OpenG developers (JG if he’s reading): does OpenG not have some transfer of copyright to OpenG itself? It will be impossible to change licensing terms on OpenG once some of the authors die. I’d like to propose dropping the binary clause.
-
So if I understand Stephen correctly one of the things witholding NI from forking the code from LAVAG (amongst others) is the BSD requirement to have the author in the license notes of a binary. I can understand the 'tight coupling' argument by Stephen (NI==LabVIEW). We could create a special version of the BSD that would remove the attribution requirement for binaries.
I like Ton’s idea. And not just for NI; having to compile a list of all licenses to make available in an executable is a pain, especially as no one will ever read them. While providing a license in source code is easy if the license is already on the FP, or BD, or documentation of the VI’s themselves.
Not all the libraries there will ever be desired to be picked up by LV, only the ones that seem to have broad appeal, but those few, it seems to me, should have some way to allow movement of these libraries from the CR into the primary distribution channel (i.e. LV Base) without creating licensing headaches for all involved. What that mechanism is, I have no idea.
What about a test case? In OpenG there is a Trim Whitespace function that duplicates the same function in LabVIEW. Due to the work of several programmers, OpenG’s version has considerably higher performance. I don’t believe there is any other difference in function, no “advanced” features or anything, and thus no reason why the OpenG version shouldn’t be adopted as standard. What would it take to do this?
— James
-
1
-
-
Crud. Didn't think of that... I was thinking that you had just offered suggestions that drjdpowell acted on... but now that I revisit the thread, you actually contributed code.
My statement stands -- everyone has to act as they believe they can and should.
I could, presumably, post only the core part involving the JSON classes which I wrote, leaving out Shaun’s polymorphic accessors. Or I could get Ton and Shaun’s permission to post the whole thing (maybe; how does that work as only one person can actually post it on NI?).
-
I believe with the NI.com agreement...
My reading agrees with yours. Posting to NI.com gives NI an unrestricted license to do whatever they want with it. Further, I don't see why the authors of a work previously released under BSD can't upload it to NI.com and thus grant NI unrestricted use separate from BSD.
-
1
-
-
My understanding is... that at any moment AQ is going to rightly point out that it is only some lawyer's understanding that actually matters, and there is really no understanding of that.

For discussion, what about this unlicense:
This is free and unencumbered software released into the public domain.Anyone is free to copy, modify, publish, use, compile, sell, ordistribute this software, either in source code form or as a compiled binary, for any purpose, commercial or non-commercial, and by any means.
In jurisdictions that recognize copyright laws, the author or authors of this software dedicate any and all copyright interest in the software to the public domain. We make this dedication for the benefit of the public at large and to the detriment of our heirs and successors. We intend this dedication to be an overt act of relinquishment in perpetuity of all present and future rights to this software under copyright law.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OFMERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OROTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
For more information, please refer to <http://unlicense.org/>
-
On looking carefully at the BSD license the "JSON LabVIEW" is under, and at the "Terms of Use" governing posts on NI.com, I see that both have prominent legal liability disclaimers. BSD says that I'm not liable, while the Terms of Use only says that NI is not liable. Should I be concerned by that?
Also, I could not see why I, along with any other copyright holders of "JSON LabVIEW" couldn't legally upload the code to NI.com and thus trigger NI's ability to use the code unhindered by the BSD (I also didn't see anything that indicated that posted code is now owned by NI; just that, by posting, I grant them the right to so whatever they want with it).
-
Question:
As the author of a work released under BSD or some other license, am I not able to re-release it under another, less restrictive license, such as one waiving any attribution requirements? And can I not make it "public domain" with no licensing restrictions at all?
Also, as a side point. if I were a company that did not want to allow open-source code, I would certainly not allow arbitrary code posted to ni.com. That such code is legally owned by NI would be immaterial, as it is not tested or certified by NI. Only if such code became part of LabVIEW would it be acceptable.
Added later: I should explain that I always assumed that some companies did not allow Open Source software because of concerns about the quality of that code. But if the real issue is attribution and keeping track of all the licenses that have to be reproduced, then that is different. Personally, I don't really care about personal attribution beyond perhaps a note in the code itself.
-- James
-
I hate software licensing rules. Really hate them.
And I just don't understand them. I picked BSD because it seemed to be to be entirely permissive, except for an acknowledgment. It's not "copy left" which would prevent it from being used in a commercial product. Would making things "public domain" be any better?
And though I understand why some companies may shy away from open-source software, preferring all code to come from "approved vendors", how does posting things on NI solve this issue?
And for future knowledge, was it posting on the LAVA CR that creates the issue, or was it already tainted once we posted code in a conversation on LAVA?
Anyway, this answers a question I've long had: Why does OpenG need a different "Trim Whitespace" VI; why doesn't NI just adopt the higher-performance version as standard LabVIEW?
-- James
We need a distribution system that is lightweighted and reliableDo you not like VI Package Manger?
What should we do with NaN, -Inf, and +Inf? JSON does not support them. NaN could be null but the others I don't know.
Official JSON sets those three values to 'null' however I lean to this idea. For numerics we should use 1e5000 though.
I think some "JSON" implementations have (perhaps wrongly) allowed these
values, so it is probably a good idea to accept things like "Inf", "Infinity", "NaN" when parsing in JSON.
When writing JSON, a problem with the 1e5000 idea is that there is no defined size limit for JSON numbers; one could theoretically use it for arbitrarily large numbers. Not that I've ever needed 1e5000
Maybe there should be an input on "Flatten" that selects either strict JSON or allows NaN, Inf and -Inf as valid values.
BTW, i'm on vacation without a LabVIEW machine so I'll comment on the excellent code additions when I get back.
-
I would. There are a lot less "working" things in there already
Alternatively. Start a new thread.Indeed. I have to be very careful about dependencies. Some clients insist on "approved vendors" or "no 3rd Party/open source" and, for most of the stuff in OpenG that I would use; I have my own versions that I've built up over the years. It's just easier not to use it than get bogged down in lengthy approval processes.But won’t this package be 3rd party/open source? To everyone but us at least. And OpenG is a “Silver Add-on” on the LabVIEW Tools Network (oooh, shiny!).
-
- Popular Post
- Popular Post
JSON LabVIEW
JSON is a data interchange format (sometimes compared to XML, but simpler). There are multiple projects to create a JSON package for LabVIEW. This is yet another one motivated by this hijacked conversation originally about a different project to convert JSON into LabVIEW Variants.
This project uses a set of LVOOP classes to match the recursive structure of JSON, rather than variants. It allows conversation to and from JSON. All functionality is available through two polymorphic VIs: Set and Get. In addition to Get and Set VIs for common data types, one can also convert directly to or from complex clusters via variant-JSON tools.
Copyright 2012-2016 James David Powell, Shaun Rumbell, Ton Plomp and James McNally.[Note: if you are using LabVIEW 2017, please also see the JSONtext library as a an alternative.]
-
Submitter
-
Submitted10/04/2012
-
Category
-
LabVIEW Version
-
3
-
Ah, non-uniform spacing, I see.
Greg,
My first thought would have been to truncate the weighting calculation and fitting to only a region around the point where the weights are non negligible. Currently, the algorithm uses the entire data set in the calculation of each point even though most of the data has near zero weighting. For very large datasets this will be very significant.
— James
BTW> Sometimes it can be worth using interpolation to produce a uniform spacing of non-uniform data in order to be able to use more powerful analysis tools. Savitsky-Golay, for example, can be used to determine the first and higher-order derivatives of the data for use in things like peak identification.
-
I would not be able to help you for a few weeks as I’m off on vacation. I can see why your smoothing functions so slow and I’m sure someone could easily improve it’s performance by orders of magnitude on large data sets. However, are you sure you would not be better served by using one of the many “Filter” VIs in LabVIEW? I tend to use the Savitsky-Golay filter, but there are many others that can be used for smoothing. They’ll be much, much faster.
-
Do they need to be utility VIs?
I don’t mean utility VIs for the User of the API, rather, I mean “utility” for writing the package internally. Conversion to/from valid JSON string format will be required in multiple places. I tend to call subVIs, needed by the class methods, but not themselves using those classes in any way, “Utility” subVIs.
If I remember correctly, as long as you keep the copywrite on the VI and. perhaps, the documentation, you can use, modify and do pretty much what you like with them (someone in the OpenG team could advise). It may be possible to rename (so they don't clash) just the variant stuff (there's only a couple) and include them in the package so it is then completely self contained with no dependancies.There’s a good 30+ VIs in dependancies. Copying all that to support my variant-to-JSON stuff is excessive. Compare it with just changing the one “remove whitespace” subVI to make the rest of the package independent. But as I said, it should be easy to make the variant stuff an optional add-on, for those who don’t mind adding a couple of OpenG packages.
Might I suggest you place it in the unconfirmed CR so that we can make a list of things that need to be done and to manage it?. We've been rather obnoxious in hijacking JZollers thread-my apologies JZoller!
Is it OK to put unfinished stuff in the CR, even uncertified? I’m afraid I’m about to go on two weeks vacation, but I could put what we have to this point in the CR and commit some free time finishing it when I get back. Don’t whip up a thousand and one pretty polymorphic instances until we get the core stuff finished.
 Yeah. There is a re-use library consisting of about 10 VIs for mundane stuff. That's about all I need from project to project. Everything else is self contained APIs
Yeah. There is a re-use library consisting of about 10 VIs for mundane stuff. That's about all I need from project to project. Everything else is self contained APIs
At some point I switched from not using OpenG if possible, to considering it “standard LabVIEW”. VIPM making it so easy probably contributed to this shift.
-
Nearly. Flatten adds things like quotes and brackets. For conversion, these need to be removed.
The package needs a pair of utility VIs that convert strings to/from the JSON valid form (in quotes, backslash control characters, possible unicode encoding).
It's not a case of liking. There's some great stuff in there. It's a case that not everyone can use OpenG stuff. It's also not really appropriate to expect someone to install a shedload of 3rd party stuff that isn't required just to use a small API (I had to install OpenG especially just to look at your code and uninstall it afterwards)The variant-to-JSON stuff could be kept separate as an optional feature that requires OpenG (a lot of work to rewrite that without OpenG). Otherwise, I think I just used the faster version of “Trim Whitespace”, easily replaced.
-
I made a slight change to your lookup by adding a "To String" in each of the classes to be overridden. This means that the polymorphic VIs become very simple (Not mention that I could just replace my lookup with yours, change terminals and, hey presto, all the polys I've already created, with icons, slot straight in
).Nicely done!
Though I think you didn’t need “To String”, as “Flatten” does the exact same thing. I never thought of using the JSON string form internally to make the outer polymorphic API easier. Great idea.
I've back-saved it to 2009 so others can playNot sure how many are still reading.
 Next on my list is to get rid of the OpenG stuff.
Next on my list is to get rid of the OpenG stuff.Don’t like the OpenG stuff? I love the Variant DataTools.
— James

[CR] JSON LabVIEW
in Code Repository (Certified)
Posted
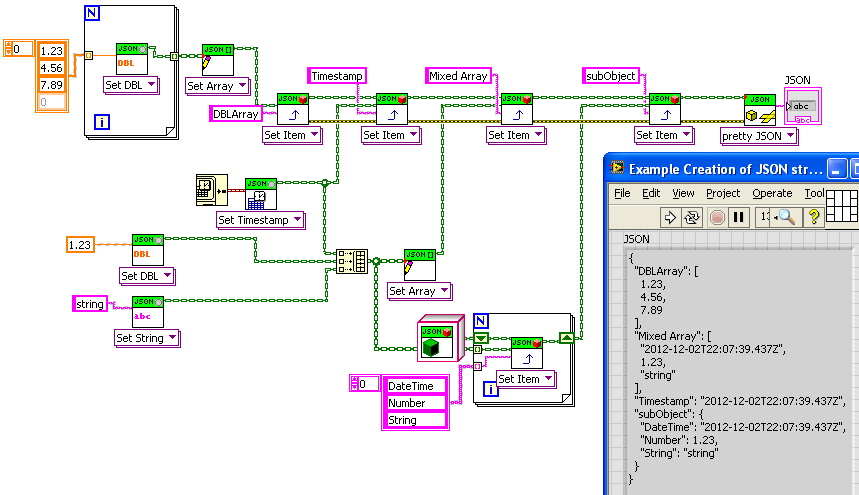
Just added some improvements to the bitbucket repo. Below is the new “Example Extract… V2” example using the polymorphic Get function. Note that there is no object type casting now, as the function do the casting themselves (throwing an error if the input type is invalid).
I’ve also been working on meaningful error messages. On issue I’d like comment on is getting an item in a JSON object when the object isn’t found. Currently this is not an error, but just makes the “found” output false. I would rather get rid of the “found” output and make it an error instead.
— James