

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
Do you have an example? Seems I would have to create a listener on the receiver side for every 'potential' sender. Since the receiver does not know who the senders might be, I can't think of how to do that.
There is only one listener. It listens for clients on a port and creates connections (one for each connected client). Those connections can be serviced either by polling through them or by dynamically spawning a connection handler for each. But there is only one listener.
-
The reason I went with this message architecture is it was the only one I could think of that did not require any polling on the receiver's part.
One can do a “Server” without polling, if one dynamically spawns new processes to handle each connection. Though dynamic spawning brings one right back to the root loop problem...
-
Why are you using VI Server, rather than other communication methods (like TCP, Network Steams or Shared Variables)?
-
I sure wish this worked with Variants. In fact, I may post that as an idea on the Idea Exchange; a “Preserve Run-Time Type” function for Variants.
-
My question is what exactly is the difference between this and the stock downcast. I believe the downcast will also throw an error if the cast cannot be done.
Illustration:
A Child object on a Parent-type wire being cast into a "target" Grandchild object on a Parent-type wire will produce an error with PRTC (note that the “stock downcast” works on wire types, not the actual objects).
The point of this is that the compiler can be certain that the object coming out of the PRTC is the same as the target object; this means it can trace through the input wire type to the output of the subVI at edit time. So if you write a subVI with Parent inputs and outputs, and connect a grandchild wire to the input, the output wire will take on grandchild type. See below an example subVI I made recently using PRTC; note that I can “pass through” wires of different object types (the actual subVI uses LVObject inputs and outputs).
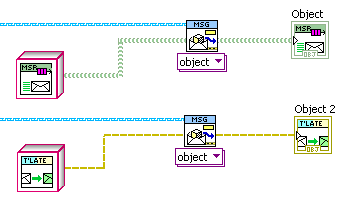
I should add that the PRTC is only needed if the compiler cannot already tell that the object out is the same as the object in. In my subVI above, I’m receiving an object in a message and using PRTC to “cast” it as an object of a specific type. Inside the subVI, the wires are LVObject, so the stock cast functions do nothing.
It is confusing at first.
-
Latest version, as a VIPM package, posted to the CR.
-
Messenger Library
An extensive library for passing messages between parallel processes. Generalizes the communication method, allowing the message sender to use the method provided by the receiver. Supported communication methods include wrappings of simple queues, user events, and notifiers, as well a more complex channels such as a TCP server and client. In addition, one can configure simple forwarding addresses (“Observers"), which can send messages to multiple destinations, optionally with modifications such as adding a prefix to the message label, relabelling, or substituting a different message.
Communication patterns supported include request-reply (asynchronous or synchronous), where the reply is sent to a "reply address" attached to the request, and register-notify, where one process sends a registration message to another in order to subscribe to a series of updates. Also supports scatter-gather, the gathering of replies from multiple senders into an array of messages.
An option framework for dynamically-launched VI "actors" is also provided, including example templates, which can be accessed via the Tools menu (from an open Project, select Tools>>Messenger Library>>Create Actor from Template..). An "Actor Manager" debug tool is also installed under the Tools menu. Please note that this package has nothing directly to do with the NI Actor Framework (other than both packages are influenced by the Actor Model).
***Introductory Videos are on a YouTube channel.***
***A great summary of many Messenger Library sources, provided by Bob W Edwards***
JDP Science Tools group on NI.com.
Original conversation on this work is here.
Now hosted on the LabVIEW Tools Network (but note that the latest version will often be on LAVA)***NOTE: latest versions require VIPM 2017 or later to install.***
-
Submitter
-
Submitted11/27/2012
-
Category
-
License TypeBSD (Most common)
-
 1
1
-
-
When I run the highlight execution the queue get the correct size of elements, 5 in this case, then the event structure flush the queue, and start again from element 1 to 6, 5 again but this time it doesn't trigger the event structure and the for loop keeps waiting.
That’s because the second time around your are setting N=6, so the FOR loop needs to execute six times, but the queue only holds 5, so it gets stuck waiting.
-
1
-
-
Your second mistake was in wiring the buffer size to the max queue size of the obtain queue node. The top loop is filling the queue with five elements and waiting for the bottom loop to respond, which it never does because of the way an Event structure works (see below).
Actually, he needs that to throttle the producer loop to always provide “buffer” number of elements to the consumer loop. Instead, he has a bug in setting the number of iterations of the inner FOR loop (it should be “buffer”-1); removing that, the “buffer full” locals, and adding a Val(signal) property makes the code work.
But this is all academic as...
This is a very over-engineered way of doing what could be done with one simple loop with “Array Subset” in it. I recommend the OP start from scratch after resolving not to use any local variables, queues, or event structures.
— James
-
The "good" news is the leak is not cumulative, you get only one leak for each VI that is operated on regardless of how many times you call Set Busy.vi on that VI.
Should that meaningfully be called a “leak” then?
-
LVOOP is by value, with the values on the wires, so if there are no terminals there is no object.
-
That's right (and I have never used any software from LavaG in a commercial application). However, it is much easier to gain approval for a single self contained API than it is for one that relies on another 20 (like the OpenG).
The JSON package currently depends on four OpenG packages: Data, Array, String, and Error. The array stuff is only used in one place that I’d like to rewrite anyway, so it is only three packages that are required. And the variant-handling stuff is widely applicable; if I wrote Variant-based APIs to be “self contained”, I would quickly wind up in a situation where I have multiple non-identicle sets of variant-handling VIs installed on my machine. Not ideal. Switching to using the off-palette VariantDataType VIs installed with LabVIEW is one option, but then if NI hasn’t put it on the palette, don’t you need to gain approval for that?
-
Saying that. I use the vi.lib getTypeInfo,GetCluster/numeric etc but I haven't bench-marked them since they are "Hobsons Choice" for me.
I’m pretty sure you’ve got some non-UI thread substitutes lying around. I think you posted one once.

-
Changing it programmatically in the "Mouse Down?” event doesn’t work?
-
Yeah. Well its got LVPOOP in it so that's not an option.

Theoretically, the not-on-the-pallet VIs in vi.lib\Utility\VariantDataType should blow the OpenG stuff out of the water, as OpenG has to flatten the data to access it (expensive), but my only experience with the VariantDataType Vis is that they are glacially slow.
-
If you can wait until next weekend, I'll replace all the openG stuff so it's a self contained lib. Just a bit busy at the moment finalising the websocket demo, but that will be finished this week.
OK, but to me it seems silly for anyone to avoid OpenG yet use this (far, far less tested through experience) third-party open-source software. I’d rather offer the whole package to OpenG.
Now, do it with higher performance and you’ll get me interested.

-
Shaun,
I am looking at the VIPM package that Ton and I have put together. Shall we divide into two packages, one not dependent on OpenG and one that contains all the Variant stuff? So people who can’t use OpenG can still use the core functions or your extended API? I can do that just be replacing one OpenG function, Trim Whitespace, in the core (can we use your “Fast Trim” instead).
Ton,
You currently have the package installing under LAVA; don’t we need a LAVA tools approved package before doing that?
-
To be clear, Args was just a normal cluster, nothing Varianty about it. Ton
Ah, I though your “variant arguments” were variant attributes and couldn’t understand how you were doing that.
-
This allowed me to have a cluster with optional variant Arguments flatten well:
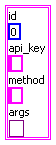 into:
into:{"api_key":"xx","args":{"owner":"ton","repo_name":"repository","repo_type":"hg"},"id":915,"method":"create_repo"} (with args)
or
{"api_key":"xx","args":{},"id":378,"method":"get_users"} (no args)
Hi Ton,
I cannot, for the life of me, tell how you got this behavior before (where in the code were the attributes extracted?) but it seems like a good idea so I added it to “Variant to Cluster”. Though I made an empty variant with no attributes “null”, rather than an empty object.
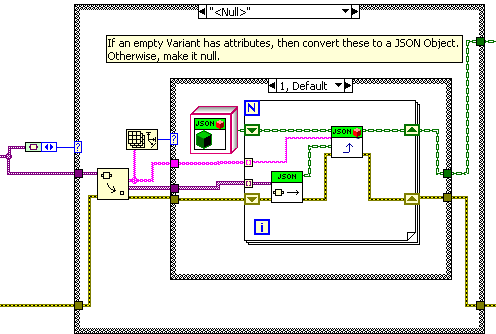
Note that a non-empty variant will ignore the attributes and convert the contained value instead.
-
I'm assuming that a situation where OVR returns both an error and a half-valid ref is a bug, but it looks like it still can (or at least could) happen.
Was it really “half-valid”, or just invalid but non-zero?
-
The close function won’t cause a leak if passed a previously closed or invalid reference. However, if the problem is not that the reference was closed, but instead you lost the correct open reference due to a bug in the code upstream, then that still-open reference could be a leak. So make sure the reference actually was properly cleaned up somewhere else.
-
Are you suggesting that if the JSON stream has a double and an Int is requested then it should throw an error?
Oh no, definitely not that.
I mean what if the User requests:
— the string “Hello” as a DBL? Is this NaN, zero, or an error? What about as an Int32? A timestamp?
— for that matter, what about a boolean? Should anything other than ‘true’/‘false' be an error? Any non-‘null'/non-‘false' be true (including the JSON strings “null” and false”)? Or any non ‘true' be false (even the JSON string “true”)?
— “1.2Hello” as a DBL? Is this 1.2 or an error?
— or just “1.2”, a JSON string, not a JSON numeric? Should we (as we are doing) allow this to be converted to 1.2?
— a JSON Object as an Array of DBL? A “Not an array” error, or an array of all the Objects items converted to DBL?
— a JSON Scalar as an Array of DBL? Error or a single element array?
— a JSON Object as a DBL? Could return the first item, but Objects are unordered, so “first” is a bit problematic.
And what if the User asks for an item by name from:
— an Object that doesn’t have that named item? Currently this is no error, but we have a “found” boolean output that is false.
— an Array or Scalar? Could be an Error, or just return false for “found”.
Then for the JSON to Variant function there is:
— cluster item name not present in the JSON Object: an error or return the default value
Personally, I think we should give as much “loose-typing” as possible, but I’m not sure where the line should be drawn for returning errors.
-
I’m talking about errors in the conversion from our “JSON” object into LabVIEW datatypes. There are also errors in the initial interpretation of the JSON string (missing quotes, or whatever); there we will definitely need the throw errors, with meaningful information about where the parsing error occurred in the input JSON string.
For debugging type conversion problems, one can use the custom probes to look at the sub-JSON objects fed into the “Get as…”; this will be a subset of the full initial JSON string.
BTW, heres the previous example where I’ve introduced an error into the Timestamp format (and probed the value just before the “Get”):
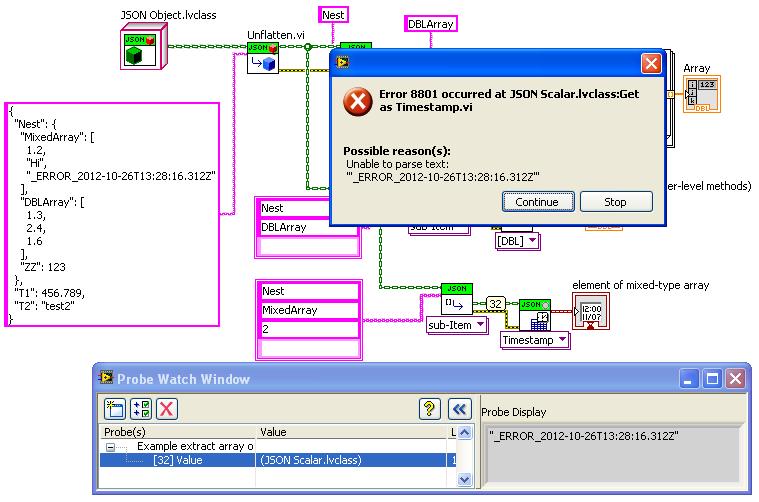
-
Actually, another possible error choice is to basically never throw an error on “Get”; just return a “null” (or zero, NaN, empty string, etc.) if there is no way to convert the input JSON to a meaningful value of that type (this follows the practice of SQLite, which always provides value regardless of a mismatch between requested and stored data type). Then perhaps all “Get” instances should have a “found” boolean output.
Ton, Shaun, what do you think?
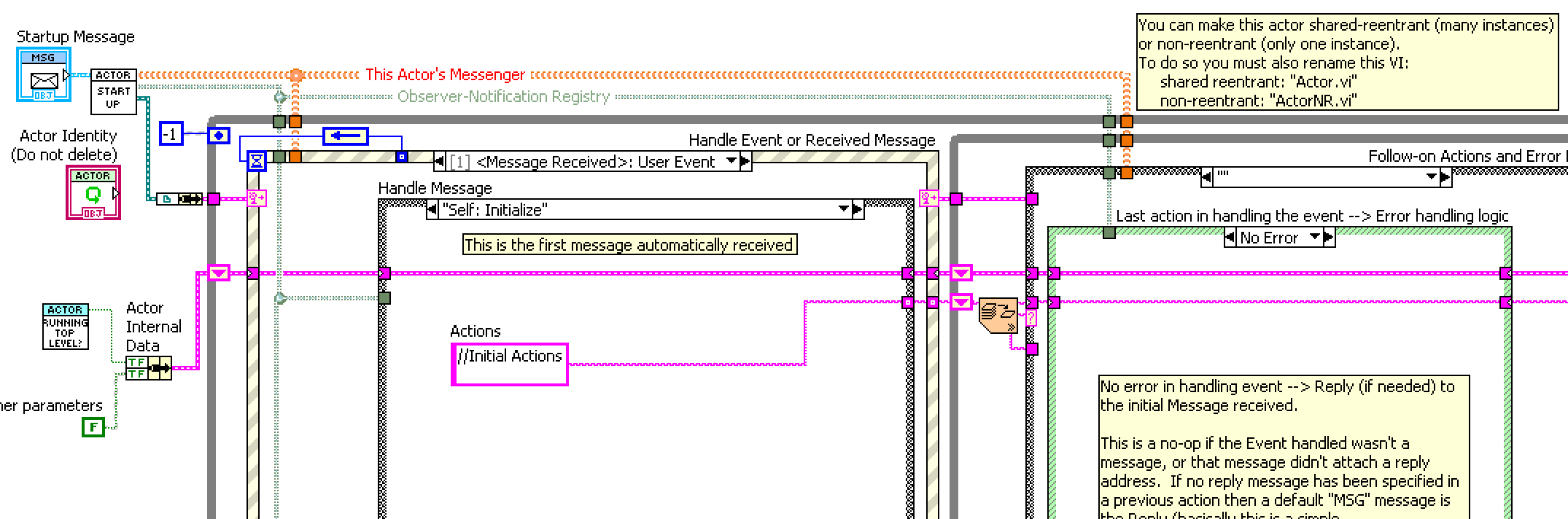

Network Messaging and the root loop deadlock
in Application Design & Architecture
Posted
Also see the NI examples “DataServerUsingStartAsynchronousCall” or “DataServerUsingReentrantRun”.