drjdpowell
-
Posts
1,988 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
Note to Darin on in his Champion’s profile picture: I recognize that hardware! Axions! Or search therefore. Did a very little bit on it as a Post Doc long ago. I’m very, very least author on an axion Phys Rev Lett from 1998 (I see from my CV that you're second author). Found those things yet? — James
-

Object serialization (XML) and LabVIEW
drjdpowell replied to PaulL's topic in Object-Oriented Programming
I was under the impression (from a post somewhere by AQ) that lvclass references work in run-time as of 2010. -
closed review Suggestions for OpenG LVOOP Data Tools
drjdpowell replied to drjdpowell's topic in OpenG Developers
Oh good! Having to put those terminals in was annoying. I second the suggestion to go without the terminals. Though we might want a temporary note in the VI descriptions and/or on the block diagrams explaining this issue. — James -
Oh, man… The number of times I’ve double clicked on a subVI, double clicked on its icon to bring up the editor, made a copy, closed the editor, opened another VI’s editor, pasted. What a waste of time!
-
Self-addressed stamped envelopes
drjdpowell replied to drjdpowell's topic in Application Design & Architecture
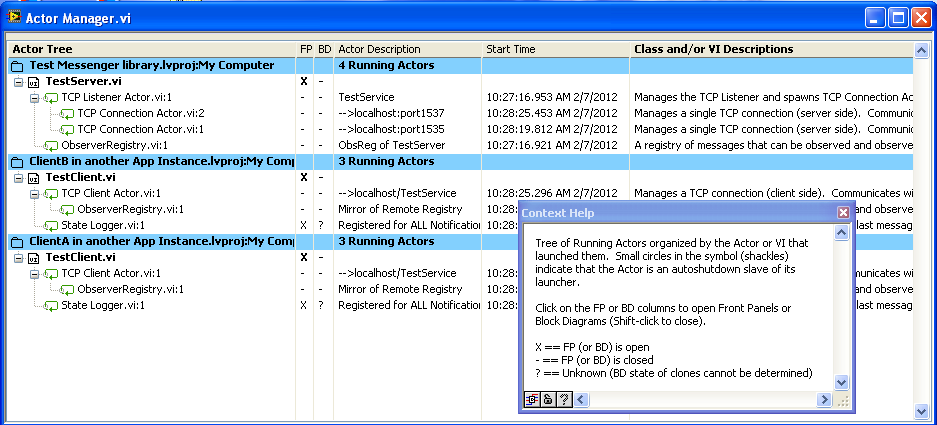
Oh, the new version will also contain the “Actor Manager” (I’ve started to call my “Parallel Process” things “actors”, it’s a lot shorter and is an established computer science term) which makes knowing what’s running, and accessing the Front Panels or Block Diagrams, much easier. Below is a tree of actors running TCP communication tests (same computer, but three different projects): If one tries something complicated, with umpteen copies of “Observer Register” or “Metronome” used in different ways, this really helps diagnostics. As does being able to quickly open the Block Diagram of any actor and place the “MessageTable” probe to observe the incoming message stream. — James
-
Self-addressed stamped envelopes
drjdpowell replied to drjdpowell's topic in Application Design & Architecture
Hi monzue, thanks so much for your highly positive feedback! Gives me the impetus to push forward and get a new version in the Code Repository. I wasn’t aware of anyone using this, and I apologize in advance as updating your code to use the new version will involve a couple of tedious hours tracking down and replacing VI’s that have moved/been renamed/put in a different library. I’ve done a lot of reorganization. It looks scary the first time you open a VI that can’t find some of its classes, since all the class methods show up as question marks, but it is usually easier than it looks to fix by just replace the missing class constant, with all the methods magically reappearing. I promise to make the next version more finalized so you don’t have to do it again. Alternately, feel free to take the previously posted version and build on it to make it your own. The new version will have the TCP Messengers shown above, though, which is a major new feature if one has a distributed application (unfortunately, I don’t have a distributed application at the moment to really test it on). It will also have the above "Asynchronous Dialog box” and Futures. BTW, what LabVIEW version are you using? I have recently upgraded from 8.6 to 2011, and I was going to use the new “Async Call by Ref” node of 2011 in place of the “Run” method for launching VIs (this has very important performance advantages), but I could try and keep a separate 8.6 version available. It’s more (unpaid) work for me, so I need to know if there’s a need. Thanks again, — James BTW on the Actor Framework: My Messenger library is the work of a lone programmer who’s interested in easy use of dynamic VIs talking to each other. The Actor Framework comes from a very different perspective, that of a framework for a diverse team of programmers working on a large project, where restrictions are needed to prevent hard-to-see flaws compounding into severe problems. I don’t have the multi-programmer experience to analyze my Messenger library from that perspective. -
Not trying to hassle AQ. OK, a hopefully constructive hassle. One problem with complex designs is that people rarely take the effort of digging into them enough to make a constructive criticism of them. I was lamenting that fact one day (since I have complex design posted here myself) and I thought I really should make an effort. I’d be happy for AQ to point out the security flaws in my own, made by lone developer with an eye only for flexibility, designs. Or of other worthy ActorFramework-like targets, like mje’s “MessagePump". — James
-
Selecting which child class to cast to.
drjdpowell replied to SteveChandler's topic in Object-Oriented Programming
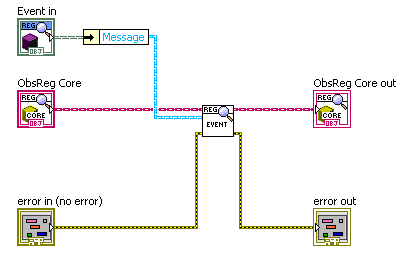
Ah yes, this makes a lot more sense. It does appear to be the command pattern. Call your “execution” class “Command for <name of class command is for>” and your “children” “Command A”, etc. Your dynamic VI dispatches off of the Command child class, but the actual work is done with methods of the class the command is for. Here is a command-pattern execute method of mine, looking very similar to yours: Note, btw, that one can put needed parameters inside the command object, such as the “Message” in my example. — James
-
Selecting which child class to cast to.
drjdpowell replied to SteveChandler's topic in Object-Oriented Programming
Still not understanding. The dynamic VI to execute is determined by the class of the object passed along the wire. It almost looks like you are trying to change the class of the object coming in through the “Parent.lvclass” control terminal. Or that you want to be able to call the VI for ClassA on an object of Parent Class. One can’t do either off those things. -
Selecting which child class to cast to.
drjdpowell replied to SteveChandler's topic in Object-Oriented Programming
The difference between objects and wire data types, and the different possible meanings of “coercion”, can be rather confusing. -
Selecting which child class to cast to.
drjdpowell replied to SteveChandler's topic in Object-Oriented Programming
Not really, I’m afraid. The “too more specific class” function only affects the wire types. Your saying “stuff the object on this parent wire into this child wire, if possible”. But though your selector returns a child object, that’s at runtime, not edit time, where the wire type out of the index array can only be the parent wire. So “too more specific class” isn’t doing anything here. Does that help? I can’t actually tell what you want to happen. Actually, what are you using to get the name of the class in your subVI? Is that what isn’t working? — James -
Object serialization (XML) and LabVIEW
drjdpowell replied to PaulL's topic in Object-Oriented Programming
What about using the LVClass references (like here) to determine the default object’s data clusters? AQ says that LVClass references are very slow, but, one could keep a look-up table of the needed information inside the Flattening VI (i.e. each object type needs to have its default info determined only once). I was looking into this stuff a few weeks ago, and it seemed to me that one could get around the “default” issue this way. Then one could make a VI that flattens an object, and then fills in the missing default pieces. One could also make VIs that alter the cluster values this way (I was actually thinking of making a VI that could take objects of different types, such as parent/child, and copy from one the the other all the common levels of cluster data). I never did any actual tests, so there may be a roadblock, but I think LVClass references can give one the information one needs. — James -
Who you calling fast? That’s the first time I measured it and I thought it was slow. Something built for speed would be much faster. But Property Nodes, and anything that runs in the UI thread, are REALLY slow. Using a waveform for individual reading does NOT seem like a good idea. Why not just store two channels: “Measurement” and “Measurement_Time”? That’s what I do. I’ve never noticed a problem with subpanels, but I’ve never looked into the speed. I’ve never done anything like that. Usually, I have most of the detail of an instrument in it’s own Front Panel, with only the key summary on a main screen of the whole application. So, for example, if I have a temperature controller, the main app might just show the temperature, the set point and some other summary info (like “ramping”). Clicking on the temperature indicator (or selecting from a menu or whatever) would bring up the “Temperature Controller Window” (could be in a subpanel) with a full set of controls (PID settings, maximum temperature, alarms) and indicators (chart of last ten minutes temperature and heating). The secondary window would be specific to that controller, so it doesn’t need adjusting, while the main app window would have only the general info that doesn’t need to be changed if you use a different controller. Another technique is to realize that most simple indicators are really just text, or can easily be represented by text, and thus one can do a lot with a multicolumn listbox or tree control to display the state of your instruments. — James
-
Actually, I’d expect sending a message via a queue and updating a terminal to be faster than using an indicator reference and a property node. Property nodes are quite slow. I did a quick time test with the messaging system I use (which is very similar to Lapdog); a round-trip command-response (i.e send a message via one queue and get a response back via another) was about 250 microseconds, or about 130 microseconds per leg. A single Value Property node on a Numeric indicator was between 300 and 500 microseconds. Also, note that a delay is unimportant if it’s equal at each end; the relay indicator will still be on for 50ms. One could also switch to indicating heater duty cycle (x%) rather than flash an LED. — James
-
Shortcut Menu Utility VIs for OpenG?
drjdpowell replied to drjdpowell's topic in OpenG General Discussions
Ah. I don’t use it to change the menu at run time. I use it to make adding/chnaging options very easy. If I needed a new option, say display the X scale in photon energy instead of wavelength, I would just drop a boolean in the Options cluster and name it “Display X axis as photon energy”, and go change the display update code to read that option. Job done. No need to manually configure a runtime shortcut menu, then write code to interpret the tags and set the appropriate state parameter in the shift register (with all the additional potential for bugs/misspelling). Also, if the Enums are type-defs, the menu will automatically adjust to changes in the type-def, without me having to manually update the runtime menu. Basically, it avoids doing something (defining the options) twice, in the code and in the menu setup, and avoids the necessity of custom interface code between the two. -
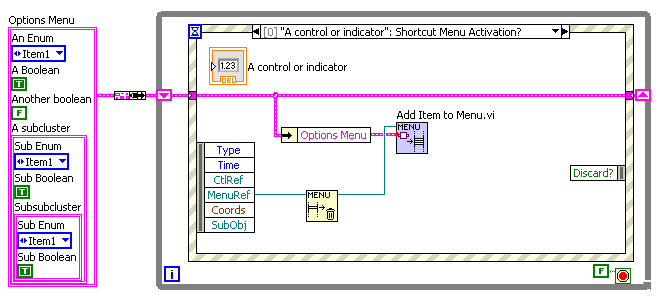
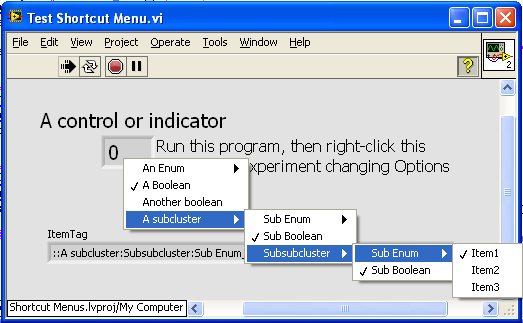
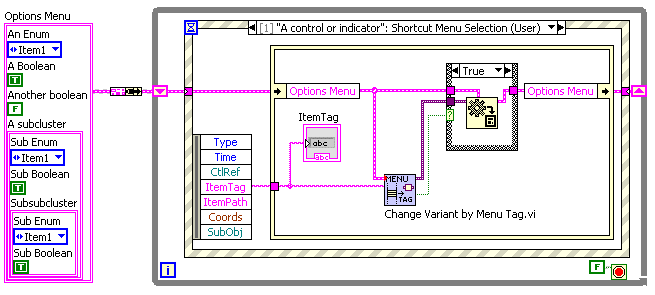
Hello, I use shortcut menus a lot, particularly for setting display options on graphs and charts. I have a pair of VIs that I use for this that leverages the variant data tools of OpenG, and I wondered if they, or something like them, would be a useful addition to OpenG. I’m not sure if they are quite right, but even if they are too specialized for my way of using menus, perhaps there are other more general VIs that exist for helping configure menus. So here they are for comment: The basic use case is shown in the top image; I have a shift register of program state parameters, including a number of options. When the User right-clicks on a control/indicator (a numeric in this example, but more usually it is a graph or listbox) the options are inserted into the shortcut menu via the VI “Add Items to Menu”. This VI can handle booleans, enums, and clusters thereof. The second image is the front panel and the pulldown menu that results. The third image shows the Shortcut Menu Selection case, where a second VI, “Change Variant by Menu Tag” (needs a better name) interprets the selected tag and updates the cluster of options accordingly. It also has a “Changed?” output that can be used to trigger redisplay with the new options. As I said, I’m not sure if these are general enough for OpenG, but perhaps someone else has a set of reuse menu VIs that might be more suitable. Menus are a UI feature that is very valuable, IMO, and they could do with some OpenG support. — James Shortcut Menu Utilities.zip
-
Need LVOOP Object VIs in lvdata library
drjdpowell replied to Jim Kring's topic in OpenG General Discussions
I noticed that the first call to either “GetTypeInfo” or “Get LV Class Path” is very slow, between 3 and 16 milliseconds, but only for the first one of the two called. So they must both access the same (very slow on first call) thing. Quick Tests: 1) Stub the Variant —> faster 2) set UI Thread —> much slower! That could be it. -
One could use a symbol in the label to indicate excluded controls, like “_Numeric”.
-
Need LVOOP Object VIs in lvdata library
drjdpowell replied to Jim Kring's topic in OpenG General Discussions
Takes a coffee break half way though. NI’s not paying it enough for “high performance”. -
closed review Suggestions for OpenG LVOOP Data Tools
drjdpowell replied to drjdpowell's topic in OpenG Developers
How does the new “inline” option play in to that? In has always seemed strange to me that OpenG VIs are mostly non-reentrant. It makes them different from the LabVIEW primitives that they supplement/extend. But that might be a different conversation. Though I note that you did remove the “Get Default” subVI from “Return Class Name” to improve performance. In doing so you eliminated the self documenting advantage of the subVI; a new LabVIEW user will be mystified as to what “Preserve RunTime Class” is doing here. Would it not be better to “inline” that subVI and use it? Or just accept a performance hit (which I think is quite small)? At the very least we need a comment here. Side Note: I noticed that OpenG has an off-palette subVI for parsing a PString (“Get PString_ogtk”) that is used in the Variant VIs. Perhaps that should be used in “Return Class Name”, where we are walking along a set of PStrings? The only advantage is getting the short name slightly faster, but that is probably not a good enough reason for a separate VI. BTW, maybe we should call the short name form “Base Name” or “Class Base Name”. Everything else looks fine to me. The only quibble is that the documentation for “Return Class Name” singles it out as being “highly inefficient” when it is considerably more efficient that many VIs that ship with LabVIEW, such as the VariantType Library or “Get LV Class Path”. But ignore the quibble. — James -
Need LVOOP Object VIs in lvdata library
drjdpowell replied to Jim Kring's topic in OpenG General Discussions
I tried making Shaun’s VI normal priority, not inlined, debugging on, and non-reentrant with the FP open: only slowed it down to 18 microseconds. So that isn’t it. -
closed review Suggestions for OpenG LVOOP Data Tools
drjdpowell replied to drjdpowell's topic in OpenG Developers
Hi JG, great work! Please see my previous post where I introduced the object outputs. At least when calling these VI’s in a For Loop on an array of objects, the lack of an output seems to require a copy of the object, leading to poor performance for large objects. This adds (in my tests) more than 150 microseconds of execution time for objects containing a 1 million U8 byte array. This compares with times of between 1 and 10 microseconds for the various proposed VIs with object outputs (note, I don’t even need to connect the outputs). Admittedly, I don’t particularly like having outputs, especially on comparison VIs, but the performance difference is potentially large. Large enough for me to have to worry about it and have custom “high-performance" versions of the VI’s to use if it matters, or just use the raw code in each case. This would eliminate most of the advantages of putting these VIs in OpenG. You did a similar thing in replacing the “Get Default Object” subVI in the Name VI; I want to avoid that kind of thing as much as possible. Note, also, that having object outputs, though not consistent with other OpenG VIs, is consistent with how LVOOP methods are written, where even “Read” methods have an object output. So, I would strongly argue for these outputs, and encourage any lurkers to comment on this one way or the other. I’ll write more later, gotta go... — James -
Need LVOOP Object VIs in lvdata library
drjdpowell replied to Jim Kring's topic in OpenG General Discussions
Strange. I put ShaunR’s VI (which seems to just call into LabVIEW.dll) into my speed tests using small objects, and it executes in about 8 microseconds, while the “GetTypeInfo” VI (the password protected one, which I would have thought does exactly the same thing) executes in 240 microseconds!!! Comparable OpenG functionality (based on the int16 type array) executes in 22 microseconds. I wonder what extra overhead is in that password-protected VI? — James -
Need LVOOP Object VIs in lvdata library
drjdpowell replied to Jim Kring's topic in OpenG General Discussions
OpenG it is then. Who’d have thunk flattening and parsing would be the “high performance” method. — James -
Need LVOOP Object VIs in lvdata library
drjdpowell replied to Jim Kring's topic in OpenG General Discussions
Are there plans to improve the performance of the VariantType library? The few VIs I’ve tested seem to be about an order of magnitude slower than equivalent OpenG functionality based on parsing the Int16 type array. I never use them as result. — James