G-CODE
-
Posts
41 -
Joined
-
Last visited
-
Days Won
2
1 Follower

G-CODE's Achievements
")





-
What about this... https://www.jki.net/profusa?hsLang=en or this... https://www.jki.net/radx?hsLang=en or this... https://resources.jki.net/smarter_sorting or this... https://resources.jki.net/femtometrix-case-study or this... https://www.jki.net/apollo-fusion?hsLang=en or this... https://www.jki.net/kairos-power
-
Same thing just happened to me in LabVIEW 2020. It's the malleable VI with the broken wire.

-
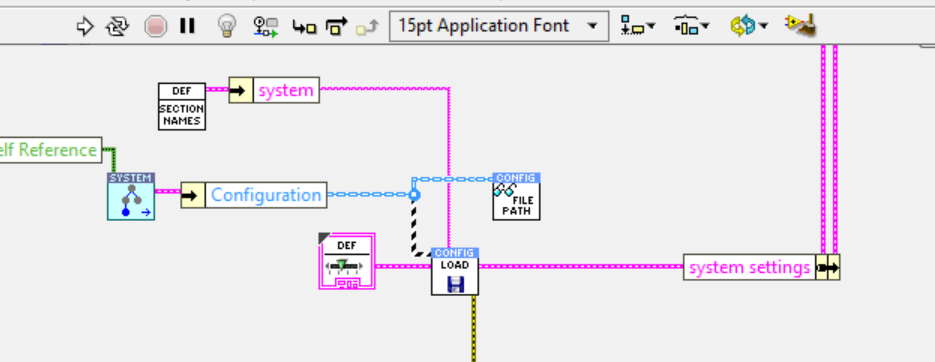
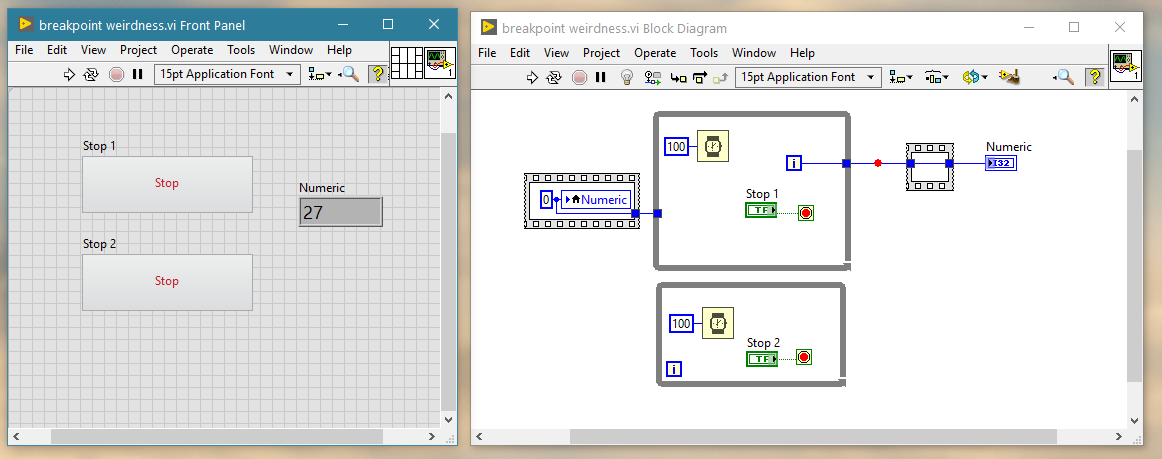
But this isn't the issue is it? The front panel is updated long before the VI finishes executing.
-
 ... to further elaborate on merging. Note that we have used that word with respect to branches in source control and also with respect to files. As I previously mentioned, if you're careful not to edit the same files in multiple branches, when it comes time to merge a branch, it doesn't require that you merge a file. Merging branches is easy as long as it doesn't also require you to merge files.
... to further elaborate on merging. Note that we have used that word with respect to branches in source control and also with respect to files. As I previously mentioned, if you're careful not to edit the same files in multiple branches, when it comes time to merge a branch, it doesn't require that you merge a file. Merging branches is easy as long as it doesn't also require you to merge files. -
Bob, I can't help but wonder if you might be mixing up terms here. If you're talking about using code from one project in another you might be thinking about Submodules (Git) or Subrepos (Mercurial). Branching is typically done within the same project with the assumption that whatever work is done on the branch will get merged back into something considered the main or master. In LabVIEW, I suspect most of us try really hard not to modify the same file in multiple branches since merging VI's isn't as straightforward as merging text files. You might branch something to work on a feature that you're not ready to deploy, but you want to be careful not to also modify the same file in another branch because when it comes time to combine everything back into one (merge), the source code can't automatically reconcile a file that has changes in multiple branches. It leaves you in the position to decide which of the changes is the one to keep and which do you want to throw away or the worst case scenario - you think there might be unique changes in both of those edits that you need to figure out how to combine into one. Eric
-
1. Mercurial (with TortoiseHg), Subversion, Git (with Sourcetree) 2. I have no option but to love any or all of them because the alternative (no source control) would make my life a lot more difficult. 3. Yes and yes. It just depends on the project. I would prefer Git just so I was always using the one that everyone else in the world is using. 4. Subversion might be the simplest for you considering it sounds like you don't want to be using SCC in the first place. You mentioned wanting to use source control "within" LabVIEW and I think you can setup LabVIEW to work with SVN although I'm not doing it that way. However, your computer will require constant connection with the central repository. Also, last time I tried to create a branch on Subversion, I vowed I would never try it again. It's difficult to give up the ability to easily create branches once you have it. Mercurial is a distributed version control system and seems easier to understand than Git, but that might be because I have used it more. Git has plenty of horror stories written about it when people are confused in the beginning. Eventually they learn it and the frustration subsides. 5. Once you learn what you're doing, almost never. The major pain is just in the beginning while you're learning. There is likely to be more initial pain with Git. If you're a solo developer who is used to clicking the "Save All" button on the project every few minutes, transitioning to a more thoughtful workflow where you are mentally keeping track of what you have actually changed and only committing those files is going to suck - to put it bluntly. Yet another thing to think about! After all, who wants to think more? Imagine having to constantly interact with source control by constantly typing little notes about the work you just did. This might feel disruptive to your workflow. However, it's worth asking yourself why almost every experienced developer does this. One customer I work with uses SVN and the way they use it is single commits of all their work they did that day with no commit notes. Is this helpful? Well I guess it's better than nothing. You could return to some prior state of the code although it would be difficult to figure out what state you were returning to. Consider this option if someone told you that source control is mandatory and you're just trying to check a box so you can say you're using some "stinking" source control. If you're inclined to implement some best practices and you understand the software world interacts largely through GitHub and you would like to engage with that world, consider using Git. Keep in mind this will probably require more patience initially. Whatever you choose, I don't think there is any way to completely avoid the cognitive discomfort that can arise from learning something new. Eric Graham
-
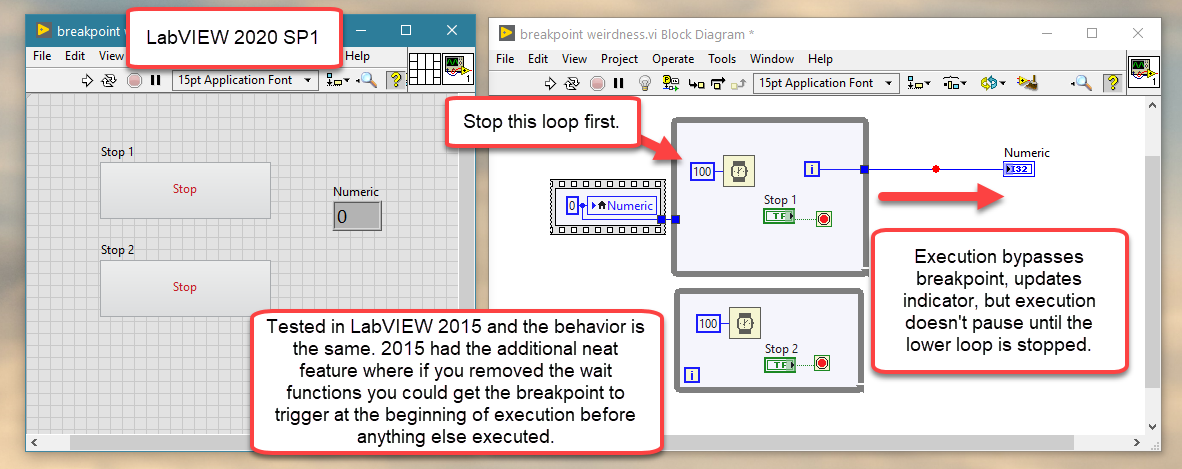
I think it's really helpful to point that out. Thinking about this.... I can't figure out if now we are trying to explain why it's expected behavior or if we are trying to justify unexpected behavior (or something in between). 🙂
-
If it were an optimization then we should be prevented from placing breakpoints where they won't function as expected. I know breakpoints have been buggy for a long time. The fact that in 2015 I could remove the wait functions and get the execution to pause as soon as I ran the VI tells me that at least some of the quirks have been fixed over time. The fix is to place a sequence structure between the breakpoint and indicator.
-
Every time I encounter something like this, my first thought is, "What am I doing wrong?" Is this one of those known behaviors that everyone but me knows about? See screenshot. How is it possible to update an indicator if the upstream wire has a breakpoint that hasn't paused execution?
-
G-CODE changed their profile photo
-
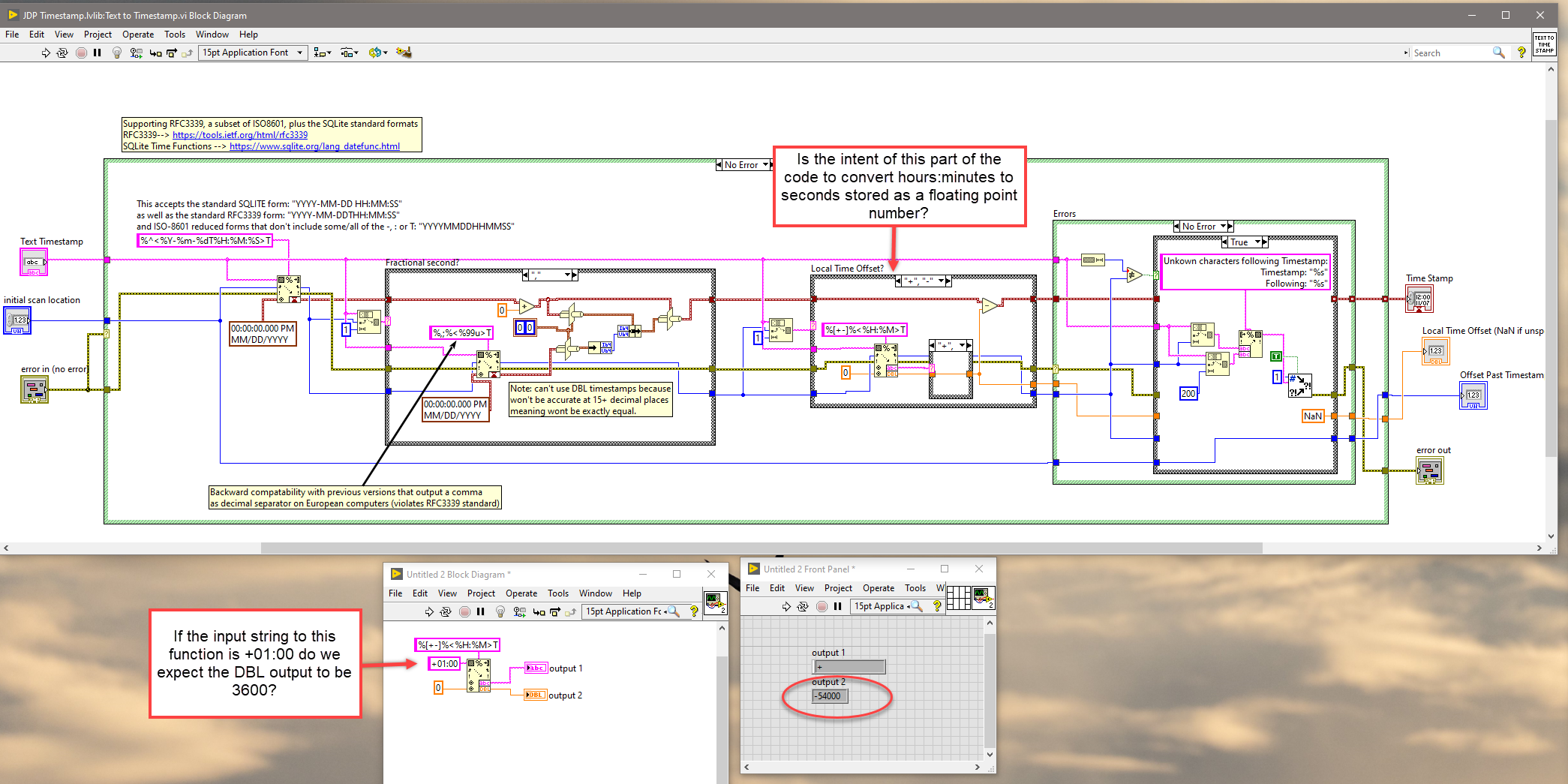
@drjdpowell, thanks for all the work you put into this really useful library. I noticed you have some timestamp conversion utilities that the SQLite library uses. I am confused by some behavior I am seeing when converting a string timestamp with a local time offset. Can you look at the attached screenshot of that function? Maybe this is expected behavior and I'm not understanding something. Thanks, Eric
-
1D Array to String not compiling correctly
G-CODE replied to G-CODE's topic in OpenG General Discussions
This happened on a virtual machine that only had LabVIEW 2020 installed. VIPM was always configured to mass compile VIs after package installation. If this happened even when packages were being mass compiled, what else is lurking under the hood waiting to be found? I want to assume that had I built an EXE in this state, this problem would have gone away. -
I was experiencing a whole host of problems running an application in LabVIEW 2020 (32-bit) dev environment. This function was giving me the wrong output. After an edit and save, the output of the function now appears correct. This is the first time I have ever seen this... 2020-09-11_17-18-49.mp4
-
The two people who gave this presentation might be able to point you in the right direction.
- 1 reply
-
- 1
-

-
LabVIEW 2019 "create constant" right click menu
G-CODE replied to bjustice's topic in LabVIEW General
Oh, you can turn it off.... Well previously I was using the right-click plugin, so I was happy to see it appear as a feature in 2019. When it comes to software, over the years I have adjusted my attitude by telling myself to "expect everything to change all the time". That way I'm not frustrated every time I have to reteach myself something. On the upside, it's probably a good mental exercise to not allow our muscle memory to become burned in. Think of it as cross-training for the brain. 🙂 -
Poll on Architecture and Frameworks
G-CODE replied to drjdpowell's topic in Application Design & Architecture
Now you've got me thinking. I'm so habituated to creating typedefs, events, and registrations for every message. Maybe there's a better way...