Rolf Kalbermatter
-
Posts
3,974 -
Joined
-
Last visited
-
Days Won
282
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-
I was just recently trying to find out where the cutoff point is. In my memory 2016 was the version that stopped with 32-bit support. But looking on the NI download page it claims that 2016 and 2017 are both 32-bit and 64-bit. But that download page is riddled with inconsistencies. For 2017 SP1 for Linux you can download a Full and Pro installer which are only 64-bit. Oddly enough the Full installer is larger than the Pro. The 2017 SP1 Runtime installer claims to support both 32-bit and 64-bit! For 2017 and 2016 only the Runtime installer is downloadable plus a Patch installer for the 2017 non-SP1 IDE, supposedly because they had no License Manager integration before 2017 SP1 on non-Windows platforms. Here too it claims the installer has 32-bit and 64-bit support. So if the information on that download page is somewhat accurate, the latest version for Linux that was still supporting 32-bit installation was 2017. 2017 SP1 was apparently only 64-bit. Of course it could also be that the download page is just indicating trash. It's not the only thing on that page that seems inconsistent.
-

Can I ride the LV/TS train to retirement?
Rolf Kalbermatter replied to Phillip Brooks's topic in LAVA Lounge
Easy typecasting in C is the main reason for a lot of memory corruption problems, after buffer overflow errors, which can be also caused by typecasting. Yes I like the ability to typecast but it is the evil in the room that languages like Rust try to avoid in order to create more secure code. Typecasting and secure code are virtually exclusive things. -
It's the same that LabVIEW adopted many years ago when they added the PCRE function to the string palette in addition to their own older Match Pattern function that was obviously Perl inspired (and likely generated with Bison Yacc), but more limited (not necessarily a bad thing, PCRE is a real beast to tame 😀). Not sure about the exact version used in LabVIEW but since it appeared around LabVIEW 8.0 I think, it would be likely version 6.0 or maybe 5.0, although I'm sure they upgraded that in the meantime to a newer version and maybe even PCRE2.
-
You actually will need the NI VC2015 Runtime or another compatible Microsoft Visual C Runtime. Since the Visual C Runtime 2015 and higher is actually backwards compatible, it is indeed not strictly needed for Windows 10 or 11 based systems since they generally come with a newer one. However that is not guaranteed. If your Windows 10 system is not meticulously updated, it may have an older version of this Runtime Library installed than your current LabVIEW 2021 installation requires. And that will not work, it's only backwards compatible, meaning a newer installed version can be used by an application compiled towards an older version, not the other way around. You mentioning that the system will be an embedded system makes me think that it is neither a state of the art latest release, not that it will be regularly updated.
-
LabPython 1.2-2 and LabVIEW 7.1
Rolf Kalbermatter replied to Dave21's topic in OpenG General Discussions
LabPython needs to know which Python engine to use. It has some heuristics to try to find one but generally that is not enough. But as Neil says. For some things, old-timers can have their charm, but in software you are more and more challenging the Gods by using software that is actually 20 years or more old!!! -
Can I ride the LV/TS train to retirement?
Rolf Kalbermatter replied to Phillip Brooks's topic in LAVA Lounge
That's because I don't have a solution that I would feel comfortable with to share. It's either ending into a not so complicated one off for a specific case solution or some very complicated more generic solution that nobody in his sane mind ever would consider to touch even with a 10 foot pole. -
Can I ride the LV/TS train to retirement?
Rolf Kalbermatter replied to Phillip Brooks's topic in LAVA Lounge
Unfortunately one of the problems with letting an external application invoke LabVIEW code, is the fundamentally different context both operate in. LabVIEW is entirely stackless as far as the diagram execution goes, C is nothing but stack on the other hand. This makes passing between the two pretty hard, and the possibility of turnarounds where one environment calls into the other to then be called back again is a real nightmare to handle. In LabVIEW for Lua there is actually code in the interface layer that explicitly checks for this and disallows it, if it detects that the original call chain originates in the Lua interface, since there is no good way to yield across such boundaries more than once. It's not entirely impossible but starts to get so complex to manage that it simply is not worth it. It's also why .Net callbacks result in locked proxy callers in the background, once they were invoked. LabVIEW handles this by creating a proxy caller in memory that looks and smells like a hidden VI but is really a .Net function and in which it handles the management of the .Net event and then invokes the VI. This proxy needs to be protected from .Net garbage collection so LabVIEW reserves it, but that makes it stick in a locked state that also keeps the according callback VI locked. The VI also effectively runs out of the normal LabVIEW context. There probably would have been other ways to handle this, but none of them without one or more pretty invasive drawbacks. There are some undocumented LabVIEW manager functions that would allow to call a VI from C code, but they all have one or more difficulties that make it not a good choice to use for normal LabVIEW users, even if it is carefully hidden in a library. -
Can I ride the LV/TS train to retirement?
Rolf Kalbermatter replied to Phillip Brooks's topic in LAVA Lounge
And that is almost certainly the main reason why it hasn't been done so far. Together with the extra complication that filter events, as LabVIEW calls them, are principally synchronous. A perfect way to make your application blocking and possibly even locking if you start to mix such filter events back and forth. Should LabVIEW try to prevent its users to shoot themselves in their own feet? No of course not, there are already enough cases where you can do that, so one more would be not a catastrophe. But that does not mean that is MUST be done, especially when the implementation for that is also complex and requires quite a bit of effort. -
it’s a general programming problem that exists in textual languages too although without the additional problem of tying components in the same strict manner together as with LabVIEW strict typedefs used in code inside different PPLs. But generally you need to have a strict hierarchical definition of typedefs in programming languages like C too or you rather sooner than later end in header dependency hell too. More modern programming languages tried to solve that by dynamic loading and linking of code at runtime, which has it’s own difficulties. LabVIEW actually does that too but at the same time it also has a strict type system that it enforces at compile time, and in that way mixes some of the difficulties from both worlds. One possible solution in LabVIEW is to make for all your data classes and pass them around like that. That’s very flexible but also very heavy handed. It’s also easily destroying performance if you aren’t very careful how you do it. One of the reason LabVIEW can be really fast is because it works with native data types, not some more or less complex data type wrappers.
-
Can I ride the LV/TS train to retirement?
Rolf Kalbermatter replied to Phillip Brooks's topic in LAVA Lounge
Maybe there isn’t other than that you and me and anyone else using LabVIEW never really was asked when they did their “reliable independent” programmer questioning. Trying to draw conclusions from a few 1000 respondents that where not carefully selected among various demographical groups is worse than a guesstimate. Also most LabVIEW programmers may generally have better things to do than filling out forms to help some questionable consulting firms draw their biased conclusions to sell to the big world as their wisdom. 😀 -
Can I ride the LV/TS train to retirement?
Rolf Kalbermatter replied to Phillip Brooks's topic in LAVA Lounge
In Google Trends LabVIEW is considered a software, while the others are considered programming languages. Many programming language comparisons don’t consider LabVIEW as they see it as a vendor software. On the other hand is G usually associated with something else. So LabVIEW falls through the cracks regularly. On the other hand is your statistic website also not quite consequent. I would consider Delphi also more the IDE than a programming language. The language would be really (Object) Pascal. And HTML/CSS as programming feels also a bit off, can I enter Microsoft Word and Excel too, please? Or LaTex for that matter? 😀 Rust on the other hand for sure is going to grow for some time. -
Can I ride the LV/TS train to retirement?
Rolf Kalbermatter replied to Phillip Brooks's topic in LAVA Lounge
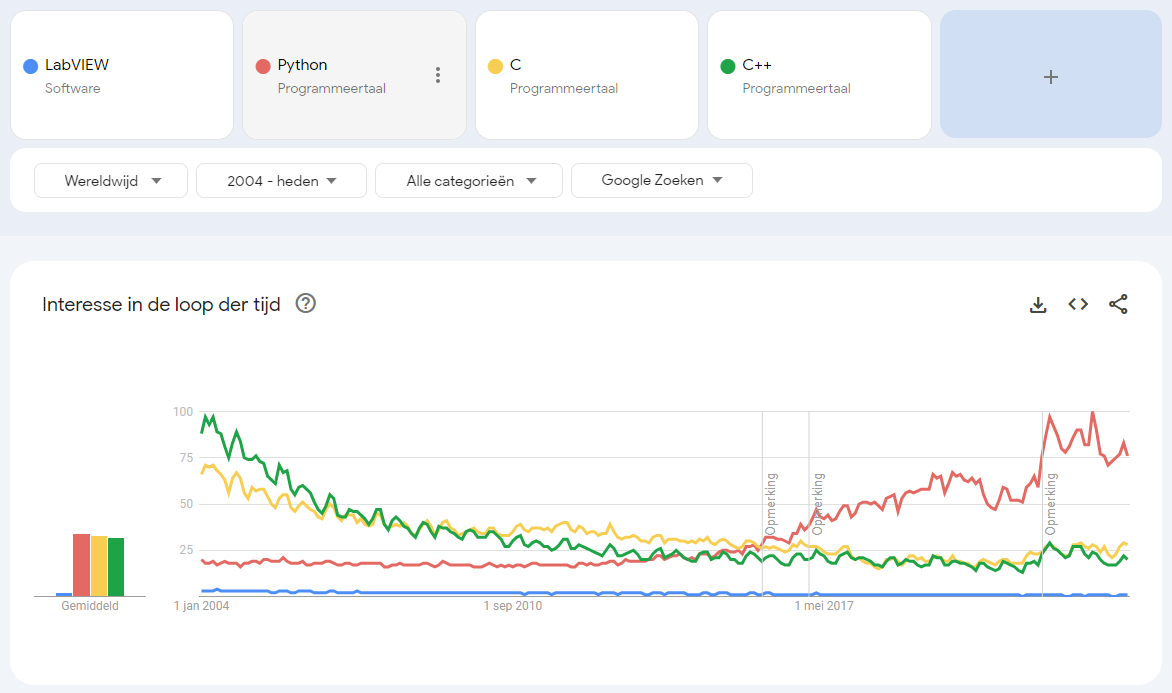
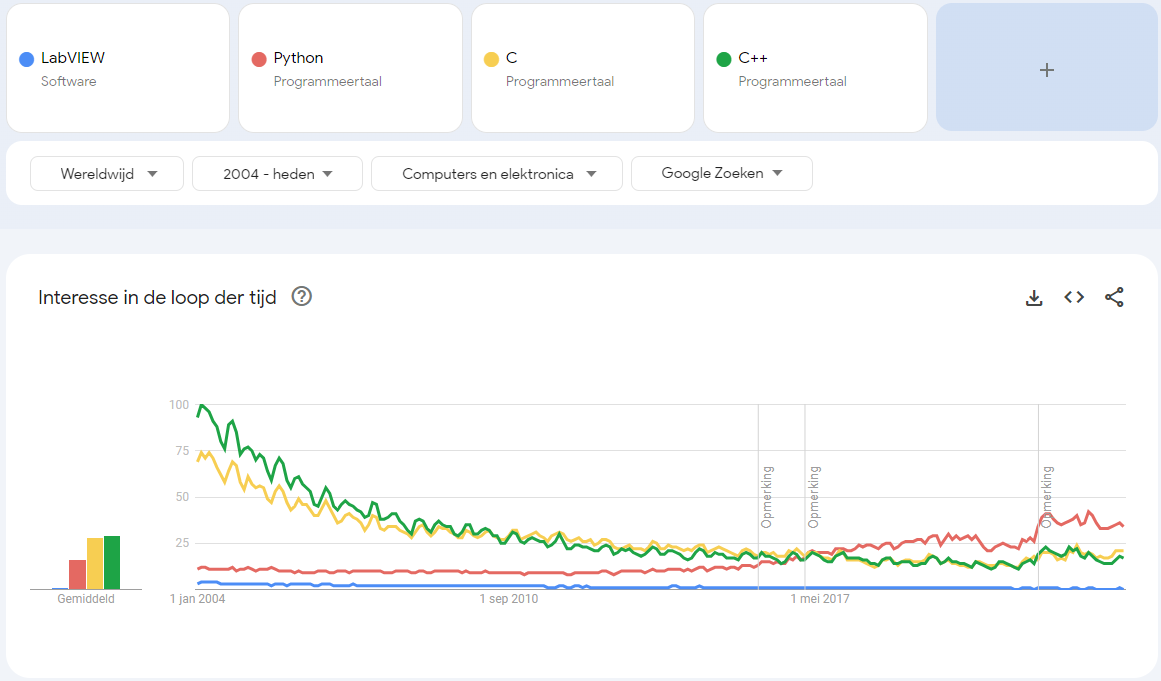
It is more complex than that. First it is a trend so it is relative to some arbitrary maximum. Second if you combine multiple items the trend suddenly looks a little different. Interesting that C started lower than C++ back in 2004 but seems to be now slightly higher than C++. It's obvious that LabVIEW always has been a minor player in comparison to these programming languages. And if you limit it to computers and electronics as search categories it looks again different:
-
I Con not install dsc by vipm for labview2016
Rolf Kalbermatter replied to Danial Nasser's topic in LabVIEW General
I'm fairly sure his believes will be proven right. What it will bring in terms of new features will be anyone's guess. -
I Con not install dsc by vipm for labview2016
Rolf Kalbermatter replied to Danial Nasser's topic in LabVIEW General
LabVIEW 2024? Where did you get that??😁 I sense someone from a movie from Christopher Nolan has been posting here. 😀 -
Can I ride the LV/TS train to retirement?
Rolf Kalbermatter replied to Phillip Brooks's topic in LAVA Lounge
That's what LabWindows/CVI was. And yes the whole GUI library from LabWindows/CVI was under the hood the LabVIEW window manager from ca. LabVIEW 2.5! My guess (not hindered by any knowledge of the real code) is that at least 95% of the window manager layer in LabVIEW 2023 is still the same. And I'm not expecting anyone from NI chiming in on that, but that LabWindows/CVI used a substantial part of the LabVIEW low level C code is a fact that I know for sure. but look where that all went! LabWindows/CVI 2020 was the latest version NI released and while they have mostly refrained from publicly commenting on it, there were multiple semi-private statements from NI employees to clients, that further development of LabWindows/CVI is not just been put in the refrigerator but definitely has been stopped. As to AI as promoted by OpenAI and friends at this point: It has very little to do with real AI. It's however a very good hype to raise venture capital for many useless things. Most of it will be never ever talked about again after the inventor went off with the money or it somehow vaporized in other ways. It feels a lot like Fuzzy Logic some 25 years ago. Suddenly everybody was selling washing machines, coffee makers and motor controllers using Fuzzy Logic to achieve the next economical and ecological breakthrough. At least there was a sticker on the device claiming so, but if the firmware contained anything else than an on-off controller was usually a big question. People were screaming that LabVIEW was doomed because there was no Fuzzy Logic Toolkit yet (someone in the community created eventually one but I'm sure they sold maybe 5 or so licenses if they were really lucky). Who has heard for the last time about Fuzzy Logic? Sure AI, once it is real AI, has the potential to make humans redundant. In the 90ies of last century there was already talk about AI, because a computer could make some model based predictions that a programmer first had to enter. This new "AI" is slightly better than what we had back then, but a LLM is not AI, it is simply a complex algorithmic engine. -
MathScript was the mathematic node that used to be NI's attempt to make a Matlab clone. It sort of worked similar to Matlab and could execute Matlab scripts to some extend. But it was of course never a full replacement for Matlab and NI eventually stopped pursuing MathScript any further. Since LabVIEW 2023 MathScript has been removed from LabVIEW. NI recommends to use Matlab now to implement those scripts https://www.ni.com/docs/en-US/bundle/daqexpress/page/migrate-to-interface-for-matlab.html
-
The 5 and 10 volume license give you some discount. But it still adds up. And the real volume licenses for large sites are indeed relatively cheap for what you get but I doubt your company is willing to shelf out 50k or more even if it allows them to have 500 licenses to be used. 😀
-
No you can't anymore. NI added subscription licenses in November or December of 2021 to the order system, and discontinued perpetual development licenses on January 1, 2022. After that date they did officially not sell any non-subscription licenses anymore. For a little while you could try to appease a sales representative and if you were good and did it long enough, they could still put an order for a perpetual license into the system, but I'm pretty sure that possibility has long been removed since. You could buy a subscription for one year. It gives you the right to download older versions too. If you use the old serial number, it will allow to use the old installation up to the point your maintenance contract expired. If you use the new serial number that comes with the subscription purchase, you can run old versions for as long as your subscription is valid.
-
You won't like it but you could never officially download software from the NI site other than the latest version to use as evaluation download without a maintenance support contract. If you were not logged in with an account that had a current maintenance support contract associated, selection of previous versions were blocked from the Download website ever since that Download page got active. And NI never ever guaranteed anywhere that you could keep downloading software as far back as you liked. Not even with a maintenance support contract or nowadays a subscription. Even if you pay for it, it is a service that is delivered as is, without any guarantees that you can continue to download older version (for instance LabVIEW 7.1, just to name one very old version) which you indeed can't and never will be able to download anywhere officially. So if you build a system that requires a specific version for whatever reason and don't archive all and every piece of that system somewhere, the problem is definitely up your sleeve and always has been. As for charging a 100 dollar fee to download software, that may sound an interesting option. But unfortunately companies of the size of NI nowadays will not even lift a telephone of the hook for that amount. Why? Until the order is booked, payment processed, accounting had its pee over the transaction, shipment (or access to the file organized), the whole thing has cost many times more than those 100 bucks.
-
So you expect Microsoft to let you download Visual Studio 2005 (or 2008, 2010, 2013, 2015) for free because you have somewhere a Windows XP machine running that runs a very expensive experiment where the hardware drivers don't support anything newer? Bad luck for you but that is not an option (unless you want to resort to bogus download sites where you have to search for the right download button among a few dozen others trying to get scareware or worse onto your system, and/or the download itself is bogus or even malware invested). You can buy a Microsoft Visual Studio Professional subscription however for ~1500 bucks a year and then you can actually download (most) of them. Or you can of course download these packages when you have the license to access them and then safely archive the installer somewhere. If you build such a specialist system and don't plan for having to sometimes in the future reinstall the whole stuff again (on new hardware or after a fatal crash) you only did part of the job for that project! That works for LabVIEW (and many other software) the same, if there is even a possibility to download older versions!
-
How does LabVIEW get an image in memory?
Rolf Kalbermatter replied to mooner's topic in LabVIEW General
That is a tricky recommendation, as you explain too. Unless it is documented that the DLL or particular function is thread safe, I would normally refrain from calling the function in any thread. Also your claimed speed improvement is very off, especially in this case. The main time loss is when the LabVIEW program has to wait for the UI thread to be available for calling the CLN. This is at worst in the order of a few ms, typically even significantly below 1 ms. Compared to the runtime of these functions, which for the capture does a GDI bitmap copy and some extra shuffling to only get out the actual pixel data and for the MoveBlock(), which does a memory copy of a significant size, this delay of arbitrating for the UI thread is pretty small. It's likely measurable with the high resolution timer, but do you really care if this VI takes 25 ms to execute or 26 ms? Reentrant execution of a CLN gets really interesting performance wise when you have a short running function which is called over and over again in a loop. Here the overhead of arbitrating each time for the UI thread will be significant and can get even the single most dominating factor in the execution speed. There is one other aspect about not wanting to run a CLN in the UI thread. While LabVIEW is busy executing the CLN in the UI thread, this thread is not available to do anything else, including drawing anything on the screen and processing Windows events such as mouse and keyboard events. If the CLN takes a long time to execute (many 100 ms to seconds) the LabVIEW application will appear to be frozen during the call to this CLN (and in the worst case Windows will notice after several seconds that the event loop isn't polled for a long time and provide the user with a dialog suggesting that the application is unresponsive and should probably be shut down). -
How does LabVIEW get an image in memory?
Rolf Kalbermatter replied to mooner's topic in LabVIEW General
What does the documentation say about the pointer returned by the function? Is it allocated by the function? Is it a static buffer that is always the same (very unlikely)? If it is allocated by the function, you will need to deallocate it after use (after the MoveBlock() function), and the documentation should state what memory manager function was used to allocate the buffer and what memory manager function you should use to deallocate it, otherwise you create a memory leak every time you call this function. Ideally the DLL exports a function that will deallocate the buffer, still a usable solution is if they use the Windows GlobalAlloc() function to create the buffer in which case you would need to call GlobalFree(). Pretty bad would be if they use malloc(). This is because the malloc() call that the DLL does might be linking to a different version of the C runtime library than the according free() you will try to call in LabVIEW, and that is a sure way to create trouble. -
Byte Array To String Function question
Rolf Kalbermatter replied to Lucky--Luka's topic in LabVIEW General
Right click on a string control (or constant) and select "Visible Items->Display Style". The control gets an extra glyph which is marked with the red rectangle in the image of Mikael. This indicates what display mode the control uses. Note that this changes ABSOLUTELY nothing about the actual bytes used in the string. It only changes how the control displays them! -
Where do y'all get your (free) artwork for UI elements?
Rolf Kalbermatter replied to David Boyd's topic in User Interface
Icons are the resource sink of many development teams. 😀 Everybody has their own ideas what a good icon should be, their preferred style, color, flavor, emotional ring and what else. And LabVIEW actually has a fairly extensive icon library in the icon editor since many moons. You can't find your preferred icon in there? Of course not, even if it had a few 10000 you would be bound to not find it, because: 1) Nothing in there suits your current mood 2) You can't find it among the whole forest of trees -
Well, I have done a few minor updates to the library to fix a few minor problems with newer Windows systems. It's still active and used by some customers. What do you want to know about it?