Rolf Kalbermatter
-
Posts
3,973 -
Joined
-
Last visited
-
Days Won
281
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-

Communicate with hardware using USB HID?
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in Hardware
You did not address the other mentioned issues. Assuming that the return data is constructed in the same way than the command you would need to read 3 bytes, decode the 3rd byte as length and read the remaining data + any CRC and other termination codes.
-
Communicate with hardware using USB HID?
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in Hardware
It's always a good idea to show the code indication (Display Style) on a string constant! Serial Port Initialize by default enables the message termination protocol. That is for binary protocols often not very helpful. And in that case you need to get the message length right such as reading the header until the message length, decoding the length and read the reminder plus any CRC or similar bytes. -
Communicate with hardware using USB HID?
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in Hardware
That would indicate a USB VCP, not USB HID! While the format is indeed not very descriptive as you posted, a USB VCP should be easily accessible through NI VISA. -
I use Visual Studio and launch LabVIEW from within Visual Studio to debug my DLLs and unless I quirk up something in kernel space somehow I always get into the Visual Studio Debugger, although not always into the source code, as the crash can be in one of the system DLLs.
-
Your experience seems quite different than mine. I get never the soundless plop disappearance, but that might be because I run my shared library code during debugging from the Visual C debug environment. But even without that, the well known 1097 error is what this wrapper is mostly about and that happens for me a lot more than a completely silent disappearence.
-
VI options in form of 51 integers
Rolf Kalbermatter replied to Mefistotelis's topic in LabVIEW General
So you understand the gcc source code? Wow! Just wow! -
VI options in form of 51 integers
Rolf Kalbermatter replied to Mefistotelis's topic in LabVIEW General
Are you really wanting to tell me that you understand how a C compiler works? Because that would be impressive! -
I didn't mean to indicate that you had to wire the return value. I actually never even tried that as it seemed so out of touch with anything. What I do believe to remember however is that LabVIEW required you to wire the left side of parameters. However that's 20 years ago and it could just as well have been the CIN node. Much of the object handling for the CLN was inherited from the CIN node and there you don't have a return value. In fact I'm pretty certain that the return value of the CLN is basically simply a parameter as far as the node object is concerned, in order to be able to reuse much of the CIN node object handling. The fact that the first parameter is specifically reserved for the function return value is most likely mostly a special casing for the configuration object method and the run object method of the CLN. Most other methods it simply inherits from the common object ancestor for the CIN and the CLN.
-
VI options in form of 51 integers
Rolf Kalbermatter replied to Mefistotelis's topic in LabVIEW General
I see it similar to how a car works. I know how to operate it and the traffic rules and similar but I really do not plan on learning how to take it apart and put it back together again. Some people do, but if you try that with a modern car you are pretty quickly limited by the sheer complexity of the whole thing. -
VI options in form of 51 integers
Rolf Kalbermatter replied to Mefistotelis's topic in LabVIEW General
Sure a few are here who even respond to various posts. But to respond to this type of topic could easily be construed as violating non disclosure agreements you nowaday have to sign anywhere when starting a job and as such could be an immediate reason for terminating their job and even liability claims. They know better than to risk such things. Besides this type of archeological digging may be fun to do in your free time, but it leads basically nowhere in terms of productivity. It's up to you what you do with your free time, and if this gives you a fuzzy feeling somehow, then I suppose it is not a bad thing. But don't expect that there are many more out there who feel the same. -
VI options in form of 51 integers
Rolf Kalbermatter replied to Mefistotelis's topic in LabVIEW General
That's easy to answer. You lost everybody including me already quite some time ago. The only ones who could answer your questions are people with access to the LabVIEW source code and they can't and won't answer here. The rest have never gone that far into LabVIEW interna and likely have much much more important things to do. -
You may possible rather use this version 4.2.0-b1 here.
-
The main reason is that NI does not want to document the API for these functions. Not so much because it is secret but because once they are documented they can't change it anymore. Without having them documented (and an open VI diagram with the according CLN configuration is a sort of documentation too) they can't just go and change it easily as someone might have relied on this API and created his own VIs. With locked diagram they are free to change the API at any time and only have to update the according VIs that are shipped with LabVIEW and all is fine. If you sneaked into the diagram anyhow and used it, that is all your own fault. 😀
-
These ZIP VIs that come with LabVIEW are all single CLNs that call directly into LabVIEW, as NI has basically included ZLIB and the according old style ZIP file functions that come in the contributed folder of the ZLIB distribution and which were developed by Gilles Vollant. OpenG ZIP Library uses the same code, just likely a newer version. The LabVIEW inlcuded code does not allow to query the implementation version of the library so it's hard to say how up to date it is.
-
There are several levels in a ZIP file. A ZIP file is an archive format with things like directory entries, and stream headers. The directory entry contains records for every stream inside the archive (a stream is pretty much a single file entry in the archive) and each stream has its own header. The individual streams are compressed using the ZLIB algortithme with a small header in front. So while the ZIP file does use ZLIB to compress the individual streams it is anything but a ZLIB compressed stream in itself. GZ is closer to a single ZLIB stream but needs an additional header that tells the decomprosser about how to configure the decompression, so the file content is not a ZLIB stream but a bit more than that. The OpenG ZIP library is mainly an implementation of a ZIP archive reader and writer but uses at its core the zlib library for the compression and decompression, just as the ZIP library does that is included in LabVIEW. While the LabVIEW provided ZIP library only exports a few high level functions to be accessed, the OpenG version goes a lot further and basically exports a lower level API on which the whole ZIP archive handling is implemented. And in addition it also exports the according ZLIB inflate and deflate functions that allow you to implement any compression that is based on the ZLIB compression method. It would be possible to implement GZ and similar formats on top of this without a lot of effort, by simply implementing a LabVIEW library on top of these ZLIB methods and some LAbVIEW file IO methods.
-
There is no good reason why that should be forbidden. Without an input wired, LabVIEW will allocate the variable automatically (also true for normal parameters since around LabVIEW 6 or so. Before that LabVIEW required you to wire inputs no matter what). Otherwise it will reuse the one wired into the left terminal to store the result into. Useful? Not really but maybe it was left in as there is no harm done with it and someone might have figured out that it could be one day useful to reuse the passed in value to determine the data type (and possibly buffer size).
-
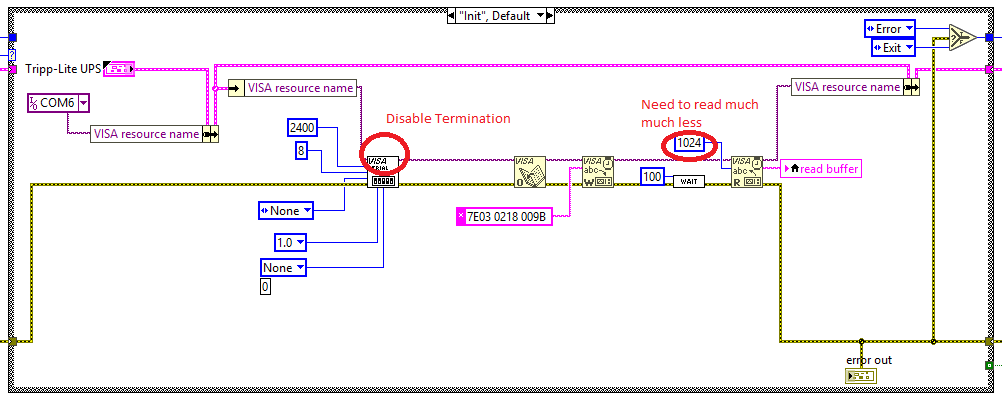
Communicate with hardware using USB HID?
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in Hardware
How does the documentation look that your received from Tripp-Lite? -
I'm fairly certain that it would work to unflatten a fixed size data string but only if the control in the data type to unflatten to is a preallocated data string with the correct size. Yes that limitation would not need to exist, but fixed size arrays/strings are anyhow an odditity in LabVIEW so why not enforcing such a rule. At least that is what I remember from LabVIEW 5.x times.
-
They can be used in RT which can be useful when interfacing to FPGA code. However they are not meant to save you from having to use explicit array subset and similar functions. For one thing the normal functions like VISA/TCP/File and whatever Read do not support returning fixed size arrays at all. Second what would you expect functions like Append to String/Array to do with a fixed size input value? There's only a very limited subset of LabVIEW functions that can be meaningfully used with fixed size arrays/strings without creating a hell of a lot of possible implementation choices that are all valid in their specific use case. Fixed size arrays/strings is a compile time decision. Most LabVIEW functions have a runtime operation however.
-
Communicate with hardware using USB HID?
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in Hardware
There is nothing out of the box. The main reason is that HID devices are normally claimed by the OS. Also HID is a low level binary protocol that says pretty much nothing at all about what data is transfered over the link, just what endpoints are involved. There are some HID sub classes such as keyboard and mice which have a specific data format to be used on the binary level but even that knows various vendor defined extensions that each vendor will implement in its own way. Other devices implementing the HID class are usually very specific to the actual device and therefore always need a custom implementation. If you want to talk to HID devices from LabVIEW you have a few options, each with its specific drawbacks: 1) Use a shared library that implements the driver and call its functions with the Call Library Node. Advantage: No need to know the low level protocol details. Disadvantage: Shared library interface requires at least some basic C programming knowledge to be able to properly interface to it. 2) Use a HID specific shared library interface. Disadvantege: In addition to the need to know about interfacing to shared libraries you also need to implement the low level binary protocol for your device. 3) Use the VISA USB Raw protocol. Advantage: can be done all inside LabVIEW without the problems to interface to shared libraries with their non-managed C difficulties. Disadvantage: You need to implement the HID protocol and also only possible if you know the low level protocol on top of HID. You seem to have gotten that information from Tripp-Lite, so you "just" have to lookup the HID protocol specifications on usb.org and study several 100 pages of USB standard documentation to do this. The biggest drawback however is that all current desktop OSes require signed drivers in order that you can install them and that also applies to VISA INF style drivers. NI can't give you their private signing keys to let you sign such a driver and getting your own has a cost associated with it and not just a one time cost either. Disabling driver signing in the OS is still possible but requires one to jump through more and more hoops as time goes by. I expect it to soon be impossible without installing a special debug build of an OS. 4) Use of the Windows device interface API through the Call Library Node. The actual communication isn't that difficult once you have the device opened but interfacing to the setup API to enumerate, find and configure the device is a pita. The setup API is also complex enough that it pretty much requires a separate external shared library as many of the parameters are pretty complex and all but LabVIEW friendly. You still would need to implement the HID protocol itself and the also the low level device protocol in addition to the whole shared library interface for the Windows API. In terms of effort this option is by far the most complex to do. 5) using libusb or WinUSB you can communicate directly to the device too. It supports claiming devices eventhough the OS has already claimed them. libusb/WinUSB basically accesses the above mentioned Windows API and hides a lot of the complexity. You still need to interface to the shared library interface of libusb/WinUSB and you would need to implement the HID and low level device protocol on top of this. -
Even if you make the string fixed size, LabVIEW most likely won't embed it into the cluster like a C compiler does. That simply was not a design criteria when fixed arrays (and strings) were implemented. They are mostly meant for FPGA, where variable sized elements have a very high overhead to be implemented. The fixed size option was documented at least since LabVIEW 3.0 in the data type documents and likely before but there was no public functionality to enable or access it and it only really got used with the introduction of FPGA support around LabVIEW 7.1. Outside of FPGA targets it's not an exercised feature at all, and for strings it's nowhere really used. It is more a byproduct of Strings being in fact just a special type of arrays with its own wire color and datatype, but the underlaying implementation is basically simply an array of bytes. Could LabVIEW inline fixed size arrays in Clusters? Sure! But that was initially never a design criteria. The support to interface to external libraries was added long after this datatype system was implemented, so changing that then to support C style fixed size arrays inside structs would have meant backwards incompatibility or a lot of extra work in the Call Library Node configuration.
-
Sharing serial device from Raspberry Pi to VISA?
Rolf Kalbermatter replied to Sparkette's topic in LabVIEW Community Edition
py-visa is a pure VISA client implementation. While the VISA API is sort of documented in the VXIpnp documents, the internal workings of VISA is not. That includes the VISA Server network protocol and all that stuff. I think the cost-usefullness analysis of trying to reverse engineer that is pretty bad as even under Windows VISA Server isn't used that often. The only platform I have ever used it with was with NI realtime controllers to access their serial ports from Windows. But that was all being NI hardware with NI drivers installed. -
LabVIEW Community Edition Announced
Rolf Kalbermatter replied to hooovahh's topic in LabVIEW Community Edition
Seems definitely doable. A bit a shame that they have one seperate API for each hardware board. -
LabVIEW Community Edition Announced
Rolf Kalbermatter replied to hooovahh's topic in LabVIEW Community Edition
The Pi is very easy to get. I have here a Beaglebone Black and a myRIO available. Also a RIOTboard and an older Atmel SAM7X embedded controller board, but they both are not supported by Linx. The MCC HAT needs to have some form of binary module interface in the form of a shared library to be accessible from C. Interfacing that interface with the LabVIEW Call Library Node definitely must be possible, it's just some busy work to do. -
LabVIEW Community Edition Announced
Rolf Kalbermatter replied to hooovahh's topic in LabVIEW Community Edition
Send one my way and I have a prelimenary library done in a few days. 😀