Rolf Kalbermatter
-
Posts
3,968 -
Joined
-
Last visited
-
Days Won
281
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-

Communication with hardware using Serial connection (RS232)
Rolf Kalbermatter replied to Shaun07's topic in LabVIEW General
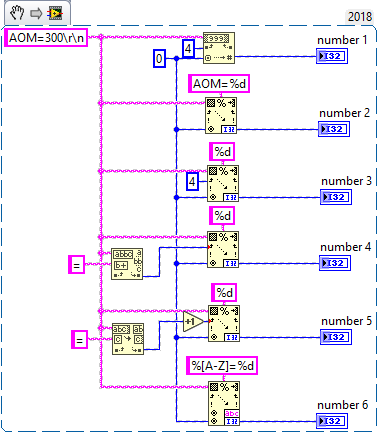
There are about 500+ ways to tackle this. You could use a Scan from String with the format string AOM=%d. Or with the format string %d and the offset with 4 wired. Or a little more flexible and error proof, first check for where the = sign is and use the position past that sign as input to the Scan from String above.
-
[CR] MPSSE.dll LABview driver
Rolf Kalbermatter replied to Benoit's topic in Code Repository (Uncertified)
It does for me. -
There are various packages around that do different things to different degree. Most of them are actually APIs that existed in the early days of Windows already. Things that come to mind would be querying the current computer name, user name or allowing to actually authenticate with the standard Windows credentials. Others are dealing with disk functionality although the current LabVIEW File Nodes offer many of those functionalities since they were reworked in LabVIEW 8.0. then there are the ubiquitous window APIs that allow to control LabVIEW and other application windows. As far as LabVIEW is concerned most of those things are since a long time also possible through VI server, but the possibility to integrate an external app as child window can be interesting sometimes (although in many cases a questionable design choice). There are of course many newer Windows APIs too but a lot of them are either to specialistic or to complex to be of much interest to most of the people. For instance there have been many attempts at accessing Bluetooth Low Energy APIs in Windows, but that API is complex, badly documented and riddled with compatibility issues, which would make a literal translation with a LabVIEW VI per API function a very useless idea for almost every LabVIEW user. But once you start to go down the path of creating a more LabVIEW user friendly interface, it is usually easier to develop a wrapper library in C that takes care of all the low level hassles and provides a more concise and clean API to the LabVIEW environment, so that one does not have to do very involved C compiler acrobatic tricks on the LabVIEW diagram to satisfy the sometimes rather complicated memory manager requirements of those APIs. The problem with the original idea of the metaformat to allow importing Windows APIs is however that the difficulties of using such an API is very often not limited to making it available in LabVIEW through a Call Library Node. That is indeed specialistic work and can require a deep understanding of C compiler details and memory manager techniques, but the really difficult part is to understand how to use those APIs properly and that use also influences often how you should actually import the API as dadreamer pointed out with the example of string or array pointers that can either be passed a NULL value or the actual pointer. It would be almost impossible to provide this functionality in the current Call Library Node implementation, since LabVIEW does not make a difference between an empty string (or array) and a NULL pointer (in fact LabVIEW has to the outside nothing like a NULL pointer since it does not provide pointers). Internally one of the many optimizations is that all LabVIEW functions are happily accepting a NULL handle to mean the same as a valid handle with the length value set to 0. How to tell LabVIEW that an empty string should pass a NULL value in one case and a pointer to an empty string in the other? Some APIs will crash when being passed a NULL pointer, others will do weird things when receiving an empty C string pointer. And that might not even be something that you want to have in the Call Library Node configuration since there exist APIs that understand a NULL pointer to have a very different meaning (such as to use a specific default value for instance) than what an empty C string will do (omitting this parameter for instance). This has to be programmed explicitly anyways by using a case structure for both cases and only a human can make this decision at this point based on the prosa text in the function documentation. A metaformat can say if a pointer is allowed to be a NULL value or not, but being allowed to be NULL doesn't mean automatically that an empty string should be passed as NULL value. And that all is not really possible to describe in a metaformat in a way that is parsable by an automated tool. It can be described in the prosa text of the Programmer Manual to that function, but often isn't or in a way that says nothing more than what the names of the parameters already suggest anyways. And as mentioned, Windows APIs make only a small fraction of the functions that I have imported through the Call Library Node in my over 25 years of LabVIEW work
-
NI abandons future LabVIEW NXG development
Rolf Kalbermatter replied to Michael Aivaliotis's topic in Announcements
That was very lame of Indy! 😆 -
NI abandons future LabVIEW NXG development
Rolf Kalbermatter replied to Michael Aivaliotis's topic in Announcements
While I prefer non-violence, I definitely feel more for a sword than a gun. It has some style. 😎 -
The potential is there and if done well (which always remains the question) might be indeed a possibility to integrate into the import library wizard. But it would be a lot of work in an area that very few people really use. The Win32API is powerful but not the complete answer to God, the universe and everything. Also there are areas in Windows you can not really access through that API anymore. In addition I wonder what the motivation at Microsoft is for this, considering their push to go more and more towards UWP, which is an expensive abbreviation for a .Net only Windows kernel API without an underlying Win32 API layer as in the normal desktop version. And at the same time and purely for users safety (of course 😄), also a limitation to only install apps from the Online Windows Store. 😀 But the Win32API is only a very small portion of external code you will typically want to interface to. It does not cover your typical device instrument driver that comes in DLL form, often with the latest update 10 years ago and with the only support in the form of obscure online posts with lots and lots of guesswork and wrong assumptions. Also it won't help with shared libraries from Open Source projects, unless some brave contributor dives into the topic and creates that meta description for it. But creation of such a meta description for an API is a lot of very specialistic and almost impossible to automate work. Microsoft may really do it, I'm still sceptical if it will be really finished, but most others will probably throw their hands in the air in despair at the first moment they lay eyes on the documentation of this meta description format. 😎 In the best case it will be several years before there is any significant adoption of this by other parties than Microsoft, and only if Microsoft is actively going to lobby for it by other major computer software providers. In reality someone at Microsoft will likely invent some hand brakes in the form of patents, or special signing authorities, that makes adoption of this by other parties extra difficult. And it won't help a single yota for Linux and Mac platforms, which are also interesting to target with the Call Library Node.
-
Git can't be this terrible, what am I doing wrong?
Rolf Kalbermatter replied to drjdpowell's topic in Source Code Control
My experience comes from the other side. We have started with SVN some 15 years ago or so and while it has limits it worked quite well for us. There are additional limitations because of the binary character of LabVIEW files, but GIT doesn't add anything to the game there really. I have been exposed to GIT in recent years because of customers using it and also from dabbling in some Open Source projects that use GIT and I have to say the experience is overwhelming at first. SVN certainly has its limits but it's working model is pretty simple and straightforward to understand. And it has always worked reliably for me, which I would consider the most important aspect of any source code control system. One of the reasons Microsoft Source Safe has failed miserably was the fact that you could actually loose code quite easily and the Microsoft developers seemed to have completely lost all motivation to work on those hard to tackle problems. With GIT I have painted myself into a corner more than once and while there are almost always some ways to do a Baron Munchausen trick and drag yourself out of that corner by your own hair, it's been sometimes a pretty involved exercise. 😀 -
NI abandons future LabVIEW NXG development
Rolf Kalbermatter replied to Michael Aivaliotis's topic in Announcements
I would agree with Shaun. Looking at the link you provide, the podcasts on that page are typical marketing speak. Many nice words about a lot of hot air. Now, I'm not going to say it is unimportant in nowadays time. Much of our overhyped and overheated economy is about expensive sounding words and lots and lots of people wanting to believe them. In so far it certainly has influence and importance, no matter how artificial it may be. The problem I see with that is that there is little substantial content in the form of real assets that back the monetary value of the whole. It's mostly about abstract ideas, a strong believe system in them much like a religion and very little real substance. Anyone remembers the Golden Calf from the bible? I sometimes wonder if we would have seen something like the 1999 and 2008 crash already, if we hadn't been all consumed with the pandemic instead. The current financial hausse in light of all the people complaining about how bad the economy got hit by the pandemic is nothing else but perverse in that respect. -
What would the named pipe achieve? How do you intend to get the image into the named pipe in the first place? If you need to write C code to access the image from the SDK and put it into a named pipe in order to receive it in LabVIEW through the Pipe VIs, you could just as well write it to disk instead and read it through the LabVIEW File IO functions. Functionally it is not different at all, while the File IO is million times proven to work and the Pipe interface has a lot more potential problems. If your SDK driver has a way to simply put everything automatically into a pipe then it may be worth exploring but otherwise stay far away from this. Any effort in writing C code anywhere is better spend in creating a wrapper shared library that massages the driver API into something more suitable to be called through the LabVIEW Call Library Node.
-
Most likely a cerebral shortcut with his more involved SQLLite library he has worked on so relentlessly over the years. 😀 There is a good chance that the Windows version of the PostgreSQL library is compiled in a way that supports multithreading calls while the Linux version may not. With the CLN set to UI thread, LabVIEW will always switch to the UI thread before invoking the library call, resulting that all such CLNs are always called in the same thread. With "Call in any thread" enabled, LabVIEW will call the shared library function in whatever thread the VI is executing itself. A VI is assigned a so called execution system and each executation system is assigned at startup of LabVIEW a number of threads (typically 8 but this does depend on the number of cores your CPU has and can also be reconfigured in your LabVIEW ini file). Each VI is typically executed in the thread of its caller from inside that thread collection for the execution system unless LabVIEW decides that parallel VIs can be executed in parallel in which case one of the VIs will be called in one of the other threads. LabVIEW does try to avoid unnecessary thread switches since the context switching between threads does incur some overhead. In fact there are at least two potential problems from calling a library with multithreading: 1) If the library uses Thread Local Storage (TLS) to store things between calls, then calls occuring in different threads will access different information and that may cause problems. This should be not the problem here as each connection has its own "handle" and all the things across calls that are important should be stored in that handle and never in TLS. 2) If the library is not protected against simultaneous access to the contents inside the handle (or worse yet global variables in the library), things can go wrong as soon as your LabVIEW program has two different code paths that may run in parallel. It should not be a problem if your LabVIEW program guarantees sequential execution of functions through data flow dependency such as a consequently wired through handle wire and/or error cluster. The fact that the VIs seem to hang immediately on first call of any function, could indicate that it is a Thread Local Storage problem. The loading of the shared library is most likely occurring in the UI thread to make sure that it does run in the so called root loop of LabVIEW and if the library then initializes TLS for some of its stuff, things would go wrong in the "Call in any thread" case as soon as the first function is executed, as it tries to access non initialized TLS values there.
-
Data buffer handling and especially callback functions really requires you to write an intermediate shared library in C(++) to translate between LabVIEW and your driver API. Memory management in LabVIEW has some specific requirements that you need to satisfy and usually goes against what such drivers expect to use. They are written with C programming techniques in mind, which is to say the caller has to adhere to whatever the library developer choose to use. LabVIEW on the other hand is a managed environment with a very specific memory management that supports its dataflow paradigma. There is a clear impedance mismatch between the two that is usually best solved in a wrapper library in C that translates between the two. While it is possible to avoid the wrapper library here, it usually means that you have to both implement the proper C memory management as required by the driver and additionally deal with things that are normally taken care of by the C compiler automatically when you try to implement the translation on your LabVIEW diagram directly. It's possible but pretty painful and gets very nasty rather quickly and results in hard to maintain diagram code especially if you ever intend to support more than one target architecture. As far as callback functions goes, anything but a wrapper library written in C(++) that handles the callbacks and optionally translates them into something more LabVIEW friendly like user events, is simply inventing insanity over and over again.
-
The internal kernel APIs used by the OpenG PortIO kernel driver were discontinued by Microsoft in 64-bit Windows. By the time I looked into this Microsoft also had started to require signing for kernel drivers to be installable. I have no interest to buy a public certificate for something like 100$ a year just to be able to sign an open source driver. That extraction of the kernel driver from the DLL is in theory a neat idea but in practice will only work if the user executing that function has elevated mode. Otherwise kernel driver installation is impossible.
-
Well, the reverse engineering was quite some work as I had to view many different existing CDF files and deduce the functionality of them. But creating a new one for the sqllite library itself should be straight forward by taking the one for lvzip and changing the relevant strings in the CDF file. Only thing besides that is that you need to generate also your own GUID for your package as that is how Max identifies each package. But there are many online GUID generators that can do that for you, and the chance that that will conflict with any GUID already in use is pretty much non-existent. Depending if you also want to support sqllite support for Pharlap and VxWorks you would have to either leave those sections in the CDF file or remove them. You can also handle dependencies and depending on what libraries you need they may actually exist as packages from NI already. Adding such dependencies to your CDF file is basically adding the relevant GUID from that other CDF file and version number to your own CDF file. Works quite well but if NI doesn't have the package available already, things can get more complicated. You either have to create an additional CDF file for each such package or you could possibly add the additional precompiled modules to the initial CDF file. A CDF file can reference multiple files per target, so it's possible but can get dirty quickly.
-
The LabVIEW deployment of VIs to a target does not copy over shared libraries and other binary objects to the target system. (Well it did for Pharlap targets but that was not always desirable. Originally Pharlap's Win32 implementation was fairly close to the Win NT4 and Win2000 API and many DLLs compiled for Windows NT or 2000 would work without change on Pharlap too. But with newer Windows versions diverting more and more from the limited Win32 support provided by Pharlap ETS and unless you went to really great lengths, including NOT using newer Visual Studio versions to compile your DLL, you could forget that a DLL would work on Pharlap. In addition LabVIEW on Windows has no notion of Unix shared libraries and so they simply removed that automatic deployment of such binary files to a target, even if that file would be present in the source tree. The possible implications and special requirements of how to install VxWorks OUTs and Unix SOs on a target system were simply to involved and prone to problems.) So to get such files properly put on the target system you need a separate installer. NI uses for their software libraries the so called CDF (Component Description Format) (not sure if they developed that themselves or snatched it from somewhere 😀). For the LV ZIP Toolkit I "reverse engineered" the NI CDF file structure to create my own CDF file for my lvzlib shared library. When you place that and the according shared library/ies into a folder inside <ProgramFilesx86>\National Instruments\Shared\RT Images, NI Max will see this cdf file and offer to install the package to the remote target if the supported targets in the CDF file are compatible with the target for which you selected the Install menu. This works but is made extra complicated by the fact that a normal user has no write access to the Shared directory tree. So if you add these files to your VI package, you must require VIPM to be started as administrator. Extra complication is that VIPM does not offer the "Shared/RT Images" path as a target option, so you would need to do all kind of trickery with relative paths, to get it installed there. I instead used InnoSetup to create a setup program containing those files and configured to require administrator elevation on startup. I then start this setup program from the PostInstall step in the package. But NI has slated CDF to be discontinued sometimes in the near future and to require NIPM packages instead to be used.
-
How does VIPM set the VI Server >> TCP/IP checkbox?
Rolf Kalbermatter replied to prettypwnie's topic in LabVIEW General
The fact that VIPM does require a restart of LabVIEW is probably a good indication as to what it does. 1) enumerate all installed LabVIEW versions 2) read the labview.ini in that location and extract the VI server settings 3) if user changes the settings for a LabVIEW version, update the LabVIEW.ini file and require a restart On restart LabVIEW reads the LabVIEW.ini file and all is according to what VIPM wanted it. Simple and no hidden vodoo magic at all. -
NI abandons future LabVIEW NXG development
Rolf Kalbermatter replied to Michael Aivaliotis's topic in Announcements
https://www.theregister.com/2021/01/05/qt_lts_goes_commercial_only/ One more issue about using QT unless you are fully commercial already anyhow. -
Yes, except that without WinSxS you had one problem, with WinSxS you end up having several more problems! 😀 While maintaining binary compatibility across library versions requires some real discipline, abandoning that and trying to solve it with something like WinSxS is simply getting you further down the rabbit hole.
-
Welcome back. Enjoy it!
-
XWindows is not the main problem, although admittedly not the most easy API to tackle UI drawing. I think QT would be a lot easier but there you have licensing issues if you are not a truly open source project. But XWindows as an API is pretty standardized and has very few of the problems Shaun alluded too. But XWindows is just a basic UI API. Once you want to tackle things that are more user related you end up with a myriad of different desktop management standards that are all fundamentally different and while there were some attempts to standardize things they are usually not much more than recommendations that different projects adhere to in very different ways. Also another problem in the Linux world are various system interfaces that sometimes change on an eye wink and also can greatly vary between Linux distributions. And if they don't change entire subsystems just because they can, it is quite common to make binary incompatible API changes that require often specific version of libraries and aren't upwards compatible at all. So if you want to install library XY you end up needing library Z, V, A and T all in specific versions except that library ZV needs some of these in different versions and if your project depends both on XY and ZV you are screwed. That each of those Linux distributions uses their own packaging system doesn't help this at all either. It's not just the repositories that vary but also the format, dependency tracking and all that. If you want to develop an application like LabVIEW that should support all major Linux distributions you end up spending countless hours of debugging and code tweaking to work around all these kind of trouble only to have to do the whole work again 6 months from now.
-
The problem with the argument about better mergeability if LabVIEW would use a text based file format is that XML and really any format that can represent more complex data structures, can not easily be merged with current tools. It doesn't even fully work for normal text based languages as the merge tool can NOT determine what to do when two code modifications occurred at the same or immediately adjacent line location in a text file. You end up with conflicts that have to be resolved manually. While that is doable although not fully painless for normal text based languages, XML and similar formats pose an additional challenge since a change in one element can actually cause changes in multiple line locations, often separated by many text lines. As soon as two different changes are somehow not totally independent in line location, you can't merge just based on line information. And in the worst case a single change can basically mean a modification right in the beginning of the file and one at the end. With such a change any other change is potentially very problematic to merge. And just doing the standard conflict resolution for text files as it is done now, with including both sections and letting the user manually decide which to use, would basically just create a double as big file, which would be pretty useless to try to manually merge. So while converting LabVIEW binary files to XML or similar sounds like a good idea, it won't solve the problem of merging in source code control really. In a way the current situation is easier: You know it can't be done automatically so are forced to plan accordingly! XML may in that respect seem to many to promise something that could not be delivered anyways in most merge situations. To do any meaningful merging for anything but the most trivial modifications in XML format, one would have to create a diff/merge tool that fully understands XML and to make matters worse, it should also be aware of the actual schema used in the XML file. Even then creating an XML format from that merge result would be only partly helpful, one would really need an interactive merge visualizer that presents the XML data structure to the user directly in a suitable graphical form such as a tree view and lets him select the relevant modification when there are any logical conflicts. As to creating external tools for dealing with LabVIEW files without the need to script things in LabVIEW itself, the idea sounds good, but I doubt it will be used a lot. Maybe a translation tool for different languages but many such things are rather runtime features than edit time features. About throwing away LabVIEW for non-Windows platforms: That is hardly an argument to even start to try to remain relevant in comparison to things like Python or in a far far future from now maybe .Net. Python runs on pretty much every hardware you can imagine that has a C compiler available, from low end 8-bit microprocessors to extreme high end system. There are also literally exclusive points in that list. * Stop adding new features to LabVIEW for several years This directly contradicts several other items in that list.
-
G Interfaces for LabVIEW 2020
Rolf Kalbermatter replied to Aristos Queue's topic in Object-Oriented Programming
To be honest, I would probably not put them anywhere in that view. It’s called Class View for a reason. 😀 It hadn’t really occurred to me that you would want to have the non-class VIs visible in there. Is that a flaw or just out of the box thinking? -
Poll: Should the CLA Exam require applied knowledge of OOP?
Rolf Kalbermatter replied to Mike Le's topic in LabVIEW General
Point in case: LabVIEW NXG! -
NI abandons future LabVIEW NXG development
Rolf Kalbermatter replied to Michael Aivaliotis's topic in Announcements
QT from a pure technological view might be a good choice. From a licensing point of view it might be quite a challenge however. Qt | Pricing, Packaging and Licensing That all said, they do use a QT library in the LabVIEW distribution somehow. Not sure for which tool however, but definitely not the core LabVIEW runtime. If it is for an isolated support tool, it is quite manageable with a single user license. For the core LabVIEW runtime, many of the LabVIEW developers would need a development license. And some of the QT paradigms aren't exactly the way a LabVIEW GUI works. Aspect ratio accurate rendering would most likely be even further from what it is now with even bigger differing results when loading a VI frontpanel on different platforms. -
NI abandons future LabVIEW NXG development
Rolf Kalbermatter replied to Michael Aivaliotis's topic in Announcements
The cross platform backend they definitely have already. It exists since the early days of multiplatform LabVIEW whose first release was version 2.5 on Windows. It was originally fully written in C and at times a bit hackish. The motto back then was: make it work no matter what even if that goes against the neatness of the code. In defense it has to be said that what is considered neat code nowadays was totally unknown back then and in many cases even impossible to do, either because the tools simply did not exist or the resulting code would have been unable to start up on the restrained resources even high end systems could provide back then. 4MB of RAM in a PC was considered a reasonable amount and 8MB was high end and costing a fortune. Customers back then were regularly complaining about not being able to do create applications that would do some "simple" data acquisition such as a continuous streaming of multiple channels at 10kS/s and graphing it on screen with a PC with a "whooping" 4MB of memory. The bindings to multiple GUI technologies also exists. The Windows version uses Win32 window management APIs, and GDI functions to draw the content of any front panel, Mac used the MacOS classic window management APIs and Quickdraw and later the NSWindows APIs and Quartz, while the Linux version uses for everything the XWindows API. These are quite different in many ways and that is one of the reason why it is not always possible to support every platform specific feature. The window and drawing manager provide a common API to all the rest of LabVIEW and higher level components are not supposed to ever access platform APIs directly. But moving to WPF or similar on Windows would not solve anything, but only make the whole even more complicated and unportable. The LabVIEW front end is built on these manager layers. This means that LabVIEW does basically use the platform windows only as container and everything inside them is drawn by LabVIEW itself. That does have some implications since every control has to be done by LabVIEW itself but on the other hand trying to do a hybrid architecture would be a complete nightmare to manage. It would also mean that there is absolutely no way to control the look and feel of such controls across platforms. You have that already to some extend since LabVIEW does use the text drawing APIs of each individual platform and scales the control size to the font attributes of the text as drawn on that platform, resulting in changed sizes of the control frames if you move a front panel from one computer to another. If LabVIEW would also rely on the whole numeric and text control as implemented by the platform those front panels would look even more wildly different between computers. And no, front end moved into the IDE is not a solution either. Each front panel that you show in a build application is also a front end part so needs to be present as core runtime functionality and not just an IDE bolted on feature. -
HTTP Post does not work
Rolf Kalbermatter replied to Thang Nguyen's topic in Remote Control, Monitoring and the Internet
HTTP Error 401: https://airbrake.io/blog/http-errors/401-unauthorized-error#:~:text=The 401 Unauthorized Error is,client could not be authenticated.&text=Conversely%2C a 401 Unauthorized Error,to provide any such authentication. Somehow your HTTP server seems to require some authentication and you have not added any header to the query that provides such authentication.