Rolf Kalbermatter
-
Posts
3,968 -
Joined
-
Last visited
-
Days Won
281
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-

VISA read timeout, all data received
Rolf Kalbermatter replied to ThomasGutzler's topic in LabVIEW General
Because your logic is not robust. First you seem to use termination character but your binary data can contain termination character bytes too and then your loop aborts prematurely. Your loop currently aborts when error == True OR erroCode != <bytes received is bytes requested>. Most likely your VISA timeout is a bit critical too? Also note that crossrulz reads 2 bytes for the <CR><LF> termination character while your calculation only accounts for one. So if what you write is true, there still would be a <LF> character in the input queue that will show up at the next VISA Read that you perform. As to PNG containing checksum: Yes it does, multiple even! Each data chunk in the image data is compressed with the zlib deflate algorithme and this contains a CRC32 checksum! -
Where do you discuss LabVIEW?
Rolf Kalbermatter replied to Michael Aivaliotis's topic in LAVA Lounge
I don't think that would work well for Github and similar applications. FINALE seems to work (haven't tried it yet) by running a LabVIEW VI (in LabVIEW obviously) to generate HTML documentation from a VI or VI hierarchy. This is then massaged into a format that their special WebApp can handle to view the different elements. Github certainly isn't going to install LabVIEW on their servers in order to run this tool. They might (very unlikely) use Python code created by Mefistoles and published here to try to scan project repositories to see if they contain LabVIEW files. But why would they bother with that? LabVIEW is not like it is going to be the next big hype in programming ever. What happened with Python is pretty unique and definitely not going to happen for LabVIEW. There never was a chance for that and NI's stance to not seek international standardization didn't help that, but I doubt they could have garnered enough wide spread support for this even if they had seriously wanted to. Not even if they had gotten HP to join the bandwagon, which would have been as likely as the devil going to church 😀. -
Where do you discuss LabVIEW?
Rolf Kalbermatter replied to Michael Aivaliotis's topic in LAVA Lounge
It used to be present in the first 50 on the TIOBE index, but as far as I remember the highest postion was somewhere in the mid 30ies. The post you quoted states that it was at 37 in 2016. Of course reading back my comment I can see why you might have been confused. There was a "n" missing. 😀 Github LabVIEW projects are few and far in between. Also I'm not sure if Github actively monitors for LabVIEW projects and based on what criteria (file endings, mention of LabVIEW in description, something else?). -
Where do you discuss LabVIEW?
Rolf Kalbermatter replied to Michael Aivaliotis's topic in LAVA Lounge
Interesting theory. Except that I don't think LabVIEW never got below 35 in that list! 😀 -
Wasn't aware that LabVIEW still uses SmartHeap. I knew it did in LabVIEW 2.5 up to around 6.0 or so but thought you guys had dropped that when the memory managers of the underlaying OS got smart enough themselves to not make a complete mess of things (that specifically applied to the Win3.1 memory management and to a lesser extend to the MacOS Classic one).
-
Question: Does anybody use "Cyth SQLite Logger"
Rolf Kalbermatter replied to drjdpowell's topic in Database and File IO
I symply use syslog in my applications and then a standard syslog server to do whatever is needed for. Usually the messages are viewed in realtime during debugging and sometimes simply dumped to disk afterwards from within the syslog server, but there is seldom much use of it once the system is up and running. If any form of traceability is required, we usually store all relevant messages into a database, quite often that is simply a SQL Server express database. -
I've seen that with clients I have been working for on LabVIEW related projects. A new software development manager came in with a clear dislike for LabVIEW as it is only a play toy. The project was canceled and completely rebuild based on a "real" PLC instead of a NI realtime controller. The result was a system that had a lot less possibilities and a rather big delay in shipping the product. Obviously I didn't work on that "new" project and don't quite know if it was ever installed at the customer site. That said, we as company are reevaluating our use of LabVIEW currently. We have no plans to abandon it anytime soon, but other options are certainly not excluded from being used whenever it makes sense and there have been more and more cases that would have been solved in the past in LabVIEW without even thinking twice, but are currently seriously looked at to be done in other development platforms. And I know that this trend has been even stronger at many other companies in the last 5 years or so. My personal feeling is that the amount of questions in general has dropped. The decline is less visible on the NI fora, but all the other alternative fora including LAVA, have seen a rather steep decline in activity. Much of the activity on the NI fora tends to be pretty basic beginner problems or installation pericles and pretty little advanced topics. It could be because all the important questions for more advanced topics already have been tackled but more likely it is because the people who traditionally use LabVIEW for advanced usage are very busy in their work and the others are dabbling their feet in it, come with their beginner problems to the NI fora and then move on to something else rather than developing to the intermediate and advanced level of LabVIEW use. Also with exception of a few notable people, participation of NI employees in the fora seems nowadays almost non-existent and except the aforementioned notable exceptions, many times if an NI empoyee eventually reacts after a thread has stayed unanswered from other fora members for several days, doesn't go very much beyond the standard questions of "What LabVIEW version are you using? Have you made sure the power plug is attached?" and other such pretty unhelpful things. This is especially painful when the post in question clearly states a problem that is not specific to a certain version and pretty well known to anyone who would even bother to start up just about any LabVIEW version and try the thing mentioned! It sometimes makes me want to tell that blue eagle (äah is that a greenie now?) to just shut up.
-
That's the standard procedure for path storing in LabVIEW. If the path root is different, LabVIEW will normally store the abolute path, otherewise a relative path relative to the entity that contains the path. Using relative paths is preferable for most things, but can have issues when you try to move files around outside of LabVIEW (or after you compiled everything into an exe and/or ppl). But absolute paths are not a good solution either for this. LabVIEW also knows so called symbolic path roots. That are paths starting with a special keyword such as <vilib>, <instrlib>, and similar. This is a sort of relative path to whatever the respective path is configured in the actual LabVIEW instance. They refer by default to the local vi.lib, inst.lib and so on directories but can be reconfigured in the LabVIEOW options (but really shouldn't unless you know exactly what you are doing). Chances to mess up your projects this way are pretty high.
-
Sure it was a Windows extender (Win386) but basically built fully on the DOS/4GW extender they licensed from Rational Systems. It all was based on the DPMI specifiation as basically all DOS Extenders were. Windows 3.x was after all nothing more than a graphical shell on top of DOS. You still needed a valid DOS license to install Windows on top of it.
-
One correction. the i386 is really always a 32 bit code resource. LabVIEW for Windows 3.1 which was a 16-bit operating system was itself fully 32-bit using the Watcom 32-bit DOS extender. LabVIEW was compiled using the Watcom C compiler which was the only compiler that could create 32-bit object code to run under Windows 16-bit, by using the DOS extender. Every operating system call was translated from the LabVIEW 32-bit execution environment into the required 16-bit environment and back after the call through the use of the DOS extender. But the LabVIEW generated code and the CINs were fully 32-bit compiled code. While the CINs were in the Watcom REX object file format, and LabVIEW for Windows 32-bit later by default used the standard Windows COFF object format for the CINs resources, it could even under Windows 32-bit still load and use the Watcom generated CINs in REX object file format. The main difference was simply that a REX object file format had a different header than a COFF object file format but the actual compiled object code in there was in both cases simply i386 32-bit object code. Also LabVIEW 2021 or more likely 2022 is very likely going to have an 'mARM' platform too. 😃
-
I just made them up! I believe NI used the 'i386' as a FourCC identifier for the Win32 CINs. From my notes: i386 Windows 32-bit POWR PowerPC Mac PWNT PowerPC on Windows POWU PowerPC on Unix M68K Motorola 680xx Mac sprc Sparc on Solaris PA<s><s> PA Risc on HP Unix ux86 Intel x86 on Unix (Linux and Solaris) axwn Alpha on Windows NT axln Alpha on Linux As should be obvious some of these platforms never saw the light of an official release and all the 64-bit variants as well as the vxworks versions never were created at all, as CINs were long considered obsolete before VxWorks was released in 8.2 and the first 64-bit version of LabVIEW was released with LabVIEW 2009 for Windows. There even was some work done for a MIPS code generator at some point. And yes the problem about adding multiple CIN resources for different architectures was that it relied on the 'plat" resource inside the VI. So you only could add one CIN resource per CIN name into a VI, rather than multiple ones. All platforms except the i386 and Alpha, used to be Big Endian. Later ARM came as an additional Little Endian target to the table. Currently only the VxWorks target is still a supported Big Endian platform in LabVIEW.
-
Well if you are correct is of course not debatable at this time but there is definitely a chance for this. Don't disregard the VIs interfacing to the shared library though. A wrongly setup Call Library node is at least as likely if not more. Obvously there seems to be something off where some code tries to access a value it believes to be a pointer but instead is simply an (integer) number (0x04). Try to locate the code crash more closely by first adding more logging around the function calls to the library to see where the offending call may be, and if that doesn't help by disabling code sections to see when it stops crashing and when it returns crashing. My first thing would be to however review every single VI that calls this library and verify that the Call Library Node exactly matches the prototype of the respective functions and doesn't pass in unallocated or to short strings and array buffers. LabVIEW certainly can cause segfaults but it is extremely rare that that happens nowadays in LabVIEW itself. But even LabVIEW developers are humans and have been known to bork up things in the past. 😀
-
CINs have nothing to do with LabWindows CVI, aside of the fact that there was a possibility to create them in LabWindows CVI. They were the way of embedding external code in a LabVIEW VI, before LabVIEW got the Call library Node. They were based on the idea of code resources that every program on a Macintosch consisted of before Apple moved to Mac OS X. Basically any file on a Mac consisted of a data fork that contained whatever the developer decided to be the data and a resource fork that was the model after which the LabVIEW resource format was modelled. For the most part the LabVIEW resource format is almost a verbatim copy of the old Macintosh resource format. A Macintosh executable usually consisted of an almost empty data fork and a resource fork where all the compiled executable code objects where just one of many Apple defined resource types together with icons, images, (localized) string tables and custom resource types that could be anything else a developer could dream up. Usually with the exception for very well known resource types these files also contained resource descriptions (a sort type descriptor like what LabVIEW uses for its type system) as an extra resource type for all its used resource types. The idea of CINs was interesting but cumbersome to maintain as you had to use the special lvsbutil executable to put the CIN code resource into the VI file. And in my opinion they stopped short of creating a good system by only allowing one CIN code resource per CIN name. If they had instead allowed for multiple CINs to exist for a specifc name, one for each supported platform (m68k, mppc, mx86, sparc, wx86, wx64, vxwk, arm, etc) one could have created a VI that truely runs on every possible platform by putting all the necessary code resources in there. As it was, if you put a Mac 68k code resource into the VI it would be broken on a Mac PPC or on Windows system and if you put a Windows code resource in it it would be broken on the Mac. Also once the Call Library Node supported most possible datatypes, CINs basically lost every appeal unless you wanted to hide the actual code resource by obfuscating it inside the VI itself. And that was hardly an interesting feature, but was bought with lots of trouble from having to create seperate C code resources for every single CIN (shared libraries can contain hundreds of functions all neatly combined in one file) and also a maintenance nightmare if you wanted to support multiple platforms. As to the articles mentioned in the link from dadreamer, I resurrected them from the wayback engine a few years ago and you can find them on https://blog.kalbermatter.nl
-
I first thought it may have to do with the legacy CINs but it doesn't look like that although it may be a similar idea. On second thought it actually looks like it could be the actual patch interface for the compiled object code of the VIs. It seems the actual code dispatch table that is generated during compiling of a VI. As such I doubt it is very helpful for anything unless you want to modify the generated code somehow after the fact.
-
LINX SPI CE Line select - Raspberry Pi
Rolf Kalbermatter replied to Jordan Kuehn's topic in LabVIEW Community Edition
I'm not sure which Python interface you use but the one I have seen really just uses a shared library to access those things too and uses exactly that function too. -
LINX SPI CE Line select - Raspberry Pi
Rolf Kalbermatter replied to Jordan Kuehn's topic in LabVIEW Community Edition
Well, one problem is that your Python script uses GPIO pin numbers while Linx uses connector pin numbers. Now the GPIO25 happens to be Linx pin 22, so you got that right. But the GPIO22 pin is the Linx pin 15 and you configure that as custom CS signal. This is wrong. The Python script sets this explicitly to be an input and with pullup resistor. The Linx custom CS handling will set this as output and actively drive it, asserting it before every frame and deasserting it afterwards. This is likely going to conflict with whatever your hat is trying to do. There are two things you can try: - Set the custom CS pin for the SPI ReadWrite function to a pin number that is not connected to any pin on your hardware. That will make sure it doesn't conflict with your hardware. Call before the Digital Write for pin 22 an explicit Digital Read for pin 15. This will make sure the digital pin is configured as input. Unfortunately Linx does not allow you currently to configure a pullup/pulldown pinstate, but it may be enough to let your hardware work. -
LINX SPI CE Line select - Raspberry Pi
Rolf Kalbermatter replied to Jordan Kuehn's topic in LabVIEW Community Edition
I will create a pull request for the minor fixes to the Makerhub repo. The current changes are much bigger and restructure quite some code for the BeagleBone and Raspberry Pi. They will also provide the true Pi Model string as Device Name, rather than the current static fixed string. And support two SPI channels and maybe even support for reading the EEPROM I2C on the hat connector, but that may not be something I can easily add from the user space environment the shared library is running in. There will also be a more robust listener and also a client implementation for serial and TCP directly in the shared library. I even found information on how to access the onchip OTP memory but that may not be so helpful. As it is OTP you can't program it multiple times really but you could read some of the device configuration information that way. -
LINX SPI CE Line select - Raspberry Pi
Rolf Kalbermatter replied to Jordan Kuehn's topic in LabVIEW Community Edition
The note in the C source code is in my opinion false. Unless you add the SPI_NO_CS flag to the SPI mode byte the SPI driver will use the default CS pin that it is assigned by the standard setup. For /dev/spidev0.0 this would be the CE0 signal and for /dev/spidev0.1 this would be CE1. However the Linx driver for the Raspberry Pi only allows for /dev/spidev0.1 to be instantiated. I've been hacking on the liblinxdevice.so driver myself and have added the /dev/spidev0.0 to the allowable SPI channels and also modified the SPIReadWrite() function to skip the custom CS handshake handling when the CS pin is set to 0, which makes more sense to me. It should be possible to disable the standard CS pin too by adding 0x40 (SPI_NO_CS flag) to the mode value that you use to set the SPI mode from your LabVIEW program. The current liblinxdevice.so driver on my github clone is actually even further altered and at the moment in an highly untested state, but I'm planning to spend some time on that over the weekend. I basically redesigned part of the class hierarchy to use a common Linux specific ancestor class for both Raspberry Pi and BeagleBoneBlack devices since they are both very much Linux based. The main difference is only during the initialization where both drivers need to do different initialization routines, and enumerate and enable specific resources. Once that is done the functionality is very much the same for both devices. I also did some preparation for a remoteable interface to the liblinxdevice shared library that would make the whole LabVIEW VI interface implementation a lot simpler and the remote communcation more stable. -
My Lack Of Knowledge On Hex???
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in LabVIEW General
Well ~00R means reject. That is of course not to helpful but it tells you that: 1) you can send commands to the device 2) It receives them and reacts to them I checked the source code and it's my bad. The identification command is UID, so try that instead of the IDN. Must have been thinking of GPIB/SCPI when I wrote that part. Now the next command to try is would be the ~00P003VER vor a version query. Then the various status commands STA, STB, STI, STO. -
My Lack Of Knowledge On Hex???
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in LabVIEW General
Your UPS seems to be a SmartOnline model. Looking at the NUTS source code I see that the protocol is constructed as follows: ~00<message type><3 bytes: decimal length><3 bytes: command><remainder: parameters> So: 7E 30 30 50 30 30 34 53 4F 4C 31 as crossrulz pointed out translates to ~00P004SOL1 which means - P for Poll - 004 for message length - SOL for relay status - 1 relay number (my guess) The answer is: ~00D0010 which means - D for data - 001 length - 0 relay status Try to send for lolz ~00P003IDN A robust receiver implementatation will first read 4 characters. These should be either ~00D or ~00A. A means an acknowledge of the command without further data and D is a response with additional data. Anything else is an error and you should flush the buffer. So if you receive ~00A you are done, otherwise you read the next three bytes and interpret it as a decimal number. This is the number of remaining bytes to read. As you can see in those sources there are actually several protocols for Tripplite. The other seems to be the Omnivis type protocol which uses :<1 or 2 bytes: command><optional: extra parameters><carriage return> :D\r // request status message even for their USB interfaces that are not HID based. -
Communicate with hardware using USB HID?
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in Hardware
You did not address the other mentioned issues. Assuming that the return data is constructed in the same way than the command you would need to read 3 bytes, decode the 3rd byte as length and read the remaining data + any CRC and other termination codes.
-
Communicate with hardware using USB HID?
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in Hardware
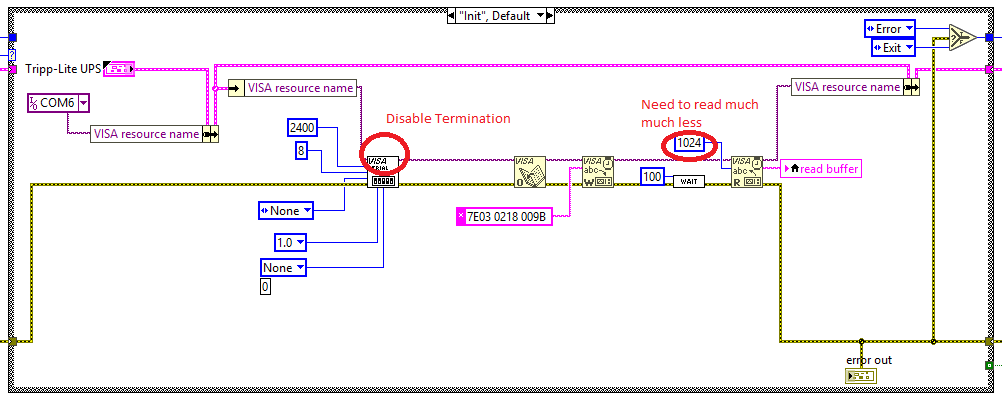
It's always a good idea to show the code indication (Display Style) on a string constant! Serial Port Initialize by default enables the message termination protocol. That is for binary protocols often not very helpful. And in that case you need to get the message length right such as reading the header until the message length, decoding the length and read the reminder plus any CRC or similar bytes. -
Communicate with hardware using USB HID?
Rolf Kalbermatter replied to rharmon@sandia.gov's topic in Hardware
That would indicate a USB VCP, not USB HID! While the format is indeed not very descriptive as you posted, a USB VCP should be easily accessible through NI VISA. -
I use Visual Studio and launch LabVIEW from within Visual Studio to debug my DLLs and unless I quirk up something in kernel space somehow I always get into the Visual Studio Debugger, although not always into the source code, as the crash can be in one of the system DLLs.
-
Your experience seems quite different than mine. I get never the soundless plop disappearance, but that might be because I run my shared library code during debugging from the Visual C debug environment. But even without that, the well known 1097 error is what this wrapper is mostly about and that happens for me a lot more than a completely silent disappearence.