Rolf Kalbermatter
-
Posts
3,968 -
Joined
-
Last visited
-
Days Won
281
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-

"LabVIEW" CLN calls: are we supposed to know?
Rolf Kalbermatter replied to ensegre's topic in LabVIEW General
Well, this may be not an official NI document but it is an example being published over 12 years ago. It sort of documents the use of the LabVIEW keyword in the Call Library Node as library name, to refer to the internal LabVIEW kernel functions. It is also used in various places in VIs inside vi.lib, so not very likely to change over night either. The fact that you could refer to the LabVIEW kernel functions through use of this keyword is more or less present since the Call Library Node was introduced in LabVIEW around 5.0. Changing this now would break lots of code out there, which either inherited some of those password protected VIs from vi.lib or custom made libraries that were created by various people. I'm personally not really to much concerned that this would suddenly go away. How and if it is supported in LabVIEW NXG I haven't looked at yet, but unless you want to be NXG compatible too with your library, which I suppose will impose quite a few other more important challenges than this, I would not bother. -
I find that a bit unwieldy, but could go for the 60 weeks year, with 6 days per week and no designated weekend, but rather a 4 day work shift. It would also solve some of the traffic problems at least to some extend as only 2 third of the population would at any moment be in the work related traffic jams, and 1 third in the usually on different times and different locations occuring weekend traffic jams. And the first Deci calendar was the French Republican calendar, but it was very impractical and hard to memorise, with every day of the year having its own name. Napoleon abolished it quickly after taking over power, and not just because it was not his own idea :-).
-
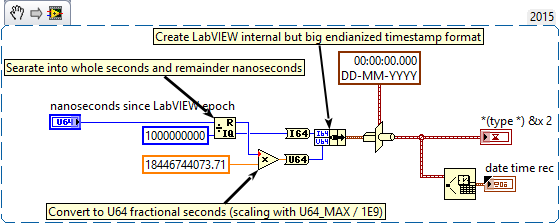
One extra tidbit: The Timestamp fractional part is AFIK actually limited to the most relevant 32 bits of the 64 bit unsigned integer. For your situation that should not matter at all as you still get a resolution of about 0.1 ns that way. Also while the Timestamp allows a range of +- 263 or +-10E19 seconds (equals ~3*10E12 or 3 trillion years) from the LabVIEW time epoch, with a resolution of ~0.1ns, 99.9% is not even theoretical useful since calendars as we know it only exist for about 5*10E3 years. It's pretty unlikely that the Julian or Gregorian calendar will still be used in 1000 years from now.
-
I also have a method to propose: U64 Nanoseconds to LabVIEW Timestamp.vi

-
Calling GetValueByPointer.xnode in executable
Rolf Kalbermatter replied to EricLarsen's topic in Calling External Code
Nope sorry. Somewhere between transfering that image to the LAVA servers and then back to my computer something seems to have santized the PNG image and removed the LabVIEW specific tag. The image I got onto my computer really only contains PNG data without any custom tags. The same thing seems to happen with the snippet from my last post. I suspect something in Lava doing some "smart" sanetizing when downloading known file formats, but can't exclude the possibility of a company firewall doing its "smarts" transparently in the background. Hope that Michael can take a look in this if snippets have been getting sanitized on Lava or if it is something in our browsers or network. I attached a simplified version of my VI for you. C String Pointer to String.vi -
Labview anti-pattern: Action Engines
Rolf Kalbermatter replied to Daklu's topic in Application Design & Architecture
It's not necessarily a mistake but if you go down that path you have to make double and triple sure to not create circular references and similar stuff in your class hierarchy. While this can work on a Windows system (albeit with horrendous load times when loading the top level VI and according compile times) an executable on RT usually simply dies on startup with such a hierarchy. -
Data type matching when calling a DLL
Rolf Kalbermatter replied to patufet_99's topic in Calling External Code
The bitness of LabVIEW is relevant. 32-bit LabVIEW doesn't suddenly behave differently when run on a 64-bit system! -
Data type matching when calling a DLL
Rolf Kalbermatter replied to patufet_99's topic in Calling External Code
Actually it's more compilicated than that! On Windows 32-bit, (and Pharlap ETS) LabVIEW indeed assumes byte packing (historical reasons, memory was scarce in 1990 and that is when the 32-bit architecture of LabVIEW was built) and you have to add the dummy element fillers to make the LabVIEW cluster match a default C aligned structure. On Windows 64-bit they changed the alignment of LabvIEW structures to be compatible to the default alignment of 8-byte most C compilers assume nowdays. And yes while the default alignment is 8 byte this does not mean that all data elements are aligned to 8 byte, The alignment rule is that each data element is aligned to a multiple of the greater of its own size or the current alignment setting (usually the default alignment but can be changed with #pragma pack to something else temporarily when declaring a struct datatype). The good news is that if you pad the LabVIEW clusters that you pass to the API, it will work on both Windows versions, but might not on other platforms (Mac OS X, Linux and embedded cRIO systems). So if you do multiplatform development a wrapper DLL to fix these issues is still a good idea! -
I'm sorry Benoit but your explanation is at least misleading and as I understand it, in fact wrong. A C union is not a cluster but more like a case structure in a type description. The variable occupies as much memory as the biggest of the union elements needs. With default alignment these are the offsets from the start of the structure: typedef struct tagZCAN_CHANNEL_INIT_CONFIG { /* 0 */ UINT can_type; //0:can 1:canfd union { struct { /* 4 */ UINT acc_code; /* 8 */ UINT acc_mask; /* 12 */ UINT reserved; /* 16 */ BYTE filter; /* 17 */ BYTE timing0; /* 18 */ BYTE timing1; /* 19 */ BYTE mode; } can; struct { /* 4 */ UINT acc_code; /* 8 */ UINT acc_mask; /* 12 */ UINT abit_timing; /* 16 */ UINT dbit_timing; /* 20 */ UINT brp; /* 24 */ BYTE filter; /* 25 */ BYTE mode; /* 26 */ USHORT pad; /* 28 */ UINT reserved; } canfd; }; }ZCAN_CHANNEL_INIT_CONFIG; So the entire structure will occupy 32 bytes: the length of the canfd structure and the extra 4 bytes for the can_type variable in the beginning. The variant where a can message is described only really occupies 24 bytes, and while you can pass in such a cluster inside a cluster with the can_type value set to 0 if you send the value to the function for reading you always will have to pass in 32 bytes if the function is supposed to write a message frame into this parameter as you might not know for sure what type the function will return.
-
Should I use .net or a custom library
Rolf Kalbermatter replied to ATE-ENGE's topic in LabVIEW General
There is no right or wrong here. It always depends! .Net is Windows only and even if there exists Mono for Linux platforms it is not really a feasible platform for real commercial use, even with .Net Core being made open source. And that is why CurrentGen LabVIEW never will support it and NexGen LabVIEW which is based for some parts on .Net still has a very long way to go before it may be ever available on non-Windows platforms. My personal guess is that NexGen will at some point support the NI Linux RT based RIO platforms as target but it will probably never run on Macs or Linux systems as host system. So if you want to stay on Windows only and never intend to use that code on anything else including RIO and other embedded NI platforms, then you should be safe to use .Net. Personally I try to avoid .Net whenever possible since it is like adding a huge elephant to a dinosaur to try to make a more elegant animal, and using my code on the embedded platforms is regularly a requirement too. Admittingly I do know how to interface to platform APIs directly so using .Net instead, while it sometimes may seem easier, feels most times like a pretty big detour in terms of memory and performance considerations. For things like the mentioned example from the OP, I definitely would prefer a native LabVIEW version if it exists than trying to use .Net, be it a preexisting Microsoft platform API (which exists for this functionality) or a 3rd party library. Incidentally I implemented my own Hash routines long times ago, one of them being a Sha256, but also others. Other things like a fully working cryptographic encryption library are not feasible to implement as native LabVIEW code. The expertise required to write such a library correctly is very high and even if someone is the top expert in this area, a library written by such a person without serious peer review is simply a disaster waiting to happen, where problems like HeartBleed or similar that OpenSSL faced will look like peanuts in comparison. If other platforms than Windows is even remotely a possibillity then .Net is in my opinion out of question, leaving either external shared libraries or LabVIEW native libraries. -
ADODB possible LabVIEW ActiveX Bug
Rolf Kalbermatter replied to GregFreeman's topic in LabVIEW General
One difference between LabVIEW and .Net is the threading for ActiveX components. While ActiveX components can be multithreading safe, they seldom really are and specify the so called Apartement threading to be required. This means that the component is safe to be called from any user thread but that all methods of an object need to be called from the same thread that was used when creating the object. In .Net as long as you do not use multi-threading by means of creating Thread() objects or some derivated objects of Thread(), your code runs single threaded (in the main() thread of your application). LabVIEW threading is more complicated and automatic multi-threading. This means that you do not have much control over how LabVIEW distributes code over the multiple threads. And the only thread execution system where LabVIEW does guarantee that all the code is called in the same thread is the UI Execution system. This also means that apartment threaded ActiveX objects are always executed in the UI Execution system and have to compete with other UI actions in LabVIEW and anything else that may need to be called in a single threaded context. This might also play a role here. Aside from that, I'm not really sure how LabVIEW should know to not create a new connection object each time, but instead reuse an already created one. .Net seems to somehow do it but the API you are using is in fact a .Net wrapper around the actual COM ADO API.- 5 replies
-
- 1
-

-
- connections
- database
- (and 1 more)
-
There is no rule anywhere that forbids you to post in multiple places. There is however a rule at least here on Lava that asks people to mention in a post, if they posted the same elsewhere. That is meant as a courtesy to other readers who might later come across a post, so they know where to look for potential additional answers/solutions.
-
Running LabVIEW executable as a Windows Service
Rolf Kalbermatter replied to viSci's topic in LabVIEW General
Not for free, sorry. It's not my decision but the powers in charge are not interested to support such a thing for external parties nor give it away for free. And I don't have any copyright on this code. -
Duplicate post over here.
-
Investigating LabVIEW Crashes - dmp file
Rolf Kalbermatter replied to 0_o's topic in Development Environment (IDE)
Error 1097 is hardly related to a resource not being deallocated but almost always to some sort of memory corruption due to overwritten memory. LabVIEW sets up an exception handler around Call Library Nodes if you don't disable that in the Call Library Node configuration, that catches low level OS exception, and when you put the debug level to the highest, it also creates some sort of trampoline around buffers. That are memory areas before and after buffers passed to the DLL function as parameter and filled with a specific pattern and after the function returns to LabVIEW, it checks that these trampoline areas still contain the original pattern. If they don''t then the DLL call somehow wrote beyond (or before) the buffer it is supposed to write too and that is then reported as error 1097 too. It may only affect the trampoline area and that would mean that nothing really bad happened, but if it overwrote the trampoline areas it may just as well have overwritten more and then crashes are going to be happening for sure, rather sooner than later. In most cases the reason for error 1097 is actually a buffer passed to the function that the function is supposed to write some information into. Unlike in normal LabVIEW code where the LabVIEW nodes will allocate whatever buffer is needed to return an array of values for instance, this is not how C calls usually work. Here the caller has to preallocate a buffer large enough for the function to return information in. One byte to little and the function will overwrite some memory it is not supposed to do. I'm not sure which OpenCV wrapper library you are using, but image acquisition interfaces are notorious to make such buffer allocation errors. Here you have relatively large buffers that need to be preallocated, and the size of that buffer depends on various things such as width, height, line padding, bit depth, color coding etc. and it is terribly easy to go wrong there and calculate a buffer size to allocate that will not match with what the C function tries to fill in because of a mismatch of one or more of these parameters. For instance if you create an IMAQ image and then retrieve its pointer to pass to the OpenCV library to copy data into, it will be very important to use the same image type and size as the OpenCV library does want to fill in, and to tell OpenCV about the IMAQ constraints such as the border size, line stride, etc. -
Open "Edit Events" dialog programmatically?
Rolf Kalbermatter replied to Jim Kring's topic in VI Scripting
Well if those dialogs still work like they used to in older LabVIEW versions, the panel itself is a real VI front panel from one of the resource files but the implementation for it is a dialog window procedure written in C(++), which is why it can not be launched from another VI diagram. -
Call Library Function Exception Error
Rolf Kalbermatter replied to viSci's topic in Calling External Code
You like mega pronto saurus clusters, don't you! -
Call Library Function Exception Error
Rolf Kalbermatter replied to viSci's topic in Calling External Code
Nope! Array to Cluster is limited to 256 elements in its Right click popup menu. Of course you could add 4 clusters of 256 bytes each directly after each other. -
Call Library Function Exception Error
Rolf Kalbermatter replied to viSci's topic in Calling External Code
Well every structure can be of course represented by a byte array. But you don't always have to go through those trouble. Fixed arrays inside a structure are in fact best implemented as an extra cluster in LabVIEW inside the main cluster with the number of elements indicated between the square brackets and of the type of the array. BUT: if the number of elements get huge this is not practical anymore as you end up with mega pronto saurus clusters in LabVIEW. Then you have two options: 1) flatten the entire cluster into a byte array and before the call insert into (for input values) and after the call retrieve the elements by indexing into that array at the right offset. Tedious? Yes you bet! And to make everything even more fun you also have to account for memory alignment of elements inside the cluster! 2) Create a wrapper DLL in C that translates between LabVIEW friendly parameters and the actual C structures. Yes it is some work, and requires you to know some C programming but in fact less low level knowledge about how a C compiler wants to put the data into memory than the first approach. -
Call Library Function Exception Error
Rolf Kalbermatter replied to viSci's topic in Calling External Code
Yes, Yair's idea won't work. The array inside the cluster is fixed size and therefore inlined. Putting a LabVIEW array in there is not only once wrong but even twice. First a LabVIEW array is not just a C array pointer but really a pointer to a pointer to a long pascal byte array, second there is not an array pointer but an inlined fixed size array in the structure. So the correct thing to pass is a byte array of 1024 + 12 bytes as you have already figured out. And more correctly it might be actually totalFrames * (12 + 1024) bytes. Also eventhough you may not plan to ever use this in 64-bit LabVIEW it still would be useful to configure the handle parameter as pointer sized integer instead (and use a 64 bit integer control on the front panel to pass that handle around in the LabVIEW diagrams). -
Quite a lot of things wrong indeed. In the first you use Variant to Flatten to flatten the binary string that you read from the file into a Flatten data. But a Binary string is already flattened, turning it into a variant and then flattening it again is not only unnecessary but is synonym to forcing a square peg into a round one in order to force it through a triangle hole. I'm not familiar with this implementation of the SQL Lite Library but the BLOB data seems to be a binary string already so I would assume that connecting the wire from the read file directly would be the best option. Personally I would have made the BLOB function only accept a Byte Array as that is more what a Blob normally is. In that case the String to Byte Array would be the right choice to use for converting the File Contents binary string into the Byte Array. The second attempt is not flattening the JPEG binary content but the LabVIEW proprietary Pixmap format. This is uncompressed and likely 32 bits in nature so a decent sized JPEG image gets suddenly 6 to 10 times as large in this format. You could write that as blob into the database but the only client who can do anything with that blob without reverse engineering the LabVIEW pixamp format (which is not really difficult since it is simply a cluster with various elements inside but still quite some work to redo in a different programming language) is a LabVIEW program that reads this data and turns it back into the LabVIEW Pixmap format and then uses it. In the third you take a LabVIEW waveform and flatten that. A LabVIEW waveform is also a LabVIEW proprietary binary data format. The pure data contents wouldn't be that difficult to extract from that stream but a LabVIEW waveform also can contain attributes and that makes the format pretty complicated if they are present (and to my knowledge NI doesn't really document this format on binary level). The first is a clear error, the other two might be ok if you never intend to use anything else than a LabVIEW written program to retrieve and interpret the data.
-
Depending on the LabVIEW realtime version used it may be necessary to add an extra configuration file to the system (this is for Linux based cRIOs but should be the same for myRIO): For FTDI based devices this usually seems to work out of the box, but your mileage may vary depending on the USB vendor and product IDs used by the manufacturer of the device. But the NI Linux realtime kernel has additional drivers to support other adapters too. The first check is to run lsmod from a command line on the controller (you know what SSH is, don't you) to see what module drivers are currently loaded. First run it before the adapter is plugged in after a full reset of the system and then after plugging in the adapter. There should be at least one new driver module loaded which has usbserial as parent. If this already fails the adapter is not recognized by the Linux USB subsystem. Once lsmod has shown a driver to be loaded make sure the adapter is plugged in and then look for /dev/ttyUSB devices by entering ls -l /dev/ttyUSB* on the command line. This should give a listing similar to: crw-rw-rw- 1 admin tty 188, 1 Oct 28 02:43 /dev/ttyUSB0 Important here is that at least the first two rw- are present and that the group (after the admin owner) is set to tty. If VISA recognizes the port but lists it as Not Present one of these settings is most likely wrong. To change the permissions with which a specific device is mounted by the kernel device discovery subsystem there are two different methods depending on which Linux kernel version is used. NI Linux Realtime 2013 This uses the old mdev system to add dynamic devices. Make sure to add following line to /etc/mdev.conf ttyUSB[0-9]* root:tty 666 Possibly the root entry should be replaced by whatever the login name of the administrative account is on that system (admin). NI Linux Realtime 2014 (and supposedly newer) This uses the newer udev system to add dynamic devices. Create a text file with the name ttyUSB.rules with following contents: KERNEL=="ttyUSB[0-9]*", GROUP="tty", MODE="666" Add this file into this directory: /etc/udev/rules.d
-
dll How to deal with clusters containing clusters?
Rolf Kalbermatter replied to Fred chen's topic in Calling External Code
That is not quite true. LabVIEW for Windows 32 bit does indeed packed data structs. That is because when LabVIEW for Windows 3.1 was released, there were people wanting to run LabVIEW on computers with 4MB of memory , and 8MB of memory was considered a real workstation. Memory padding could make the difference between letting an application run in the limited memory available or crash! When releasing LabVIEW for Windows 95/NT memory was slightly more abundant but for compatibility reasons the packing of data structures was retained. No such thing happened for LabVIEW for Windows 64 bit and all the other LabVIEW versions such as Mac OSX and Linux 64 bit. LabVIEW on these platforms uses the default padding for these platforms, which is usually 8 byte or the elements own datasize, whatever is smaller. The correct thing to use for byte packed data is The following will reset the packing to the default setting, either the compiler default or whatever was given to the compiler as parameter (respectively what the project settings contain). #pragma pack() It sure is and I think trying to create this structure in LabVIEW may seem easier but is in fact a big pitta. I personally would simply create a byte array with the right size (plus some safety padding at the end and then create a VI to parse the information from the byte array after the DLL call. And if there would be more in terms of complicated data parameters for this DLL even create a wrapper DLL that translates between the C datatypes and more LabVIEW friendly datatypes. -
These are the VIs that you normally get when installing the IMAQdx drivers. You do want to install the IMAQ Vision Module too, AFTER installing any new LabVIEW version. But yes there is a change that the Vision 2016 installer doesn't know about the LabVIEW 2017 location. If you have a previous version of LabVIEW installed alongside on the same machine, you can try to copy the IMAQ Vision directory from the previous LabVIEW version over to your LabVIEW 2017 directory after you installed Vision 2016. But you should probably talk to NI about updating the Vision 2016 to Vision 2017 too as that will make things easier (and there might be a license issue anyhow if you try to run the Vision 2016 VIs in LabVIEW 2017 without a properly updated NI Vision license).
-
Even if he had, he is factually still right. The differences are small in the last few years. That is to say that there haven't really been ground breaking new features in a new release in quite some time. Personally I'm quite fine with that as I rather have a stable development environment than a new UX compatible UI widget set that will be obsoleted by the next Google developer conference or Microsoft cheerleader party again . That said we still do not start new projects on a non-S1 version of LabVIEW. Everybody is allowed to install the latest version, but what version is used for a particular project is defined by the project leader at the beginning of the project and that is not going to be a non service pack version. Since development of projects is typically always a multiple people task nowadays there is also no room left for someone to just go with whatever version of LabVIEW he prefers. Version changes during a project principally don't happen, with a few very rare cases for longer running projects when a new version of LabVIEW or its drivers supports a specific functionality much better or fixes a fundamental bug. Not even for bugs that can be worked around will we go and upgrade to a new version during a project. The reason for this is obvious. A LabVIEW program as we write them is not just LabVIEW alone. It consists of all kinds of software components, NI and MS written, third party and in house developments. Any change of a component in this mix can have far reaching consequences that don't always have to be visible right away. For in house developed software we can quickly debug the issue and make a fix if necessary, so there the risk is contained, but for external software it is much harder. It often feels like a black hole when reporting bugs. It's almost impossible to even track down if and when a bug was fixed. This is both for NI and other external software similar, but considering the tight contact with NI it feels like being used. The whole bug reporting feels very like a one sided communication even if I follow threads on the fora. For problems reported there, if there is at all a reaction from some blue bird, it often is a rather standard reaction where the poster is thanked for reporting a problem and then a number of standard questions about version numbers and involved software, which sometimes has no relevance to the problem at hand and sometimes could even be inferred from the first post already if read properly. This sometimes goes on for a few more posts like this and then the thread dies, without any further final resolving post by any blue bird. It may have been solved offline but the reader on the forum doesn't see this. It looks like a back and forth of a more or less related or unrelated question and answer conversation and then it vaporizes like a tiny water stream in the desert. In addition I'm myself not a proponent of installing always the latest and greatest software version if not really necessary. And developing also tools and libraries for reuse it is again not an option to only develop them for the last version. So even if a bug gets fixed I might not profit from that immediately but due to the feeling of being so disconnected anyways it doesn't even feel like it is getting fixed ever.