Leaderboard




Popular Content
Showing content with the highest reputation on 08/20/2015 in all areas
-
I honestly don't know what you're talking about, I get that it is a joke but I don't get the joke. You can't easily just open an XNode. If there a template VI (like most of mine have) you can open that but actually opening the code generated requires some INI keys. Yeah that's part of the problem, the only "standard" on making an actor design at the moment is the NI Actor Framework. This standard is not catching on in the advanced developer community. I can speculate why but the point is, if standardization is key to adoption, then all of these different designs might be adding to the noise. Which is hard for me to say because lots of what i see in the DQMH, and JKI Objects I like a lot. And will likely be using one of them over the Actor Framework. The value of the DQMH videos, and scripting code should not be understated. Conceptualizing, and designing actor based software is confusing at first. Being able to say "Here watch this video for a few minutes, and you'll get the basics." is going to be a very valuable tool.1 point
-
Is that how your CLAD programmer learns about your Xnodes? But your right, it is a problem. Even though I could show someone what to do in minutes, it’s easy to have no idea what the first step to do is. Fabiola is fighting that problem by providing several instructional videos for her new Delacor framework. I’ve been trying to develop a way to make my actors easily switched between reentrant and non-reentrant, so I can leave single-instance actors as more “just open and seeâ€. It hard, because I don’t want to give up other simplifying features, like auto-shutdown of actors. As Fab points out, one can also provide a junior developer simplicity via a simple API or set of tools that encapsulates complexity. And personally, I think there is simplicity in standardization, since there is so much effort in learning code structure.1 point
-
Here's a Quick Drop plugin that loads all cases into a Tree, and the elements are draggable to reorder the cases - https://decibel.ni.com/content/docs/DOC-24058 It used to be a RCF plugin in the LAVA CR - https://lavag.org/files/file/90-caseselect/1 point
-
You know what, I need to look at this differently, and Shaun is helping with that. VIMs are getting people excited about an entry level way of doing type adaption, allowing for unrealized ways of making code. This technology has its limitations, and as users use VIMs they might realize the powerful potential of XNodes and how they can bridge the gap between what they can do with VIMs and what they want to do with them. It's a gateway drug VI. Or they may have a VIM that just does exactly what they want and don't need to change a thing...I wonder if I should try to make Variant Repositories with VIMs. Not all of the features would be supported but type adaption is the big selling point. Any function similar to Read/Write Anything could benefit from this for sure.1 point
-
Oh yes. does anyone know the frequencies and durations to play the A-Team theme tune with the Beep VI?1 point
-
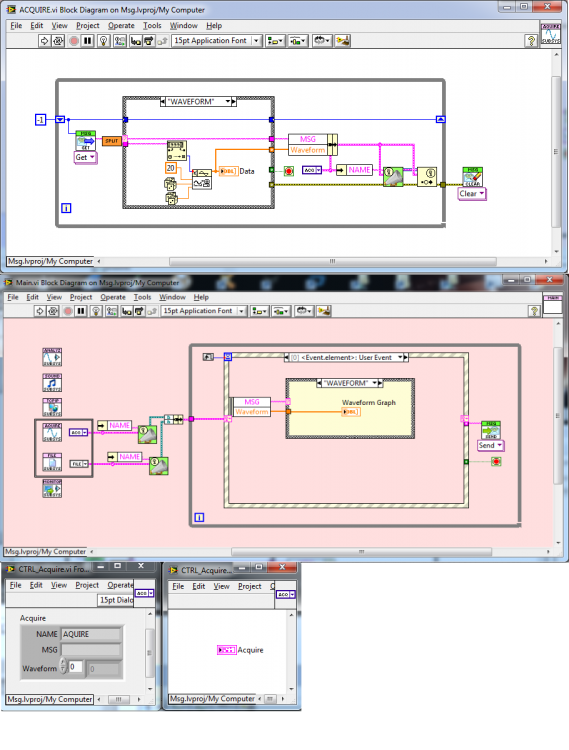
Yup. You've got it. I prefer to keep the generator separate because the register does some intelligent naming which could impact fast generation of events. It may be a personal preference, but I think I prefer less ambiguity between grabbing an event and generating one. I'd be shooting myself in the foot more often than not One thing that we can't get is the name from a connecting control the same way the queues and events do.An xnode would probably be able to get it but I settled on an old method of using a VI as a control and having a "name" field - a poor mans type-def.. It requires unbundling so it's not as concise but acceptably verbose, I think. I did think about putting it inside the Macro but didn't want to start making "special use" rules. This way its clear whats going on, IMO. Below is a demo use case showing one of the sybsystems (ACQUIRE) and one of its listeners (in Main UI). My architecture has queues in and events out so the Get and Send is a queue. That probably won't get replaced by a macro as it needs to be able to send a single command or an array of commands. For that, you need different diagrams and a polymorphic VI is more appropriate. So far. All the messaging, subsystems, user interfaces and project libraries are ~700 KB.
 1 point
1 point -
Played for a few hours with vim and event generation. I wanted to create universal vi for creating and adding UE. It seems that we can create one vi for registering and sending UE data, but registering more than one UE will require xnode I added one flag to decide when to register and when to generate. vim needs to be extracted because I couldn't attach it. event testing.vi event test.zip1 point
-
For reasons of which I am not 100% aware, the decision was made before I was brought on that direct data write access to the local database would be disallowed, and instead it would only allow stored procedures to be run that targets the local file. I think it's done because of a combination of reasons (encapsulation of the table structure, a security level flag we have to attach to each piece of data in the DB for reasons I won't go into, etc). I admit it would simplify things to have direct DB writing as the data storage. I am at this very moment only attempting to design a universal data storage method and not worrying about the sequencing aspect. We do have TestStand on some of our stations and are trying to roll it out to more of them, but I know that we'll never be able to switch 100% to TestStand for some of our processes, so when designing a universal solution it needs to be able to work both from a full LabVIEW application and from VIs called by TestStand as it runs. However I do see that instantiating a worker for each DUT (or one worker per class that handles an array of DUTs of that same class) addressable by serial number and sending it a message whenever a piece of data is available may be a better solution. I think I was fixated on converting the global clusters that the old versions of the applications use (where they constantly unpack a cluster from a global VI, read/modify it, then put it back in the same global VI) to a by-reference method that I didn't think that maybe sending messages to a data aggregator of sorts might be a better idea. I think I'll pursue that idea further and see what I come up with.1 point
-
I don't see how it helps. It's just another wire to trail around except it won't sequence execution like all the others do. If my subVI is truly asynchronous I can take that sub VI and put it anywhere. I can dynamically launch it. I can run it on a another computer. I just don't wire between loops - it's clutter that requires decoding. Its not to do with visualisation. It is encapsulation and breaking dependencies. I create self contained autonomous "nodes" that can be tested in isolation. Can be transplanted from project to project, Can be distributed as a single entity and can be worked on without the rest of the application. It just has the side effect that it really cleans up the diagram and makes it look much simpler than it really is. My mind is a dark and foreboding place I will describe how I see software and it may cast light on why I like LabVIEW over the others and how I currently use the VI hierarchy window and design software. Probably more than your asking for but it may help In a nutshell, I see dead people 3D systems. I don't see these systems as lines of code or flow diagrams or other abstract sensations at that level. I see them like in the hierarchy window but in 3D. More like Firefox 3D view but infinitely big. Where there are icons, I see real devices that I've used or know about. Where there are lines, I see TCPIP, Serial, broadband and satellite comms. I see mains cables, probes and sensors. I can also see the layers of that system like the layers in the Firefox 3D view, I can see cabinets full of devices and devices full of boards and boards full of software and a sometimes a rough BOM. You know when the girl in Jurassic Park turns security back on and locks the doors with the computer? That's a poor mans version of how I see systems in my head and I can envision them from scratch, from specs or discussions with a customer. At least one of those devices is usually a programmable device and that's where LabVIEW comes in. I can zoom around and in and out of that 3D hierarchy too. I can go to a particular device and inspect it. I can also switch views of that device. I can see it's UI menus and DIP switch settings. I can flip a brain-bit and view it as the wiring diagrams or as a high level schematic of subystems. I can see the exploded view of the accessories and attach them to the fascia to figure out wire routing. My thoughts are very visual and I can view it in many ways. This is also how I view the software. I see VI icons that represent the devices and the databases and all the things in the real world. I can move them around, change their menus and their dip switches-except they aren't menus or dip switches. They are configuration files and VI front panels. I flip my brain-bit to view the software wiring [vi diagram] and click on "Create SubVI" as I transition the subVI to a subsytem and the current VI to a high level schematic. Moving from the real world to LabVIEW is seamless to me. With other Languages I have to build those sub VIs and diagrams in my head and keep them there or reload them from a document/source file. LabVIEW lets me put them directly into code and leaves me free to think about the system not the memory location/pointers or other mechanics of the programming language. It gets the job done rather than being the job. So those new wires don't have a use for me. They are in the wrong "view". I always try to simplify, encapsulate and decouple the wiring diagrams in my code and part of that is reducing wire counts and breaking flow where appropriate.1 point
-
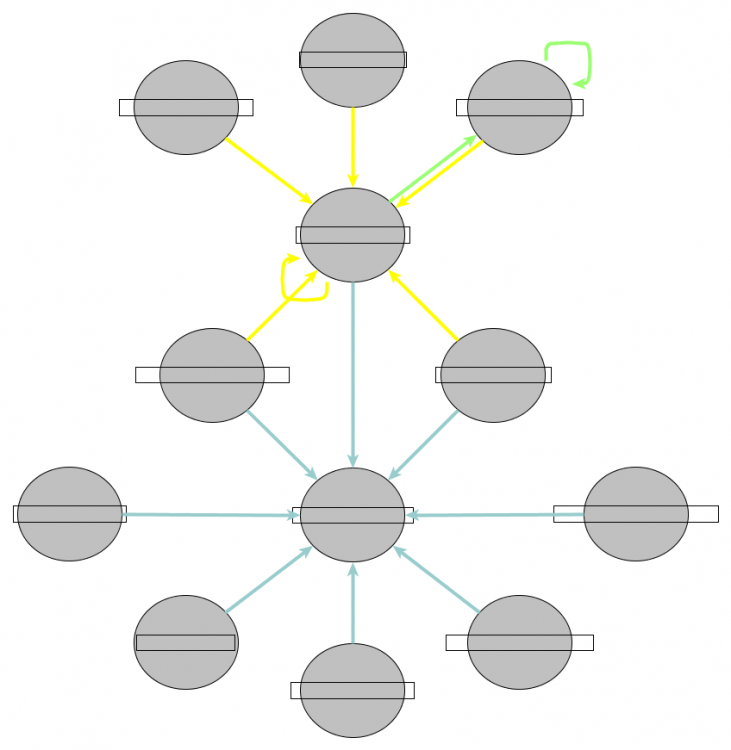
All of that code was just to dump out some sort of Queue Structure into a VI so we could see where the Queues are sending Information to / from in a Map Diagram. The Top level structure of test, test_A, test_B is just randomness (except I ensured there was only one De-Q per Queue). I am just trying to illustrate that part of what a "Channel Wire" is trying to accomplish is indicate to the developer where asynchronous data is accessed / flowing (I am not good with terminologies). A different way of relaying this information is in a hierarchy / map file / class hierarchy diagram, which in my opinion is easier to read. Here is the same rough VI I posted but run on an actual project which includes VIs which are dynamically called (and therefore may not be represented by a "Channel Wire" ??). I have anonymised the vi Names hence the blank boxes.
1 point