Leaderboard




Popular Content
Showing content with the highest reputation on 10/08/2011 in all areas
-
Occurrences work a bit more complicated. I have to admit that my memory is a little foggy about the exact details of this, as it has been several years that I struggled with this for a rather complicated infrastructure, involving use of occurrences also in external C code. But from what I remember, once an occurrence has triggered it is in the set state (to use a more common concept of ResetableEvent as analogy). When a WoO executes for the first time it looks at the state and when ignore previous is true it will USUALLY wait even when the occurence is currently in the triggered state. When it is false it will just continue when the occurrence is in the triggered state. In any case when WoO returns without timeout it will reset the state of the occurrence for this instance of WoO only. Next time around this WoO will use its local state to detect previous triggers when ignore previous is false. Other WoO instances will not influence the behaviour of this WoO in respect to detecting previous triggers. But a specific WoO can only wait once on a trigger eventhough you may have ignore previous set to false. What I encountered sometimes was that the occurrence could get triggered the first round around even when ignore previous was true AND the trigger event had clearly occurred before the wait executed. My solution was to use the occurence as an indication that something might have happened and when WoO returned without timeout to actually check for the data to have arrived and if it didn't so far treat it as timeout anyhow, usually looping once more for an event. This was back in LabVIEW 6 or 7 days and I have since always used occurrence in a way that was tolerant to this behavior. At first I considered it a bug of the occurrence but some discussions let me believe that it was an artifact of concurrent programming that can't be completely avoided and use of this should always be prepared for this possibility. NI might have changed something in the occurrence handling since and it may not behave exactly that way anymore, but I wouldn't really notice as my implementation is tolerant to the old behavior but of course won't break on an improved behavior of the occurrence. As to a case where occurrences have an advantage over the other asynchronous objects in LabVIEW: If you want to be able to trigger an event from external C code the only native LabVIEW objects that are to my knownledge available for this are Occurrences since LabVIEW 3 or 4 and User Events since LabVIEW 7.1. None of this is well documented but there are for both semi offical NI examples floating around. Wait on Occurrence had that as long as I can remember. (But my long term memory is sometimes a bit fuzzy so it may not have been there in LabVIEW 3. It's definitely there as far back as LabVIEW 5.1, I just checked. ) Using (undocumented) LabVIEW manager calls, one can create dynamic occurrence refnums. I have done so in the past for a data logging application, giving every single channel tag its own occurrence so clients could wait on value changes easily. Worked like a charm even for several 100 channels. All the LabVIEW refnums created (except those created by the LabVIEW manager calls directly unless you use some other manager calls to register those refnums for automatic cleanup) are suspectible to automatic cleanup on termination of the hierarchy that created them. So they do get cleaned up eventually. Static refnums vs. dynamic refnums has always pros and cons on both sides. Try to execute Create Occurrence in a loop to create several occurrences for a varying number of objects. It won't work as expected. So while dynamic refnums do require extra care from a programmer to properly cleanup after use, they also offer much more flexibility. For the same reasons you could vote that string constants should be static to avoid a LabVIEW user creating memory hogs by wiring it to an autoindexing loop boundary of an infinite loop. But that would possibly render LabVIEW even turing incomplete as you could not deal with a lot of common situations anymore. Yes notifiers and occurrences are similar but a notifier can have a data item attached to it, while an occurrence only carries the notification event itself.2 points
-
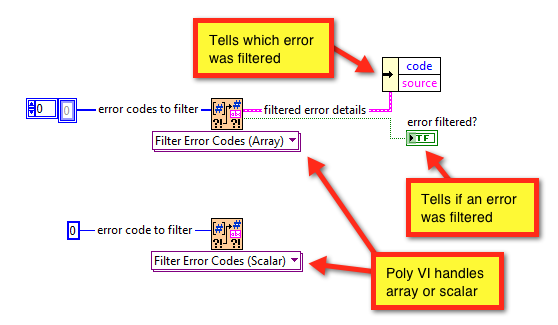
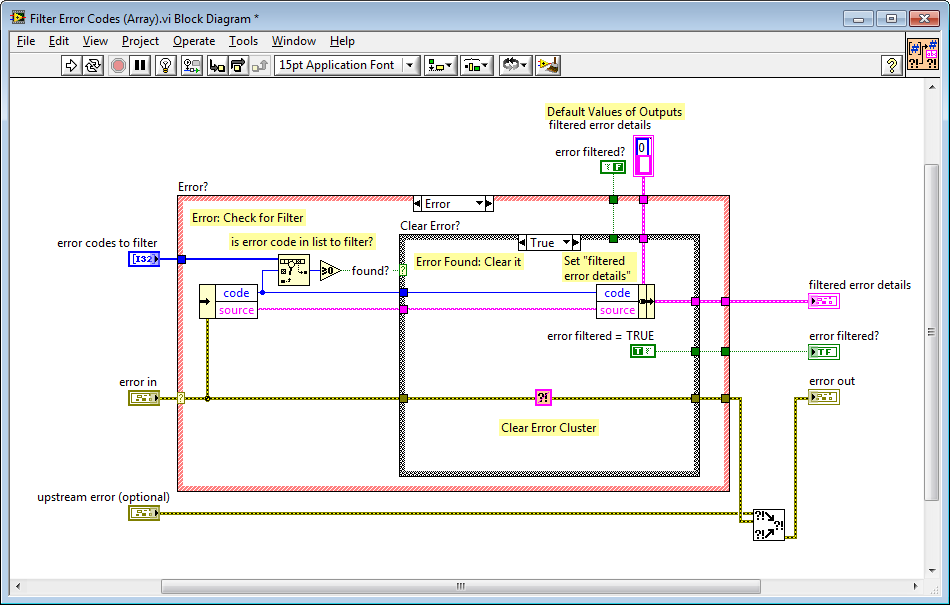
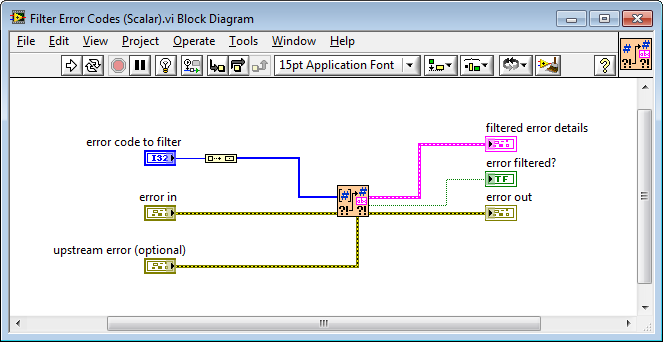
Hi All, This is a great discussion! In an effort to support this, JKI has decided to donate (to the community via BSD license) a couple relevant VIs into the mix, in the hope that they might contribute some design inspiration to this discussion: JKI - Clear All Errors and Filter Error Codes.zip The first VI is called Filter Error Codes and filters either a scalar or array of integer error codes. It also returns the information about the error that was filtered, which is useful for handling that error. This is what the array implementation looks like: And, here's what the scalar implementation looks like -- you can see it just calls the array implementation. The second VI is called Clear All Errors, which is just like NI's Clear Errors, but a lot more compact, which is nice Cheers!
 2 points
2 points -
That's right. It's a real space saver to not have to merge errors as a separate function call. And, this is a standard that I hope can be adopted, if others agree that it makes sense. Note: I think we should add this "upstream error" to the "Clear All Errors" function, too.1 point
-
It e.g. allows you to check for an error from a specific task, handle it (e.g. clear it) whilst persisting error information from previous code (upstream). Normally I would merge this external to the VI, but I like the fact that the merge is included in the VI (one less thing to do).1 point
-
This package will be available for download through VIPM in a few days and adds the error constant to the palette for use on the BD. [FIX] 3410309 - Add Error Constant to Palette Kind regards Jonathon Green OpenG Manager
1 point
-
This package will be available for download through VIPM in a few days and incorporates a new MD5 Hash? VI and changes to existing MD5 Message Digest. [FIX] 3410441 - Add 'MD5 Hash' candidate to package [FIX] 3410442 - Add Hexadecimal String output to MD5 Digest These are the new/updated VIs: Kind regards Jonathon Green OpenG Manager
1 point
-
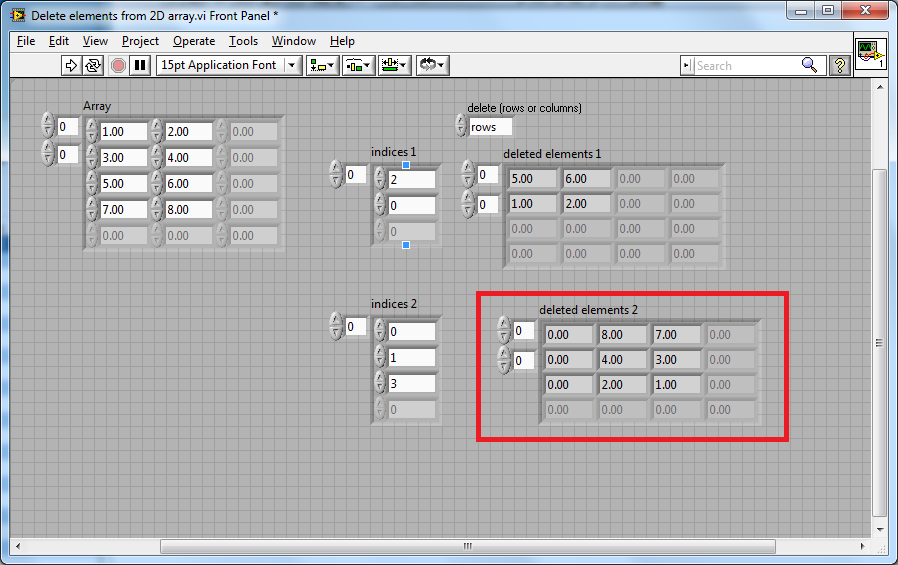
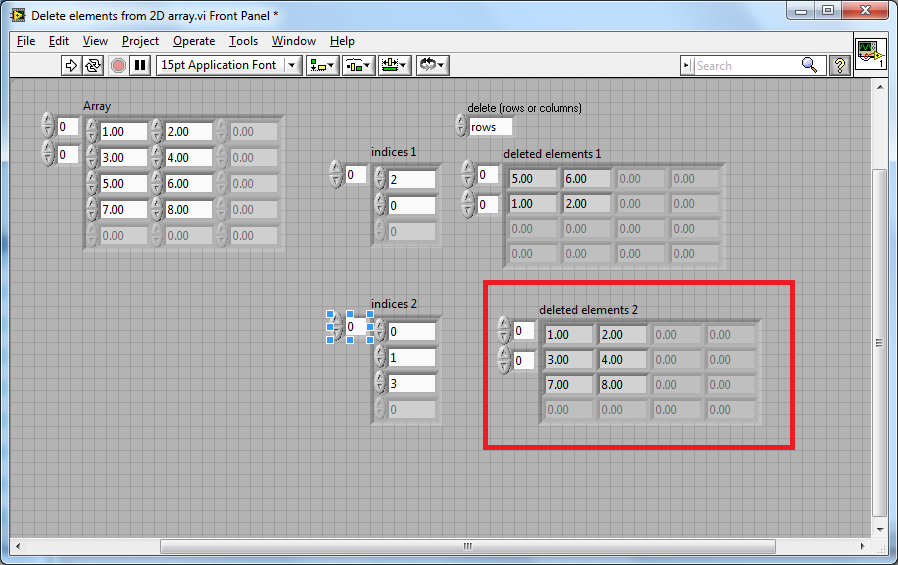
This package will be available for download through VIPM in a few days and covers a bug fix. [FIX] 3390029 - 'Delete elements from 2D array.vi' outputs incorrect result This is the output from buggy code: This is the output from the fixed code: Kind regards Jonathon Green OpenG Manager
1 point
-
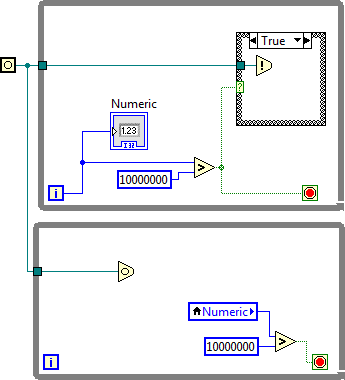
Because the local variable will be evaluated well before the first loop reaches the large number and will present a FALSE to the stop terminal. Everything (in the second loop) then waits for the occurance. Once Loop 1 actually fires; loop 2 then proceeds with the FALSE, goes around again and then waits, once more, on the occurance-which never arrives since the first loop has already terminated. This is why no-one uses them. Its too easy to get race conditions that hang your app because they don't have a time-out. It will work correctly IF you put the occurance and the local into a sequence structure that guarantees the local is read AFTER the occurance (another reason no-one uses them since they don't have error terminals and forces you to use those pesky sequence structures.)1 point
-
Awesome - thanks! Quick design question - why pass out and maintain a new data-type (which is a subset of Error cluster) when an Error cluster could just be passed out? Cheers! -JG1 point
-
1 point
-
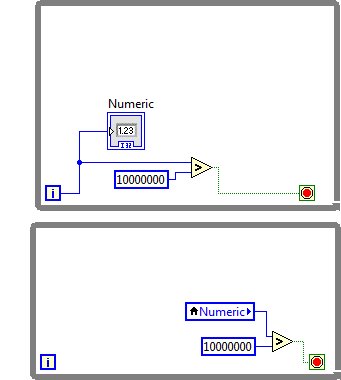
I had a conversation with our chief architect whose been working on LV since version 0.1 and who created the occurrences long long ago. Here is THE correct way to use occurrences: First build a system which polls busily for whatever it is the occurrence will signal. You need to be able to determine the state of things without an occurrence. This creates a correct, but inefficient busy waiting implementation. Once that works, add an occurrence to alleviate the inefficient waiting. Do not remove the actual polling. In other words, use the occurrence only to indicate that "it is probably a good time to check on that thing...". [Later Edit] I added a much better example of the usage of occurrences a few days later in this thread. Read it here. In other words, start with this: and then go to this: As I understand it, occurrences don't have thread safety on their state because they are the building blocks by which thread safety for state in higher level APIs is built.
1 point
-
Occurrences are the underlaying functionality of all LabVIEW asynchronous operations. However they have a few limitations in itself. 1) They don't allow for any data to be associated to them 2) They have somewhat confusing semantics 3) You can get a triggered occurrence from set occurrence invocations that happened before the wait occurrence was called even when ignore previous is true. This can be worked around easily by checking for the actual event in some other ways and reentering a wait if the event wasn't really true, but one needs to be aware of it.1 point
-
Yes I do happen to know about LuaVIEW and its future. We haven't yet defined an exact timeframe of when and what things will happen, but expect LuaVIEW to be maintained and even improved in the future. A few things in the pipeline though no promises they will all be released: - Fix some minor errors in newer LabVIEW versions with the unit tests - Make the LuaVIEW core a shared library instead of a CIN - Provide direct VISA and .Net interfaces in LuaVIEW from a script - Make it's distribution VIPM compatible - Get it Lua 5.1 compatible - Add additional targets (x86 Mac, x64 Mac, x64 Windows, possibly cRIO VxWorks)1 point
-
Here is my favorite mathmatical identity: I now have a second favorite: What has been seen can't be unseen...1 point
-
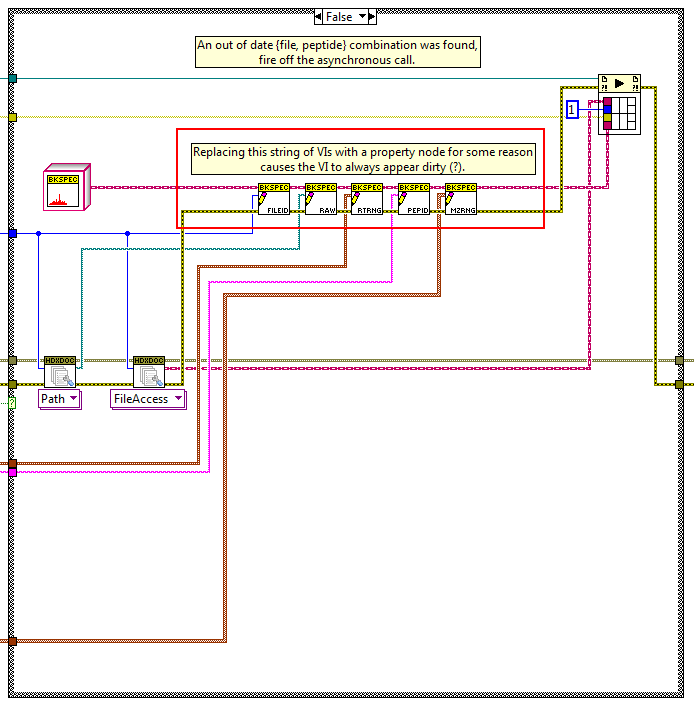
Well this is fun. The relevant section of code: The above code works and doesn't cause the VI to be dirty when loaded. The original code had a property node in place of the string of five accessor methods I highlighted in red. Even now, if I delete the accessor VIs and drop a property node instead, I'll get the dirty dot problem. Even though the two pieces of code should be equivalent according to everything NI has said with respect to classes and property nodes. Thank you very much for all the clues. The bit about in-placeness clued me in to looking at the subVIs more closely, and eventually I homed in to the property node using some creative sleuthing with the diagram disabled structure. Fun fact: even having the property node on the diagram in a disabled case causes the dirty dot to appear when the VI is loaded. Weird.
1 point
-
I saw a strange case of dirty dots that I attributed to the inplaceness algorithm. I posted an example here. The gist of the problem had to do with changing the error wire in a subvi from error-in to error out to passing the data through a native function that MIGHT modify the error. The subVI must contain info that allows the inplaceness algorithm to short-circuit the wire. When I changed the low-level vi, all calling VIs indicate they need a save. Don't know if this is what you are seeing, but it made me crazy for some time. Inplaceness is synonymous with insidiousness ...1 point
-
Some causes of "dirty dots" of which I know (as of LabVIEW 2010): 1) Calling "system VIs": http://digital.ni.com/public.nsf/allkb/D4032A485C9F18C1862576D6007681F4 2) Opening a copied RT VI (i.e., in a new location on disk) with an FPGA VI reference (nondynamic). 3) A dirty dot appears in the project if you open a library (e.g., class library) where the contents are set to (Custom?) arrangement. Changing to Arrange by Name fixes this. 4) Changing a strict typedef in the private data of a class in one project may keep making you save a different project that uses the class. I usually make a trivial change (e.g., arrange horizontal then vertical again) to force a recompile. Then we're OK. 5) As Ben already mentioned, using autopopulating folders causes this a lot. We only use virtual folders anyway. I'm not sure any of these apply in your situation.1 point
-
Well references and error wires could default to shift register terminals when wired into the loop? Much like arrays default to auto-indexing. This would also be useful for counteracting the auto-indexing of references and errors when exiting the loop.1 point