ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
Standard Indexes on individual columns isn't very useful. In its simplest form you can consider an index to be an alias to a group so creating an index for each column is a little pointless. An index on XY and/or XZ makes more sense. Creating a partial index on single columns is very useful, though, since you are pre-mapping the alias to a subset of the rows of the table. Making an index on Z=0 would probably be useful in your case. Can you explain that? I thought "WITHOUT ROWID" was purely an optimisation.
-
Run Explain. (SQLite_Explain Example.vi) on both queries. It will "explain" how it processes the query and what optimisations are performed (like if an index is used or not) and you can see what the differences are.
-
Is this SQLite only? Or a more general SQL question since performance varies markedly from platform to platform and some responses may not be valid for MSSQL, for example. Group by is probably the wrong approach for decimation. You'd have to execute the Explain query to find out what the internal lookups are. I expect you are forcing one or more full table scans. In the Data Logging Example I use the following expression to return decimated data. Decimating 1M datapoints is a few hundred ms on an SSD but I don't know what that file size is, off-hand. The "rowid" decimation is quite obvious and means that SQLite can skip entire sections without querying and testing the data. WHERE (x between ? AND ?) AND (rowid % 500 == 0) What does this approach yield with your dataset? If X,Y,Z are coordinates, I would highly recommend using the R-TRee features of SQLite if you haven't tried it already. If your SQL queries are to find intersections and/or contained/overlapped polygons then the R-Tree module is far more performant that straight SQL.
-
Don;t wire anything to the "options" terminal of the open primitive. You don't really want a shared pool, you want pool of 3 individual instances (pre-allocated).
-
Doh! It wasn't a call by asynch node that was used. Opticians appointment confirmed.
-
I think it is one pool because of the strict type ref. Called in any order because of the Asych call and as if parallel iterations was enabled of the for loop.. For those who haven't seen this before. It is a demonstration of this behaviour. Foot Shooting factor 9000! What do we get if we win? Can I go home early?
-
Any 3 values between 1 and 9 in any order.?
-
I think SQLite is shipped with the Linux RT. There is a how-to-update thread over on the dark-side at any rate.
-

Programming for Separator Character in File Paths between platforms
ShaunR replied to dhakkan's topic in Apple Macintosh
The VI "UNIXPathStringToPath" is an unused placeholder on windows. It is replaced with a platform specific implementation when loaded on Mac.- 5 replies
-
- 1
-

-
- separator character
- mac os
- (and 2 more)
-
"Select VI Server Class" on Refnum Control programatically
ShaunR replied to PiDi's topic in VI Scripting
I see no problems. Only a solution to the question asked and the beginning of other solutions -
"Select VI Server Class" on Refnum Control programatically
ShaunR replied to PiDi's topic in VI Scripting
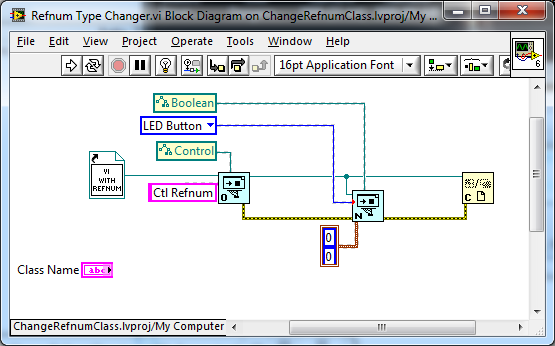
Control Refnums don't really work like that. It is a container that assumes the type of the contents a bit like ,NET and ActiveX containers rather than LabVIEW objects, per se. So you have to do something like this. You will notice that by inserting the control into the reference; the reference now assumes the [type] name of the control. ChangeRefnumClass Folder.zip
-
Programming for Separator Character in File Paths between platforms
ShaunR replied to dhakkan's topic in Apple Macintosh
There are two VIs in "vi.lib\Advanced String\" Path To Command Line String.vi Command Line String To Path.vi These take in to account the platform separator when converting to and from strings and paths. Use those instead of the palette primitives. -
ms timing accuracy over WiFi Tablets using IEEE1588
ShaunR replied to Chris's topic in LabVIEW General
Yes. I tried posting a link to the wikipedia page but the editor kept truncating the address. hopefully this works for you. You are after the TCP_NODELAY option of SocketImpl (set to true) -
ms timing accuracy over WiFi Tablets using IEEE1588
ShaunR replied to Chris's topic in LabVIEW General
Just turning Nagle off would be good enough for a quiz buzzer, wouldn't it? -
I don't see any issues with the algo at first glance. You did say it used bit reverse (the two other functions) and I don't see you doing that, however.
-
Is this really a box you want to open? You can't inherit from multiple parents and the Character Lineator is designed for this.
-
The easiest way by far is to use the [un]Flatten to XML primitives, which can take objects and variants as arguments, and convert the XML to/from JSON. with simple regex/search/replace. Why they didn't make the native JSON ones like the XML is beyond me
-
If you can't give me some numbers I can put straight into LabVIEW, I'm not going to even try. You also haven't told us what the polynomial is so we don't know which flavour of CRC it actually is. Google should have told you that the code is 3/5ths of "this one" Once you know which flavour just put LabVIEW in front of your search term (e.g. LabVIEW CRC16 xmodem) and you will find plenty of pre-written VIs like "The Inline CRC Reference Library",
-
Is there a CAR or some document detailing the findings?
-
VISTA - Professional Software Engineering Tools for LabVIEW
ShaunR replied to crelf's topic in User Interface
My oldest software that hasn't become "vapourware" seems to be the "windows_api_1.0.llb".It was written in LabVIEW 5 in the late 1990s but think I had it internally for a couple of years before I released it. It is posted in the CR after someone asked for it and is identical to the original except it was recompiled for 2009 and later so people could actually use it. Here is the original in LabVIEW 5. I can't actually open it any more but I'm pretty sure it is identical to the CR one. windows_api_1.0.llb -
VISTA - Professional Software Engineering Tools for LabVIEW
ShaunR replied to crelf's topic in User Interface
I doubt if you are willing to elaborate on that. I expect it was an obtuse, back-handed, compliment. Programmers that advocate "Ad-hoc reuse" are cut from the same cloth as those that say they are green minded, concerned for the environment and recycle just because they reuse their shopping bags as bin(trash) liners. -
It's starting to sound very much like you have a race condition or two somewhere. Extra messages could be due to retries but could also be due to reading the same value twice (especially happens with notifiers). So you are losing messages sometimes and gaining messages sometimes. All seemingly randomly tied to arbitrary and unconnected system conditions. That is a code smell I am very familiar with.
-
VISTA - Professional Software Engineering Tools for LabVIEW
ShaunR replied to crelf's topic in User Interface
"Data mining" just isn't a phrase I use for programming at all. I don't see software as data - more a tool for manipulating data. I wouldn't say I "data mine" a laptop to recover components and I see software the same. So whilst I could write software to "data mine" I would never think to use it as a phrase for code reuse. No and no and no and no. Not only are you hell bent on the tortured use of "reuse" but now you want to torture "reference" as well. Just stop it "Ad-hoc reuse" is a phrase made up by script kiddies because they can't write proper code at all and have to steal others'. It isn't a thing.. -
VISTA - Professional Software Engineering Tools for LabVIEW
ShaunR replied to crelf's topic in User Interface
Well. don't keep us in suspense. Where's the rest of it? Components, yes but........ I know that was probably a throw away statement but it's something that annoys me and I see/hear newbies and oldies parroting without thinking. If you meant by "data mining" the process of taking an unmodified chunk of an old project and use it "by reference", i,e, place the VIs on diagrams or link via code interface nodes then yes, it is reuse [of an informal library]. You just haven't reused it enough to make it formal. However. Copying and pasting or copying and modifying (forking) of an old project/code isn't reuse - it's replication. It is just a tortured interpretation of the English word to make an anti-pattern sound like a good thing when making a reuse library is too much effort or its reuse would be too limited. "Your Honour! I just copied the dollar bill onto another piece of paper. I was simply reusing it " I now use the term "reuse-by-reference" to explicitly exclude these abominations from the definition. If you are "data mining" by copying code then it is an opportunity to define a reuse-by-reference subsystem/library but is not, in and of itself, reuse. -
Rolf's given you the technical reasons and history. So ignoring cross-platform (big one for me, especially as I'm now moving away from Windows) , performance and falling to pieces when IT push out a security updates. Here are some real world, LabVIEW specific examples. Thread Starvation Obsolecence. Deadlocks.(see note at bottom) Like Rolf says. When they work-fine. When they don't; they are self contained bundles of nightmares that you can only remove (if you can get into the IDE ). I just prefer not to put them in in the first place.