
Mads
-
Posts
471 -
Joined
-
Last visited
-
Days Won
33
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Mads
-
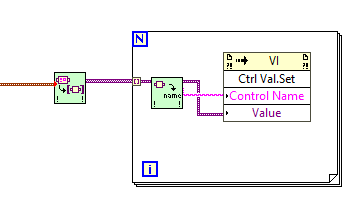
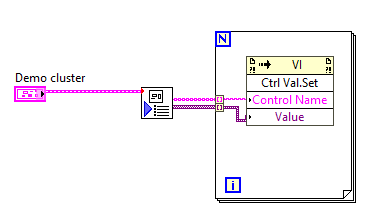
 I ended up getting too frustrated (again) with the stupidity of having clusters in the GUI involved in key navigation and locked to one terminal . so all controls are individual/primitives in the GUI again. Then the challenge however is that initializing all those individual controls is an inflexible and space-eating affair when done in the traditional graphical way (unbundling extra large clusters). So: How to programmatically fetch all values from a huge cluster and initialize all equivalent individual controls in the GUI? Well, one way I had been using before was to use a Ctrl Val.Set property. That works fine as long as the names of the individual controls in the cluster(s) are unique and match the labels of the controls in the GUI....but you then have to "flatten" the cluster to a list of names and variants. If the cluster(s) do not contain subclusters I use this OpenG-based method: But in this case the cluster is complex - and there are sub-clusters within subclusters, something this code does not handle. The OpenG configuration VIs handle this in "Write INI cluster", but not in a way directly translatable to a list of names and variants as the recursive algorithm to access sub clusters does not translate into this use case.... So I wrote the attached VIs to flatten any complex cluster into its individual element names and variants: The initialization code could alternatively be put into the VI itself instead, and perhaps a blacklist/only init these input could be added, but for now this does the job: It keeps the initialization code very compact and flexible - even though the cluster(s) in question is complex and might change later (sorry, did not rewrite it to JSON instead...not yet at least @drjdpowell😳) Is anyone else doing something similar, perhaps better? Demo of cluster to init of individual controls.zip
I ended up getting too frustrated (again) with the stupidity of having clusters in the GUI involved in key navigation and locked to one terminal . so all controls are individual/primitives in the GUI again. Then the challenge however is that initializing all those individual controls is an inflexible and space-eating affair when done in the traditional graphical way (unbundling extra large clusters). So: How to programmatically fetch all values from a huge cluster and initialize all equivalent individual controls in the GUI? Well, one way I had been using before was to use a Ctrl Val.Set property. That works fine as long as the names of the individual controls in the cluster(s) are unique and match the labels of the controls in the GUI....but you then have to "flatten" the cluster to a list of names and variants. If the cluster(s) do not contain subclusters I use this OpenG-based method: But in this case the cluster is complex - and there are sub-clusters within subclusters, something this code does not handle. The OpenG configuration VIs handle this in "Write INI cluster", but not in a way directly translatable to a list of names and variants as the recursive algorithm to access sub clusters does not translate into this use case.... So I wrote the attached VIs to flatten any complex cluster into its individual element names and variants: The initialization code could alternatively be put into the VI itself instead, and perhaps a blacklist/only init these input could be added, but for now this does the job: It keeps the initialization code very compact and flexible - even though the cluster(s) in question is complex and might change later (sorry, did not rewrite it to JSON instead...not yet at least @drjdpowell😳) Is anyone else doing something similar, perhaps better? Demo of cluster to init of individual controls.zip
-
I wouldn't want this. User management is difficult to develop, maintain, and keep secure. It would be unwise for NI to roll their own manager; they should integrate existing, tried-and-true technologies. Currently, non-Enterprise SystemLink does use LDAP and Windows Active Directory for user management, which is good. I haven't looked closely at what new technologies are available under Enterprise (Jordan mentioned OAuth?) We do not want to roll our own, so we want SystemLink to handle it. And if NI does not want to roll their own - they can always use subcomponents that does, but to us as a user of SystemLink it would/should appear to be handled by SystemLink😉. In our case the bulk of the users would be external clients and we would not want to handle their dashboard accounts in Active Directory...typically the user management would be handled by support engineers that would not have admin-access to AD. I see some of these issues mentioned in the latest release note though. Perhaps it is time to have a closer look again.
-
The presentation seems to show that we need to implement custom user account handling...(helpful in that regard, although just browsing quickly through the video it does not seem to be a particularly secure method - sending user names and passwords(perhaps I overlooked an underlying encryption?). What we were hoping for, as far as I remember now, was that that the user account administration and logon was handled securely by SystemLink itself, and that the selection of dashboards and/or what data those had access to would then depend on the user account (then only the last part might require the G-code to know anything about the user).
-
Regarding Systemlink for Enterprises; when SystemLink came out we wanted to use the WebVI-option to provide external users/groups dashboards offering data only that user had access to. So we needed programmatic access to the user information to then only present the dashboards/data that that user should be able to see, but that was not readily available. Managing such a setup was not practical then (we wanted to just be able to create user accounts, add them to a user group and then that user would automatically (no further programming etc needed) get access to the right data only). Has there been any movement in such a direction (Enterprise?), or would you still need to have separate system link servers to ensure restricted access / user specific content?
-
No complaints, you are doing a fantastic job 😀👍 I edited my examples to include two versions based on JSONtext (attached). PS. I have not tried to scale up the cluster array to see what the differences would be performance-wise yet, they all have their pros and cons usability-wise though. Distributing cluster changes, now with 4 solutions.zip
-
Aah, thanks, that works.😃 I made a demo of the issue, but you replied just when I was about to post it. The reason I though the $.[0] notation should work was that if I tested it with https://jsonpath.com/ it (almost) seems to find what I wanted... Attached is the demo/test I made...but now with the correct notation for arrays as well. Exploring having Cluster array as JSON.vi
-
The GUI presents a list of devices by tag in a list box or tree where the user can choose to select one or multiple devices (only of the the same type). If they choose multiple that is one way for me /the code to know whether they want to have changes replicated. If they have selected multiple serial links e.g. the GUI will only show the setup of one link, but changes will be applied to all. There is also a tick box that allows them to put the GUI into "global mode", which is just a shortcut to always apply all changes to all devices of the same type (no need then to select them manually in the listbox/tree). As you say there is one issue with this, and that is if they want to apply a value that is already set for the device chosen by the GUI as the "template". They then have to re-enter the value just to trigger the distribution of it to the other device configurations. This I find OK though - it is part of the "contract"; when you select global mode or multiple devices the user accepts that this will apply *changes* to all - and that is that. With that contract in their head the function makes sense / is intuitive enough. You could add additional GUI elements like an apply all button to sub-sections of the configuration, it depends on how many elements you have in the setup and how often the user would want to replicate them. In my case there are many inputs, but only some of them make sense to replicate; but those often need to be replicated to *many* devices, so the user saves a lot of time having this feature (makes users very happy to have it, so no complaints about such shortcomings... 🙂 ). I do not indicate to the user which values he has changed, that I expect the user to keep track of himself...(he knows what he just did, if he has forgotten already he can always cancel the changes though) but as @hooovahhmentions you could do that... One thing I have not mentioned is that the replication/apply to many/all functionality is kept from touching things that should be unique anyway... Guarding from such changes can be put at different levels, in my case they it is handled by having dedicated event cases for those controls, but in a more generic solution you might want to have a blacklist instead, or include a key in the control name that enabled/disables the replication...
-
I have not used JSON/JSONtext much, but this sounds like a good plan. If you can bare with me, could you elaborate a bit on how this can be implemented (or point me to an example/documentation that would help)? To use the solution examples I posted as a starting point: Would I replace the array of clusters with a JSON object? In JSONtext, how do I go about replacing the value of multiple items then? If I start with this (instead of the LabVIEW cluster array from the examples): [ {"Enabled":true,"Hello":-2,"Hi":6}, {"Enabled":true,"Hello":-2,"Hi":6}, {"Enabled":true,"Hello":-2,"Hi":6}, {"Enabled":true,"Hello":-2,"Hi":6} ] and try using Set item with the path $.[*].Enabled e.g. when that value changes, it returns an error. Accessing just one of the indexes ($.[0].Enabled e.g.) fails as well. What would be the correct way? Naming each element to be able to use set multiple items with an item names input? (I did successfully rewrite the demo to work with JSON using JSONtext, but then I just treated each array element as a separate JSON string and ran Set item on each of them with the path $.<Label.text>😳) PS. I guess you would also use your SQLite library to store the configuration of each device in a table with the config clusters as JSON strings then...or?🙂
-
Basic problem: If an element of a given cluster is changed - that value, and that value change alone, should be applied to several other clusters (which will otherwise retain their other element values). Known solutions: In the attached file (LabVIEW 2020 code) I have two ways of doing this: 1) using dynamic events and Set Cluster Elements by Name (OpenG), or 2) by using the Cluster To Array of VData.vi (also from OpenG). (Note: The use of array locals in the examples are there just to simplify the demo). Question: Are there other / better ways of doing it? A bit more background: In configuration windows I sometimes allow users various ways to choose to apply any *changes* globally or to a selection of targets. If e.g. they want to change the baud rate of 3 out of 5 different serial links they can choose the 3 links, and if they change anything in the communication setup of the first of them it will be applied to all 3 links (the rest of their setup will remain as before (they might still have different parity settings e.g.). I usually avoid clusters in the GUI so each change is handled individually, either in a dedicated value change event case (lots of coding needed...), or in a common case that uses the control reference to touch the correct element of the other target's configuration...(less code needed). However, in cases where the number of controls is very high, it can be nice to just have them in a cluster in the GUI as well - and to not have to write event cases to handle the change of each and every cluster element... Distributing cluster changes.zip
-
Have you installed sudo and added the lvuser to the sudoders list? If you are calling a script make sure lvuser has access to the file (ownership defaults to admin if you have transferred it onto the device logged on as admin). The LabVIEW RT Linux site has some threads with pointers for this, like these: https://forums.ni.com/t5/LabVIEW/Mount-NSF-share-to-NI-Linux/td-p/3822135 https://forums.ni.com/t5/NI-Linux-Real-Time-Discussions/Is-it-possible-to-close-and-re-open-RTEXE-through-Embedded-UI/td-p/3707540
-
We should have a native solution to this. I added it as an idea on the idea exchange...
-
Separating "installer" development from code development
Mads replied to infinitenothing's topic in Source Code Control
Finding problems is an integral part of coding; you code, test, code, test etc. If you are not testing continuously and spending much more time on that than actual coding you are bound to run into serious trouble late in the project. Code reviews? Ten people can look at the same code and think it is fine. Testing, and most importantly - testing while coding is more effective. When you think you have something completed - someone else tests it, sure. You have probably overlooked things. Again the ones that test it do it best alone (they should not be guided by you, that will reduce the likelihood of them finding errors and non-intuitive designs), and when they find something they review the code and discuss the issue with you etc. I am talking more of the creative side of coding (including the feedback from the aforementioned testing). Two heads or more should always be involved at some stage, but it should not replace the focus only a single mind can achieve. The holes I am talking about are holes in the plan that become visible when you start to poke at it / actually execute the plan. There are no waterfall projects , you learn while doing and adjust. As for item 8 the use of remote work *is* in line with having quiet offices. For people that do not have that at home though, remote work is not a good option and we return to item 8 😉 -
Faster Spline interpolation - c++ dll implementation?
Mads replied to Bruniii's topic in Calling External Code
Ok, so you need the processing to return the results faster for other reasons than the sampling itself. Just as a comparison I set up a test on my computer (I used the NI_Gmath:Interpolate 1D.vi, with spline as the chosen method) and as on your computer it took 400 ms to run through an array of 10000*100. Adjusting the parallelism of the loop running the interpolation VI it dropped to 220 ms with 2 loops. With 16 loops it got down to 74 ms (I ran it on an i7-9700 with 8 cores). -
Faster Spline interpolation - c++ dll implementation?
Mads replied to Bruniii's topic in Calling External Code
No, I am asking why you need the spline to run between the measurements, instead of just handling that part off to a parallel or post-processing code. If the result of the spline is not needed for the next measurement the two things might not need to be handled sequentially. If that is the case the time spent on the interpolation would not be an issue...(it might represent a memory issue instead then, but that is less likely and easier to deal with). -
Faster Spline interpolation - c++ dll implementation?
Mads replied to Bruniii's topic in Calling External Code
Is the output of the previous interpolation used in the setup of the next measurement, or could you process the incoming readings in a separate loop to avoid having to wait for the interpolation before doing the next measurement? -
Separating "installer" development from code development
Mads replied to infinitenothing's topic in Source Code Control
Wow, I would *never* program in pairs. Who can stay in the zone with someone else messing with the flow (see item 8 on this list...) Working together while discussing the work and writing pseudocode is good, but while actually programming? Yuck. To work well I need to keep and manipulate 110% of the problem in my head (the extra 10 percent (or 200%) is the array of continuously variating attacks on the project my fantasy throws at it while I am working on it to find holes, weaknesses and opportunities in the plan 🧐) , and to do that I need to be "alone inside my head".... -
Have you tried updating the firmware via the web interface of the controller?
-
I am taking a sabbatical from LabVIEW and NI R&D
Mads replied to Aristos Queue's topic in LAVA Lounge
Toronto is halfway around the globe from me so I will not pretend to know anything about the job market there, but just out of curiosity I found 28 adverts here that at least mentions LabVIEW. The number of open positions that mentions LabVIEW here in Norway actually seems slightly higher than it used to be (contrary to the feeling I also have about its decline). There are very few pure developer positions though, as has always been the case. -
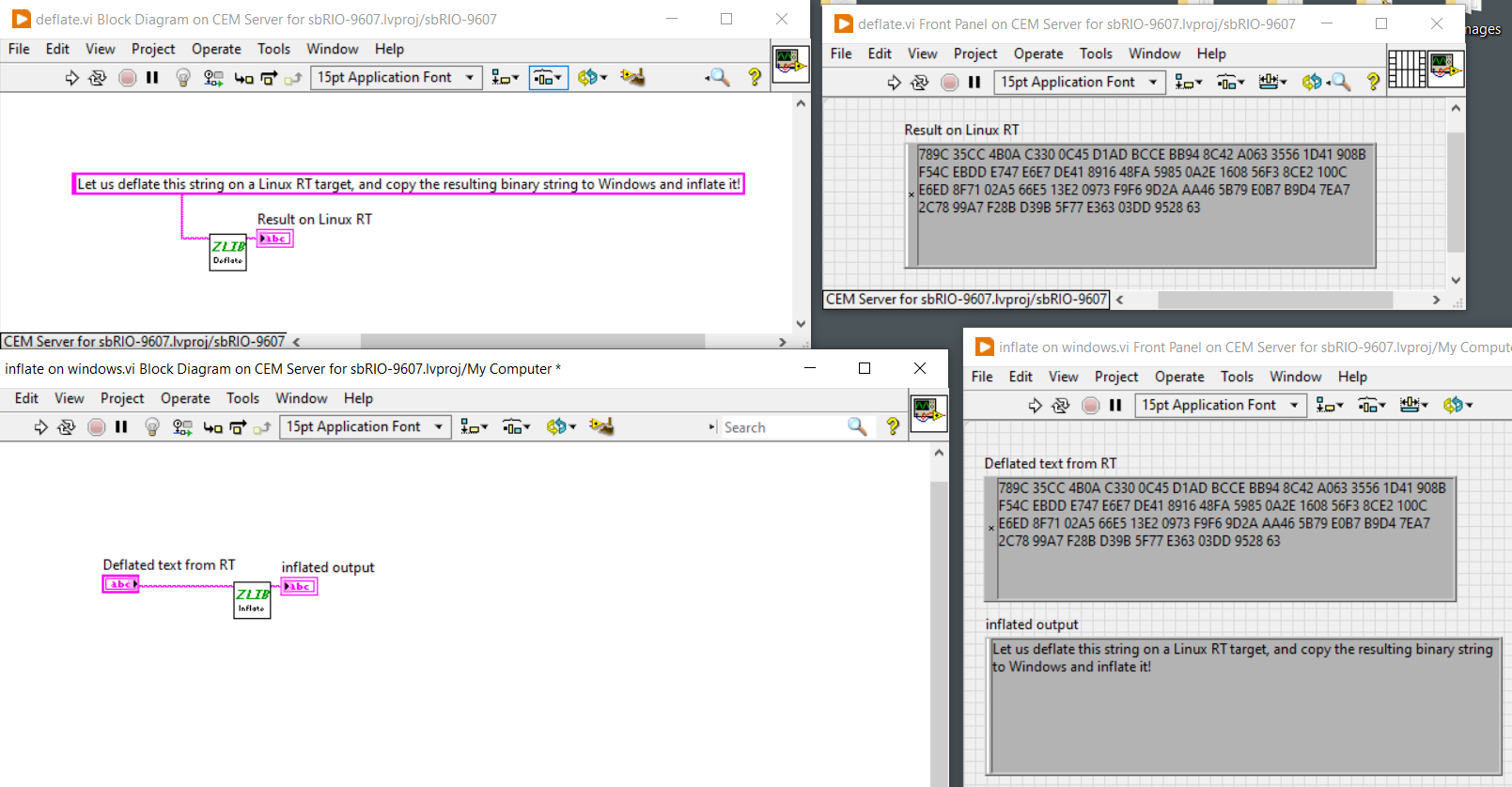
Start with something simple, then work from there... Here is an example of how it looks like with a simple test: The deflated string is binary so the string indicator/control is set to hex for the deflated input/output... If the content can be compressed too much and the expected length is not included it can fail yes....We had an issue with that where we could not change a protocol to include the length, we "fixed" it (increased the probability of success that is) by editing the inflate VI so that it would run a few extra buffer allocation rounds - you can do that too...
-
We have server applications running on cRIO/sbRIOs (Linux RT) and the clients run on Windows. The TCP-based client-server protocol uses @Rolf Kalbermatter's zip tools to deflate/inflate all the time, to speed up the communication in both directions. It runs without a hitch. I do not have a target to test on right now, but it sounds like there was something else affecting the test you ran. If you have an example of some data deflated/inflated on both targets that might help. Did you run the same version (which?) on both targets?
-
Everything works just as before in LabVIEW 2020 at least. We install it from NI Max using the custom software option.
-
The path to the rtexe launched by the RTE is not fixed...so perhaps you could just change the given path before killing the current application? I have not tried, but if it works it would allow you to keep multiple rtexe files instead of overwriting them: On LinuxRT the path is in: etc/natinst/share/lvrt.conf which is an ini-file formatted file it looks like with the key: RTTarget.ApplicationPath=/home/lvuser/natinst/bin/startup.rtexe
-
We normally just make the executable reboot the cRIO/sbRIO it runs on instead, through the system configuration function nisyscfg.lvlib:Restart.vi, but here are two discussions on killing and restarting just the rtexe on LinuxRT: https://forums.ni.com/t5/NI-Linux-Real-Time-Discussions/Launching-startup-rtxe-from-terminal-or-linux-window-manager/td-p/3457415 https://forums.ni.com/t5/NI-Linux-Real-Time-Discussions/Is-it-possible-to-close-and-re-open-RTEXE-through-Embedded-UI/td-p/3707540
-
LabVIEW, as the Xerox GUI, needs a Steve Jobs... I was an Apple fan back in the 20 MB HDD days. It was only natural to fall in love with LabVIEW as well.🤩
-
I do not like to judge anyone by their official background but if we are talking about it his background prior to that seems to be mainly in hardware and testing. He has a lot of chiefs, vice presidents and fellows under him though...(Too many, with too much overlap is my initial reaction). I do not fully grasp how the top management ended up with those particular titles, but based on their titles I assume the two most responsible below him in the hierarchy for taking care of LabVIEW are the newly hired CTO, Thomas Benjamin (with SaaS background) and Scott Rust, as the Executive Vice President, Platform & Products, or? Where in the organization does Omid Sojoodi , the Senior Vice President of R&D, Software sit? This is the best organizational map I found. It has one role specifically for software strategy, but that's a software *sales* strategy role it seems?