
Mads
-
Posts
469 -
Joined
-
Last visited
-
Days Won
33
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Mads
-
How realistic is the test setup that fails to reproduce the issue? Does it have the same potentially slow/unstable links/external devices, does it run the exact same operations etc? Perhaps a DNS server that disappears from the network now and then e.g, or other connected equipment that fails / you can cause errors in to expose potential issues? Is the test unit set up based on an image of the troublesome unit? More difficult obviously but can you alternatively downscale software/ turn off some of the tasks / remove parts of the code on the field unit to see if that removes the issue? When the cRIO fails to respond is it really dead locally as well, or is it running/responding locally? We have had units unreachable through existing network links due to DNS and other issues where we had to modify the code (remove any DNS lookups e.g.) to get it to respond properly... Have you tried enabling and reading the debug output from the device? We had some sbRIOs crash without much explanations due to a sudden spike in the memory usage (inferred, not fully observed) caused by a calculation that was triggered. There was no obvious reason; the debug logs and memory monitoring could not really explain why - we just had to push down the memory footprint until it started working... Have you tried formatting the cRIO in the field and setting it up again? Would it be possible to replace the cRIO in the field with another one - then bring the field unit back and use that to try to recreate the issue? If it stops in the field with the new cRIO it is most likely linked to the cRIO hardware...or a system corruption on it. If it shows up witht he new cRIO and not in the test setup the test setup is obviously not realistic enough...
-

Ramer-Douglas-Peucker algorithm - Reducing points for DB storing
Mads replied to Bjarne Joergensen's topic in LabVIEW General
For logging of some of our more erratic parameters we are looking at using this algorithm. It is called "Largest-Triangle-Three-Buckets" and is quite simple to implement. For more gradually changing values (tempeatures or pressures e.g.) I found a nice compression algorithm many years ago that was patent-protected by GE at the time. The patent is expired now though, so it should be usable. I have attached a demo of that one here (run CACF_Demo and generate a fluctuating value with the slider to see how it compresses the data), it is called the Critical Aperture Convergence Filter. Critical Aperture Convergence Filter.zip -
In the example I posted earlier there is a tab at the bottom which (seemingly) scales nicely. It is a trick though...I described it a long time ago here. Maybe someday we get this implemented.... Or better yet, anchoring.
-
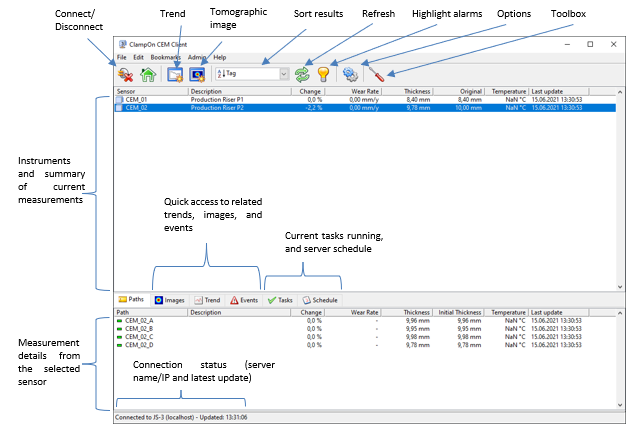
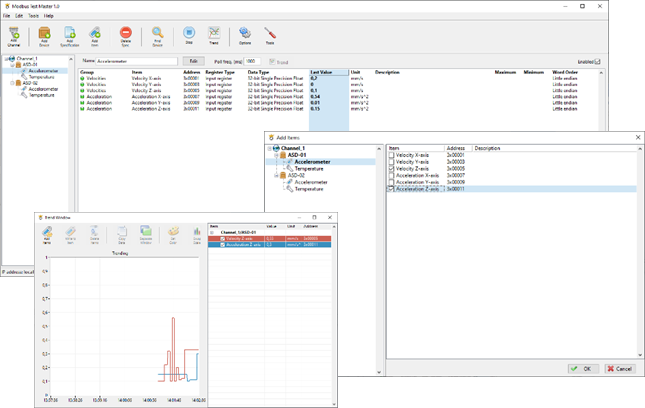
Awesome as in unusual but cool / exploring new concepts in user interface design (often irritating the user in the long run though...) - or as in user friendly and nice (non-LabVIEW-typical?) looking? I too would love to see examples of what others have made. I can share some of the designs I have made myself or have influenced, that I think at least fit the user friendly but not typically LabVIEW-looking bill: We make monitoring systems and use LabVIEW to develop everything that runs on PCs and PACs. I have always put a lot of effort into making the user interfaces as nice, intuitive and recognizable as regular Windows applications (helps with the intuitiveness) as possible in G...The system typically consists of a headless service/embedded server (sbRIO inside a subsea device e.g.) gathering, analyzing and logging data from sensors, and exposing it to control systems or data historians through Modbus, OPC or CANOpen. Users can connect remotely to configure the server and view and analyze the results using application specific clients (through TCP, serial or CANOpen (Cia309.3 transparent links)). Here is a screenshot of the main window of one of the clients (this one is used for corrosion-erosion monitoring): We also make many of the tools we need to do tests and troubleshooting on these sensors and systems, and some of them we have chosen to release as shareware (CAN Monitor on the NI Tools Network e.g.). Here is an example of the Modbus Test Master: We do not earn much from the shareware, but since we want these tools ourselves anyway, and need to maintain them, having them out there at least do not cost us much. It also puts a bit of extra pressure on us to make even (some of) the internal tools look and work well.

-
I agree with you, and would normally stick to just a File\Exit menu option and window close. As long as extra ways of closing the application do not harm (read: confuse) more than they help I would not argue too much against them though. It depends mostly on the type of application. Different people prefer different solutions (the true lesson in the 80/20 rule). A File>Exit (Ctrl+Q) menu option and the window close covers the standard methods, so they should always be there, but if the application might end up running on a computer with a touch screen, and access to an exit is desirable, having a button would be nice too - and not weird. (Assuming it is made distinct from other buttons that just stop sub-processes (as ShaunR mentioned earlier)). I am lucky to normally have the final say in such matters myself😃. PS. We used to have a financial system that did not offer any save options. Instead you were always required to select print, and then Print to file (💩!). I would love to meet and have a chat with the people who designed and approved that solution😉. (This was even before printing to pdf e.g. became a concept, which at least makes it partially recognizable as an *optional* route today).
-
I have to agree with the requirement (although having an OK and a Cancel would suffice unless you also want to apply prior to closing the window). Stick to the norms established by the OS, familiarity is key. If I regret entering the dialog and/changing something having OK/Cancel there will allow me to recognise what to do in a fraction of a second. If this particular designer though it obvious that closing the window would revert...eh, I mean save the...hmmm. Do I need to change back the changes I did, or is it enough to close the window, I wonder....🤔
-
Hi, My guess is that you have set the Get Image method to use 16 bit colors. Use 24 bit and it will show up correct (I recreated and solved the issue just now by generating a front panel image of a screenshot of your original colors).
-
What is the cost you are worried about? Is it speed, memory, or both? If it is speed - is the example representative? In that case I would calculate the window function within the inner loop and just output the result, not generate an array of all the subwindows and *then* apply the actual window calculation. The loop(s) can also be configured for parallelism to speed things up significantly (assuming you have more than one core at least)... More speed, less memory. If none of that reduces the cost enough you will probably have to do the processing in external (non-G) code.
-
If only NI could implement my second most popular idea on the idea exchange 😉 (please vote!). (Hopefully they can squeeze it in while working on my most popular idea/rant which partially covers this one anyway).
-
Modbus read problem - beginner level
Mads replied to BeeEyeBye's topic in Remote Control, Monitoring and the Internet
What error code does the Modbus VIs return, if any? Can you try it towards a local Modbus TCP server/simulator, does that work better? Can you temporarily disable the firewall? I used your code as it was, just changed the IP, and it connected immediately to my local Modbus server and was able to read the registers, I also changed the addresses out of that server's range to verify that I got the expected exception response/error I showed earlier. If you can install Wireshark I would use that to sniff and compare the traffic from the LabVIEW code with the one you generate with Qmodmaster (post the Modbus traffic here and we can decode, Wireshark can help you as it is able to decode Modbus too). -
Modbus read problem - beginner level
Mads replied to BeeEyeBye's topic in Remote Control, Monitoring and the Internet
A couple of notes: a) The code you have will work for reading *Holding* registers (not input) from a slave/server on the given IP and port, but only if that server ignores the unit id or happens to have unit id=1. If it requires a different unit id (many Modbus TCP servers expect it to be 0), right click on the modbus master wire and insert the "Set Unit ID"-function, then wire the correct id to that. b) Assuming the unit id is not preventing the server from bothering to answer you should still get replies from the device even if it does not have any holding registers available, but the replies will then be exception responses and the functions you use will then return an error looking like this (create an indicator within the loop to see it imemdiately): Error -389112 occurred at an unidentified location Possible reason(s): LabVIEW: (Hex 0xFFFA1008) The Modbus slave does not accept the data address contained in the query. Function 3 c) Why two Modbus master connections to the same device? It might support it, but during troubleshooting I would remove the second loop and focus on getting one working. -
I'll leave the logic to others for now, but here are a couple of initial observations: 1) If these tables can get larger you might consider making the table cell formatting more efficient: Defer front panel updates (updating table GUI for each step is extremely slow) then format the table cells and headers in one go before you reenable front panel updates. If all rows of all columns are to have the same format anyway (empty ones can get the same as they are empty anyhow) you might as well set the active cell to -2,-2 and apply to all. If the headers are to be different you can then apply a reformatting of all of them afterwards using a -1, -2 combo (kudo this idea to avoid that last step in the future...). 2) The OpenG toolkit has "Remove Duplicates" and "Sort 2D array" functions you could use to get the unique and sorted week and models. If you have LabVIEW 2020 the same functions are available as VIMs on the array palette. 3) Avoid the repeated searches, e.g. by running an auto-index-driven set of for loops and simple equal or not checks instead. As others have mentioned already using a feedback node / shift register to keep track of whether to insert a 0% or not is likely to be part of the solution. Personally I would probably be lazy and just initialize the whole table with 0% and leave it at that 😄, but that might be misleading here...and not as pretty. Working from the bottom up filling in 0% on empty cells after the last entry has been found (state kept in feedback/shift reg) is another idea. The fact that you want to fill APR W3 all the way down to the end of APR W2 makes it necessary to include the state (end index) from the previous column as well though, not just whether or not there is an entry lower in the same column.
-
I have not seen that. It is not the NI Tools Network your thinking of, is it? We did put one product there as it relies on NI hardware, but otherwise it feels more right for libraries and coding tools than generic applications...
-
I recently needed to figure out a good way to get a piece of shareware (developed i LabVIEW) distributed to the various popular download sites. It does not really matter which programming language or tool(s) were used in the development so I did not search for help on this here or at ni.com. One good source I found was this https://www.fatbit.com/fab/promote-software-app-online/ It did strike me as a bit curious though that we never really discuss such matters. Most applications developed in LabVIEW are probably not generic enough to be released through such channels, but sometimes they are, and unless you have your own sales and marketing people that are familiar with software you might need to do the job yourself. Perhaps some of you have been through this with your products already and have some tips and tricks to share? One generic product we have *not* released this way yet uses the OPC UA API. The distribution license requirement NI puts on it makes it too cumbersome to handle 😒 One of the things I discovered from the mentioned web site was the use of PAD-files. I created an account at AppVisor and started working on a file for the shareware we were to release. You can edit, save and publish the PAD file, but very few download sites automatically discover your software that way so I soon came to realize that I needed to pay AppVisor a fee for them to submit the software to the download sites. I did try to submit to my favourite download site myself first (download.com), but they never published it on their site. The AppVisor submission service came in different price categories and as I did not expect the software to generate that much sales I chose the cheapest option for now which only gives you 4 submissions per year to 100 sites, but it is a starting point. One thing I soon learned was that the download links should be made permanent. At first I used links that contained the version and build number , and that got cumbersome very quickly as we soon needed to submit a few bug fixes and updates... I also had to create program descriptions of various standardized lengths, provide links to icons, screen captures etc. Having a video or two showing some of the features is probably a good idea as well. Reading tips and tricks from other sites I started mentioning and/or linking to the product on social media, but tried to do it rather discreetly as I personally hate obvious marketing🤢. I still got marked very quickly as "spam" on one site - even though I had only mentioned the product in a relevant setting, and along with similar competing products 😦. It makes me appreciate the work our sales people normally do for us. They are too busy selling our main products so I have not bothered them much with this.
-
Front Panels turning to gibberish Chinese (CAR 185890)
Mads replied to eberaud's topic in LabVIEW General
I have seen this a couple of times in my applications and a fix then has always been to either remove all but English, or support all languages on the run-time languages page in the application builder (perhaps any change there is what is really doing the trick, I have not explored that as I have always just moved on when the error disappeared). -
Just to tie off this thread: The reason for the glitch was that the wiring allowed for a minuscule race-condition 😒. One minor adjustment was needed to ensure everything was *only* decided by the enqueue scheduling. So no worries about that anymore 😀
-
Nice discussion, thanks for the link. The quoted statement seems to contradict my observations yes. I have not checked if the misbehavior was absent in any of my earlier LabVIEW installations yet...I am working in Windows LabVIEW 2020 SP1 at the moment.
-
The original producers acquire a reference to the consumer queue, and call enqueue in a pre-allocated reentrant VI...But when multiple copies of these are waiting in parallell to enqueue, the time at which they started to wait does not decide when they get to do the enqueue. So what I did as a test was to test how this worked if the reentrant VI was non-reentrant (which does not work in the actual system as VIs enqueuing to a different consumer should not wait for the same VI, but just to test now) - and that made everything run according to the time of call. I guess this comes down to the internals of the enqueue function; when you have multiple enqueuers waiting, I thought the queuing system would keep track of when the various callers had first requested access - and then, when the queue has room for another element, assigned access to the originally first request. Instead it looks as if there is something like a polling system in the background (running when it is hung in a wait to enqueue state) that makes it random which of the waiting enqueuers will win the race...
-
If the enqueue and wait for a reply function of all producers sharing the same consumer is put in a non-reentrant VI, the execution *is* scheduled according to the order in which the producers call it. So that is one solution. Assuming that the execution of enqueue calls (or rather their access to the bounded queue) would be stacked in the same way; ordered by the time of call, seems a bit less obvious now that I think about it, but the level of queue jumping is still surprising. If for example there are 5 producers, 4 will at all times be waiting to enqueue (while the fifth in this case has finished enqueuing and is waiting for the consumer to return a result). In my test case, where each exchange between a producer and the consumer will take 1 second, a fully ordered execution should consistently complete a round in 5 seconds (which it does if I use the non-reentrant VI solution). - Instead, due to all the seemingly random enqueue-queue (!) jumping, the period of processing for any given producer can spike as high as 15 seconds😱! That means it has been bypassed by the others several full rounds before it got first in line.
-
Does anyone here know how LabVIEW decides in which order multiple instances waiting to enqueue to the same size-limited queue get to enqueue?😵 If e.g. a consumer has a queue of length 1 (in this case it is previewing, processing, then dequeing to ensure no producer is fooled into thinking that the consumer has started on their delivery just because it was allowed to enqueue 1 element...) and multiple producers try to enqueue to this consumer, I have (intuitively / naively) assumed that if Producer A started to wait to enqueue at t=x, and other producers try to enqueue at t>x, producer A would always be the first to be allowed to enqueue.. This does not seem to be the case (?). Instead producers that begin to wait to enqueue while others are already waiting sometimes get to enqueue prior to those. This causes the waiting time for some producers to increase unpredictably, because a variable amount of producers cut in line. This phenomenon occurs in a rather complex piece of code I have, so I wrote a simulator to see if I could recreate the issue - but so far my simulator seems to adhere to my previous assumption; Each producer gets to wait the same amount of time because they keep their place in the enqueuing order. This might just be a weakness in the simulation though...or I have so far misinterpreted what is really going on. If my assumption about priority was wrong all along it would solve the case faster though....(then it becomes a quetion of how to solve it in a manner where producers actually have such a priority 🤨)
-
I think this is about as wrong as it can get. If an indicator is wired only (no local variables or property nodes breaking the data flow) it shall abide the rules of data flow. The fact that the UI is not synchronously updated (it can be set to be, but it is not here) can explain that what you see in an indicator is not necessarily its true value (the execution, if running fast, will be ahead of the UI update)- but it will never be a *future* value(!). As for breakpoints they do not exist just in the UI - they are supposed to act at the code level, and their execution should be controlled by data flow. So in the case of a break point the break will (should) occur as soon as it has its incoming data available at the execution level, not the UI. The UI will update the state at its pace, but UI is just displaying the state after it has occured, not deciding when it is entered. One thing that makes this more complex in LabVIEW and in this example is that we are dealing with parallel execution within the same diagram. A breakpoint should really (we expect it to) as soon as it has its input value cause a diagram-wide break, but it does not. Instead it waits for the parallell code to finish, then breaks. As for the indicator showing the value prior to the break that part is explained by the bit LogMAN refers to; that breakpoints allow the value to pass before they hit the break...
-
In the few cases where performance is that critical you will probably have to get by without traditional debugging anyhow. Do you expect you comfy car seat to occasionally disappear, and accept that as a consequence of wanting a quick car...? Sure, in the rare cases you need it for drag racing 😄 I do not consider key features like data flow and breakpoints something that should be allowed to occasionally break/act randomly. Either you have them and they work as they should, or you remove/disable them and explain/visualize why they are sacrificed (to get performance) until you are able to offer both performance and proper behavior. Disabling debugging and/or turning down/off optimizations could still be an option in the few cases where that is the only way to get the necessary performance.
-
As drjdpowell mentions the bug could be caused by optimizations, but it should still be considered a bug that optimizations are allowed to interfere with the data flow in debugging mode. I suggest you post it on the ni.com forum as well and see what NI says.
-
Looks like a bug to me. It is not restricted to your example though. Breakpoints should execute according to the data flow, but often do not.
-
Here is one that involves a nice mix of small challenges: My first assignment after being hired as an engineer back in 1998 was to write a multiplexer and demultiplexer. In that case we had 8 instruments outputting readings as an ASCII string every second (fixed length message containing a numeric value: "AA 2500BB\r\n"), and all those strings had to be read from 8 separate serial ports, tagged with a channel (c1, c2, c3 etc..) and then sent on through a single serial link (because we physically only had two wires available) to another PC where the signals would be split into the original 8 live values...Unless you are already familiar with serial IO you might want to simulate the physical parts at first to finish the downstream logic, then you can add the physical / serial communication bits at the end (in case you end up spending too much time on that to finish everything).