PiDi
-
Posts
85 -
Joined
-
Last visited
-
Days Won
15
Recent Profile Visitors
6,810 profile views






PiDi's Achievements
")





-
 It should work. It doesn't matter if you're passing class or cluster or whatever else. Some generic questions, as troubleshooting this deeper would require actual code: 1. Is your FGV VI non-reentrant? 2. Are you using this FGV in different timed loops with different priorities? Are you sure all of those loops are running (i.e. one high-priority, high-rate loop might starve the others). 3. Can you use Global Variable instead od FGV? (yes, it's a genuine question ) I'm not sure why adding a ton of complexity to the problem would solve it
It should work. It doesn't matter if you're passing class or cluster or whatever else. Some generic questions, as troubleshooting this deeper would require actual code: 1. Is your FGV VI non-reentrant? 2. Are you using this FGV in different timed loops with different priorities? Are you sure all of those loops are running (i.e. one high-priority, high-rate loop might starve the others). 3. Can you use Global Variable instead od FGV? (yes, it's a genuine question ) I'm not sure why adding a ton of complexity to the problem would solve it -
Let's try to break it down a bit: Why is it too complex? What exactly is complex? What's wrong with that? What problems are you actually trying to solve by trying to move into OOP? Why do you think the "simple producer/consumer" is a mistake? I'd say QMH and Actor Framework are kind of fancy producer/consumer frameworks, you may get some value, but you also get the learning curve. Have you ever used them, or even looked at some example applications? Again - what is wrong with your current way of handling the data? As a side note - going with OOP do not require you to use Actor or QMH, and using any of those frameworks does not automatically make your code object-oriented. Generally speaking, if you're thinking about designing your application in object-oriented way, you'd need to actually start with the design part - do some modeling of your application, thinking about possible objects and their interactions with other objects, etc. But I'd start with thinking about questions above - what problems are you trying to solve?
-
Just watched it, it's underwhelming. The first feature was "improved Matlab integration" followed by Python... You don't really expect much if they start with better 3rd party software integrations. And then there was the Future of LabVIEW slide: That's just a bunch of generic slogans and integrations of niche products... Don't see any clear idea of the direction here.

-
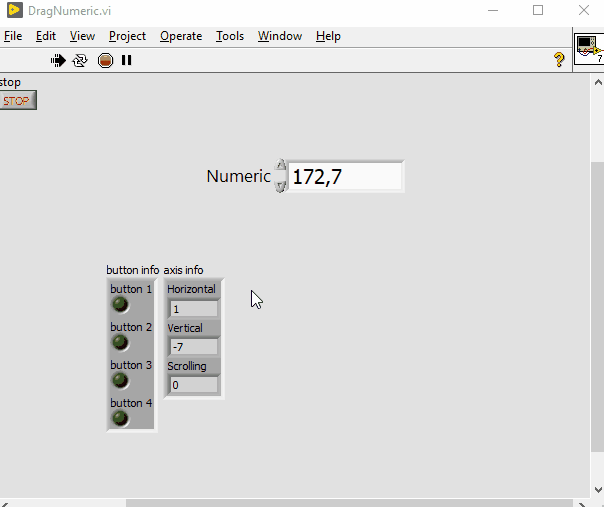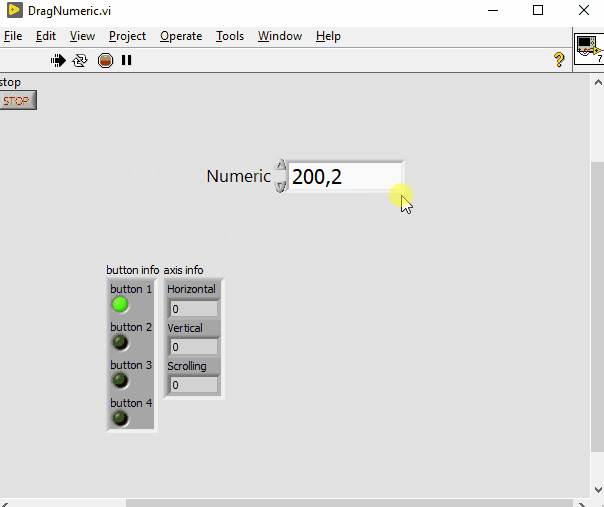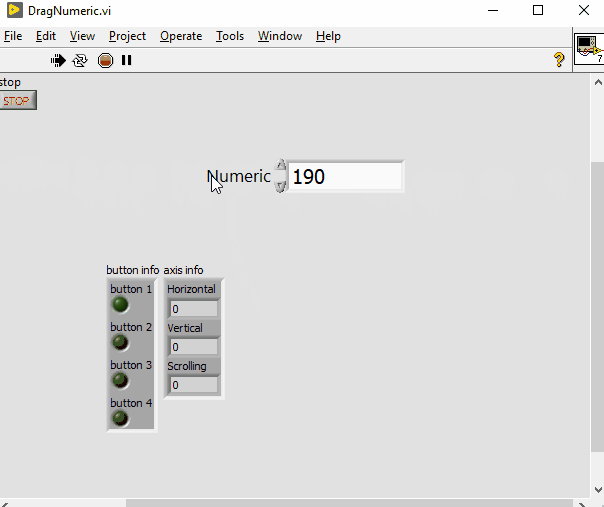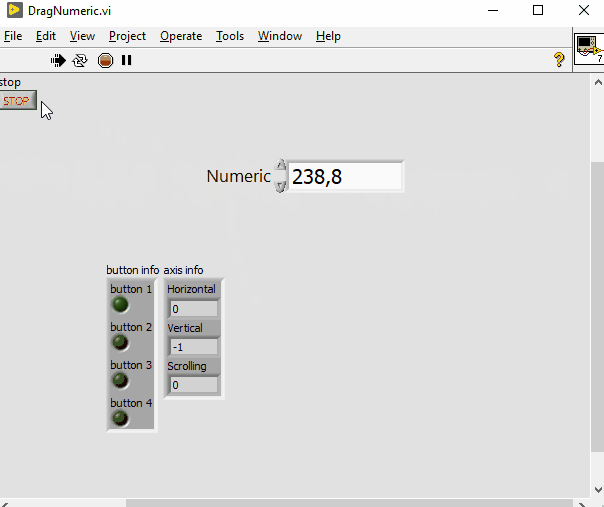
The ability to adjust a numeric value by dragging the mouse
PiDi replied to Neil Pate's topic in LabVIEW Feature Suggestions
@thols, it's doable, I may do it for further fun @ShaunR, nah, just event structure and Input Device Control pallete. Attached the LV8.5 version if you want to take a look. Implementing it in XControl would be cumbersome as it needs to pool the mouse continously. (Plus I removed XControls entirely from my "technology toolbox" a long time ago, together with tons of problems they cause). DragNumeric.vi -
The ability to adjust a numeric value by dragging the mouse
PiDi replied to Neil Pate's topic in LabVIEW Feature Suggestions
Interesting idea, I've made a quick implementation of it just for fun. This might actually be usefull on touch screen GUIs, I need to explore that. DragNumeric.vi
-
Anyone have a G version of "Search Results" dialog that I can use?
PiDi replied to Aristos Queue's topic in VI Scripting
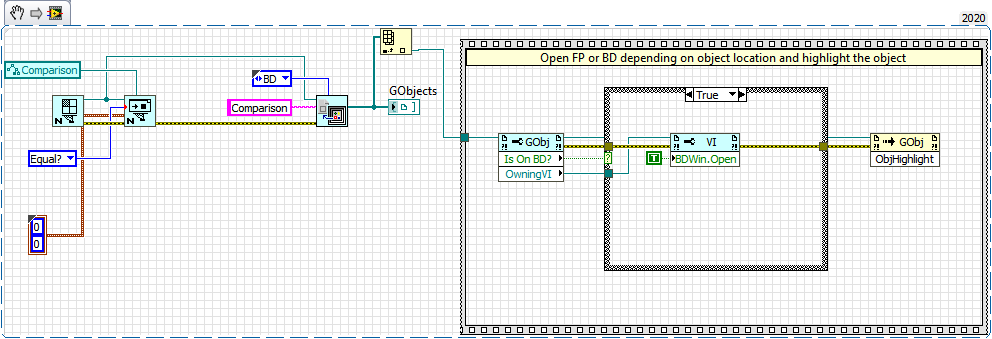
Do you want to just open the proper FP/BD and highlight the item? This part is pretty straightforward.
-
Same story here. We've just started to standarize on Beckhoff. EtherCAT is nice medium for realizing distributed systems. We use EP boxes for distributed IO (just as your case - a great way to reduce wiring; add IO-Link sensors and actuators to the mix and you save A LOT of work with the system assembly and testing and gaining unlimited flexibility). EL terminals for the control cabinet - you can basically build any system capabilities you like, and add anything any time in case you'd forgot. Also, you get safety-rated terminals and boxes (and you can build distributed system with that, no need to bother with all those cables from curtains and interlocks from the other side of the machine). And motion control with EtherCAT based servodrives. And everything integrated within single TwinCAT environment (and they even know and care what source code control is). And you can have everything deployed on Windows based industrial PC with real-time TwinCAT capabilities and have some other applications running side-to-side. Well, if you haven't noticed yet, I'm in love with this whole system That being said, I still consider LabVIEW ("old-gen" one, mind you) to be superior environment. It's sad that NI never had and still doesn't have too much to offer in terms of machine control and industrial automation.
-
NXG, I am trying to love you but you are making it so difficult
PiDi replied to Neil Pate's topic in LabVIEW General
After starting NXG 5.0.0 and traditional hang of the whole OS for 3 minutes, LabVIEW forgot how to write text on the screen Ok, not only LabVIEW, other apps too... They used to have a name software that caused weird system behaviour: a virus...
-
I don't think this window is available as VI. It is probably one of those built-in windows. Even if it isn't, you'll probably be better off doing your own tool. The recreation of the current override VI generation shouldn't be very complicated, and you could use anything available in MemberVICreation.lvlib to save some work. Project Provider for it is really just a quality-of-life addition, your tool will work as well (or even better :D) with a simple class selector drop-down list.
-
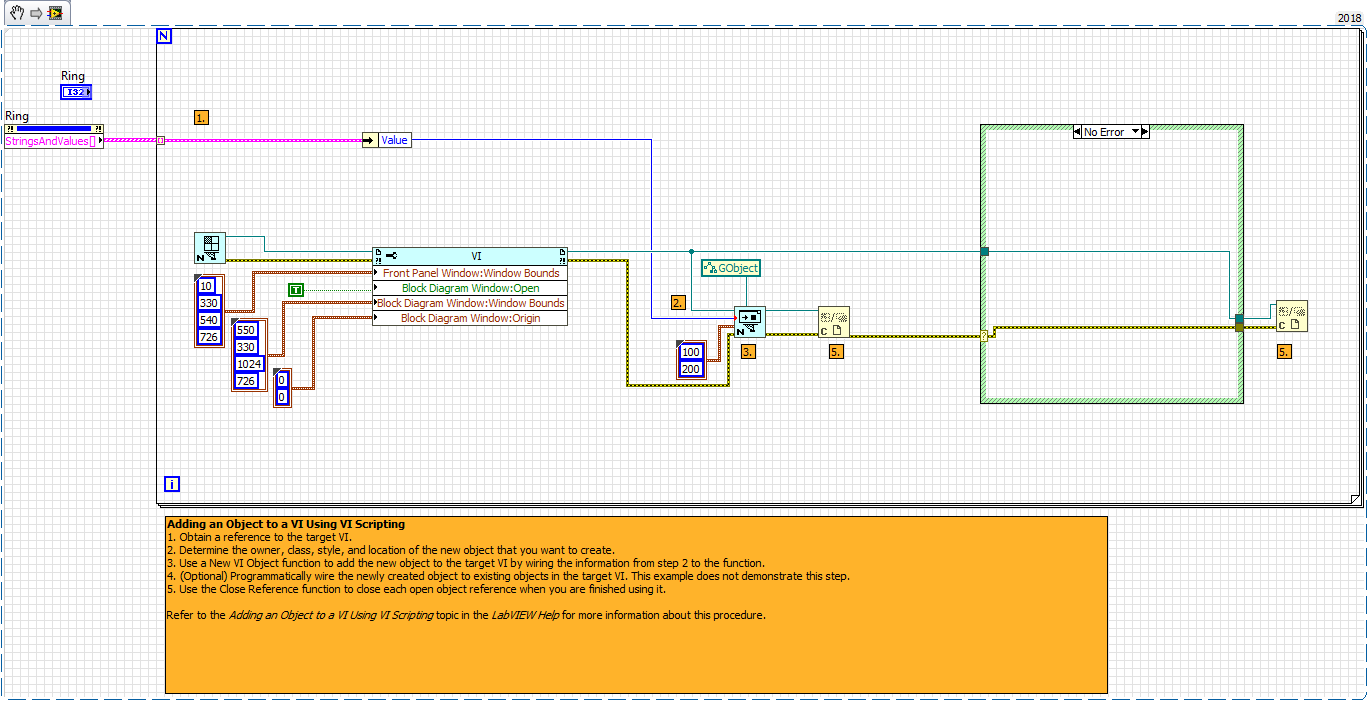
Something like that. CreateALLObjects.vi
-
Those RT utility VIs get broken whenever you try to open code in My Computer project context instead of RT. On which target do you develop your framework? Do you have any shared code between PC and RT? If yes - try to get rid of it.
-
I've seen this behaviour many times. We use OOP and lvlibs heavily in our projects and unfortunately often run into those builder quirks. The fun fact is that sometimes the same project built on different machines produces different outcomes (on one it always breaks, while on other it always succeed, while on third it's 50-50 chance). I never really bothered to investigate and report this to NI as those problems are very non-reproducible. Going to your specific question aboutt VIs which end up outside exe (in no particular order) : 1. Check the dependencies between libraries. The builder hates circular dependencies between them (i.e. something in lib A depends on something in lib B and vice versa). Avoid them - usually the solution is to move the offending VIs between those libraries. You'll also end up with better code design, so double the profit. 2. Enable builder log generation (I think it's in Advanced settings) and see if you can make any sense of what it puts out regarding those "outside" VIs. 3. Try building on different machine. 4. Set "Enable debugging" for the build (also in Advanced settings I think). 5. Try to recreate the problematic VIs under new names - create the blank VI, copy the contents (block diagram) of the current VI, replace the calls. Do not simply rename the current VI and do not Save as..., both of those might retain some hidden problems inside the VI. Also,try to change reentrancy settings and try to make them inline. 6. Try to recreate callers of those problematic VIs in the same manner as above. 7. Separate compiled code from the VIs. 8. On the contrary, do not separate the compiled code. Try to do both and see if there is any difference. 9. Last resort - put the contents of the VI inside the caller.
-
Multiple EXE instances crashing at the same time?
PiDi replied to drjdpowell's topic in LabVIEW General
It is actually possible to force DLL to use shared memory space, so it still may be the problem. I had a simillar problem once: when I would run the DLL in development OR in exe, it was ok. But when the exe was running and I was simultaneously runt the dev VI, it would crash. I never bother to look for the actual solution, as I only needed only one exe in production. But I've heard that renaming the DLL for each instance of application might be solution, as it allocates the memory space, shared included, according to the name. I'm not really sure if it's true, but if you're desperate, it is worth a try. -
Hello LAVA-ers! If you haven't heard already, the CLA Summit 2020 will take place in Budapest on March 24th to March 26th. You can read more and register here: https://events.ni.com/profile/web/index.cfm?PKwebID=0x94716776a&varPage=home . This year we have an Open Source Session dedicated to the people who want to show their projects and encourage the collaboration. The rules are simple: Contact either me (through private message or email: piotr.demski@sparkflow.pl), Thomas McQuillan (who's also wrote about it on linkedin: https://www.linkedin.com/feed/update/urn:li:activity:6628225386339803137/ ) or Anastasiia Vasylieva (anastasiia.vasylieva@ni.com) You'll prepare three minutes presentation to showcase your project (we'll provide you with two-slides presentation template to fill most important info) (optional) We also have a poster session, so you can prepare an A1 sized poster to display at the Summit (please also contact us if you're interested) I know that not everyone here is CLA and is able to come to the Summit, but I encourage you to submit your project anyway. We'll compile all the presentations into one document and we'll distribute it in the LabVIEW community. So it's also a good way to promote your project!
-
- 1
-

-
Hi Porter, where is this Pallete API? I've never used it, so I'm a bit in the dark Would you like to help creating this plugin to G Code Manager?