hooovahh
-
Posts
3,466 -
Joined
-
Last visited
-
Days Won
298
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by hooovahh
-
I would not count on purchasing a license, causing the passwords to be removed. Sorry. Additionally the NI toolkits are often just wrappers around a DLL or some binary. This means for it to work it must hook into NI specific function calls to NI specific hardware. The ADCS toolkit works this way and that's why I had to rewrite it to allow using different hardware. The ISO 15765, XCP, CCP, KWP2000, UDS, J1939, and other CAN protocols are really just software layers on top of some frame level API. They can all be written in a way that is hardware agnostic. But NI's toolkits are not written this way. NI wrote their ECU toolkit to work with NI hardware, and they want to keep it that way. The hardware helps sell software, and the software helps sell hardware. They don't have an incentive to have it work with other hardware. But honestly their hardware is quite good. I really like the NI USB 8502.
-
Yeah multiple targets is the main issue I've had over the years. I have a great reuse library that is written well to work on RT or Windows. But making a single PPL for both targets is impossible. And having the palettes, and builds, and projects pull from the right PPL, and pull the other dependent PPLs, is such a major pain that I abandoned it.
-
Several things can be done to optimize TDMS writing. TDMS has to occasionally write header data to the file to keep track of the data being written. Because of this you can add one TDMS file to the end of another and it will make a valid file. You can't for instance append an Excel file (XLSX) to the end of another and get a valid file. So you want to minimize the amount of times the header data needs to be written to disk. The easiest way to do this is to write multiple samples at once, or writing multiple channels at once. You want to avoid writing single samples. So build up N samples for your N channels and write them once the buffer is full. The buffer doesn't need to be your whole 12-18 hours. You can start small with say 10 samples and see how it performs.
-

Question on "Finding a missing subVI in a referenced VI"
hooovahh replied to xiongxinwei's topic in LabVIEW General
Use the File Dialog express VI on the File IO >> Advanced palette. You can configure this to prompt the user for a file path then wire that into the open. -
Parallel For Loop versus Async Call and Collect
hooovahh replied to Stagg54's topic in LabVIEW General
I went to dig up my fast ping utility for Windows, but I see you were already in that thread. As for this thread. I rarely use the parallel for loop but when I do it is a more simple set of code. It has those caveats Shaun mentioned and I typically use it is very small cases, and where the number of iterations typically are small. In the past I did use it for accessing N serial ports in parallel to talk to N different devices sending the same series of commands and waiting for all of them to give the responses. And I have used it for cases when I want to spin up N of the same actor. Here there is other communications protocols to handle talking between processes. And again these are usually limited to some hardware resource like two DMMs that are independent. If it needs to be very scalable, and have large numbers of instances a parallel for loop probably isn't what you want. -
This is very true. But LabVIEW does a decent job with resizing panes with splitters. It isn't always an ideal solution but if you can known the supported UI layouts you can have subpanels, in subpanels to support what you want. Here is a demo I made. Just run the VI and resize the window. The youtube video isn't nearly as smooth. But this design only supports 20 images high, and 20 images wide. I should have probably implemented some kind of minimum size, and then have a scrollbar appear.
-
I emailed the site admin to see if there is something broken. Welcome back.
-
I use User Events as the transport mechanism between asynchronous processes. As a result I wish there were a feature where there was an event generated when a reference goes invalid. I made an Idea on the Idea Exchange here. Similarly the work around is to have a timeout where the reference is checked to be invalid. A better solution is to send a stop command as some kind of global user event, or in your case enqueue. But as you've seen there can be edge cases where things stop unexpectedly and I just want all the running children to go through their cleanup process. Stopping on the error, or invalid user event reference, is a fairly simple way to do that.
-
Is there a reason you are doing this, instead of having a type def'd cluster? Then you can use the Bundle/Unbundle by name to get and set values within a single wire? Then probing is easier, and adding or updating data types can be done by updating that one cluster. Typically Variant Attributes are used in places where an architecture wants to abstract away some transport layer that can't be known at runtime. In your case we know the data type of all the individual elements. If you were doing some kind of flatten to a Variant, then sending over TCP, you'd want some standard way to unwrap everything once it got back. I've also seen it used where a single User Event handles many different events, by using the Variant as the data type. Then each specific User Event will have a Variant to Data to convert back to whatever that specific event wants. There isn't anything wrong with what you are doing, I'm just unsure if it is necessary.
-
Have you tried uninstalling, then reinstalling the toolkit? Are the VIs in the vi.lib and just not on the palette?
-
There's also a little known feature in the top method where you can right click the Wait On Asynchronous Call and can set a timeout. This will then wait some amount of time for the VI to finish and will generate an error if it isn't completed yet. There are better ways to handle knowing when the VI is done, but it is good for a quick and dirty solution to wait a few ms for it to finish, and if it isn't done, go service something like the UI and come back again later. I submitted that as an idea on the Idea Exchange, then AQ said why it was a bad idea. Only for years later it to be implemented anyway.
-
XNode enthusiast here. I've never really minded the fact that the LUT needs to be generated on first run but maybe I'm using these CRCs often many times in a call so the first one being on the slow side doesn't bother me. If you did go down the XNode route, the Poly used could still be specified at edit time. It could be a dialog prompt, similar to something like the Set Cluster Size on the Array to Cluster function where the user specifies something like the Poly, and reflective settings used. Then the code generates the LUT and uses that. You could have it update the icon of the XNode to show the Poly and reflective settings used too. You could still have an option of specifying the value at run-time, which would then need to be generated on first call. Again I personally don't think I'd go this route, but if you do you can check out my presentation here. It references this XNode Editor I made.
-
They said Unicode support was coming in the next 1 to 2 releases, two years ago. Priorities change, challenges happen, acquisitions go through, so I get that NI hasn't been as timely with their roadmap as they had hoped. Sarcasm aside I don't actually want to be too critical of NI and missing road map targets. They didn't have to publish it at all. I'm grateful they did publish it even if it is just to give an idea of what things they want to work on. Oh but I did look up the 2023 roadmap, and unicode support was changed to "Future Development".
-
If you want to just plop a window inside another one you can do that using some Windows API calls. Here is an example I made putting notepad on the front panel of a VI. https://forums.ni.com/t5/LabVIEW/How-to-run-an-exe-as-a-window-inside-a-VI/m-p/3113729#M893102 Also there isn't any DAQmx runtime license cost. If you built your application then the EXE runs without anything extra. There is a NI Vision runtime license cost so maybe that is what you are thinking? If you have a camera stream you can also view it by using VLC. VLC can view a camera stream, and then you can use an ActiveX container to get VLC on your front panel. USB cameras are a bit trickier but if you can get the stream to work in VLC, you can get it to work in LabVIEW. Here is an example of that. https://forums.ni.com/t5/Example-Code/VLC-scripting-in-LabVIEW/ta-p/3515450
-
Issues building applications in LabVIEW 2023 Q3
hooovahh replied to Mads's topic in Development Environment (IDE)
Bots won't procrastinate as well as I can. It truly is what makes me human. -
Issues building applications in LabVIEW 2023 Q3
hooovahh replied to Mads's topic in Development Environment (IDE)
Here is some info on what changes there are in the new release. https://www.ni.com/docs/en-US/bundle/upgrading-labview/page/labview-2024q1-changes.html This is not the major release of the year so there isn't too much to talk about. As for fixing the build issue I wouldn't hold your breath. I've already seen someone mention that the build for an lvlibp failed with error 1502. Cannot save a bad VI without its block diagram. But turning on debugging allowed it to build properly. -
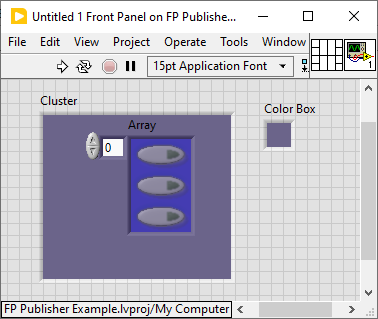
Get Boolean Image with Alpha - Get Array Element Background Color
hooovahh replied to hooovahh's topic in User Interface
Thanks Shaun but this doesn't quite work like I wanted. Maybe I didn't explain it well I can be long winded. Using your method this is what I get: In this case I actually want the somewhat blue looking color since that is what the boolean is in. The method suggested on NI's forums seems to work but is clunky but works. It hides the array element, label, caption, and index, then gets the image of the array control. Then gets the color of the pixel at the center of the image. With the element hidden it just shows the background which is the color blue in this case. As for why, I also ended up answering that on the NI forums. It is because I wanted to improve the web controlling VI code I uploaded a while ago here. Boolean Get Image Testing_sr.vi
-
Crosspost Okay so I have a front panel, with some boolean controls on it. I want to get the image of that control, and I want to put that image on top of other images. The background color of the other images is controllable, so if I use the Get Image invoke node method on the control reference, and just set the background color to what the background is of the pane that the boolean is on, then it is convincing enough. But I am having issues when these boolean controls are in other controls. If it is in a Cluster for instance I need to get the image of the background of the cluster. Clusters can be transparent so I need to keep getting the owner controls until I find one that isn't transparent. For bonus points I can also use the Create Mask VI to mask out a color, and I can use the color of the background element to get an even cleaner image of my boolean control. This is all a pain but doable. The issue I have is when my boolean is in an array. My main goal is to just get the boolean control, with the alpha or specific colors masked out. But when it comes to having booleans in arrays that is an issue. Any suggestions? Attached is a demo of what I mean. Set the enum then run it. For the scalar we just get the pane color. For clusters we get the color, then if it is transparent, keep going up until we find a color, or find the pane. But how do I handle the array? Thanks. Boolean Get Image Testing.vi
-
Issues building applications in LabVIEW 2023 Q3
hooovahh replied to Mads's topic in Development Environment (IDE)
We've been on 2022 Q3 64-bit for Windows and RT applications for a little over a year. Both the RT and Windows builds fail, but RT way more frequently. I try tracking down the offending VI, I try renaming classes back and forth, I've tried checkbox roulette in the build settings, and I've tried changing the private class data. The only thing that consistently works, is clearing the compile cache over and over until it builds. Then usually running from source fails to deploy and I clear it over and over until that works, which usually breaks the build again. My failure mode is different in that I don't see it hanging on initializing build. All that being said I'm glad to leave 32 bit behind. -
In general it is just best to make your cluster a type def (which links all the places that data is used, similar to a defined struct) and then unbundle and bundle the data as needed. Since LabVIEW is a strictly typed language, getting all data from something like a cluster means it will have to return them as variants. And then what do you do with that? Well you'll need the Variant to Data, and specify the type it should turn into. If it is the wrong type you get an error. So while you can get all elements of a cluster in an order, the usefulness of it might be limited. If you are doing something like taking a cluster then writing it to a file, or reading it from a file and you want it to be somewhat human readable, then this might be useful way of doing it. These functions already exist in the OpenG Variant Configuration File toolkit.
-
The Search function for this forum does not work very well
hooovahh replied to WMassey's topic in Site Feedback & Support
I can't answer that. But I can say there are many threads on the dark side, that also complain about searching over the years. And the conclusion there was the same. -
The Search function for this forum does not work very well
hooovahh replied to WMassey's topic in Site Feedback & Support
I also had a hard time finding this in Google, which is a better search tool than the one built into the forums. Invision is the tool that the forums is built off of and the search comes with that forum level software. Occasionally the site admin will go through a migration process to the new versions adding features and it is possible search has been improved. But since Google is the defacto search tool they probably don't see much value in investing in better search tools. Sorry I don't have a good answer for this. -
-
I knew of the malaphor only because my wife does it all the time, but then insists her phrase is the way people always say it. When you are up a creek, you are without a paddle. A bird in the hand catches bees with honey. Does the pope crap in the woods?
-
Oh yeah I'm not trying to convince anyone, I just was putting it out there in case others aren't aware of this style of messaging. I prefer the design I described it because it makes life easier on the developer using the API, at the expense of extra work on the architect making it.