hooovahh
-
Posts
3,477 -
Joined
-
Last visited
-
Days Won
299
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by hooovahh
-
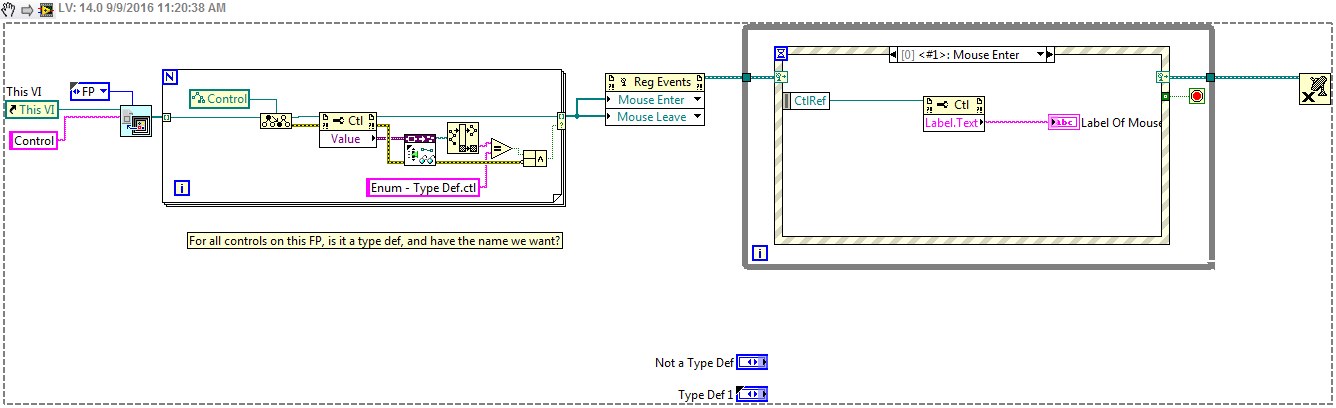
Sure, there's a couple of options but I think what can be done is to on startup, get all control references, then find which ones are type defs, and then get the path to those type defs, and if the path is what you expect, to register for those control references. Attached is a demo. Find Type Def Demo.zip

-
I was always cautious when using the aggregate compare mode because I didn't fully understand what it meant. Reading through the documentation it seems it should work the way you described.
-

Strange Behavior of Scales for a AI Voltage
hooovahh replied to Gan Uesli Starling's topic in LabVIEW General
Does it behave this way on other computers? Maybe resetting MAX config? Not quite sure really but if you tried another piece of hardware and it behaves the same it would make me think it is not the hardware, but some software or config on that PC. What kind of scale is used? Is it a linear, table, mapped range, etc? I guess it probably doesn't matter but I'd try to see if I can make any scale work on the full range. -
A quick google search shows several tools for removing passwords from zips. No idea if these actually work. Alternatively there are tools like this one which appear to brute force the password for you. http://www.isunshare.com/blog/how-to-remove-password-from-zip-file/
-
"This contract engineer discovered the secret to LabVIEW programming, and NI is furious."
-
Action Engines... are we still using these?
hooovahh replied to Neil Pate's topic in Application Design & Architecture
To answer the primary question of the thread, yes I do still use them but kinda rarely. For each medium to large sized project I'd say I probably create 2, and there are probably another 3 or 4 buried in reuse library function, used in the project. The reuse functions I can make a decent argument to make them classes, for the project specific ones, I could say the simplicity, and ease of use for other developers makes me want to leave them alone. In most of my cases I don't see action engines working well because there maybe a time when I intend on doing some kind of periodic function, like checking status and reporting it every 100ms, and an action engine is a blocking, synchronous call. So I usually end up making a separate asynchronous module (actor) so that in the future if I need to do some task periodically it can be done there. The calls to this will still look like the action engine, but with a message to the actor, and then a message that is in the reply coming back so the call will still be synchronous, but asynchronous tasks can take place too. It's rare that I can convince myself that an interaction with some private data, will never need this feature. -
Yup totally agree. Array stuff needs to be evaluated. Many improvements could be made from inlining, to the new conditional, and concatenating terminals in 2012. Several things could be removed from the palette too to use the native functions if they have replacing functionality. Things like Strip File Extension exist on the File I/O palette, but don't quite cover all of the same functions. Same with some functions on the LabVIEW Data palette, and the newer variant palette.
-
The LabVIEW compiler is smart, and it knows that if you are doing some operation that doesn't use the outputs (and a few other key determinators) then it won't even execute the code at all. Your case 11 isn't actually being executed. This is dead code elimination and constant folding. Updating controls is an asynchronous process, and adds a lot of jitter to measuring timing like this. That's one reason why you'll notice my code doesn't update any of the controls until after all timing values have been taken. To get a more accurate measurement you should not update or read from any control terminals inside the sequence structure. I highly recommend watching some of these NI Week videos from this last NI Week where Ed and Christian talk about performance measuring and benchmarking. https://decibel.ni.com/content/docs/DOC-48493
-
You are a braver man than I. I wouldn't go through the registration, I'd be concerned NI was going to charge me for an event that took place in the past. Thanks for being your guinea pig.
-
Because you're doing all the operations in parallel, this is a poor test and should be only doing one thing at a time. Also you should disable debugging, and automatic error handling. I also think your time is too small to measure well enough. Maybe try a larger sample size. Here is a speed test I did on the writing of the new IPE and it shows improvements. https://forums.ni.com/t5/LabVIEW/Correct-way-of-using-the-Variant-Get-Replace-In-Place-Element/m-p/3334502#M978560
-
I think 20%-25% might be over estimating it a bit. 9% XP, 1% Vista, and sure 50% Windows 7, but if they are connected to the internet it should be SP1. But it's hard to say, especially in the test system fields, where older machines are more common than consumer devices, and being isolated from the internet is more common than a consumer PC. Still I consider myself up on the latest updates of NI and LabVIEW and this was the first I'd heard about it. "Not being clear and upfront" is an understatement. BTW that's a neat site.
-
Sensational title much? It still supports Windows 7 SP1, I've built EXE in LabVIEW 2016 32-bit on Windows 7 SP1 x64 without any issue. I've also built applications in LabVIEW 2015 SP1 32-bit, that have 16.0 dependency drivers, and that builds and deploys to Windows 7 SP1 x64 without any issue. As mentioned in that thread dropping OS support should be made more obvious, but this is really Windows 7 SP0 and older that official support is dropped for.
-
Finding Controls in LV executable
hooovahh replied to Voklaif's topic in Remote Control, Monitoring and the Internet
Okay here's the solution I did that seems to work. You need to make the window the front and focused so that the key presses go into that window. This can be done by setting the Z order. Using this API there is a function called Move Window To Top and you just need to give it the window title name. http://www.ni.com/example/29935/en/ Then I used a this API for sending key presses like Alt and then arrow keys (with delays in between) https://decibel.ni.com/content/docs/DOC-15310- 13 replies
-
- 1
-

-
- executable
- control
- (and 1 more)
-
Because the XNode features of LabVIEW require a special license by NI, these properties and methods won't be listed on the XNode, or XNode Library class, but these functions do work. I made a post about this a while ago, and showed how to create these functions in vanilla LabVIEW if you use scripting, or use the QuickDrop function and know the name of the property or method you want. The code I posted also can create a new VI, or place the hidden property or method in your clipboard. I also posted a VI with all the properties and methods that scripting can make which you can use and copy into a VI and use.
-
Finding Controls in LV executable
hooovahh replied to Voklaif's topic in Remote Control, Monitoring and the Internet
Nope, as far as I know there is no way to programatically control this. There are a few private methods that have "Not Implemented" in them and mention Mercury and Merlot branches. This makes me think that at one point NI wanted this functionality, maybe for themselves but since it hasn't be finished in the several years that I've seen this private function I'd guess NI found another way to do what they wanted. If you have the source maybe you could make some hidden controls that VI Server can interact with but the user can't. Like if you have a File >> Exit function, just also have a hidden Exit button that can be invoked which triggers the same code execution. Of course this might be duplicating some of the work you already have. Another option for these menus might be keyboard simulation. If you press Alt+F it opens the File menu, then you could press Down arrow until the desired menu is selected. I've wanted this function off and on for a few years so I've made an idea exchange item here. -
Finding Controls in LV executable
hooovahh replied to Voklaif's topic in Remote Control, Monitoring and the Internet
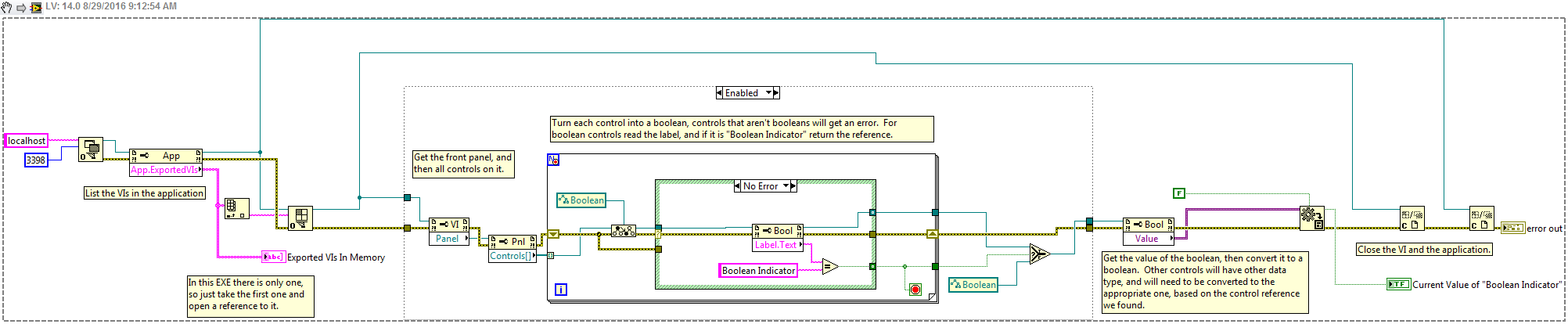
Sure thing, sorry I forgot a couple of other details. To enable VI Server access in an EXE you need to add a few lines of text to the built EXE INI file. In your case this is the Executable.ini file in the Executable folder. This INI gets rebuild every time a new build is made, so you will either want to edit this every time, edit it programatically using a Post Build VI, or you can actually specify the INI to use in the application builder settings under Advanced >> Use Custom Configuration File. In this case you can add this text manually just so you can see it working. server.tcp.enabled=True server.tcp.access="+localhost" server.tcp.port=3398 This enables the server, enables it for localhost access, and sets the port to 3398. This can be any number but needs to be unique. Then in the Open Application Reference you specify the port as 3398, and the machine as localhost. Once you have done this, run the EXE, run your VI, and you should be able to do things like list the Exported VIs, open references to those VIs, and get references to the controls on the front panel. Attached is a snippet back saved to 2014 that will read the Boolean Indicator value.
-
Will the steps mentioned also force LabVIEW to recognize the SO file as a dependency, and include it any builds? That's one issue I thought I remember having with Windows built EXE, when specifying the DLL path by the CLN input.
-
If you are using VIPM this is already done for you. To be able to install a package means that the VI Server business is already working. As for how to know what port is what version of LabVIEW, you can look at the LabVIEW.ini to see what port goes to which, and you can read the Windows registry to find what versions of LabVIEW are installed, and the path to the LabVIEW.exe and LabVIEW.ini files. This is all done in the source of the LabVIEW Tray Launcher I linked to earlier. Glad you were able to find a solution.
-
I literally shaved the day before. I can grow a mean beard, but I don't travel with any trimming equipment. So I shave on Sunday, and by Friday I'm looking pretty rough, and it's not just from all the Shiner Bocks. Also does everyone think they look dorky in pictures or is it just me?
-
The command line option only works if you know no other versions of LabVIEW are currently open. LabVIEW communicates over DDE to other versions of LabVIEW, and that is why some times you'll see LabVIEW try to open the wrong VI in the wrong version. If you double click a VI, or open it over the command line, it may choose to open it in the wrong version even if the command line specified which version to open it with. Here is a post I made on it a while ago and many other applications (like VIPM launching LabVIEW, and LabVIEW version selection tools) suffer from this issue. The work around is using the technique I've mentioned. But if you can ensure no versions of LabVIEW are running, maybe by closing them all, making a VI that runs when opened is much easier.
-
Well it is possible but a pain. Is there a minimum version of LabVIEW you want to support? I think that function came around in 8.2 or so. What I'd suggest doing is create a VI with just that function in it, and save it in the lowest version of LabVIEW you want to support. Then ensure each version of LabVIEW installed is configured to use VI Server from localhost (basically make sure VIPM can connect to each version). Then you can have a VI that opens a connection to each version of LabVIEW installed using the Open Application Reference function, then use the Open VI Reference passing in the path to the VI you saved earlier and using VI Server run it. I created a tool a while ago that sits in your system tray and allows you to launch any version of LabVIEW installed. It also allows you to abort all VIs running in all versions of LabVIEW and it uses this technique by having a VI saved in an older version of LabVIEW and embedded in another VI, and then runs this VI in every version of LabVIEW installed. The source for this can be found here with the topic on LAVA here.
-
Any improvements you can make are appreciated. I clearly don't know much about the web page side of things, I mostly was able to get done what I did with a lot of googling. Plenty of room for improvements, but I am using it on a real project and it meets my needs. As for the future of LabVIEW are you talking about the Tech Preview? http://www.ni.com/en-us/support/software-technology-preview.html WebVIs and porting the runtime engine to Java Script are things that have been announced, but the timelines mentioned (or not mentioned) makes me think it will be business as usual for a while longer. I'm not saying it isn't cool, and I'm not saying it isn't going to replace, or deprecate some of the work we are doing here, but I am saying you can use the code posted here today for free to create interactive webpages, and who knows when you'll be able to do the same with native NI technologies.
-
The "easy" solution as far as I know is the one already described, where you can place a transparent path control on top of your graph and set it to visible when your VI is not active (or mouse leaves the window, I'm not quite sure what works best). Then when you drop a file from explorer it will be dropped on the transparent path control, which generates the Value Change event, and from there you can get the path of the file dropped. It is not ideal, and if there isn't an idea on the Idea Exchange for this to be improved yet, I suggest making one, I'd vote for it. I wouldn't recommend using the Windows Queue API. With the advent of x64 versions of Windows several of those functions don't work, or will work most of the time, but won't work some times.
-
Put your LabVIEW in the Tray -- Once and for all
hooovahh replied to Stinus Olsen's topic in Code In-Development
Set the front panel window to the window to hidden using the Invoke Node on the VI class (Front Panel >> Open - State). And in your built EXE you may need the HideRootWindow = TRUE in the INI of the application. My LabVIEW Tray Launcher uses this code to be minimized to the system tray, you can checkout the source here. -
See I didn't realize this was a limitation. In my situation LabVIEW Libraries are the main container for code modules, not classes and this appears to be a limitation of LabVIEW classes which is why I've never seen this. So in my situation I can open both Windows Main, and RT Main VIs at once, and run them independently, or develop in either context with few issues (one being you need to sync code after making changes). Here is the article put out by NI (which was found in the idea exchange) that describes the issue with classes.