Leaderboard




Popular Content
Showing content with the highest reputation since 07/14/2024 in Posts
-
Hello all. The last 72 hours we've had some issues with spam bots taking over the forums, pretty aggressively. As a result new account creation has been temporarily disabled. Thanks to all those using the report feature. I don't read every post but I do read every new thread title and you are very helpful in spotting issues. There might be some forum upgrades taking place soon to help combat this issue. After which the new user creation will be turned back on. Nothing is scheduled yet but this is meant to be a heads up that the forums might have some down time soon and it is to be expected. Thanks for your patients.7 points
-
Hello. I am not a bot... I'm planning on taking the site offline this weekend to perform long overdue upgrades and to investigate ways to curb the spam attacks. Thanks to everyone for all the help cleaning up the forums. Hopefully I can find a solution and we can get back to the usual next week.7 points
-
A customer asked me to create a powerpoint explaining the advantages of LabVIEW. While putting together the practical rationales, just for grins I asked Chatgpt to create a presentation explaining the philosophy of LabVIEW in a Zen sort of way. Here is what it came up with. Zen_of_LabVIEW.pdf6 points
-
A is for Argumentative, right?5 points
-
@hooovahh Is still weeding out the spam. I think he's in the eastern US time zone so he's 3 hrs. ahead of me ☺️. Much thanks to him. But I'm also improving the filters. Unfortunately, I think there are some sleeper accounts that were created before the changes that are starting to post. But, yes, I think it's getting much better. BTW, I just discovered that if you ctrl+right click a posted image you can set its' size! neat.
 5 points
5 points -
I noticed that this morning. However, I'm adjusting some knobs behind the scenes. There will still be some that get through and I will be monitoring the forums for the next few weeks to optimize the settings.5 points
-
I spent a long time online with YouTube support and finally got to the bottom of it. The Channel is back, and all the links work!4 points
-
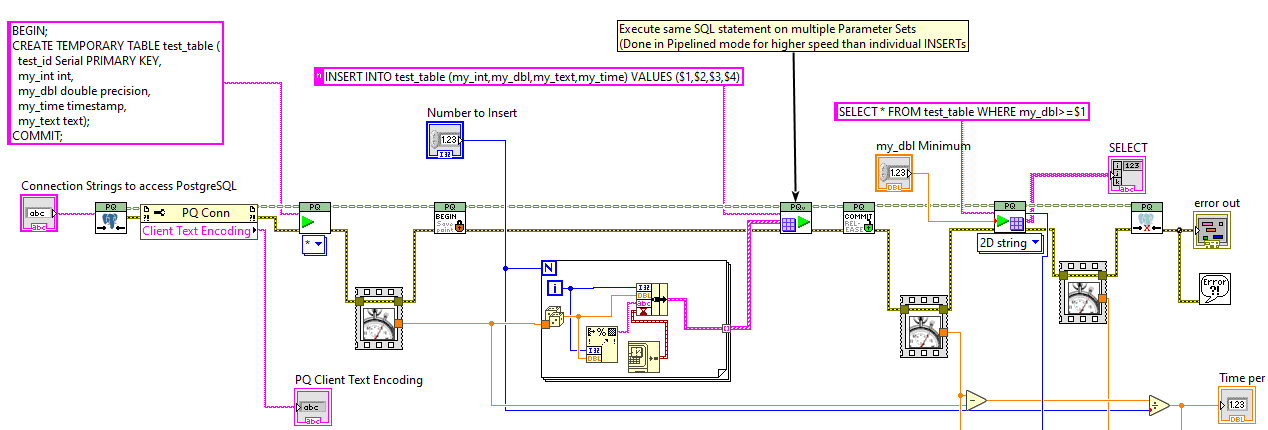
0.6.0 version now on VIPM: https://www.vipm.io/package/jdp_science_postgresql/ This involves significant improvements, as well as Examples that work with a public postgres server (and thus work without needing Postgres installed). I am hoping this is close to a 1.0 version.
4 points
-
Says the account with "AI" right in the name. Hiding in plain sight! eta: In fact, you can't even pronounce it without saying "AI" - "A I va lee oh tis". Well, I can't, anyway...4 points
-
I've had to disable all external services used to login to LAVA such as Google, Facebook etc. If you were using these services and now cannot login. Please send an email to s u p p o r t (at) l a v a g (dot) o r g with your login email address and I will reset your password so you can use the built-in login method. This is a permanent change moving forward. Sorry for the inconvenience.4 points
-
Anyone else getting their popcorn? I cannot predict the future. And worrying about things I can't control gives me anxiety. So I'm just going to chug along as best as I can. My boss likes the work I do, and I like my job. I'll be mindful of industry changes. But at the moment I am not pivoting away from LabVIEW or NI if I can't help it.4 points
-
Many years ago I made a demo for myself on how to drag and drop clones of a graph. I wanted to show a transparent picture of the new graph window as soon as the drag started, to give the user immediate feedback of what the drag does and the window to be placed exactly where it is wanted. I think I found inspiration for that on ni.com or here back then, but now I cannot find my old demo, nor the examples that inspired me back then. Now I have an application where I want to spawn trends of a tag if you drag the tag out of listbox and I had to remake the code...(see video below). At first I tried to use mouse events to position the window, but I was unable to get a smooth movement that way. I searched the web for similar solutions and found one that used the Input device API to read mouse positions to move a window without a title and that seemed to be much smoother. The first demo I made for myself is attached here (run the demo and drag from the list...). It lacks a way to cancel the drag though; Once you start the drag you have a clone no matter what. dragtrends.mp4 Has anyone else made a similar feature? Perhaps where cancelling is handled too, and/or with a more generic design / framework? Drag window out of listbox - Saved in LV2018.zip3 points
-
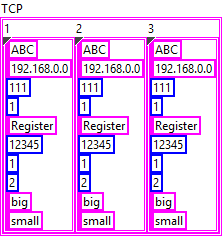
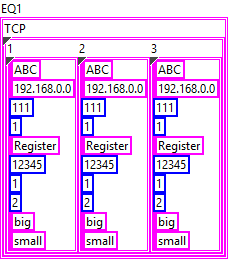
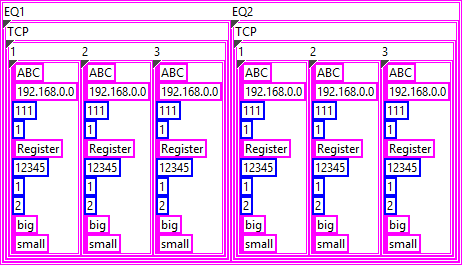
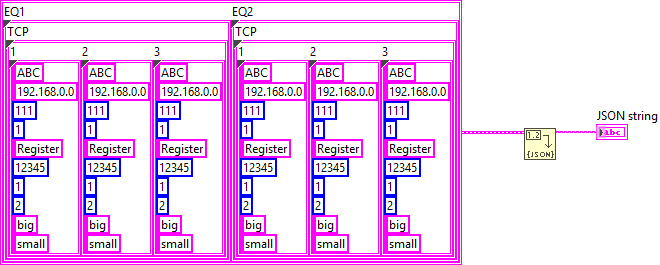
The examples you provide are invalid JSON, which makes it difficult to understand what you are actually trying to do. In your VI, the input data is a 2D array of string but the JSON output is completely different. Your first step should be to define the types you need to produce the expected JSON output. Afterwards you can map your input data to the output data and simply convert it to JSON. The structure of the inner-most object in your JSON appears to be the following: { "Type":"ABC", "IP":"192.168.0.0", "Port":111, "Still":1, "Register":"Register", "Address":12345, "SizeLength":1, "FET":2, "Size":"big", "Conversion":"small" } In LabVIEW, this can be represented by a cluster: When you convert this cluster to JSON, you'll get the output above. Now, the next level of your structure is a bit strange but can be solved in a similar manner. I assume that "1", "2", and "3" are instances of the object above: { "1": {}, "2": {}, "3": {} } So essentially, this is a cluster containing clusters: The approach for the next level is practically the same: { "TCP": {} } And finally, there can be multiple instances of that, which, again, works the same: { "EQ1": {}, "EQ2": {} } This is the final form as far as I can tell. Now you can use either JSONtext or LabVIEW's built-in Flatten To JSON function to convert it to JSON {"EQ1":{"TCP":{"1":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"},"2":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"},"3":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"}}},"EQ2":{"TCP":{"1":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"},"2":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"},"3":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"}}}} The mapping of your input data should be straight forward.
3 points
-
In a previous life, I used to teach a CLD level class using this book, and enjoyed it a lot -- Some of it is certainly outdated at this point, but I think it still has a lot of solid info / strategies in it. I've attached the files as a .zip file to this post. Good luck! Effective LabVIEW Programming Files.zip3 points
-
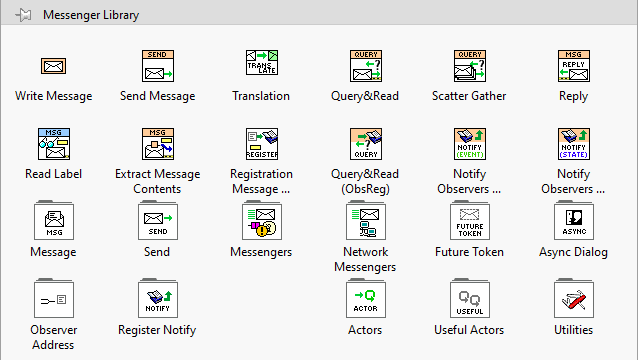
I have put some effort into improving the VI icons in Messenger Library, in hopes of making things clearer. I have particularly been trying to get rid of the magnifying glass icon, which was standing in for too many concepts. I have also tried to improve the Palettes by putting the standard VIs (that one would most commonly use) in the root-level palette: The 2.0 version also introduces Malleable API methods (the orange-coloured ones), which make code cleaner. If anyone could spare some time, it would help me to have feedback. Especially from people who have not used Messenger Library before, so I can get an idea if the key concepts come across. New 2.1.3 version is available here: https://forums.ni.com/t5/JDP-Science-Tools/New-icons-for-Messenger-Library/m-p/4412550#M192
3 points
-
Yes you can. The official form is at https://www.ni.com/en/forms/perpetual-software-licenses-labview.html Some things to keep in mind: There is a current promotion (valid till the end of December 2024) where those who used to have an SSP can renew it today as if the SSP never expired in the first place. That means you can get the latest version of LabVIEW, under a perpetual license, at a discounted price (compared to buying it "new"): https://forums.ni.com/t5/LabVIEW/LabVIEW-subscription-model-for-2022/m-p/4398958#M1296289 Quotes/sales are now handled by external distributors, rather than Emerson/NI. Lots of people have reported that they didn't get a response to their quote requests, or didn't get the expected discount applied. If that's the case, message Ahmed Eisawy, the Director of Test Software Commercialization (who wrote the forum post in my link above) and he'll get it sorted out.3 points
-
The 'Arrange VI Window' Quick Drop keyboard shortcut does this. With the diagram open, Press Ctrl-Space, then once Quick Drop appears, press Ctrl-F. If you want to look at the code that accomplishes this, see here... it should be a good resource for writing your own tool: [LabVIEW 20xx]\resource\dialog\QuickDrop\plugins\_Arrange VIWin SubVIs\Arrange VIWin - Arrange BD.vi3 points
-
Because of a thread over on the darkside, I got the motivation to improve this code, and include the Google Material icons in it. I posted the package over on VIPM.IO. This uses the native 2D picture control for displaying icons like I wanted. It still requires Windows due to how icons are resized, but maybe that could be worked around if there is interest. https://www.vipm.io/package/hooovahh_boolean_vector_controls/ Install the package and its dependencies and you'll have a Tools >> Hooovahh >> Boolean Control Creation... Once ran it will start trying to display all the icons the toolkit installed. In the background it will be converting the vector images to 56x56 PNGs to be able to display them in the window. I tried being smart and having it prioritize icons that you scrolled to, but I honestly don't know how well it works. It basically takes about a minute after first launching it to have all of its icons displayed properly. You can use the tool during that minute but not all the icons will be available yet. From that point on you can scroll around and resize the window and it should work as expected, just a little bit slow at times. There is a single constant on the block diagram where you can change the icon side. At one point I had icon size be a control on the front panel but since it took about a minute to process all the images for every change I just left it. Some of the icons have multiple versions. If you left click on an icon and a window pops up you can pick from what version of that icon you'd like to use. Then create a control using that icon. You can theoretically put your own EMF files in the folder with the rest but at the moment it doesn't scan for new files since it is relatively slow to find all icons on every launch. What I'm saying is compromises had to be made. Maybe I could have a separate program that gets ran in the Post Install VI that starts processing the icons right away in parallel. That way the tool might be done processing icons by the time the user launches it for the first time. I did use the Post Install and Post Uninstall to do extra work since there are so many individual files. Normally you'd have VIPM handle the files but it took a long time. So the package just installs a Zip, and the Post Install will unzip them. This also means Post Uninstall needs to delete the extracted files. Not ideal but the install time was much longer otherwise.3 points
-
Oh yeah it sucks. I do what I can, I contact the admin when there are issues I can't resolve. I appreciate your patients.3 points
-
It does put more spam in my inbox. Honestly with how frequent things are I'd say make a single report of any kind, then I'll review all the posts by the newest users. Banning a user deletes all of their stuff, so just one report to get my attention is enough.3 points
-
3 points
-
Thanks for cleaning up the mess. Let us know if we can help. In the meantime we'll provide moral support in the forms of memes
3 points
-
You guys are on point with the meme. So Snippets in general still work for me. I just tested one from NI's site and it was fine without needing to run as admin. That being said I know there were issues with LAVA and those might still exist. If I go to this NI post: https://forums.ni.com/t5/LabVIEW/Serial-port-number-savings-in-ini-file-executable-with/m-p/3957698#M1126478 There is a snippet. If I drag that pictures to LabVIEW it doesn't work. If I right click the image and choose open in new tab, then drag that image, it also doesn't work...BUT If I take the URL which was this: https://forums.ni.com/t5/image/serverpage/image-id/251299iAB15C965246CD61E/image-size/large?v=v2&px=999 and change it to this: https://forums.ni.com/t5/image/serverpage/image-id/251299iAB15C965246CD61E Then drag that to LabVIEW it does work.3 points
-
LabVIEW has been my forte throughout my quarter-century or so of employment. It's what has made me most valuable to present and past employers, (and is what I enjoy doing the most). My only real concern at this point would be in finding another job within my purview, that wouldn't require me to relocate my family, should I not be able to continue working for my current employer. In the current state of things, I'm not concerned - but often wonder if I should be.3 points
-
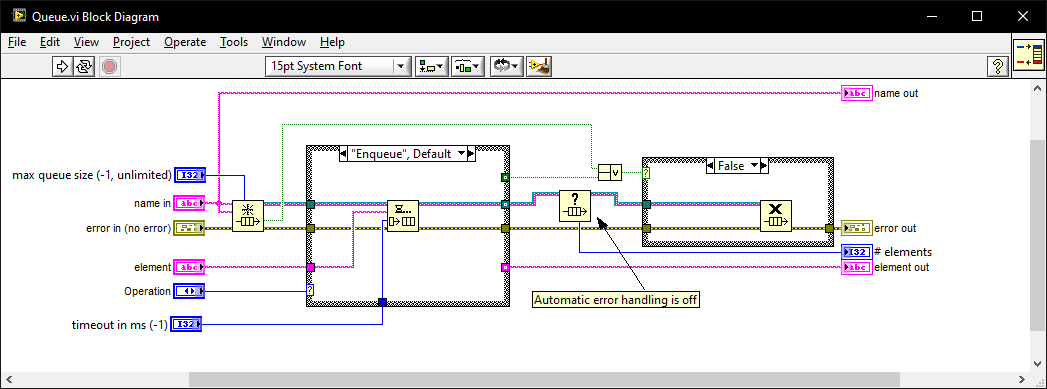
I once went for an interview where they gave me a coding test and asked me to modify it. It was a very long time ago so I don't remember the exact modification they wanted (nothing to do with memory leaks) but I do remember the obtain queue and read queue inside a while loop with the release queue outside. I asked if they wanted me to also fix the memory leak as well as the modifications and they were a little puzzled until I explained what you have just said. I must have seen (and fixed) this while-loop bug-pattern a thousand times since then in various code bases. I also created this VI which I generally use instead of the primitives as it intialises on first call, can be called from anywhere, and prevents most foot-shooting by rolling them all into a single VI and ensuring all references but 1 are closed after use. Queue.vi
2 points
-
Those aren't typo's and errors. They are tests to see if we are paying attention.2 points
-
In the past I have used the IMAQ drivers for getting the image, which on its own does not require any additional runtime license. It is one of those lesser known secrets that acquiring and saving the image is free, but any of the useful tools have a development, and deployment license associated with it. I've also had mild success with leveraging VLC. Here is the library I used in the past, and here is another one I haven't used but looks promising. With these you can have a live stream of a camera as long as VLC can talk to it, and then pretty easily save snapshots. EDIT: The NI software for getting images through IMAQ for free is called "NI Vision Common Resources". This LAVA thread is where I first learned about it.2 points
-
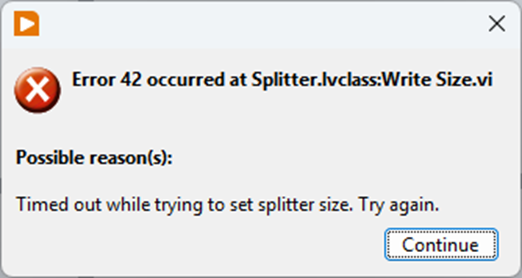
Just to share how I got around this: By deleting 1 front panel item at a time I found that one single control was causing PaneRelief to crash; an XY graph. Setting it temporarily to not scale and replacing it with a standard XY graph (the one I had had some colours set to transparent etc) was enough to avoid having PaneRelief crash LabVIEW, but it would now just present a timeout error: I found a way arund this too though: the VI in question was member of a DQMH lvlib that probably added a lot of complexity for PaneRelief. With a copy saved as a non-member it worked: I could replace the graph, edit the splitters with PaneRelief without the timeout error (even setting the size to 0), then copy back the original graph replacing the temporary one, and finally move the copy back into the lvlib and swap it with the original. Voila! What a Relief... 😉 I probably have to repeat this whole ordeal if I ever need to readjust the splitters in that VI with PaneRelief though 😮
2 points
-
I put a temporary ban on inserting external links in posts (except from a safe list). We'll see what affect it has.2 points
-
This is the modern 2020's equivalent of "works for me".2 points
-
Your reporting of spam is helpful. And just like you are doing one report per user is enough since I ban the user and all their posts are deleted. If spam gets too frequent I notify Michael and he tweaks dials behind the scene to try to help. This might be by looking at and temporarily banning new accounts from IP blocks, countries, or banning key words in posts. He also will upgrade the forum's platform tools occasionally and it gets better at detecting and rejecting spam.2 points
-
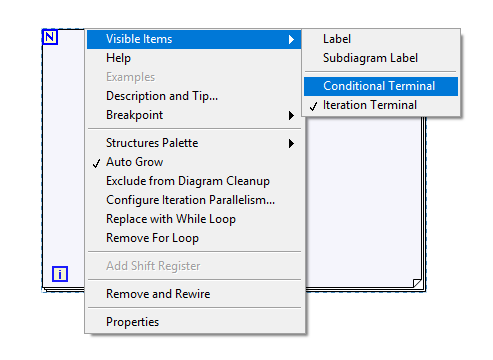
Apparently they moved it under Visible Items Edit: This also affects other types of structures.
2 points
-
Well, there are two aspects. The first is the technical one from hackers diving into the software and unhiding things that NI felt were not ready for prime time, to complicated for simple users, or possibly also to powerful. The main reason definitely always is however: if we release that, we have to spend a lot more effort to make it a finished feature (a feature for internal use where you can tell your users: "sorry that was not meant to be used in the way you just tried") is maybe 10 - 20% of development time than the finished feature for public use. There is also support required. That costs money in terms of substantial extra development, end user quality documentation (a simple notepad file doesn't cut it), maintenance and fixing things if something does not match the documented behaviour. And yes I'm aware they don't always fix bugs immediately (or ever) but the premise is, that releasing a feature causes a lot of additional costs and obligations, if you want to or not. The other aspect is, if someone who is an active partner and has active contacts with various people at NI, he is infinitely more likely to be able to influence decisions at NI than the greatest hacker doing his thing in his attic and never talking with anyone from NI. In that sense it is very likely that Jim having talked with a few people at NI has done a lot more to make NI release this feature eventually, than 20 hackers throwing every single "secret" about this feature on the street. In that sense the term "forcing NI's hands" is maybe a bit inaccurate. He didn't force them, but led them to see the light! Not out of pure selfless love, but to be able to officially use that feature for himself. The according Right-Click framework was a proof of concept to see how this feature can be used and mainly an example to other users how it can be used, and indeed once it worked it had fulfilled its purpose. That it was not maintained afterwards is not specifically JKI's fault. It is open source, so anyone could have picked up the baton, if they felt it was so valuable for them. The problem with many libraries is actually, if they are not open source and free, many complain about that, if it is open source and/or free, they still expect full support for it! In that sense I have seen a nice little remark recently:
2 points
-
Well, you are missing some important details in "The story of how this came about". So maybe indeed "it is worth a post of its own". It was LabVIEW 7.0 where they forgot to put a password on one of the VIs shipped with LabVIEW. And that VI had some node(s) on its block diagram including, I think, the BD reference property for the VI class. The community indeed got excited. But what did NI do? They tried to hide everything again in LabVIEW 7.1! I made a joke then that "our mother" NI must had had a PMS so she put the most interesting toys on a top shelf. So I made a"ladder" for us, kids, to get to them again and called it hviewlabs was me then, because that was a name of my company I used to sell my LabHSM Toolkit, an actor framework with actors controlled by hierarchical state machines (statecharts), long before the Statechart toolkit by NI, "THE Actor Framework", DQMH, and even before LVOOP. After PJM_Labview has published his private class generator http://forums.lavag.org/index.php?showtopic=307&hl=# and class hierarchies http://forums.lavag.org/index.php?showtopic=2161# and http://forums.lavag.org/index.php?showtopic=314&hl=hierarchy# (neither topic is available anymore) it became clear how to get access to private classes, properties and methods. However, it wasn't convenient enough. My PMS Assistant made it really easy. It gave back the access to those features to a much wider community of LabVIEW enthusiasts As you can see from the PMS topic discussion, by that time brian175 already had made his DataAct Class Browser. And he got really excited about the possibility not only browse but also to actually create objects, property and method nodes with the properties and method NI didn't want the users to see. By April of the same 2006 he figured out object creation too and incorporated the capabilities of PMS Assistant into DataAct Class Browser. At that point, I guess, NI decided that "the cat is out of the bag" and there is no point to resist. Nevertheless even after VI Scripting was made released by NI some classes, and even some properties and methods of public classes remain hidden even in LabVIEW 2024. I wonder why DataAct Class Browser is no longer available (as of January 2025) as well as original findings by PJM_Labview even here, on LavaG. Did NI "politely asked" admins to remove all that and just forgot about my PMS Assistant?2 points
-
Unfortunately, many of those are bots. I've disable user:pages long time ago, because of the spam. If there's anyone that deserves a lot of credit lately it's @LogMAN. He's doing amazing work cleaning up the pages and adding/editing content. There's a push recently from NI to support the Wiki and promote its use to the broader community and within NI internally as well. So, we should see more traffic and more activity than usual, which is great. This is one of the reasons for the recent stability updates. I encourage everyone here on LAVA to find whatever LabVIEW topic they are passionate about and start adding some pages or even fleshing out some existing content that needs improvement. One way to start would be to find some information that you always wish NI had easily available on their website but could never get easy access to. Then create that on the Wiki.2 points
-
I have had this in my toolbox for a long time to do what you are asking. It is part of a QuickDrop plugin I made to "fix up" a VI, similar to Darren's Nattify plugin. Size Diagram Window.vi2 points
-
I have published a 0.3.1 package on VIPM.io with Antoine's changes (LabVIEW 2017). Then I've accepted your Pull Requests and published a 0.4.0 version as well (LabVIEW 2019): https://www.vipm.io/package/jdp_science_postgresql/2 points
-
I was relieved to login this morning and not see pages worth of spam when I clicked on the "Unread Content" link. Awesome job to all!2 points
-
2 points
-
Spoiler: don't do that on the weekend 😭
2 points
-
Answered: https://www.ni.com/docs/en-US/bundle/labview/page/understanding-url-mappings-and-query-strings-in-web-services-real-time-windows.html?srsltid=AfmBOopGM5Aom7rH3ofPKKWSHNo1Ye6RrmFtwG6Zh_QJFtInuTGsTOJO Future me (or you) - simply set the Web Service Properties -> HTTP Method VI settings -> URL Mapping to something such as <base url>/path1/path2/:variable1/path3/:variable2 ) and variable1 and variable2 will be passed into the VI as a path parameter rather than the query parameter (eg: <base url>/path1/path2/path3/?variable1=___&variable2=_____ )2 points
-
Skip the PXI DMM, FG and scope cards, they are expensive and usually do not perform as well as standard instruments. Instead pick whatever instrument fits your requirement with a modern interface (LXI, USB) and a rack kit. Example Keysight 33465A vs NI PXI DMM. The NI card is ~4000USD, with slightly worse performance. Definitely use the PXI for massive multiplexers, DAQs, Digital interfaces (CAN, I2C etc) and GPIO. Also, take into account that PXI is being phased out in favor of PXIe. Some of NI PXI muxes are EOL, without an alternative.2 points
-
Yes that function is used for generating hashes in LabVIEW itself for various things including password protection. It was never meant for hashing huge buffers and is basically the standard Open Source code for MD5 hashing that floats on the internet for as long as the internet exists. It is similar to what the OpenSSL code would do, although OpenSSL is likely a little more optimized/streamlined. This function exists in LabVIEW since about at least 5.0 or thereabout and likely has never been looked at again since, other than use it. You could of course call it, and dig in the LabVIEW attic with its many rusty nails, but why? Just because you can does not mean you should! 🙂 If you absolutely insist you might try yourself. This is the prototype: MgErr GetMD5Digest(LStrHandle message, LStrHandle digest);2 points
-
Thanks for keeping up the fight! I don't even want to imagine your inbox on a Monday...2 points
-
I do note that in the list of currently logged in users there are regularly users whose name looks suspicious and when checking them out they have supposedly 20, 40 or more posts but no current activity. Is this part of keeping them in the dark after banning them? Let them log in anyways and also maybe even create posts that are then consequently immediately /dev/nulled? I really wish Michael could throw that switch to require moderator approval of the first 3 or so post for every new user! It's not so nice to login on LavaG and find no new post by anyone as has been the case regularly lately, but I prefer that many times above finding a whole list of spam posts about call girls, drugs, counterfeit money and secret societies that are waiting for nothing else than to heap money over anyone who is willing to sell their soul to them.2 points
-
Also just so others know, you don't have to report every post and message by a user. When I ban an account it deletes all of their content so just bringing attention to one of the spam posts is good enough to trigger the manual intervention.2 points
-
I actually never bothered to click on that and simply assumed that it does the same as selecting the image 😅 Yes, this has been known for a long time. You wouldn't believe who reported it first 😄2 points
-
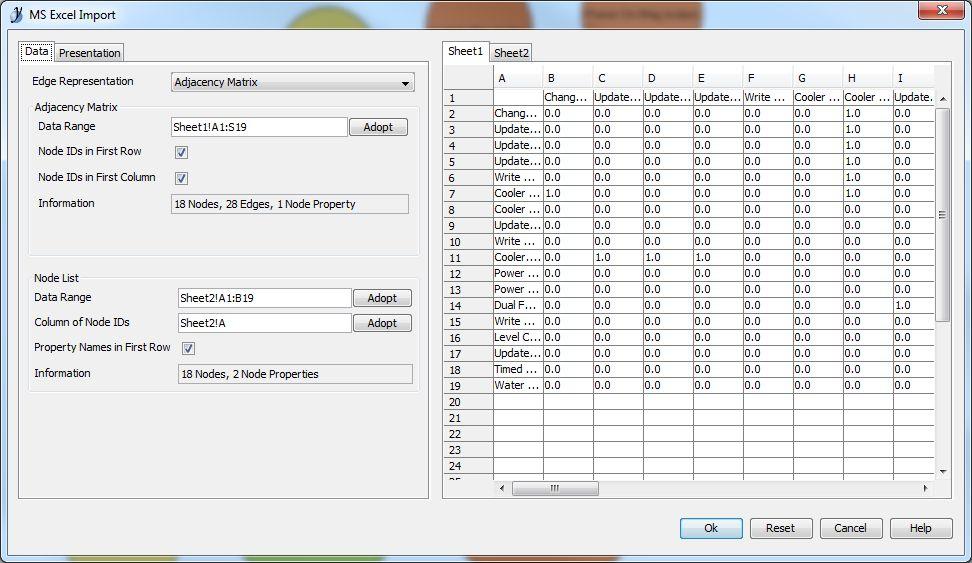
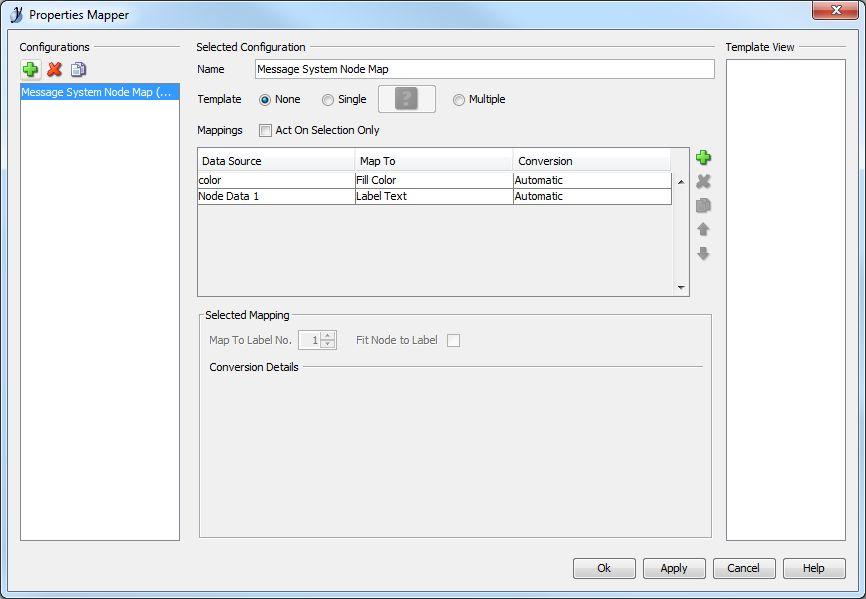
Due to the overwhelming response I put together a solution using some free online tools. First, you will need a tool called yEd. (http://www.yworks.com/en/products_yed_about.html) This is a very nice free tool for generating various graphs and charts. Next you will need Excel because that is the file type yEd uses to import an adjacency matrix. Last, you will need some LV code to generate an adjacency matrix and node property list from a project. Here is one I made for Actor Framework. Please excuse the poor code layout as I hacked this together quickly. Generate AF Node Map Data.vi (Note: this can easily be adapted to other message systems. The only change would be the mapping for the color properties to the appropriate parent classes. Open the VI, choose your target project and your destination xlsx file and run it! You will get a file like this: AF Demo node list.zip (zipped for your protection. ) Next you need to open this file in yEd. When you do, you need to set the data ranges correctly, like this: and choose a presentation configuration like this: which I created earlier using this: The end result, after a few cosmetic tweaks results in this: Pretty cool, eh? (Well, I think it is useful. I always prefer to visualize my applications. Complex apps using messaging architectures can get pretty hard to follow without good documentation.) I hope others find this useful. -John
2 points
.thumb.jpg.5d2ee2fea691c9fe3fab4270ba8e531d.jpg)