Leaderboard




Popular Content
Showing content with the highest reputation on 10/21/2011 in all areas
-
A few other options could be to: Pass in configuration data as a Class Use a Factory Pattern Read configuration data from disk inside e.g. Init method2 points
-
No. For the last few applications, I managed to keep the code modular enough that refactoring was basically painless - but I can see a ceiling to the scalability. Reading the discussions, here, of everyone's design patterns has helped immensely. If you have time, create a bunch of classes with fake instruments and do trial-and-error. If you have money, follow Daklu's advice. I could not find suitable examples, either. The hardware abstraction examples are wonderful for teaching inheritance. I get the feeling that people who use LabVIEW to develop applications have their own methods, and that people who use it develop one-panel data-grabbing VIs are overwhelmed by (and don't need) complex examples. A few experts have shown me their code, and it seems to me that it is more complicated than it needs to be - lots of upcasting and downcasting, etc. One gentleman has a base class called Instrument from which all other instrument classes inherit. This allows him a huge amount of flexibility, but it is hard for me to keep it all in my head. (What's the G equivalent of the old Linux book's quote: "400 lines of code is all most people can keep in their head at once"? 400 VIs? 400 classes?) My plan of attack, at the moment, is a single cluster of Somethings that can be accessed by name in any test (and in an emulator). Each Something is an Action Engine class, and includes an instrument class in its private data. Create the single cluster at the top-level and pass it around to the tests. Perhaps this is easier to do with some of the messaging systems mentioned on LAVA, but I'm not there, yet. Plenty of words from me, but no code, this time. A VI's worth 400 lines.1 point
-
I'm not quite sure what you mean by "where to keep the class wires." Are you using the instruments in the tests and simulation at the same time? There's nothing particularly difficult with writing auto reconnect code, though it isn't something I'd put directly in the instrument class. Just give the class a way to report the connection has been dropped and let the calling vis be responsible for monitoring the connection and reestablishing it when you want. There are two basic ways you can handle connection monitoring: Inline or as a parallel process. Inline--meaning the connection is checked as part of retrieving a data point--is easier to implement, but if a connection is dropped you won't know it until you try to get a data point. Doing the reconnect operations directly in your data processing loops may cause unacceptable delays depending on the project specifics. Parallel process connection monitoring is just a separate loop dedicated to the instrument that periodically checks to see if the connection is still valid even if you're not actively collecting data. When it discovers the connection has been dropped it will attempt to reestablish it. That way the reconnection process doesn't cause your data processing loop to hang. You might be able to use a by-ref class if the instrument's device driver supports it. Personally I prefer to stick with by-val classes and just route all data exchanges with the instrument through that loop.1 point
-
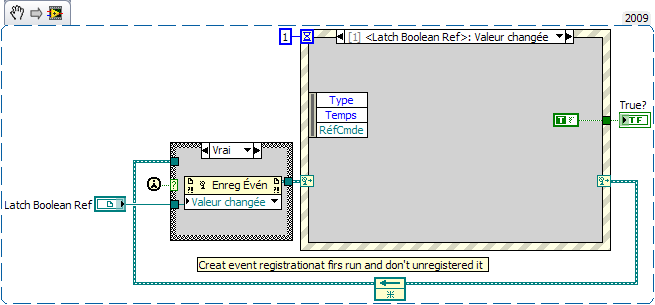
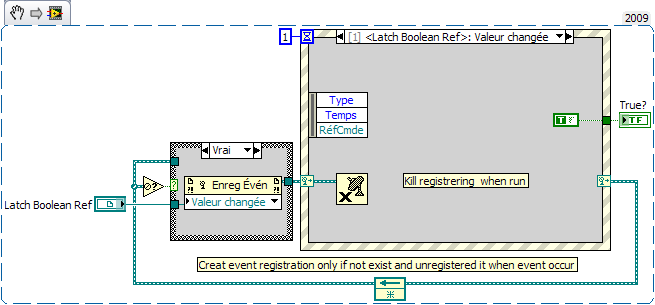
Hi Today i have write a trick to solve one old limitation of Labview. As you know , you can't create local for latched boolean. And sometimes it will be useful if we have one.(for example to propagate latch action between few parallels loops). My solution use event with dynamic registration. (see Trig on latch boolean action). TestTRIG.vi Trig on latch boolean action .vi But it's not all. With this trick, If you modify Latch boolean ref input by another kind of ref type and/or modify the kind of registration, you can easily propagate any kind of action. However, i have one question about this trick. At start, i have write one first solution where event registration is do only at first run and aren't unregistered. And after i have modify this trick, and create registration if not exist and unregister it when latch arrived. In this case, you have new registration for every latch. My question is to know which solution is best, and if it's bad to not unregister dynamic event. Eric
 1 point
1 point -
I don't know about this one. In most situations my state is maintained separate from the actual dequeued element: state is a calculation based off history, and rarely defined exclusively from a single element. So during a timeout I use the calculated state and the previous element is likely irrelevant.1 point
-
Gak! You're right. That's what I get for multi-multitasking.1 point
-
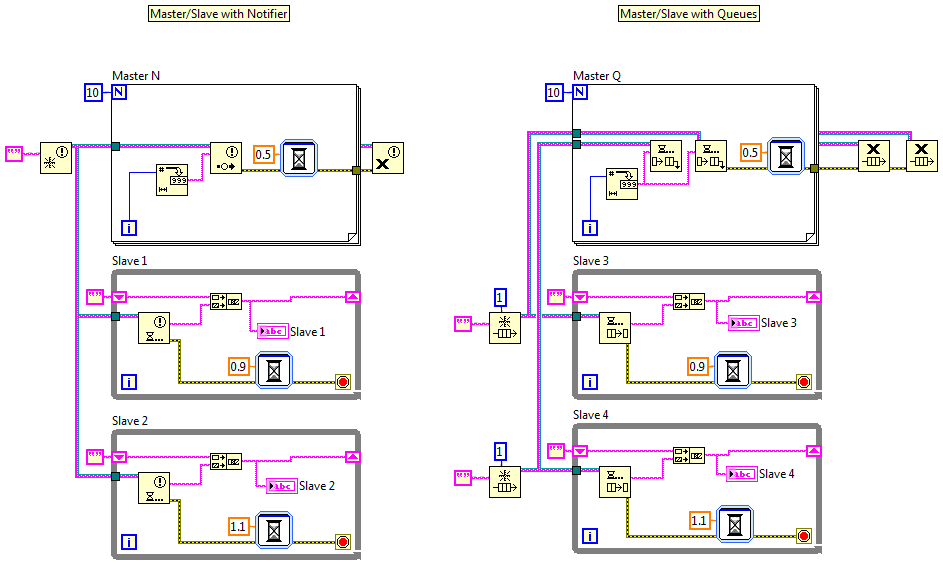
Hmm... I'm not quite sure how to interpret this statement. Are you saying NI's template defines the what the master/slave pattern is, or are you saying your comments have been directed at that particular implementation of the pattern? The context of your posts suggests the former, so I'll assume that is what you mean, but to be honest it's not clear to me. Let me know if I've misunderstood you. Did you see the part where I said each slave loop gets its own queue? This is what I'm talking about. Now I thought I understood the differences between queues and notifiers, but maybe there's something I'm missing. As far as I know these two master/slave implementations are functionally equivalent. Is there an edge condition I'm not aware of that makes them behave differently? I agree it appears to be pretty limited. I suspect it's designed for beginners and those who are using Labview as a data collection tool rather than as an application development tool. Ahh... at least one person agrees with me on what it means to be a slave. (Maybe we can brainwash convince the others. ) Your description of p/c doesn't quite make sense to me, but that's another discussion. Jon is right. Preview leaves the message on the queue, so if a slave is running faster than the incoming messages it will preview a message it already acted on. Master-Slave Comparison.vi
1 point
-
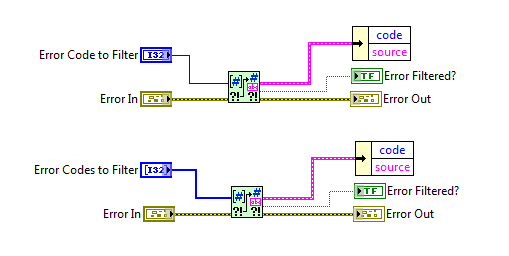
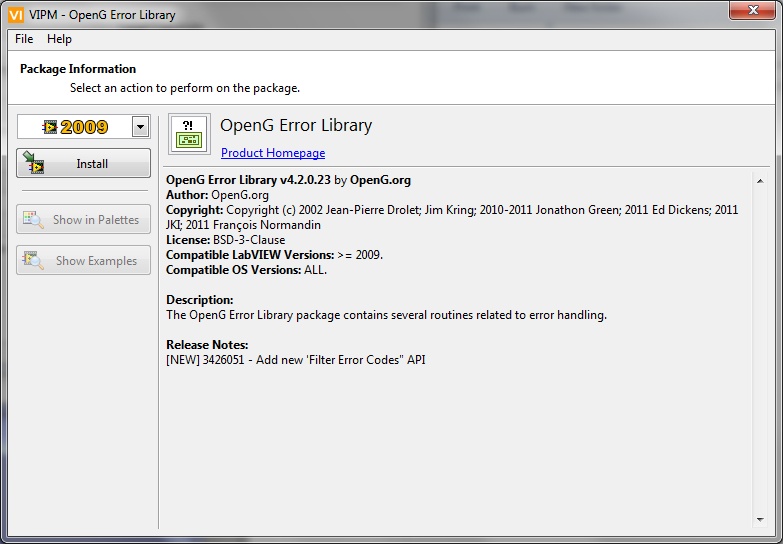
This package will be available for download through VIPM in a few days and covers some new VIs donated by JKI. [NEW] 3426051 - Add new 'Filter Error Codes" API New Palette New Filter Error Codes VIs that support Scalar and Array Error Code inputs New smaller Clear Errors VI (compared to NI) with additional Merge Upstream Error functionality Kind regards Jonathon Green OpenG Manager I would also like to thank Ed Dickens for reviewing this package for release.
1 point
-
Only if you dequeue. Preview Queue Element would be used in this case.1 point
-
I agree, there are more significant differences than communication method. A "server" stands ready to respond to requests from a "client"; a "subject" notifies its "observers" of what it's doing (but is not acting on requests and is entirely unaffected by the observation). A "slave" serves, and is entirely dependent on, one master. "Producer" and "consumer" are dependent on each other and have no separate identity. There all essentially pieces of code exchanging information, but the particular metaphors chosen carry useful, if imprecise, meaning. -- James1 point
-
Off the top of my head.... P/S : Single server to many clients, Single clients to many servers. (An example of Many to Many). P/C: Single server to single client (An example of 1-1) M/C: Single Server to many clients , Single clients to single Server (An example of 1-Many). Aggregator:Many servers to Single client, Single client to single server (An example of Many - 1) The list goes on but are variations on something to something and these too can also be broken down further. That's my understanding at least. (Oxygen is starting to get a bit thin up here )1 point
-
Would you care to take a stab at enumerating your understanding of those differences?1 point
-
I fully agree with you there, and as developers we need to understand the tradeoffs when deciding on what transport mechanism to use between two loops. I just don't think the specific transport matters because it is rather easy to duplicate one-to-many relationships between loops using queues. It's a little more work to scale functionality to multiple threads when using queues to transport, but they do scale perfectly well. Just have a unique queue for each slave and send the message to all of them. Actually you can. Set the queue size to one and use the lossy enqueue function. And if the notifier is an inherent part of the M/S pattern, it also means all the slaves operate on the same set of messages and on the identical copies of the data which, as you pointed out earlier, turns it into a solution looking for a problem. Master/Slave, Producer/Consumer, Observer/Observable, Publisher/Subscriber, etc. describe the relationships between parallel processes, not the implementation. The transport mechanism is an implementation detail and entirely incidental to the relationship. No doubt it is a very important detail, but it doesn't affect the overall relationship between the processes.1 point
-
Actually. thinking more (briefly). That is not a requirement of a Master/Slave. It is more an implementation of the example.In the same way that Pub/Sub is a subset of client/server, so is M/S and P/C. The differences are in the way that they realise the client/server relationship.1 point
-
If you are not using POOP (Predominantly Object Oriented Programming) then a lot of the POOP design patterns are no longer relevant since the problem that they solve becomes trivial and most of the mechanics gets handled by the language (yes I'm looking at you "singleton"). With POOP, the problem is usually "State", transitions of state and how to manage it. That's not to say that there aren't any in non-OOP languages, They are just usually called "frameworks" and tend to be more generic. The thing to bear in mind is that design patterns solve a well known problem. But that problem is usually a restriction in the language or paradigm you are using (sometimes called "Idioms" by the Architecture Astronauts). Therefore design patterns tend to be paradigm/language specific (not all...but most). But you have probably been using non-OOP design patterns for quite some time (State Machines, Producer/consumer, Publisher/Subscriber) Take Monads for example (a functional programming design pattern) Sound like VI's and terminals? We (as Labview programmers) have no need for this "pattern" because it is an in-built feature of the language (we chain VIs [monads] together using wires [pipelines] via their terminals [bind/return operators]). A good example of a design "Pattern" that IS useful in Labview is the Producer/Consumer (we all know that one - it's a template in Labview). Why? Because it addresses a restriction of the language (it breaks Dataflow). Most of the time dataflow is our friend (it automagically handles state and imposes strict sequencing in a parallel manner) but when we need asynchronous operations this is a simple generic pattern in our arsenal. So what POOP patterns are useful to us in "classic" labview? As a general rule -.those that break dataflow! So we have a use for things like the "Observer Pattern" or, as we muggles call it, "Publisher/Subscriber". But we also have uses for the more structural patterns such as Strategy (think plugins), State (think state machine) and Facade (think API). although these could arguably be called "idioms" for classical Labview usage. And those that aren't very useful? Well. Most of them Labview itself makes most of the issues associated with POOP patterns fairly trivial. Many are variations on a theme (Mediator and Facade for example). Many revolve around instantiating objects - Creational patterns (we generally define all objects at design time). And many are based around managing communications between objects - Behavioral patterns, (we have wires for that). Why aren't there many references to design patterns outside of POOP? Because they generally solve problems caused by POOP. Now where's my hard-hat.1 point
-
Try going for the de-facto standard - http://www.laputan.org/mud/1 point
-
Thanks, this was my goal. I will choose the first solution with the event structure because of I'm not so familiar with the state machines. Max1 point