LogMAN
-
Posts
720 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by LogMAN
-
Doesn't that require the producer to know about its consumers? You don't. Previewing queues is a lossy operation. If you want lossless data transfer to multiple concurrent consumers, you need multiple queues or a single user event that is used by multiple consumers. If the data loop dequeues an element before the UI loop could get a copy, the UI loop will simply have to wait for the next element. This shouldn't matter as long as the producer adds new elements fast enough. Note that I'm assuming a sampling rate of >100 Hz with a UI update rate somewhere between 10..20 Hz. For anything slower, previewing queue elements is not an optimal solution.
-
That is correct. Since the UI loop can run at a different speed, there is no need to send it all data. It can simply look up the current value from the data queue at its own pace without any impact on one of the other loops. How is a DVR useful in this scenario? Unless there are additional wire branches, there is only one copy of the data in memory at all times (except for the data shown to the user). A DVR might actually result in less optimized code. Events are not the right tool for continuous data streaming. It is much more difficult to have one loop run at a different speed than the other, because the producer decides when an event is triggered. Each Event Structure receives its own data copy for every event. Each Event Structure must process every event (unless you want to fiddle with the event queue 😱). If events are processed slower than the producer triggers them, the event queue will eventually use up all memory, which means that the producer must run slower than the slowest consumer, which is a no-go. You probably want your producer to run as fast as possible. Events are much better suited for command-like operations with unpredictable occurrence (a user clicking a button, errors, etc.).
-
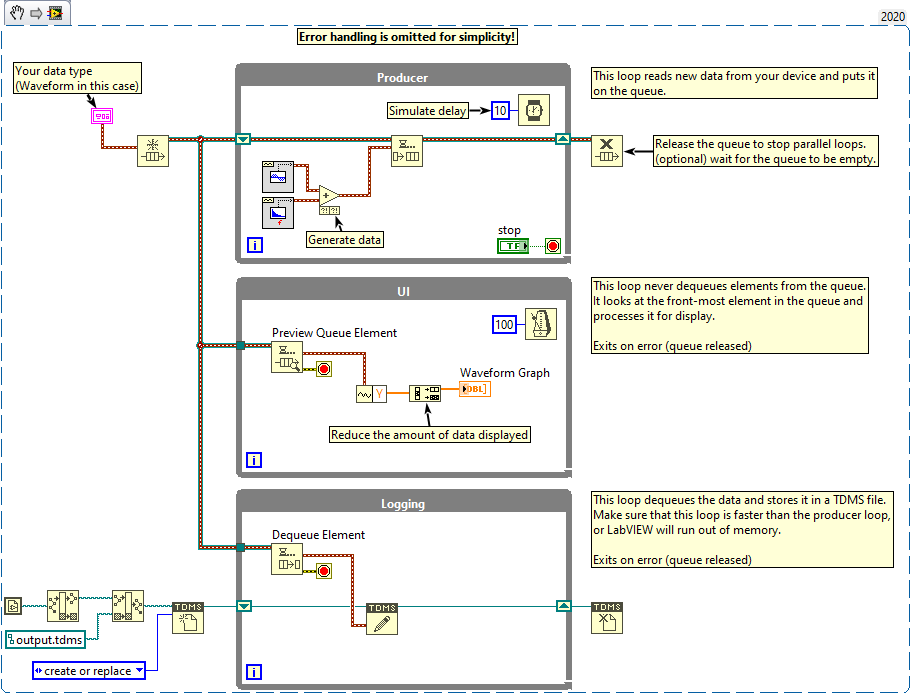
Welcome to Lava! The loops in both of your examples are connected with Boolean wires, which forces them to execute sequentially. This is certainly not what you want. Also, both examples are variations of the Producer/Consumer design pattern. You probably want to store data lossless, so a queue is fine. Just make sure that the queue does not eat up all of your memory (storing data should be faster than capturing new data). Maybe use TDMS files for efficient data storage. Use events if you have a command-like process with multiple sources (i.e. the UI loop could send a command to the data loop to change the output file). Displaying data is very slow and resource intensive. You should think about how much data to display and how often to update. It is probably not a good idea to update 24 MB worth of data every second. A good rule of thumb is to update once every 100 ms (which is fast enough to give the user the impression of being responsive) and only show the minimum amount of data necessary. In this case you could utilize the data data queue and simply check for the next value every 100 ms, then decimate and display the data. Here is an example:

-
You need to take time zones into account (UTC+14:00 in your case). By default the Scan From String function returns time stamps in local time if you use the "%<>T" format specifier. This is mentioned under section Format Specifier Examples, here: https://zone.ni.com/reference/en-XX/help/371361R-01/lvconcepts/format_specifier_syntax/ You'll get the right response if you use the "%^<>T" format specifier: "%[+-]%^<%H:%M>T"
-
You have to install at least the LabVIEW Runtime Environment for your particular version of LabVIEW and any dependencies. Otherwise you'll receive many error messages. The best way to go about it is to add a build specification for an installer to your LabVIEW project, with which you can distribute your application and any dependencies in one package. It will produce an installer for your application. Here is a KB article that explains the process: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z0000019PV6SAM Additionally, you can include MAX configurations from your machine and have them automatically installed on the target machine. Here is a KB article that explains the process for custom scales: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z0000019MvuSAE There is probably a better source for this, but ni.com is down for maintenance right now... 😱
- 1 reply
-
- 1
-

-

Design advice needed for data acquisition system
LogMAN replied to brownx's topic in Application Design & Architecture
Named queues will only work in the same instance of LabVIEW. If there are two instances, those queues are isolated from each other (labview1 and labview2 don't share their address space), which means you need inter-process communication. @drjdpowell If I remember correctly, the Messenger Library has built-in network capabilities, right? -
Design advice needed for data acquisition system
LogMAN replied to brownx's topic in Application Design & Architecture
From what we have discussed so far, the Messenger Library certainly seems to be a perfect fit. It'll provide you with the infrastructure to run any number (and type) of workers and communicate with them in a command-like fashion. It is, however, a much more advanced framework than the simple message handler from my examples. As such, it will take more time to learn and use properly. As someone who enjoys the company of technicians who get scared by things like "classes" (not to mention inheritance 🙄), I strongly suggest to evaluate the skill levels of your maintainers before going too deep into advanced topics. If nobody has the skills to maintain the solution, you could just as well do it in C++. Perhaps you can include them in the development process? This will make the transition much easier and they know what is coming for them. If they also do some programming, they have nobody to blame 😉 @drjdpowell already mentioned his videos on YouTube. I really suggest you watch them in order to understand the capabilities of the Messenger Library Here is also a link with more information for the message handler in my examples (sorry no video, +1 for the Messenger Library): http://www.ni.com/tutorial/53391/en/ -
Design advice needed for data acquisition system
LogMAN replied to brownx's topic in Application Design & Architecture
Sorry, it is not 😄 -
Design advice needed for data acquisition system
LogMAN replied to brownx's topic in Application Design & Architecture
You are trying to optimize something that really isn't a bottleneck. Even if each bit was represented by a 8-bit integer, the total size of your data is less than 200 Bytes per hardware. Even with 100 devices (hardware) only 20 KB of memory is needed for all those inputs and outputs (analog and digital). In the unlikely event that there are 1000 consumers at the same time, each of which have their own copy, it will barely amount to 20 MB... As a C/C++ programmer I feel the urge for memory management, but this is really not something to worry about in LabVIEW, at least not until you hit the upper MB boundary. It might seem easier at first glance, but now all your consumers need to know the exact order of inputs and outputs (by index), which means you need to update every consumer when something changes. If you let the worker handle it, however, (i.e. with a lookup table) consumers can simply "address" inputs and outputs by name. That way the data structure can change independently. You'll find this to be much more flexible in the future (i.e. for different hardware configurations). I'd probably use another worker that regularly (i.e. every 100 ms) polls the state of the desired input and sends the stop signal if needed. That, and the fact that the worker has to poll continuously even if there is no consumer. It is also not possible to add new features to such a worker, which can be problematic in case someone needs more features... Suggestion: Keep them in a separate list as part of the worker. For example, define a list of interrupt IOs (addresses) that the worker keeps track of. On every cycle, the worker updates the interrupt state (which is a simple OR condition). Consumers can use a special "read interrupt state" command to get the current state of a specific interrupt (you can still read the regular input state with the other command). When "read interrupt state" is executed, the worker resets the state. Now that I think about it, there are quite a few things I might just use in my own I/O Server... 😁 -
Design advice needed for data acquisition system
LogMAN replied to brownx's topic in Application Design & Architecture
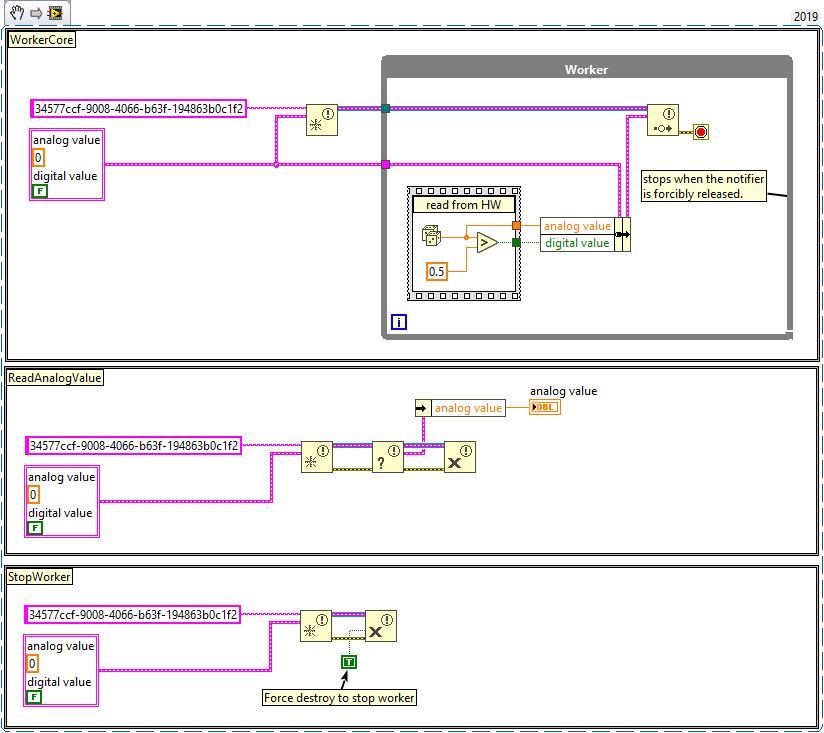
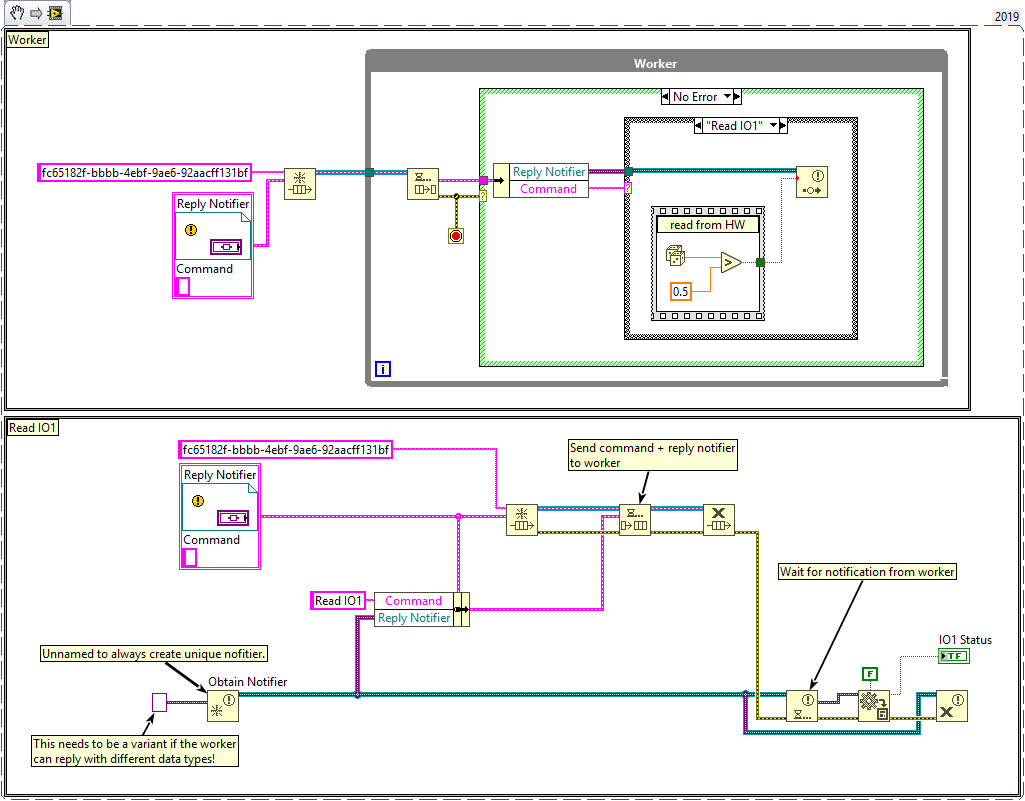
Yes, either notifier or queue. You can store the notifier reference, or give the notifier a unique name (i.e. GUID), which allows you to obtain an existing notifier by name if it already exists in the same address space (application). Here is an example using notifiers: Queues work the same way. Either your notification always contains the value for "read IO1", in which case the latest value also contains it, or you need to inform the worker about which channel to read. For example, by sending a message to your worker that includes the desired channel name, as well as a reply target. For things like this, the Queued Message Handler template (included with LabVIEW) or the Messenger Library are probably worth looking into. How much data are we talking about? Yes, there is some copying going on, but since the data is requested on-demand, the overall memory footprint should be rather small because memory is released before the next step starts. If you really need to gather a lot of data at the same time (i.e. 200 MB or higher), there is the Data Value Reference, which gives you a (thread safe) reference to the actual data. DVRs, however, should be avoided whenever possible because they limit the ability of the compiler to optimize your code. Not to mention breaking dataflow, which makes the program much harder to read...
-
Design advice needed for data acquisition system
LogMAN replied to brownx's topic in Application Design & Architecture
Sorry, I'm not familiar with TestStand. I'd assume that there is some kind of persistent state and perhaps a way to keep additional code running in the background, otherwise it wouldn't be very useful. For example, it should be possible to use Start Asynchronous Call to launch a worker that runs parallel to TestStand and which can exchange information via queues/notifiers whose references are maintained by TestStand (and that are accessible by step scripts). In this case, there would be one step to launch the worker, multiple steps to gather data, and one step to stop the worker. Maybe someone with more (any) experience in TestStand could explain if and how this is done. -
Design advice needed for data acquisition system
LogMAN replied to brownx's topic in Application Design & Architecture
Oh I see, my first impression was that the issue is about performance, not architecture. Here are my thoughts on your requirements. I assume that your hardware is not pure NI hardware (in which case you can simply use DAQmx). Create a base class for the API (LabVIEW doesn't have interfaces until 2020, a base class is the closest thing there is). It should have methods to open/close connections and read data. This is the Read API. For each specific type of hardware, create a child class and implement the driver-specific code (TCP/IP, UDP, serial). Create a factory class, so that you can create new instances of your specific drivers as needed. The only thing you need to work out is how to configure the hardware. I can imagine using a VISA Resource Name (scroll down to VISA Terminology) for all drivers, which works unless you need to use protocols that VISA doesn't support (TCP/IP, UDP, and serial are supported though). Alternatively create another base class for your configuration data and abstract from there. Of course, the same should be done for the Write API. The easiest way is to have two methods, one to read analog values and one to read digital values. Of course, hardware that doesn't support one or the other will have to return sensible default values. Alternatively, have two specific APIs for reading analog/digital values. However, due to a lack of multiple inheritance in LabVIEW (unless you use interfaces in 2020), hardware that needs to support both will have to share state somehow. It makes sense to implement this behavior as part of the polling thread and have it cache the data, so that consumers can access it via the API. For example, a device reads all analog and digital values, puts them in a single-element queue and updates them as needed (dequeue, update, enqueue). Consumers never dequeue. They only use the "Preview Queue Element" function to copy the data (this will also allow you to monitor the last known state). This is only viable if the dataset is small (a few KB at most). Take a look at notifiers. They can have as many consumers as necessary, each of which can wait for a new notification (each one receives their own copy). There is also a "Get Notifier Status" function, which gives you the latest value of a notifier. Keep in mind, however, that notifiers are lossy. -
Design advice needed for data acquisition system
LogMAN replied to brownx's topic in Application Design & Architecture
Arrays of clusters and arrays of classes will certainly have a much higher memory footprint than an array of any primitive type. The amount of data copies, however, depends on your particular implementation and isn't affected by the data type. LabVIEW is also quite smart about avoiding memory copies: https://labviewwiki.org/wiki/Buffer_Allocation Perhaps, if you could show the particular section of code that has high memory footprint, we could suggest ways to optimize it. I don't want to be mean, but this particular approach will result in high CPU usage and low throughput. What you build requires a context switch to the UI thread on every call to one of those property nodes, which is equivalent to simulating keyboard presses to insert and read large amounts of data. Not to mention that it forces LabVIEW to copy all data on every read/write operation... Certainly not the recommended way to do it 😱 You don't need to sync read and write for property nodes, they are thread safe. Do you really need to keep all this data in memory in large chunks? It sounds to me as if you need to capture a stream of data, process it sequentially, and output it somewhere else. If that is the case, perhaps the producer/consumer template, which comes with LabVIEW, is worth looking into. -
Has anyone thought about using LabVIEW with modded Minecraft?
LogMAN replied to Sparkette's topic in LabVIEW General
If we are talking about automating factories, isn't Factorio the game of choice, rather than Minecraft? 😋 -
NXG, I am trying to love you but you are making it so difficult
LogMAN replied to Neil Pate's topic in LabVIEW General
It was mentioned once or twice...
-
Git can't be this terrible, what am I doing wrong?
LogMAN replied to drjdpowell's topic in Source Code Control
I agree that git in its entirety has become very complex. So much even, that they literally have to divide commands into categories... 🤦♂️ Talk about feature creep... However, a typical git user needs maybe 10 commands regularly and perhaps the same amount occasionally for specific tasks (like recovering from a detached head) and edge cases (like rewriting history). I found it actually much easier to just teach those few commands, than to increase the learning curve by adding another tool on top of that. Don't get me wrong, UI tools are very useful - specifically for users that are entirely new to the idea of VCS. Anyone familiar with concepts like branching, merging, and wandering the history of a project, however, should at least consider (and perhaps try for a few days) to work with the command line interface. It's just text (although the stories it tells are sometimes a bit scary) 😄 Haven't heard of it, but it is certainly something worth looking into. Thanks for sharing! -
A typical solution for this is to regularly exchange a "heartbeat" message between your top-level VI and running clone(s). That way, if either the top-level VI or clone doesn't respond within an expected timeframe (i.e. 60 seconds), the system can react accordingly (i.e. spawn a new clone, report an error, or - in case of the clone - shut itself down).
-
Here are some more potential flags: Private function calls (anything offered by "SuperSecretPrivateSpecialStuff") Undocumented function calls (anything from <labview> that is not on the palette, except those hidden gems) Functions that access files in the user's scope (desktop, documents, etc.) Although the question is about malicious LabVIEW code, there are other points to consider: Any form of harassment, racism, etc. as part of the codebase (file names, free labels, VI documentation, error messages, etc.) Non-LabVIEW files like pictures, videos, presentations and others, which may contain harmful content. For example, macros in office files. In my opinion, the likelihood of malicious LabVIEW code is far smaller than malicious office documents. This might change with the availability of the community edition, but since LV is very niche, there is not much to gain. (unless there is a chance that malicious code gets used by a company like NI or NASA...).
-
Here is my second part including some doubts. Please note that I make a few assumptions about the nature of this idea, so take it with a grain of salt. This will immediately flag all existing (non-malicious) packages as malicious, because each one will fail at least one of those checks. Just try running those checks on the OpenG packages... Also, most of those points only indicate potential technologies with which one could build malicious software. They are certainly not indicators of malicious software on their own. Not just that, but it also limits the options for the kind of licenses one can choose for their package. In fact, only an open source license is able to pass the checks (no password protected VIs + no removed block diagrams). While I like open source as much as the next developer, this will prevent businesses from providing licensed solutions via packages. In my opinion this is a bit too restrictive. I'm no security expert, but malicious code is generally detected during execution. Static code analysis is simply not smart enough to detect nuances in execution behavior. There is also no 100% guarantee that malicious code is triggered during code execution, which is why each users is responsible for verifying code that they downloaded from the internet (sandboxing). We are developers. As such it is our responsibility to take care of every tool we use for our work. This includes third-party packages from "unknown" sources or even package vendors. There are of course a few things that the package vendor could (should) do to help identify the origin of a package. For example, I want to be sure that the OpenG packages are actually from the OpenG community and not from someone random. This is why packages typically include information about their origin and are tied to a specific username. For example, the OpenG library (package) could belong to the OpenG account: "gcentral.org/packages/openg/openg-library". If you want to go one step further, have package owners sign their packages (i.e. PGP). For trusted package owners, GCentral could sign their keys to build a "web of trust". That way, if I trust GCentral, perhaps I can also trust the one that GCentral trusts... Regarding malicious code, I'd only expect GCentral to verify that packages don't include viruses (use your average anti-virus software). The rest of it is my responsibility. I am responsible for the code I download from the internet. GCentral should certainly not aim to take responsibility for that. My recommendation is to not have any kind of "no malicious code detected" tag on packages, because it will give developers a false sense of security. A "package from verified source" tag, however, could be worth looking into.
-
I have two responses to this. Let me start by contributing further suggestions. No invisible code - that is hidden code inside structures that have auto-grow disabled. No PPLs No binaries (DLLs, executables, ZIP files, etc.) - except if the source code of the DLL is included or can be obtained via open source channels attributed in the package. No unlicensed packages - a reusable package without license is worthless. No broken/missing VIs - bad code is not reusable. No viruses, etc. - just use your average anti-virus protection to verify each package. We don't want to unpack a malicious ZIP file or worse... Perhaps this can be done by a test that checks for #vian_ignore labels in all VIs.
-
Welcome to Lava! There is no way to intercept WaitForNextEvent, other than generating the event it is waiting for or the timeout occurring. It is, however, possible to handle the event directly in LabVIEW. Are you familiar with .NET Event Callbacks? Use the Register Event Callback function to execute a callback VI to generate a user event for an Event Structure. The event structure can then take care of the timeout as well as other events that may end execution prematurely. Here is an example. For simplicity reasons I didn't include error handling and the callback VI, but you should be able to work the rest out from here. Disclaimer: I haven't tested this, but I'm certain it will do what you want.
-
What you describe sounds very similar to our situation, except that we only have a single top-level repository for all stations. If you look at a single station repository of yours, however, the structure is almost the same. There is a single top-level repository (station) which depends on code from multiple components, each of which may depend on other libraries (and so forth). * Station + Component A + Library X + Library Y + Component B + Library X + Library Z + ... In our case, each component has its own development cycle and only stable code is pulled in the top-level repository. In your case there might be multiple branches for different stations, each of which I imagine will eventually be merged into their respective master branch and pulled by other stations. * Station (master) + Component A (master) + Library X (dev-station) + Library Y (master) + Component B (dev-station) + Library X (dev-station) + Library Z (master) + ... In my opinion you should avoid linking development branches in top-level repositories at all costs. Stations should either point to master (for components that are under development) or a tag. * Station A (released) + Component A (tag: 1.0.0) + Component B (tag: 3.4.7) * Station B (in development) + Component A (tag. 1.2.0) + Component B (master) <-- under development * Station C (released) + Component A (tag: 2.4.1) + Component B (tag: 0.1.0) Not sure if I misunderstand your comment, but you don't actually have to branch a submodule. In fact, anyone could simply commit to master if they wanted to (and even force-push *sight*). Please also keep in mind that submodules will greatly impact the git workflow and considerably increase the complexity of the entire repository structure. Especially if you have submodules inside submodules... In my opinion there are only two reasons for using submodules: To switch branches often (i.e. to test different branches of a component at station level). To change code of a component from within the station repository. Both are strong indicators of tightly coupled code and should therefore be avoided. We decided to use subtrees instead. For every action on a subtree (pull, change branch, revert, etc.) there is a corresponding commit in the repo. We have a policy that changes to a component is done at component level first and later pulled into the top-level repository. Since the actual code of a subtrees is included in the repository, there is no overhead for subtrees that include subtrees and things like automated tests also work the same as for regular repositories. You have the right intention, but if any developer is allowed to make any changes to any component, there will eventually be lots of tightly coupled rogue branches in every component, which is even worse that the current state. Not to forget that you also need to make sure that changes to a submodule are actually pushed. This is where UI tools become handy as they provide features like pushing changes for all submodules when pushing the top-level repository (IIRC Sourcetree had a feature like that). To be fair, subtrees don't prevent developers from doing those changes. However, since the code is contained in the top-level repository, it becomes responsibility of the station owner instead of the component owner. In my experience it's a good idea to assign a lead developer to each component, so that every change is verified by single (or a group of) maintainer(s). In theory there should only be a single branch with the latest version of the component (typically master). Users may either pull directly from master, or use a specific tag. You don't want rogue branches that are tightly coupled to a single station at component level.
-
You don't have to do a silent installation. If you follow the instructions, it will create a .spec file that you can customize (it's just a text file), so that it behaves like the standard installer but with different default values. It will only do a silent installation when you use the "/q" option. Omit that flag to do a regular installation.
-
Welcome to LAVA! You can customize the installer with a spec file. If I remember correctly that also allows you to specify the installation directory. Here is a KB article for how to create the spec file (scroll down to "customizing installation"): https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z0000019Ld6SAE&l=en-US
-
I use git submodules. Do yourself a favor and don't use them. There are many pitfalls, here are just a few examples: If a submodule is placed in a folder that previously existed in the repository (perhaps the one you moved into the submodule), checking out a commit from before the submodule existed will cause an error because "files would be overwritten". So you'd have to first delete the submodule and then check out the old commit. Of course, after you are finished you'd have to checkout master again and update your submodule to get it back to the current version. rm submodule/ -rf git checkout <old-commit> ... git checkout master git submodule update This is hard to remember and annoying to use. Not to mention the difficulties for novice git users and the lack of support by most UI tools. Everyone on the team needs to remember to occasionally do git submodule update to pull the correct commit for all submodules. Just imagine shipping an application with outdated code because you forgot to run this command... Branching submodules while branching the main repository, or as I call it: "when you spread the love". Imagine this situation: Colleague A creates a branch in the main repository, let's call it "branch_a". Now they also create a branch on the submodule, let's call it "submodule_branch_a". Of course they'll update the submodule in the main repository to follow their branch. Then they begin changing code and fixing bugs. In the meantime, colleague B works on master (because why not). Of course, master uses the master branch of the submodule. So they add some exciting new feature to the submodule and update the commit in the main repository. All of this happens in parallel to colleague A. Eventually colleague A will finish their work, which gets merged into master. Unfortunately, things aren't that easy... Although "branch_a" followed "submodule_branch_a", it will not do so after merging to master. Because colleague B changed the commit of the submodule in parallel to colleague A, whichever change happened last will be merged to master. This is an exciting game, where you spread the love, flip a coin and hope that you are the chosen one. I actually changed our main repository (shared among multiple developers) to submodules a few years ago, only to realize that they introduce problems that we simply couldn't fix. So I had to pull the plug, delete all recent changes and go back to the state before submodules. That was a fun week... That said, we now use subtrees. A subtree is somewhat similar to a submodule in that it allows you to maintain code in separate repositories. However, a subtree doesn't just store the commit hash but actually pulls the subtree into your repository, as if it was part of that repository in the first place (if you want, even with the entire history). With a subtree, you can simply clone the main repository and everything is just there. No additional commands. However, you'd want to avoid changing any files that belong to submodules, so that you essentially only pull subtrees and never push (or merge). I simply put them in a "please don't change" directory (anyone who changes files in that directory will have to revert and do their work over). Atlassian has a nice article on git subtrees if you are interested: https://www.atlassian.com/git/tutorials/git-subtree