LogMAN
-
Posts
720 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by LogMAN
-
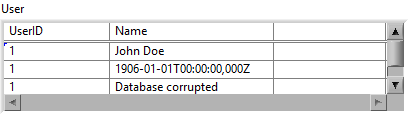
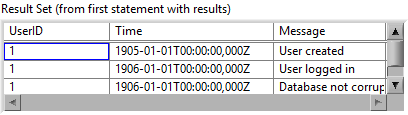
For starters, there are a few DWarns: c:\nimble\penguin\labview\components\mgcore\trunk\18.0\source\ThEvent.cpp(216) : DWarn 0xECE53844: DestroyPlatformEvent failed with MgErr 42. e:\builds\penguin\labview\branches\2018\dev\source\typedesc\TDTableCompatibilityHack.cpp(829) : DWarn 0xA0314B81: Accessing invalid index: 700 e:\builds\penguin\labview\branches\2018\dev\source\objmgr\OMLVClasses.cpp(2254) : DWarn 0x7E77990E: OMLVParam::OMLVParam: invalid datatype for "Build IGL" e:\builds\penguin\labview\branches\2018\dev\source\typedesc\TypeManagerObjects.cpp(818) : DWarn 0x43305D39: chgtosrc on null! VI = [VI "LSD_Example VI.vi" (0x396f46b8)] e:\builds\penguin\labview\branches\2018\dev\source\UDClass\OMUDClassMutation.cpp(1837) : DWarn 0xEFBFD9AB: Disposing OMUDClass definition [LinkIdentity "StatusHistory.lvclass" [ Poste de travail] even though 5 inflated data instances still reference it. e:\builds\penguin\labview\branches\2018\dev\source\UDClass\OMUDClassMutation.cpp(1837) : DWarn 0xEFBFD9AB: Disposing OMUDClass definition [LinkIdentity "Delacor_lib_QMH_Message Queue V2.lvclass" [ Poste de travail] even though 1 inflated data instances still reference it. This will almost certainly cause a crash next time we operate on one o Here is some information regarding the differences between DWarns and DAborts: I'd assume that one of the plugin VIs or classes is broken. You can try and clear the compiled object cache to see if that fixes it. Alternatively uninstall each plugin until the issue disappears. (start with LVOOP Assistant, I remember having issues with it in LV2015).
-
It could be open source and still be maintained by NI, as long as they have a way to generate revenue. There is also great potential in the NXG platform, which - as far as I know - is written in C#. Even if LabVIEW is not of interest to millions of people, keep in mind that most open source projects only receive contributions from a small portion of their users. The Linux kernel is probably not a good comparison, because it is orders of magnitudes more complex than LabVIEW. Nevertheless, Linux "only" received contributions from approx. 16k developers between 2005 and 2017 - 2017 Linux Kernel Report Highlights Developers’ Roles and Accelerating Pace of Change - Linux Foundation. Compare that to relatively young projects as Visual Studio Code (~1400 contributors), or the .NET Platform (~650 contributors). These are projects with millions of users, but (relatively speaking) few contributors. It depends. Companies might be willing to pay developers to fix issues. Enthusiasts might just dive into the code and open a pull-request with their solution. Some items might not be of particular importance to anyone, so they are just forgotten.
-

Which is the best platform to teach kids programming?
LogMAN replied to annetrose's topic in LabVIEW Community Edition
Good selection by @Mefistotelis Try to figure out what motivates them (games, machines, information, ...) and help them find the right resources. Try different things, perhaps something sticks. If not, move on to the next. Here are two links that can get you started with python in a few minutes. Take your first steps with Python - Learn | Microsoft Docs Python Getting Started (w3schools.com) -
Any reccomendation for tools to get started with OOP?
LogMAN replied to Matt_AM's topic in Object-Oriented Programming
Not sure where you got that. It's a valid approach: Command pattern - LabVIEW Wiki The Actor Framework, for example, takes this idea to the extreme. I'm not a fan of the 0ms timeout case because it adds unnecessary polling. The rest sounds good to me. It is probably best if you build a prototype to see what works best for you. -
Any reccomendation for tools to get started with OOP?
LogMAN replied to Matt_AM's topic in Object-Oriented Programming
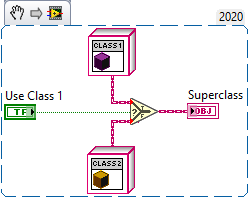
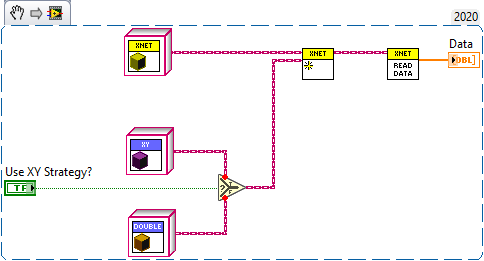
You use some patterns in the wrong context. The Factory pattern is only a means to create new objects without explicitly referencing them. Here is a very simple example using a Boolean to select from two classes. In this example, Class 1 and Class 2 both are children of Superclass. Depending on the input value, one of them will be returned. The caller doesn't need to know how to create those objects and only sets the input value to True or False. A typical implementation uses a String instead of a Boolean, which allows for many more options and adding more classes later. In any case, the output of a Factory is the most common ancestor of all possible children (Superclass in this example). Dynamic dispatching is not something that magically merges different functions into one. It is only a way to change the behavior of a function at runtime. Perhaps you are familiar with Polymorphic VIs. Dynamic dispatching is actually very similar to polymorphism. The difference is how they are resolved. Polymorphic VIs are resolved at edit time. Dynamic dispatch VIs on the other hand are resolved at runtime. This is why dynamic dispatch VIs must always have the same terminal pattern. This is of course a very simplified explanation. For your particular question, there are two parts to it: Create specific subclasses for each type of power supply - For example, XNET and DAQmx are entirely different technologies, so it makes sense to have separate classes for each. Use the Strategy Pattern to change the behavior of a particular method - For example, your XNET class could use different strategies to do the actual read operation (XY, double, etc.). The Strategy Pattern encapsulates an operation in an object. You need to write one object for every possible strategy and then provide the desired strategy at runtime (i.e. using a Factory). Here is a basic example. In this example, XNET is a subclass of Power Supply, which has a Read Data method that returns an array of double. When XNET is created, the desired read strategy is passed as an argument. The strategy has another dynamic dispatch method to do the actual read operation. The Read Data method then uses the strategy to read the data. DAQmx would work similarly, perhaps with its own set of strategies. I believe that this comes very close to what you have in mind. Don't put events and queues inside the reader class. Instead, have a separate class that uses the reader class to produce events or populate queues (these should be separate classes altogether, one for queues and one for events). I suggest you play around with the different patterns to get used to them before you use them in production. OOP can get confusing very quickly if you are only used to functional programming.
-
Poll: Should the CLA Exam require applied knowledge of OOP?
LogMAN replied to Mike Le's topic in LabVIEW General
Glad to hear it worked out well for you. I wish I had this confidence 10 years ago... I agree. Unfortunately the decision is not always up to us, especially for young teams without expert recognized by higher-ups. In our case it went something like this: NI is also not very helpful in dampening expectations: The rest is history. To be fair, our case was a single incident. The general experience with contractors has been very positive and insightful. Still, I would probably raise an eyebrow if a CLA told me that they don't know how to work with classes. Just seems weird considering that it is the final stage in the certification process. Funny how you spell "is" 😄
-
Poll: Should the CLA Exam require applied knowledge of OOP?
LogMAN replied to Mike Le's topic in LabVIEW General
Actually had to google that. If I understand it correctly, you are saying that my sentence is phrased in a way that is offensive to you (and others perhaps). That was not my intention. Let me try to explain myself and hopefully clear up what I presume is a misunderstanding. By "A CLA who isn't familiar with fundamental OOP concepts..." I mean somebody who has no prior knowledge about OOP whatsoever. They don't know what a class is and how inheritance or encapsulation works. It is my opinion that this makes them incapable of choosing between different OOP frameworks and libraries themselves (of course they could ask somebody they trust). For the second part "and in worse case puts the entire project at risk by making random decisions" imagine somebody without any prior knowledge about OOP being brought into a project that is heavily based on OOP (i.e. using Actor Framework). They are brought in by management to evaluate the situation and get the product ready for market. Of course management will listen to the CLA as an expert (as they should). If the CLA ignores the fact that they don't know anything about OOP (worse case scenario), the best they can do is decide based on their instinct, feedback from other developers, or simply by tossing a coin and hope for the best. There is a great chance that this will put the project at risk because everyone listens to that expert. I can't be the only one who went down this rabbit hole. The last part "or avoiding OOP because they don't see the value in it" is about changing architecture late in a project because of a personal vendetta against OOP. Let's take the example from before. The CLA might decide that Actor Framework is not a good solution simply because they don't like OOP stuff. So they tell management to toss everything away because it's "no good" and start from scratch using their own approach. Unless the architect has really good arguments, decisions like that are toxic to any project. I have actually experienced a situation that went in the opposite direction (replacing everything with objects because OOP is THE way to go). We eventually reverted to what we had before thanks to the power of Git. (that was probably the most expensive revert we did - so far). Just to clear up one additional point because I believe that it didn't come across in my original post. I believe that there is value in OOP but I don't think it is the only answer to everything. On the contrary. Frameworks like DQMH completely eradicate the need for frameworks like the Actor Framework. Depending on your needs and what you feel more comfortable with, either one is a great choice. I simply expect a CLA to have basic knowledge about OOP, even if they decide against it. -
Poll: Should the CLA Exam require applied knowledge of OOP?
LogMAN replied to Mike Le's topic in LabVIEW General
Did you only come here to mock me? If you disagree with something I said, please feel free to express your point of view and perhaps we can find common ground. -
Poll: Should the CLA Exam require applied knowledge of OOP?
LogMAN replied to Mike Le's topic in LabVIEW General
I believe it should. OOP (and interfaces in the near future) are architecturally relevant and at the core of frameworks and libraries that drive so many applications. A CLA should be able to assess if a particular framework is a good choice architecturally, or not. A CLA who isn't familiar with fundamental OOP concepts is incapable of making such decisions and in worse case puts the entire project at risk by making random decisions or avoiding OOP because they don't see the value in it. It probably makes sense to focus on fundamental concepts in the exam, because frameworks and libraries eventually get outdated and replaced by new ones. -
@Matteo.T You need to start a new topic for your question, it doesn't belong to this thread.
-
HTTP Post does not work
LogMAN replied to Thang Nguyen's topic in Remote Control, Monitoring and the Internet
Do you receive any error at the error output terminal? Does the other team see any error in the server logs? Did the other team give you any idea about what kind of web service they provide? Since the other team suggested Postman, chances are high that they use a RESTful service. JKI has a REST API Client library on their website which you could try: JKI HTTP REST API Client for LabVIEW -
NI abandons future LabVIEW NXG development
LogMAN replied to Michael Aivaliotis's topic in Announcements
Unless you work entirely on Linux and OSS, most of the core libraries are closed source. Even if that was not the case, you still need to trust the hardware. That's why it's important to test your mission critical software (and hardware) before you put it in the field. No amount of open source will make your software more secure or reliable. You only get to fix bugs yourself and be responsible for it. To be fair, most of us are probably not doing rocket science... right? "There will be just one .NET going forward, and you will be able to use it to target Windows, Linux, macOS, iOS, Android, tvOS, watchOS and WebAssembly and more." - Introducing .NET 5 | .NET Blog (microsoft.com) Pointers yes, values no. If you raise a .NET Event with a NULL value, the .NET Event Callback will not fire... -
NI abandons future LabVIEW NXG development
LogMAN replied to Michael Aivaliotis's topic in Announcements
I don't really expect many new language features or UX improvements in LabVIEW just because they stop working on NXG. From what we know there are only a few knowledgeable people at NI who are intimately familiar with the codebase and some of its intricate details which fundamentally drive LabVIEW. There are also many customers who rely on that technology for their own business. Because of that, NI can't just throw more developers at it and change LabVIEW fundamentally unless they find a way to stay compatible or take a bold step and do breaking changes (which are inevitable in my opinion). LabVIEW will probably stay what it is today and only receive (arguably exciting) new features that NI will leverage from the NXG codebase to drive their business. Unfortunately NI hasn't explained their long-term strategy (I'll assume for now that they are still debating on it). In particular what LabVIEW/G will be in the future. Will it be community-driven? Will it be a language that anyone can use to do anything? Will it be the means to drive hardware sales for NI and partners? Will it be a separate product altogether, independent of NI hardware and technology? There are also a lot of technology-related topics they need to address. Does LabVIEW Support Unicode? - National Instruments Comparing Two VIs in LabVIEW - National Instruments (ni.com) Error 1316 While Using .NET Methods in LabVIEW - National Instruments (ni.com) Using NULL Values or Pointers in LabVIEW - National Instruments (ni.com) Not to forget UX. The list is endless and entirely different for any one of us. If and when these will be addressed is unknown. Don't get me wrong, I'm very excited and enthusiastic about LabVIEW and what we can do with it. My applications are driven by technology that other programming languages simply can't compete with. Scalability is through the roof. Need to write some data to text file? Sure, no problem. Drive the next space rocket, land rover, turbine engine, etc.? Here is your VI. The clarity of code is exceptional (unless you favor spaghetti). The only problem I have with it is the fact that it is tied to a company that want's to drive hardware sales. -
Make sure that you have the rights to distribute those binaries before you put them in your build specification. There is a license agreement that you accepted when you installed them on your machine. Note that you don't have to distribute those assemblies yourself. Perhaps there is a runtime installer available which your clients can use. As long as the assemblies are installed on the target machine, LabVIEW will either locate them automatically, or you can specify the location in an application configuration file. Here are some resources on how assemblies are located: Loading .NET Assemblies - LabVIEW 2018 Help - National Instruments (ni.com) How the Runtime Locates Assemblies | Microsoft Docs
-
Here is an interesting note: How LabVIEW Locates .NET Assemblies - National Instruments (ni.com)
-
Edit: Nevermind, I misread your post 😄 In order for LabVIEW to know about all dependencies in a project, it has to traverse all its members. Because this operation is slow, it probably keeps references open for as long as possible. I'm not sure why it would unload the assembly in standalone, but that is how it is.
-
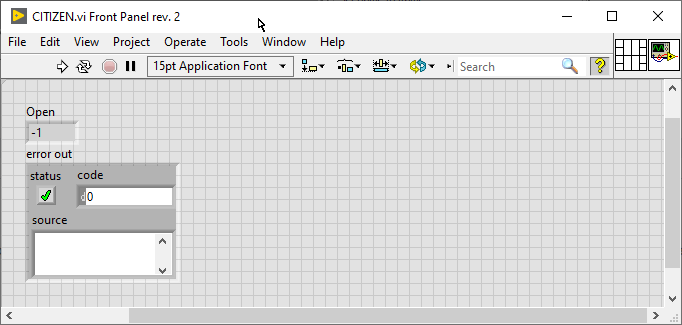
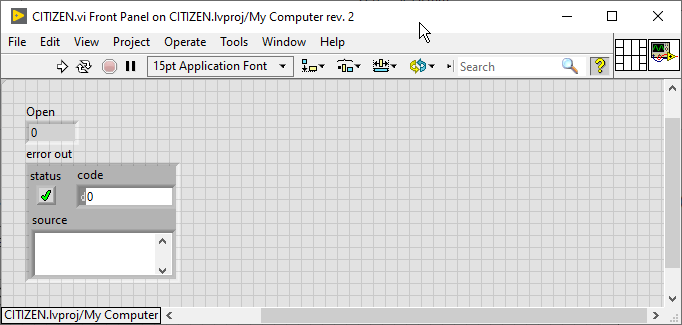
There is something strange about how this library is managed. For some reason it seems to work if the VI is part of a project, but not as a standalone VI. Standalone As part of a project I did not reproduce the entire example, so it might fail. At least you can try adding your VI to a project and see if it works (make sure the assembly is listed under Dependencies).
-
SQLite Library Beta: Parameters in "Execute SQL"
LogMAN replied to drjdpowell's topic in Database and File IO
I was wondering why it wasn't documented, now I know 😄 -
SQLite Library Beta: Parameters in "Execute SQL"
LogMAN replied to drjdpowell's topic in Database and File IO
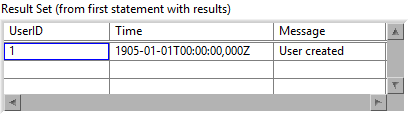
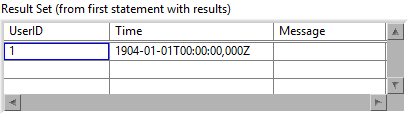
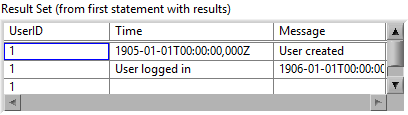
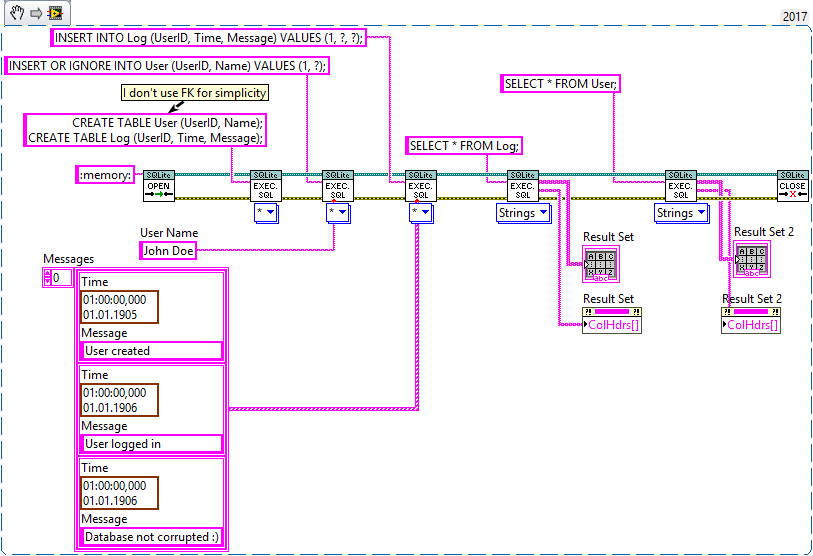
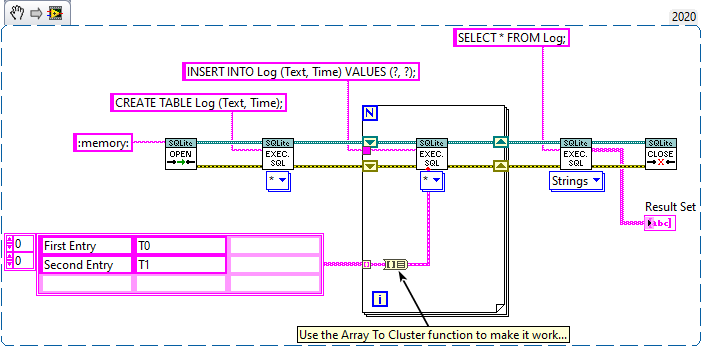
1+3 makes the most sense in my opinion. And it should be limited to a single SQL statement (or multiple statements if they use absolute parameter bindings like "?NNN"). Perhaps it also makes sense to apply that limitation to Execute SQL, because it can get very confusing when executing multiple statements in a single step with parameters that include arrays. For example, what is the expected outcome of this? I could be mislead into thinking that the user name only applies to the first SQL statement and the array to the second, or perhaps that it uses the same user name multiple times while it iterates over each element of the array, but that is not how it works. Right now it produces empty rows 😟 With my fix above, it will produce exactly one row 🤨 By executing the statement over-and-over again until all parameters are used up (processed sequentially), it will insert data into wrong places 😱 In my opinion it should only accept a) an array of any type, each element of which must satisfy all parameter bindings. b) a cluster of any type, which must satisfy all parameter bindings. c) a single element of any type. In case of a or b, subarrays are not allowed (because a subarray would imply 3D data, which is tricky to insert into 2D tables). That way I am forced to write code like this, which is easier to comprehend in my opinion: This is the expected output: Here is what I did to Execute SQL (in addition to the fix mentioned before):
-
SQLite Library Beta: Parameters in "Execute SQL"
LogMAN replied to drjdpowell's topic in Database and File IO
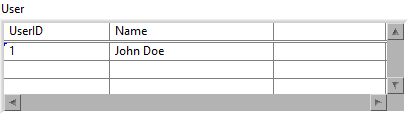
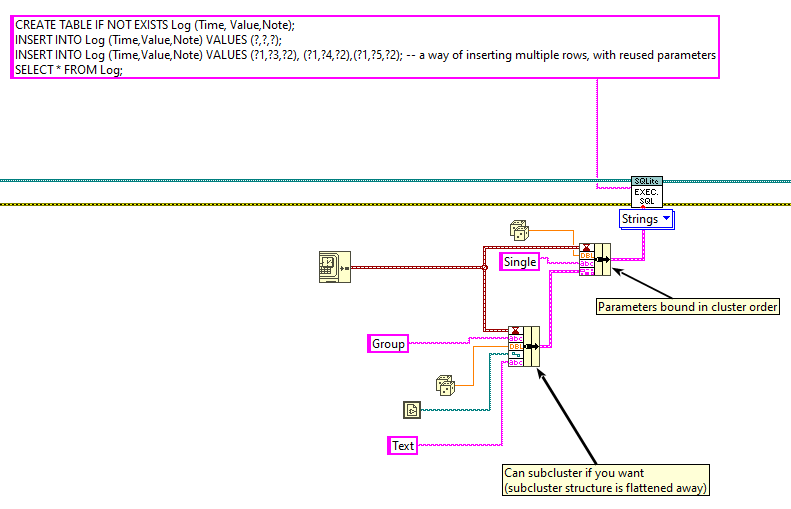
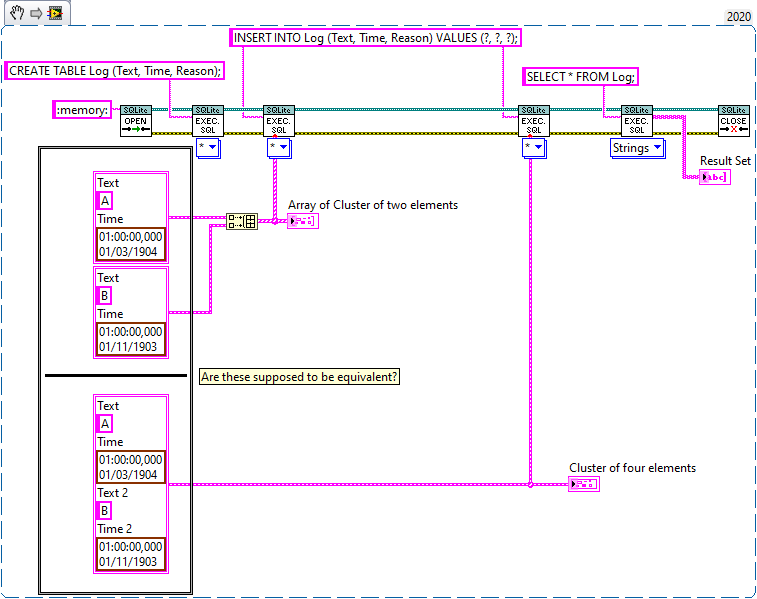
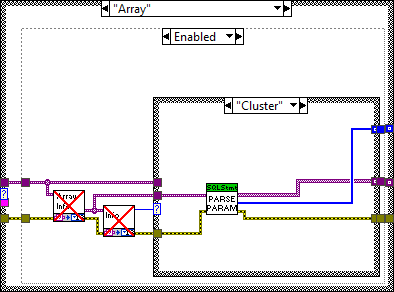
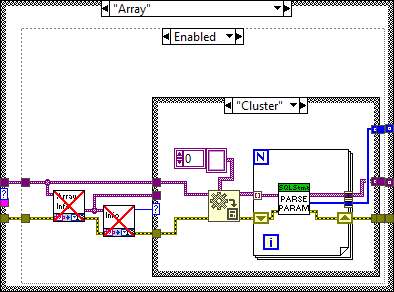
I think you already answered your own question. Each statement only affects a single row, which means you have to wrap arrays in loops. Don't forget that Execute SQL can handle multiple statements at once. This is shown in one of the examples: Note that there are multiple statements that utilize the same input cluster. You could use the Array To Cluster function to simplify the task: You are on the right path. In this case Execute SQL will report an error because only arrays of clusters are allowed: Please take the following section with a grain of salt, I make a few assumptions based on my own findings. @drjdpowell It would be great to have an example of how Arrays of Clusters are supposed to work. I opened the source code and it looks like it is supposed to take an array of cluster and iterate over each element in the order of appearance (as if it was a single cluster). So these will appear equivalent (The "Text" element of the second cluster is used for the 'Reason' field in this example): However, in the current version (1.12.2.91) this doesn't work at all. The table returns empty. I had to slightly change Parse Parameters (Core) to get this to work: Before: Note that it parses the ArrayElement output of the GetArrayInfo VI, which only contains the type info but no data. After: This will concatenate each element in the array as if it was one large cluster. Perhaps I'm mistaken on how this is supposed to work?
-
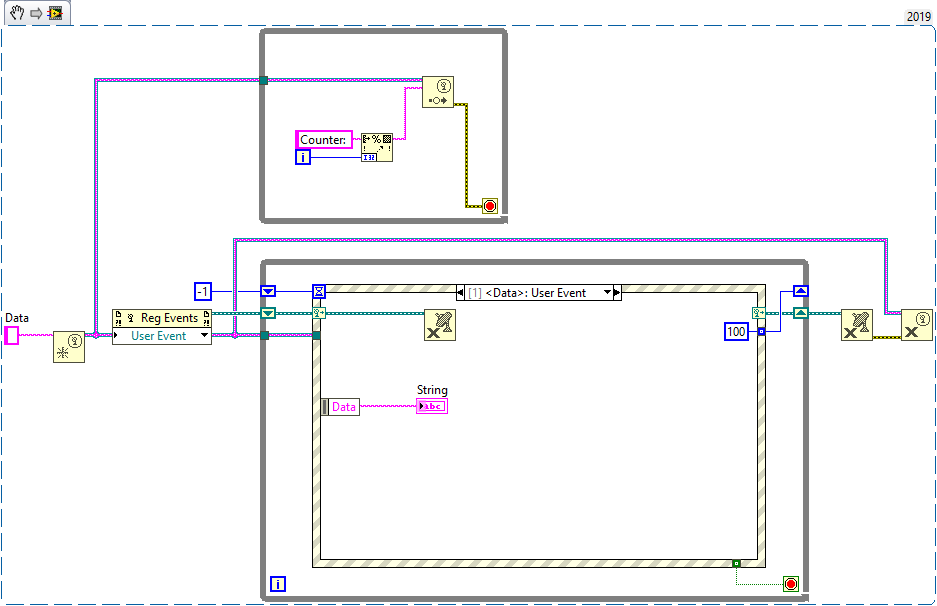
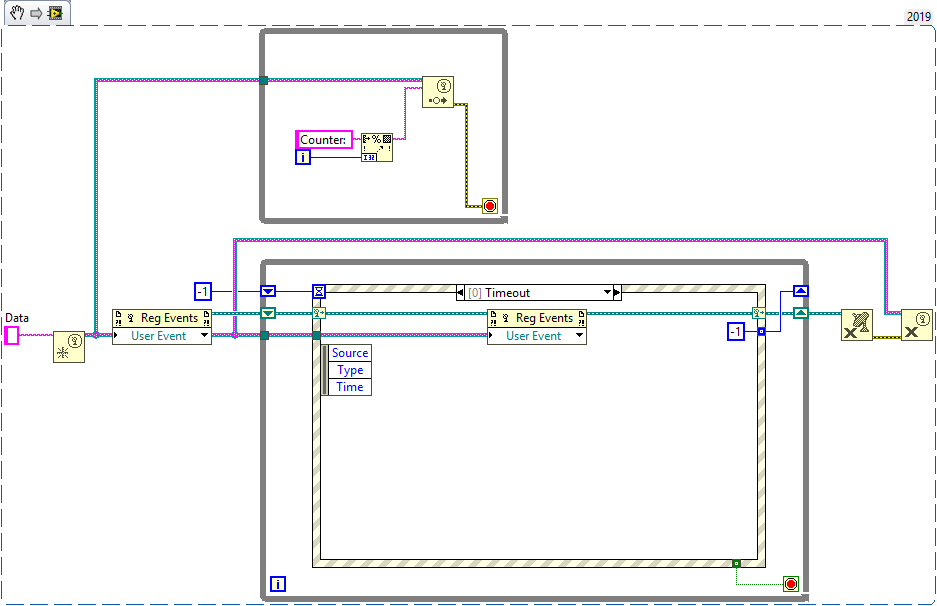
+1 for flushing the event queue. Here is another solution that involves unregistering and re-registering user events. Whenever the event fires, the event registration is destroyed. At the same time it sets the timeout for the timeout case, which will re-register the event and disable the timeout case again. This could be useful in situations where the consumer runs much (order of magnitudes) slower than the producer, in which case it makes sense to reconstruct the queue every time the consumer desires a new value. I haven't done any benchmarks, nor used it in any real world application so far, but it works.
-
My consumers also tend to update the whole GUI if it doesn't impact the process negatively (it rarely does). I was looking for a solution that doesn't require each consumer to receive their own copy in order to save memory. But as @Bhaskar Peesapati already clarified, there are multiple consumers that need to work lossless, which changes everything. Discarding events will certainly prevent the event queue to run out of memory. I actually have a project where I decided to use the Actor Framework to separate data processing from UI and which filters UI update messages to keep it at about 10 Hz. Same thing, but with a bunch of classes. I'm pretty sure there are not many ways to write more code for such a simple task 😅
-
I have only one project that uses multiple DVRs to keep large chunks of data in memory, which are accessed by multiple concurrent processes for various reasons. It works, but it is very difficult to follow the data flow without a chart that explains how the application works. In many cases there are good alternatives that don't require DVRs and which are easier to maintain in the long run. The final decision is yours, of course. I'm not saying that they won't work, you should just be aware of the limitations and feel comfortable using and maintaining them. For sure I'll not encourage you to use them until all other options are exhausted. I agree. To be clear, it is not my intention to argue against events for sending data between loops. I'm sorry if it comes across that way. My point is that the graphical user interface probably doesn't need lossless data, because that would throttle the entire system and I don't know of a simple way to access a subset of data using events, when the producer didn't specifically account for that.
-
This will force your consumers to execute sequentially, because only one of them gets to access the DVR at any given time, which is similar to connecting VIs with wires. You could enable Allow Parallel Read-only Access, so all consumers can access it at the same time, but then there will be could be multiple data copies. Have you considered sequentially processing? Each consumer could pass the data to the next consumer when it is done. That way each consumer acts as a producer for the next consumer until there is no more consumer. It won't change the amount of memory required, but at least the data isn't quadrupled and you can get rid of those DVRs (seriously, they will hunt you eventually).
-
Okay, so this is the event-driven producer/consumer design pattern. Perhaps I misunderstood this part: If one consumer runs slower than the producer, the event queue for that particular consumer will eventually fill up all memory. So if the producer had another event for these slow-running consumers, it would need to know about those consumers. At least that was my train of thought 🤷♂️😄