LogMAN
-
Posts
720 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by LogMAN
-
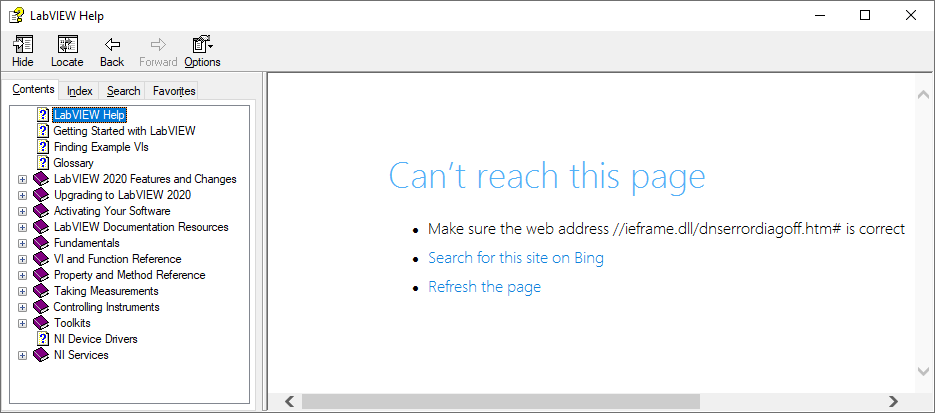
Got the same issue in LV2020 SP1 The page exists, it is just incorrectly linked

-
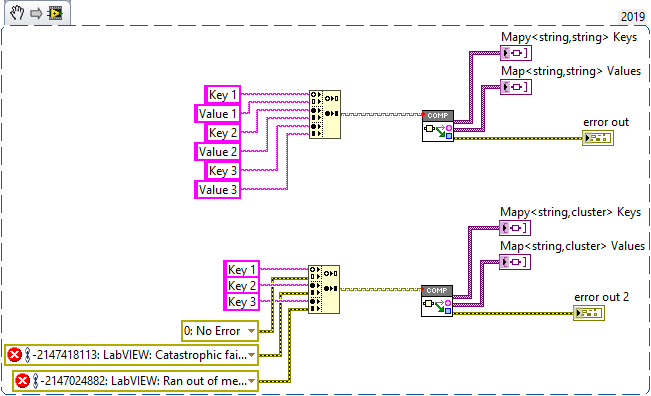
Yes it is, both ways. I'm glad you like it There is a new release which adds support for composition of maps and sets. Here is an example of what you can do with it: This is actually a very smart way of doing it. My library takes the keys and values apart into individual arrays. A key-value-pair is certainly easier to work with...
-
 It's probably not a good idea sharing DBC files publicly. That said, your database loads perfectly fine for me. Perhaps your XNET is outdated? I have no problems with XNET 19.6
It's probably not a good idea sharing DBC files publicly. That said, your database loads perfectly fine for me. Perhaps your XNET is outdated? I have no problems with XNET 19.6 -
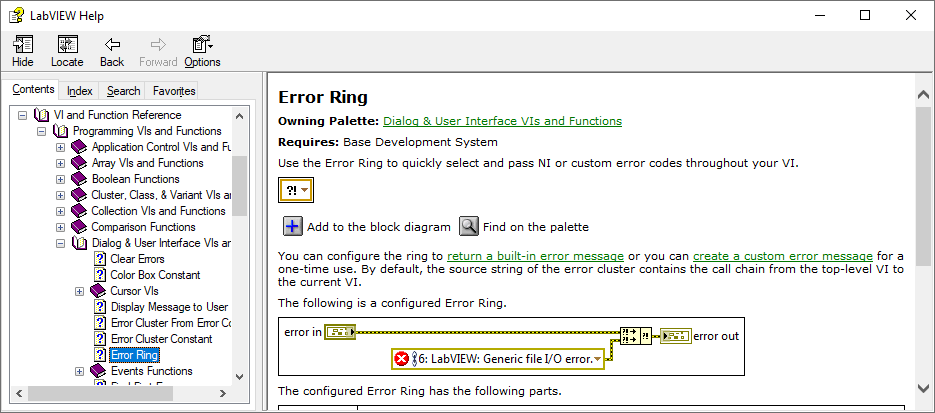
Welcome to LAVA 🎉 Not sure where you read that, here is what the LabVIEW help says: I don't see the benefit. Your projects will take longer to load and if the compiled code breaks you can't even delete the cache, which means you have to forcibly recompile your VIs, which is the same as what you have right now.
-
What you describe is called a fork Forks are created by copying the main branch of development ("trunk") and all its history to a new repository. That way forks don't interfere with each other and your repositories don't get messy.
-
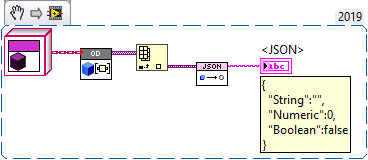
In my opinion NI should finally make up their mind to whether objects are inherently serializable or not. The current situation is dissatisfying. There are native functions that clearly break encapsulation: Flatten To XML Variant To Flattened String Flatten To String Then there is one function that doesn't, although many users expect it to (not to mention all the other types it doesn't support): Flatten To JSON Of course users will eventually utilize one to "fix" the other. Whether or not it is a good design choice is a different question.
-
If you are leaning towards Mercurial you should visit the Mercurial User Group: https://forums.ni.com/t5/Mercurial-User-Group/gh-p/5107
-
Git I don't hate it - the centralized nature of SVN simply didn't cut it for us. No. It was my decision. Pro - everything is available at all times, even without access to a central server. Con - It has too many features, which makes it hard to learn for novice users. Only when I merge the unmergeable, so anything related to LabVIEW 😞
-
Please keep in mind that it is only my mental image and not based on any facts from NI. Perhaps both. If we can understand the current behavior it is easier to explain to NI how to change it in a way that works better for us. Here is an example that illustrates the different behavior when using indicators vs. property nodes. The lower breakpoint gets triggered as soon as the loop exits, as one would expect. I have tried synchronous display for the indicator and it doesn't affect the outcome. Not sure what to make of it, other than what I have explained above 🤷♂️ I agree, this is what most users expect from it anyway. It would be interesting to hear the reasoning from NI, maybe there is a technical reason it was done this way.
-
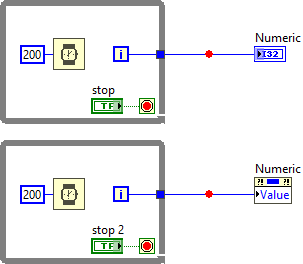
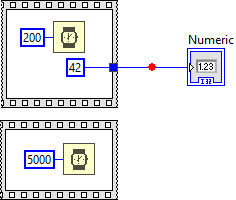
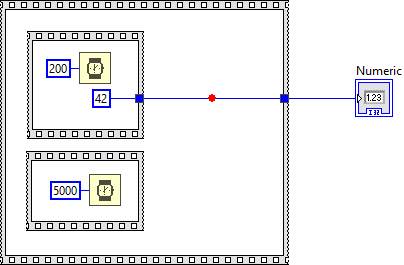
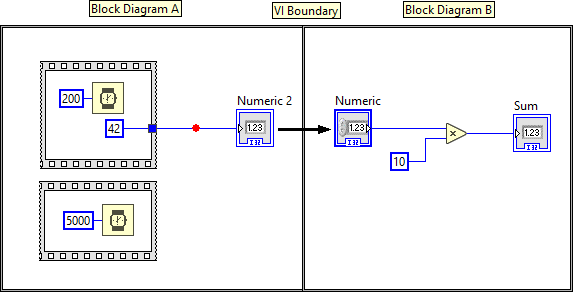
Disclaimer: The following is based on my own observations and experience, so take it with a grain of salt! The user interface does not follow the dataflow model. It runs in its own thread and grabs new data as it becomes available. In fact, the UI update rate is much slower than the actual execution speed of the VI -->VI Execution Speed - LabVIEW 2018 Help - National Instruments (ni.com). The location of the indicator on the block diagram simply defines which data is used, not necessarily when the data is being displayed. In your example, the numeric indicator uses the data from the output terminal of the upper while loop, but it does not have to wait for the wire to pass the data. Instead it grabs the data when it is available. Because of that you can't rely on the front panel to tell dataflow. Execution Highlighting is also misleading because it isn't based on VI execution, but rather on a simulation of the VI executing (it's a approximation at best). LabVIEW simply displays the dot and postpones UI updates until the dot reaches the next node. Not to forget that it also forces sequential execution. It probably isn't even aware of the execution system, which is why it will display the dot on wires that (during normal execution) wouldn't have passed any data yet. Breakpoints, however, are connected to the execution system, which is why they behave "strangely". In dataflow, data only gets passed to the next node when the current node has finished. The same is true for diagrams! The other thing about breakpoints to keep in mind is that "execution pauses after data passes through the wire" --> Managing Breakpoints - LabVIEW 2018 Help - National Instruments (ni.com) In your example, data passes on the wire after the block diagram is finished. Here is another example that illustrates the behavior (breakpoint is hit when the block diagram and all its subdiagrams are finished): Now think about indicators and controls as terminals from one block diagram (node) to another. According to the dataflow model, the left diagram (Block Diagram A) only passes data to the right diagram (Block Diagram B) after it is complete. And since the breakpoint only triggers after data has passed, it needs to wait for the entire block diagram to finish. Whether or not the indicator is connected to any terminal makes no difference. This is also not limited to indicators, but any data that is passed from one diagram to another: Hope that makes sense 😅
-
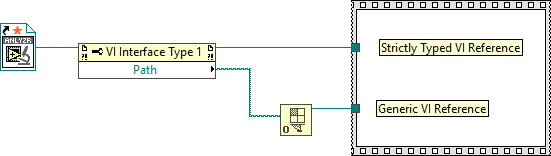
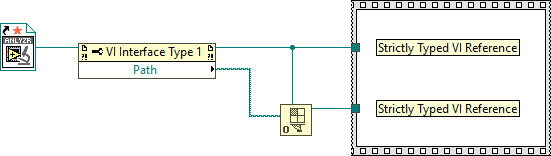
A Static VI Reference is simply a constant Generic VI Reference. There is no way to distinguish one from another. It's like asking for the difference between a string constant and a string returned by a function. The Strictly Typed VI Reference @Darren mentioned is easily distinguishable from a Generic VI Reference (notice the orange ⭐ on the Static VI Reference). However, if you wire the type specifier to the Open VI Refnum function, the types are - again - indistinguishable. Perhaps you can use VI Scripting to locate Static VI References on the block diagram?
-
Sure thing, it's also good to know there is a thread like that - first time I've head of it 😮
-
Is there an "in place" number to string function?
LogMAN replied to infinitenothing's topic in LabVIEW General
The number to string functions all have a width parameter: Number To Decimal String Function - LabVIEW 2018 Help - National Instruments (ni.com) As long as you can guarantee that the number of digits does not exceed the specified width, it will always produce a string with fixed length (padded with spaces). -
Thanks, I'll report this to NI
-
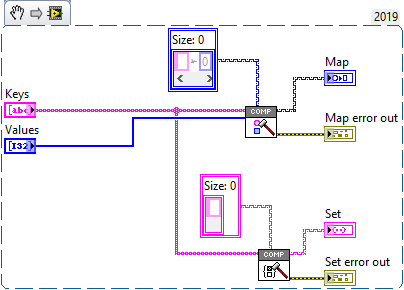
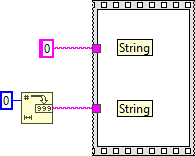
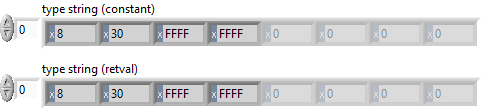
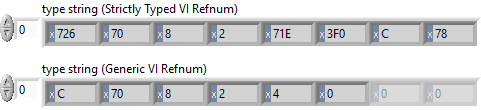
I discovered a potential memory corruption when using Variant To Flattened String and Flattened String To Variant functions on Sets. Here is the test code: In this example, the set is serialized and de-serialized without changing any data. The code runs in a loop to increase the chance of crashing LabVIEW. Here is the type descriptor. If you are familiar with type descriptors, you'll notice that something is off: Here is the translation: 0x0008 - Length of the type descriptor in bytes, including the length word (8 bytes) => OK 0x0073 - Data type (Set) => OK 0x0001 - Number of dimensions (a set is essentially an array with dimension size 1) => OK 0x0004 - Length of the type descriptor for the internal type in bytes, including the length word (4 bytes) => OK ???? - Type descriptor for the internal data type (should be 0x0008 for U64) => What is going on? It turns out that the last two bytes are truncated. The Flatten String To Variant function actually reports error 116, which makes sense because the type descriptor is incomplete, BUT it does not always return an error! In fact, half of the time, no error is reported and LabVIEW eventually crashes (most often after adding a label to the numeric type in the set constant). I believe that this corrupts memory, which eventually crashes LabVIEW. Here is a video that illustrates the behavior: 2021-02-06_13-43-58.mp4 Can somebody please confirm this issue? LV2019SP1f3 (32-bit) Potential Memory Corruption when (de-)serializing Sets.vi
-
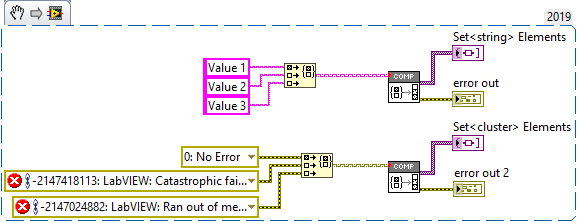
There is a VI in OpenG LabVIEW Data Library that does this for you. I took this as a challenge and added two VIs to my library on GitHub - https://github.com/LogMANOriginal/LabVIEW-Composition Decompose Map extracts variant keys and values of variant maps Decompose Set extracts variant elements of variant sets I have successfully tested these VIs with various different types, but there could still be bugs. Let me know if you find anything. I strongly discourage using these in production!
-
The library is now available on GitHub (including test cases) https://github.com/LogMANOriginal/LabVIEW-Composition I also discovered this project, which provides some useful methods to work with variant data.
-
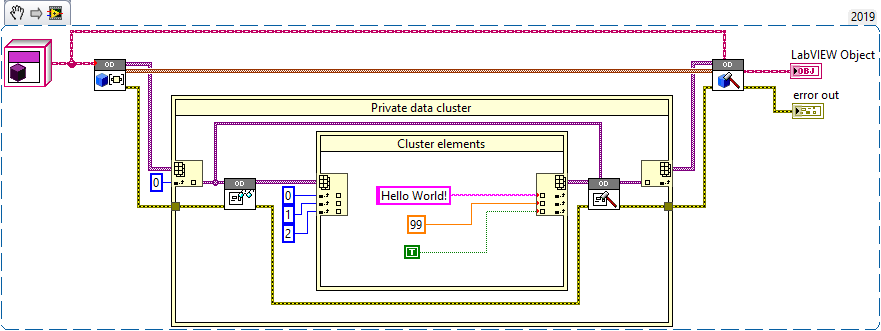
It's a separate library. Object composition was actually much more difficult to figure out than the other way around. I have attached the library for LV2017 (without test suites and package configuration). I'll also put this on GitHub in the near future. Here is an example that overwrites elements in the private data cluster (the outer IPE addresses the class hierarchy). Here is an example that uses JSONtext to extract data from a private data cluster. I was looking into this particular case as a way to transition from clusters to/from objects Both examples are included in the package. Object Decomposition LV2017.zip
-
This was meant as a proof of concept to see if it can be done and if it's something worth investigating. I should probably mention that this branch has a few bugs that I haven't fixed yet. Certainly not something I would use in production right now but still, I believe there is some value in this - especially for general-purpose libraries like JSONtext. Anyway, I'll back save and upload when I have access to LV. By the way, the details are explained on the Wiki: LabVIEW Object - LabVIEW Wiki I haven't found a better way to do this without adding (or scripting) methods to every class. The only function that currently breaks encapsulation natively is Flatten To XML, which has its own limitations.
-
If you are interested in object (de-)composition, I have a library that does most of the heavy-lifting (extracting private data and putting it back together), including functions to work with clusters of any size and shape. I can save it back to LV2017 and post here.
-
Git delete branch after merging Pull Request
LogMAN replied to Neil Pate's topic in Source Code Control
Only the name is deleted, commits are left untouched. It is actually possible to restore the branch name if you know the commit hash - https://stackoverflow.com/a/2816728 This can be useful if you deleted a branch before it was merged into master, or if you want to branch off a specific commit in the history that is currently unlabeled. Here is some documentation from Atlassian, generally applicable to GitHub as well: Git Branch | Atlassian Git Tutorial Pull Requests | Atlassian Git Tutorial -
Git delete branch after merging Pull Request
LogMAN replied to Neil Pate's topic in Source Code Control
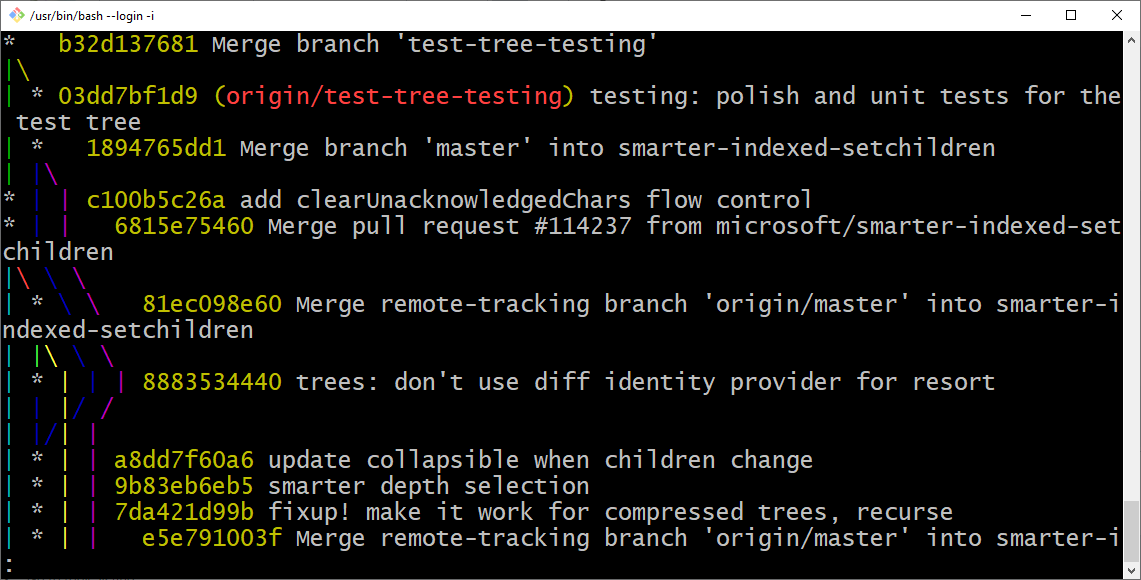
The Network Graph mentioned by @JKSH does give you some visualization on GitHub. I personally prefer the visualization in Sourcetree and bash. Here is an example for GitHub - microsoft/vscode: Visual Studio Code The command I use is git log --oneline --graph You can see that branches still exist even after merging. Only the name of the branch, which is just a fast way to address a specific commit hash, is lost (although it is typically mentioned in the commit message). That said, some branches can be merged without an explicit merge commit. This is called "fast-forward" - https://stackoverflow.com/a/29673993. Maintainers on GitHub can decide if they always want a merge commit, or not.
-
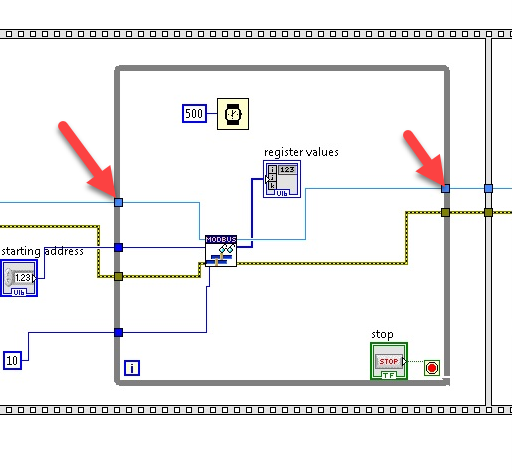
Here is some information about this error: VISA Error -1073807339 (0xbfff0015) Timeout Expired Before Operation Completed - National Instruments (ni.com) There could be many reasons for a timeout error. The error message only indicates that a timeout occurred before a reply was received, which is not very useful. NI IO Trace might give you some additional clues. Maybe put the master in a shift-register on your while loop. Not sure if that makes a difference. This is specified in the Modbus Application Protocol, although implementations vary between 1-based and 0-based. The mapping of addresses is typically resolved internally.
-
Git delete branch after merging Pull Request
LogMAN replied to Neil Pate's topic in Source Code Control
You got it right. "Delete branch" will delete the branch on your fork. It does not affect the clone on your computer. The idea is that every pull request has its own branch, which, once merged into master, can safely be deleted. This can indeed be confusing if you are used to centralized VCSs. In Git, any repository can be remote. When you clone a Git repository, the source becomes remote to the clone. It doesn't matter if the remote is on your computer or on another server. You can even have multiple remote repositories if you wanted to. You'll notice that the clone - by default - only includes the master branch. Git allows you to pull other branches if you want, but that is not mandatory. Likewise, you can have as many branches of your own without having to push them to the remote (sometimes you can't because they are read-only). On GitHub, when you fork a project, the original project becomes remote to your fork (you could even fork a fork if you wanted to...). When you clone the fork, the fork becomes remote to your clone. When you add a branch, you can push it to your fork (because you have write-access). Then you can go to GitHub and open a pull request to ask the maintainer(s) of the original project to merge your changes (because you don't have write-access). Once merged, you can delete the branch from your fork, because the changes are now part of master in the original project (there is no reason to keep it). Notice that the master branch on your fork is now behind master of the original project (because your branch got merged). Notice also that this doesn't affect your local clone (you have to delete the branch manually). You can now update your fork on GitHub, pull from your fork, and finally delete the local branch (Git will warn you about deleting branches that have not been merged into master). There is a page which describes the general GitHub workflow: Understanding the GitHub flow · GitHub Guides Hope that helps. -
How does VIPM set the VI Server >> TCP/IP checkbox?
LogMAN replied to prettypwnie's topic in LabVIEW General
You could run a VI via CLI to turn it on.


PotentialMemoryCorruptionwhen(de-)serializingSets.png.e31ac61a8ef3ee1d71ad471d67565015.png)