Rolf Kalbermatter
-
Posts
3,968 -
Joined
-
Last visited
-
Days Won
281
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-
 It seems you have placed transparent nodes in your VI and wired them all up with transparent wires. 😀 That function is simply expecting specific parameters in the lpInBuffer, and what data should be in there depends on the value of dwCommand. So you have to do some manual work here. First you need to figure out what command you want to use. Look its numeric value up in the header file. Then look the definition of the data structure up in the header file that is in the same row behind the command name in your SDK documentation. As example if you may want to change PTZPOS you need to find the NET_DVR_SET_PTZPOS value which is 292, also documented in the last column of the Remarks table. This number must be passed to the dwCommand value. According to the SDK this command parameter requires the NET_DVR_PTZPOS data structure which is defined like this: struct{ WORD wAction; WORD wPanPos; WORD wTiltPos; WORD wZoomPos; }NET_DVR_PTZPOS, *LPNET_DVR_PTZPOS; You need to build this data structure as a LabVIEW cluster but EXACTLY. In this specific case you need to create a cluster that contains the 4 numeric values of uInt16 integers. You can pass this directly to the functions lpInBuffer parameter by configuring it as Pass Native Datatype. Then you need to calculate the bytes size of that data structure and pass that in as dwInBufferSize. This is 4 times 2 bytes, so 8.
It seems you have placed transparent nodes in your VI and wired them all up with transparent wires. 😀 That function is simply expecting specific parameters in the lpInBuffer, and what data should be in there depends on the value of dwCommand. So you have to do some manual work here. First you need to figure out what command you want to use. Look its numeric value up in the header file. Then look the definition of the data structure up in the header file that is in the same row behind the command name in your SDK documentation. As example if you may want to change PTZPOS you need to find the NET_DVR_SET_PTZPOS value which is 292, also documented in the last column of the Remarks table. This number must be passed to the dwCommand value. According to the SDK this command parameter requires the NET_DVR_PTZPOS data structure which is defined like this: struct{ WORD wAction; WORD wPanPos; WORD wTiltPos; WORD wZoomPos; }NET_DVR_PTZPOS, *LPNET_DVR_PTZPOS; You need to build this data structure as a LabVIEW cluster but EXACTLY. In this specific case you need to create a cluster that contains the 4 numeric values of uInt16 integers. You can pass this directly to the functions lpInBuffer parameter by configuring it as Pass Native Datatype. Then you need to calculate the bytes size of that data structure and pass that in as dwInBufferSize. This is 4 times 2 bytes, so 8. -
Yes, when you posted that link I actually had a bit of a look around and Shaun did apparently the same, seeing his comment that nothing beyond LabVIEW 2018 could be found there.

-
Yes there is. 😆 My Chrome browser is configured to simply not download exe files. The problem is that I wasn't looking for those specific files but rather trying to find something else. And there is a difference now. A few days ago you could simply browse that entire directory tree and find out what was on there. Now the entire softlib subdirectory and all its contents is not browsable anymore. Someone shut a door somewhere. 😀 They probably couldn't rename the entire tree as then the download page for all the products might not work anymore. But that might be just a question of time too.
-
That's harmless 😆. And I think while possibly annoying, at least idealistic. It won't change anyone from driving even one mile less with his car, so likely very ineffective, but everybody needs a cause to live for. 😆 It's effect is also questionable as someone wanting to use cracked software is likely not very much concerned about the state of our earth at that moment, as long as he can start to use his badly anticipated program on his Intel Octium Core monster system with the newest NVidia super duper hardware accelerated graphic card, all of which is only consuming the power that an entire household normally would use. And if that happens in summer, the Airco only has to work a "tiny" little bit harder to get the air temperature to a "comfortable" 19 degree. In winter you even safe some energy as the central heating actually needs to burn less energy. 😎
-
Already terminated, ahem, I mean expired. ☠️
-
LabVIEW memory management different from C ?
Rolf Kalbermatter replied to Youssef Menjour's topic in LabVIEW General
Cryptography and compression/decompression are algorithms that can be significantly faster if done in C and if you really know what you are doing. However doing that requires usually a level of knowledge that simply eliminates the option to tinker yourself with it (ok I'm not talking about a relatively simple MD5 or SHA-something hash here but real cryptography or big number arithmetic). And then you are in the realms of using existing libraries rather than developing your own (see your openSSL example 🙂 ). These libraries typically have specific and often fairly well defined data buffer in and data buffer out interfaces, which is what we are currently talking about. If you can use such an interface things are trivial, as they work with standard C principles: Caller controls allocations and has to provide all buffers and that's it. Simple and quick, but not always convenient as the caller may not even remotely know in advance what size of output buffer is needed. If you need to go there, things start to get hairy and you have to think about real memory management and who does what and when. One thing is clear: LabVIEWs management contract is very specific and there is no way you can change that. Either you follow the standard C route where the caller provides all necessary buffers, or start to work with LabVIEW memory handles and follow its contract to the letter. The only other alternative is to start to develop your own memory management scheme, wrap each of these memory objects into a LabVIEW object whose diagram is password locked to avoid anyone insane enough to think they know better to tinker with it. The fourth variant is to use LabVIEW semi documented features such as external DVRs (there is some sort of minimalistic documentation in the CUDA examples that could be downloaded from the NI site many moons ago), or even more obscure, truly undocumented features such as user refnums and similar things. Venturing into these is really only for the very brave. Implementing C callback functions properly is a piece of cake in comparison 🙂. -
LabVIEW memory management different from C ?
Rolf Kalbermatter replied to Youssef Menjour's topic in LabVIEW General
Generally if you use an external library to do something because that library does things that LabVIEW can't: Go your gang! If you try to do an external library to operate on multidimensional arrays and do things on them that LabVIEW has native functions for: You are totally and truly wasting your time. Your C compiled code may in some corner cases be a little faster, especially if you really know what you are doing on C level, and I do mean REALLY knowing not just hacking around until something works. So sit back relax and think where you need to pass data to your external Haibal library to do actual stuff and where you are simply wasting your time with premature optimization. So far your experiments look fine as a pure educational experiment in itself, but they serve very little purpose in trying to optimize something like interfacing to a massive numerical library like Haibal is supposed to get. What you need to do is to design the interfaces between your library and LabVIEW in a way to pass data around. And that works best by following as few rules as possible, but all of them VERY strictly. You can not change how LabVIEW memory management works Neither can you likely change how your external code wants his data buffers allocated and managed. There is almost always some impedance mismatch between those two for any but the most simple libraries. The LabVIEW Call Library Node allows you to support some common C scenarios in the form of data pointers. In addition it allows you to pass its native data to your C code, which every standard library out there simply has no idea what to do with. Here comes your wrapper shared library interface. It needs to manage this impedance mismatch in a way that is both logical throughout and still performant. Allocating pointers in your C code to pass back and forth across LabVIEW is a possibility but you want to avoid that as much as possible. This pointer is an anachronisme in terms of LabVIEW diagram code. It exposes internals of your library to the LabVIEW diagram and in that way makes access possible to the user of your library that 99% of your users have no business to do nor are they able to understand what they are doing. And no, saying don't do that usually only helps for those who are professionals in software development. All the others believe very quickly they know better and then the reports about your software misbehaving and being a piece of junk start pouring in. -
Yes it is usually the tools that are packed with it to create a fake license or modify the executable to remove the license check, that are at least suspicious or sometimes definitely not just trying to help the person who downloaded it. But I have seen more than once modified installers itself that were not the original one anymore. Why someone would do that other than to modify something inside it to serve a specific purpose definitely escapes me. And I do know of one person who after installing such a hacked installer, I had the pleasure of rescuing his PC. It was nasty to say the least, but before crypto lockers were a commodity. It mostly was limited to having network and registry redirects that made almost every action impossible as it would open either a series of browser windows to all kind of spam, porn and other nefarious sites, or simply displaying a dialog that the executable could not be started. I managed to get it back to a workable state so the data could be rescued, but reformatted the whole disk anyways afterwards. There was simply no way to trust that all traces of nasties were really removed.
-
LabVIEW memory management different from C ?
Rolf Kalbermatter replied to Youssef Menjour's topic in LabVIEW General
Pointers are pointers. If you use DSNewPtr() and DSDisposePtr() or malloc() and free() doesn't matter to much, as long as you stay consistent. A Pointer allocated with malloc() has to be deallocated with free(), a DSNewPtr() must be deallocated with DSDisposePtr() and a pointer allocated with HeapAlloc() must be deallocated with HeapFree(), etc. etc. They may in the end all come from the same heap (likely the Windows Heap) but you do not know and even if they do, the pointer itself may and often is different since each memory manager layer adds a little of its own layer to manage the pointers itself better. To make matters worse, if you resolve to use malloc() and free() you always have to do the according operations in the same compilation unit. Your DLL may be linked with gcc c-lib 6.4 and the calling application with MS C Runtime 14.0 and while both have a malloc() and free() function they absolutely and certainly will not operate on the same heap. Pointers are non-relocatable as far as LabVIEW is concerned and LabVIEW only uses them for clusters and internal data structures. All variable sized data on the diagram such as arrays and strings is ALWAYS allocated as handle. A handle is a pointer to a pointer and the first N int32 elements in the data buffer are the dimension size, followed directly with the data and possibly memory aligned if necessary, N being here the number of dimensions. Handles can be resized with DSSetHandleSize() or NumericArrayResize() but the size of the handle does not have to be the same as the size elements in the array that indicate how many elements the array hold. Obviously the handle must always be big enough to hold all the data, but if you change the size element in an array to indicate that it holds fewer elements than before, you do not necessarily have to resize the handle to that smaller size. Still if the change is big, you anyhow absolutely should do it but if you reduce the array by a few elements you can forgo the resize call. There is NO way to return pointers from your DLL and have LabVIEW use them as arrays or strings, NONE whatsoever! If you want to return such data to LabVIEW it has to be in a handle and that handle has to be allocated, resized, and deallocated with the LabVIEW memory manager functions. No exception, no passing along the start and collecting your start salary, nada niente nothing! If you do it this way, LabVIEW can directly use that handle as an array or string, but of course what you do in C in terms of the datatype in it and the according size element(s) in front of it must match exactly. LabVIEW absolutely trusts that a handle is constructed the way it wants it and makes painstakingly sure to always do it like that itself, so you better do so too. One speciality in that respect. LabVIEW does explicitly allow for a NULL handle. This is equivalent to an "empty" handle with the size elements set to 0. This is for performance reasons. There is little sense to invoke the memory manager and allocated a handle just to store in it that there is not data to access. So if you pass handle datatypes from your diagram to your C function, your C function should be prepared to deal with an incoming NULL handle. If you just blindly try to call DSSetHandleSize() on that handle it can crash as LabVIEW may have passed in a NULL handle rather than a valid empty handle. Personally I prefer to use NumericArrayResize() at all times as it deals with this speciality already properly and also accounts for the actual bytes needed to store the size elements as well as any platform specific alignment. A 1D array of 10 double values does require 84 bytes on Win32, but 88 bytes on Win64, since under Win64 the array data elements are aligned to their natural size of 8 bytes. When you use DSSetHandleSize() or DSNewHandle() you have to account for the int32 for the size element and the possible alignment yourself. If you use err = NumericArrayResize(fD, 1, (UHandle*)&handle, 10) You simple specify in its first parameter that it is an fD (floatDouble) data type array, there is 1 dimension, passing the handle by reference, and the number of array elements it should have. If the array was a NULL handle, the function allocates a new handle of the necessary size. If the handle was a valid handle instead, it will resize it to be big enough to hold the necessary data. You still have to fill in the actual size of the array after you copied the actual data into it, but at least the complications of calculating how big that handle should be is taken out of your hands. Of course you also always can go the traditional C way. The caller MUST allocate the memory buffer big enough for the callee to work with, pass its pointer down to the callee which then writes something into it and then after return, the data is in that buffer. The way that works in LabVIEW is that you MUST make sure to allocate the array or string prior to calling the function. InitializeArray is a good function for that, but you can also use the Minimum Size configuration in the Call Library Node for array and string parameters. LabVIEW allocates a handle but when you configure the parameter in the Call Library Node as a data pointer, LabVIEW will pass the pointer portion of that handle to the DLL. For the duration of that function, LabVIEW guarantees that that pointer stays put in place in memory, won't be reused anywhere else, moved, deallocated or anything else like that (unless you checked the constant checkbox in the Call Library Node for that parameter). In that case LabVIEW will use that as hint that it can pass the handle also to other functions in parallel that are also marked to not going to try to modify it. It has no way to prevent you from writing into that pointer anyhow in your C function but that is a clear violation of the contract you yourself set up when configuring the Call Library Node and telling LabVIEW that this parameter is constant. Once the function returns control to the LabVIEW diagram, that handle can get reused, resized, deallocated at absolutely any time and you should therefore NEVER EVER hold onto such a pointer beyond the time when you return control back to LabVIEW! That's pretty much it. Simple as that but most people fail it anyhow repeatedly. -
The two video streams should be not a problem. The existing library should be able to do that already, you simply need to start the two streams separately with their respective lChannel and direct them to two different windows. And then eventually stop the two streams also separately by calling the Stop Real Play function on each of the respective lRealHandle. That library is meant to do that which is, why the Start Real Play function returns a handle that manages the specific stream. It's what follows after that which will test your patience and your seating leather as you will smack on your ass over and over again when your LabVIEW process crashes on you.
-
If you use libffi or another like library it's relatively simple. C or C++ features alone won't cut it! Unless maybe if you talk about C25 or something like that. 😀
-
Remove the numeric indicator on that Empty.vi. It is a left over from the earlier test. As to using the .Net Picture box for a canvas area to let the SDK library draw its image in, that's also an option. I simply have a distaste for .Net things, especially when using it inside LabVIEW. It feels very dirty. 😀 I was afraid you would say something like this! Good luck on that! You will need it! And you do not want to use IMAQdx here but the IMAQ Vision library. Still, you will need a lot of patience. This so far was just foreplay in comparison to what expects you to get that one working! And I'm absolutely not kidding here, or even slightly exaggerating. Expect to suffer and feel a lot of pain on the path there.
-
It's attached in this message. And downloads just fine here.
-
That wasn't intended for you but dadreamer. So don't worry. 😀 Well, that's good to know. So the whole idea did work after all. I hope that is what you need. If you also need to have the data saved somewhere, look for the according function mentioned earlier. The callback event really won't help you but just make you feel like all the problems so far have been peanuts in comparison. Believe me!
-
I was wondering about that too. But then the scrollbars in the image he posted seem to indicate that that VI is actually properly inserted and the Insert VI method doesn't seem to return an error either. With the limited information that he tends to give and the limited LabVIEW knowledge he seems to have, it is all very difficult to debug remotely though. And it is not my job to do really. Edit: I'll be damned! A VI inserted into a Subpanel does not have a window handle at all. I thought I had tested that but somehow got apparently misled in some ways. LabVIEW seems to handle that all internally without using any Windows support for that. So back to the drawing board to make that not a Subpanel window but instead using real Windows Child window functionality. I don't like to use the main VIs front panel as the drawing canvas as the library would draw all over the front panel and fighting LabVIEWs control and indicator redraws. As to the NET_DVR_GetErrorMessage() call I overlooked that one. Good catch and totally unexpected! It seems that the GetLastError() call is redundant when calling this function as GetErrorMessage() is not just a function to translate an error code but really a full replacement for GetLastError(). Highly unusual to say the least but you get that for reading the documentation not to the last letter. 😆 It's hard to debug such a software without having any hardware to test with, so the whole library that I posted is in fact a dry exercise that never has run in any way as there is nothing it can really run with on my system. Same about the Callback code. I tested that it compiles (with my old but trusted VS2005 installation) but I can not test that it runs properly. Well I could but that would require to write even more C code to create a test harness that would simulate the Hikvision SDK functionality. I like to tinker with this kind of problems but everything has its limits when it is just a hack job in my free time.😀 Attached is a revisited version of the library with the error Vi fixed and it does not use a SubPanel for now but simply lets the Empty.vi stand on its own for the moment. Quick and dirty but we can worry about getting that properly embedded in the main VI after it has proven to work like this. HKNetSDK Interface.zip
-
The HMODULE and HANDLE should be the same, but then I compile in C. You probably compile in C++ and there the compiler is usually a lot more picky. It also likely depends on the Windows SDK that comes with your compiler. Newer versions tend to be a lot more strict about defining data types, especially when using C++ mode. As to the definition for the callback pointer, I was assuming that that is somewhere in the HCNetSDK.h file but didn't check. I compiled it all without that header file. If it is not in there you simply need to copy the definition from the SDK documentation into the file just before that function. Again this should really not spook you out at all. It shows that you are basically not understanding what callbacks are nor how their C syntax is and that you are in for lots and lots of painful lessons even before you can start to wonder about how to make sense of the gibberish that your callback event will report to you. Using that callback will NOT make life for you easier than it has been so far! Rather the opposite! Problems are just starting to pile on you from here on. As far as decoding H264 data goes, you will be on your own from here on. I have no time to deal with that too, as it is going to be a much more involved task than this exercise so far has been.
-
I"m not telling you anything about what to do here. It's strange that FP.NativeWindow seems to return 0 here, it shouldn't and also doesn't on my computer, but that is LabVIEW 2013 in an old Windows 7 VmWare installation (my experimental workhorse). I could try on a new LabVIEW version but really have to do some other, real work too. The problem with that code I showed you is that even if you can compile it and it works as expected, the real trouble for you will only just have started. The data you will receive in that callback event is NOT any standard image data, it is not even decoded. That means you will still have to decode the H264 or some other compressed data packages that you will receive. And honestly that would be even for me quite a task to solve. Basically, despite all that tinkering so far you still wouldn't be really much further than what you could have gotten with the RTSP examples posted on the NI knowledge articles. Well not sure about how the camera wants the login to be solved, that could be a bit of a challenge but after that it is pretty smooth sailing except that the data packages you receive that way are still H264 encoded, respectively G711, G722, G723 or similarly encoded audio packages. But that is not different to what you will get with this callback!
-
There is really no need to guess, you know! There is an error in cluster on EVERY VI (and an error out). You can simply look at the front panel after the VI was invoked. If error in has an error that is pretty obvious, but that would mean that all the functions in that VI do nothing, which could explain why FP.NativeWindow returns 0 as window handle. And after the VI has finished, error out will show an error if error in had an error of course, but also if any function inside the VI encountered any error (that the VI was able to notice).
-
Sigh! That ini file setting has absolutely nothing to do with your video streams. It unhides some VI server properties and methods that NI considers not for end user consumption, either because they are highly special, or not fully tested and only meant for internal use. Also it clutters your VI server property and method hierarchy in a way, that it gets very difficult to find anything. With that setting you should be able to see the FP.NativeWindow property in the property list (And your property node for that property should get a dirty (poopy) brown color to indicate that this is an non-public property that you should not expose to end users if you work at NI). Yes but that is not helpful information. But did you also check that the Start.vi has no error in?
-
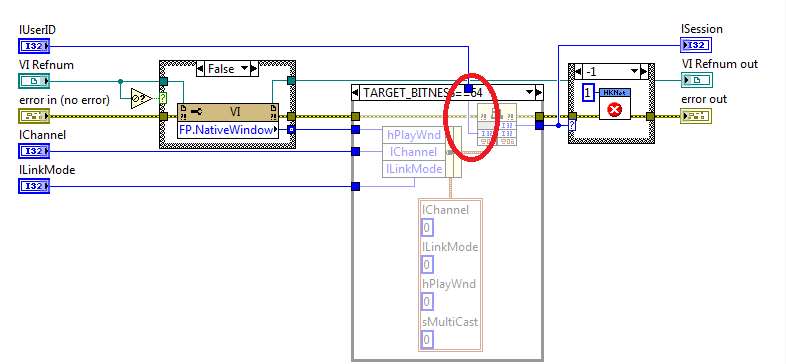
Well, this is clearly the problem. Somehow the FP.NativeWindow does not return a valid handle. There are three possible reasons. 1) NI disabled that node in later LabVIEW versions but I have no idea why they would have done that. It is an undocumented property of course, but that doesn't mean that it should suddenly stop to work. 2) The other is that the front panel of the Empty.vi is not open. But looking at the scrollbars inside the subpanel, it definitely looks like the panel is loaded. Also the Insert VI method for the subpanel did obviously not return an error either. So I'm a bit at a loss. The FP.NativeWindow property simply returns non-0 value on my system. 3) There is an error in on the Start vi. but you of course obscured that part of the VI, so we can't say if that is the reason. lUserID being 0 looks slightly suspicious but of course it could be a valid value since the documentation for the NET_DVR_Login_V30() function states that this is 0 or higher on success, and -1 indicates an error. And I take issue with your comment about the example code I provided being a mess. 😆
-
That shows nothing! What is the value of the FP.NativeWindow indicator? It should be something else than 0. You can change the value of the hPlayWnd control in that cluster to whatever you would like, it should be overwritten by the Bundle by Name node above with the handle value retrieved from the FP.NativeWindow property. You really should take some of the LabVIEW tutorials first. You try to play with guns and canons but haven't really understood how to operate the basics of using the matches.
-
It's documented in the SDK help file although I did not find it in the menu tree. But when you are looking at NET_DRV_RealPlay_v30() there is a reference to it at the end of that page. It's probably the original RealPlay function in V1.0 of the SDK, then they added V30 and later V40 of these functions and most likely each older version calls in fact the latest V40 with the unused values set to NULL or some default. "Not executed" in your probe window means that the code in that frame was not executed. It's as simple as that! And if it was not executed, you have probably not pressed the "start" button (after creating that probe). Then the probe [5] indicates that you apparently did execute the "start" frame and the output of the NotARefnum function is correctly False, since NOT being NotARefnum means that it was a valid refnum and therefore we can try to retrieve its native window handle to pass to the RealPlay function. That native window handle should then be something else than 0.
-
No! My example tries to replicate your posted Preview code. In there is only the exception callback which is used for error reporting to the user application and which I dutifully ignored to make the example more simple. Instead I did try to implement proper error handling by using the return value of each API call and requesting the last error information if that return value indicates an error. This should be more than enough for simple example code, most example code out there simply ignores any and all errors, which I find a very bad practise as when something doesn't work you have no idea where it starts to fail. The SDK documentation seems to indicate that this exception callback is optional so it should not affect the operation of the sample. That code does a number of things and some are completely wrong. 1) Forget about trying to write to that PS file in the callback. If you really wanted to have such a file you could simply just call NET_DVR_SaveRealData_V30() on the handle returned from NET_DVR_RealPlay() or NET_DVR_RealPlay_V30() and be done with it without having to bother about setting your own callback. 2) PostLVUserEvent() expects a valid native LabVIEW memory buffer to be passed to and that needs to match the event data type EXACTLY! For a LabVIEW array this is a LabVIEW array data handle. 3) The dwDataType parameter of the callback function is important in order to determine what type of data is in the buffer. You need that when trying to interpret the contents of the buffer, so you need to pass that to LabVIEW as well somehow. 4) Rather than storing the EventRefnum in a global to be referenced from the callback function I would instead pass that information through the user data pointer when installing the callback. LVUserEventRef *pUE; void SendEvent(LVUserEventRef *rwer) { pUE = rwer; } 5) This code stores the address where LabVIEW placed the refnum when passing it to the SendEvent() function. That address is almost 100% certainly used for something else by the time your callback function comes around to try to use it. You need to store the refnum instead, not the reference to it!. But this probably saved you from nasty crashes because PostLVUserEvent() does verify that the user event refnum is valid before doing anything. If it had tried to process the passed in data according to the user event data type your code for sure would have crashed immediately!!! This is a simple example of how a proper callback implementation would look like: #include "extcode.h" #include "hosttype.h" #include "HCNetSDK.h" #define LibAPI(retval) __declspec(dllexport) EXTERNC retval __cdecl #define Callback(retval) __declspec(dllexport) EXTERNC retval __stdcall // Define LabVIEW specific datatypes to pass data as event // This assumes that the LabVIEW event datatype is a cluster containing following elements in exactly that order!!! // cluster // int32 contains the current live view handle // uInt32 contains the dwDataType (NET_DVR_SYSHEAD, NET_DVR_STD_VIDEODATA, NET_DVR_STD_AUDIODATA, NET_DVR_PRIVATE_DATA, // or others as documented in the NET_DVR_SetStandardDataCallBack() function // array of uInt8 contains the actual byte stream data #include "lv_prolog.h" typedef struct { int32_t size; uint8_t elm[1]; } LVByteArrayRec, *LVByteArrayPtr, **LVByteArrayHdl; typedef struct { LONG realHandle; DWORD dataType; LVByteArrayHdl handle; } LVEventData; #include "lv_epilog.h" Callback(void) DataCallBack(LONG lRealHandle, DWORD dwDataType, BYTE *pBuffer, DWORD dwBufSize, DWORD dwUser) { LVEventData eventData = {0}; MgErr err = NumericArrayResize(uB, 1, (UHandle*)&(eventData.handle), dwBufSize); if (!err) { LVUserEventRef userEvent = (LVUserEventRef)dwUser; MoveBlock(pBuffer, (*(eventData.handle))->elm, dwBufSize); (*(eventData.handle))->size = (int32_t)dwBufSize; eventData.realHandle = lRealHandle; eventData.dataType = dwDataType; PostLVUserEvent(userEvent, &eventData); DSDisposeHandle(eventData.handle); } } typedef BOOL(__stdcall *Type_SetStandardDataCallBack)(LONG lRealHandle, fStdDataCallBack cbStdDataCallBack, DWORD dwUser); LibAPI(BOOL) InstallStandardCallback(LONG lRealHandle, LVUserEventRef *refnum) { HANDLE hDLL = LoadLibraryW(L"HCNetSDK.dll"); if (hDLL) { Type_SetStandardDataCallBack installFunc = (Type_SetStandardDataCallBack)GetProcAddress(hDLL, "NET_DVR_SetStandardDataCallBack"); if (installFunc) { return installFunc(lRealHandle, DataCallBack, (DWORD)(*refnum)); } FreeLibrary(hDLL); } return FALSE; } Compile this with your favorite C/C++ compiler. Do not pass .Net, C# or anything like that. They are a detour that can only complicate the matter even more for you but not solve any problems for you, even if you are afraid of C/C++ like the devil is afraid of holy water. The InstallStandardCallback() function is a convenience function. It tries to dynamically load the HCNetSDK.dll to avoid problems when this DLL containing the callback implementation is loaded before LabVIEW loaded the HCNetSDK.dll itself. Instead you could do a LoadLibrary("<yourDLLName>") call on this DLL in LabVIEW instead, then a GetProcAddress(hDLL, "DataCallBack") and then pass the according pointer as a pointer sized integer in LabVIEW to the Call Library Node that you created to call the NET_DVR_SetStandardDataCallBack() function. In that case you will also need to Typecast the LabVIEW user event refnum into an uInt32 integer and pass that as third parameter to the NET_DVR_SetStandardDataCallBack() function which has this parameter configured as uInt32 Numeric. You can not use pass Native Data Type here, since LabVIEW insists on passing a reference to the refnum in that case and then you start to get the same problem as is explained in point 5) above. And before you cry victory, consider another very important point: The SDK library will push data down your callback no matter if you process them in LabVIEW or not. If your user event loop serving that user event is not ready or can't keep up with that data stream, the user event queue in LabVIEW will get stuffed with event data messages with potentially huge byte array data in them and after some time it will simply post a threaded Out Of memory dialog that gives you exactly one option, to abort everything and lose whatever work you have not yet stored. So beware!!!! You are trying to bite off chunks from a cake, that is in many areas far beyond your knowledge. - Callback functions are complicated even for very seasoned C programmers. - Memory management is complicated, also for pretty experienced C programmers. - LabVIEW uses a very specific memory management that is required to allow it to optimize its operations. This memory management contract is not any more complicated than what a .Net library would use, but it is different. And no LabVIEW is not the problem here to not follow .Net. LabVIEW was invented in 1986 and its current memory management system was created somewhere around 1990, give or take a year. .Net was first introduced in 2003 so there is no way the LabVIEW developers could have anticipated what Microsoft will invent about 15 years later. LabVIEW shields you away from these difficulties almost completely but only if you stay within LabVIEW. Once you start interfacing to external code you have to consider and understand all these things fairly intimately, and in addition to that you have to understand the memory management requirements of the library you are interfacing to, which may or may not be well designed, but never designed to be compatible with LabVIEW, unless developed by a LabVIEW developer such as the IMAQ Vision library is. - And last but not least: Image handling is complicated, and video handling even more so, even if you stay with LabVIEW ready made libraries. If I had access to a HikVision camera, even one somewhere officially published on the internet as I do not want to hack anyones private door bell or security camera, I could do more testing, but I'm for obvious reasons not feeling inclined to pay 150 Euro or more, just to buy such a camera to do these tests.
-
My library does not use ANY callbacks. That was not the aim of it! Instead I tried to implement the Preview example code that you showed in a LabVIEW way. There is a callback in your Preview example code but it is NOT meant for receiving image data but to send exceptions to an app. Exceptions are when the library sees abnormal things such as errors happening and then it will send an according exception message through this callback. I completely omitted this callback as it does not seem that important to me. Instead I implemented proper error handling for all SDK functions that get called. That should be more than enough for now and that exception callback could be added once everything else is working perfectly. This SDK seems to have a number of different options. You can simply connect to the camera and retrieve an image occasionally and save it to disk. You can pass a windows handle in the lpClientInfo struct and the driver then is supposed to draw its image data into that window. This is what I tried to implement. And you can install a number of callback functions which are then continuously called by the driver to pass the image data frames to it. This callback function is the hard part and not just because you have to provide it. This will require you to write some C code to implement that function and then you have to find a way to pass this data back to LabVIEW, which the PostLVUserEvent() function MIGHT help with. But the data that this function receives is in a, let's say barely documented format. They talk a little about a proprietary format, and mention repeatedly that it can also contain simply network packets, which would be the H264 encoded data stream and you are back at square one. Also the SDK documentation is a little hard to read. Sometimes the text is hilarious, but sometimes it is simply confusing Extra note: are you by any chance using 64-bit LabVIEW? If so check your HKNetSDK:Start function. In there is a conditional compile structure and the 64-bit case is missing a very important wire.
-
Nope. That is something entirely different! I'm not making use of any message hooking library here that you might need to prime a some point. I'm simply using that empty VI to get a front panel whose window handle I can use to pass to the RealPlay function so it has a graphics port to draw its image into. That's it. I could have used the main VI instead but that would then cause the RealPlay function to attempt to draw into that and by doing so fight with LabVIEW trying to update the button areas as you press them. With this empty VI there is no LabVIEW trying to fight with the RealPlay task and you can insert it into a subpanel anywhere on a front panel and have other things besides it on that front panel However the logic is such that you have first to connect and only in start is the windows handle then passed to the SDK function, so your crash during the connect function has nothing to do with it since that VI is not yet active at that point.