Rolf Kalbermatter
-
Posts
3,975 -
Joined
-
Last visited
-
Days Won
283
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-
Why?
-
No, and there likely never will be! NI has a very strong tendency to never ever talk about what might or might not be, unless the actual release of something is pretty much announced officially. In the old days with regional field sales offices you could sometimes get some more details during a private business lunch with the field sales office manager (usually with the request to please not share it with anyone else, since it wasn't yet official and in fact might never really materialize in that exact way). The only thing we know is that the LabVIEW source code was in some escrow and supposedly still likely is, for the case NI might end up with its belly up. How much that really means, other than to sooth managers who were worried about choosing for a single vendor software solution, I can't really say. It certainly doesn't mean that the LabVIEW source code automatically will be Open Source if NI folds up or decides to shut down LabVIEW development. Selling the rights to it to some other party who declares its intention to somehow continue its development, is almost certainly enough to fulfill all obligations of such an escrow agreement. As Brian (Hooovahh) already mentioned, open sourcing LabVIEW is not an easy task. Aside from old legacy "crimes" committed in the early days of LabVIEW development (and often technically unavoidable since there simply weren't better technologies available, LabVIEW pushing the economically available hardware to its limits, and/or LabVIEW's source code requirements pushing the limits of what C compilers could do back then), there are also things that are likely simply not open sourceable for several legal reason. Reworking the source code to be able to publish it as open source would be costing a significant effort. And who is going to foot that bill, after NI is gone or decided to stop LabVIEW development?? For instance, I'm pretty sure that almost nothing of the FPGA system would be legally open sourceable, since it is probably encumbered with several NDAs between NI and Xilinx. And there are likely several other parts that under the hood are limited in similar ways. Even just the effort to investigate what could and what couldn't be open sourced is going to cost some serious legal and engineering man power and with that also real money. Then someone has to remove anything that was identified as being impossible or undesirable to be open sourced and clean up the mess after that. This in itself would be likely a serious project. And then what? Who is going to maintain a project like that? .Net Core only really is successful because Microsoft puts its might behind it. Without Microsoft's active support role it would be still Mono, hopelessly trying to catch up with whatever new thing Microsoft comes up with.
-
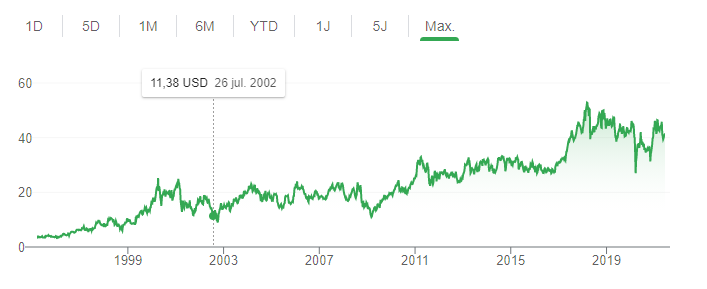
It very much depends how much back you dare to look in that graph! 😀 Since it is a NASDAQ share you should rather go to the source, Luke! That steep climb around 2017 is actually after they started implementing those changes. The decline you see is mostly happening during Covid but as a trend not quite very significant yet. That all said, the current trend to measure everything in share price is a hype that is going to bring us the next big crash in not to much time. My guess is that once most people have crawled out of their covid imposed isolation in their private hole, they will look at the financial markets and wonder where the actual real world value is, that some of the hyped companies would need to have, to make their share price expectations even remotely true. And then the big awakening happens when the first people start to yell "but he isn't wearing any clothes".

-
I don't have these numbers. What I know is that a few years ago, NI noticed that their sales figures were starting to flatten. For a company used to have high two digit growth numbers year after year this is of course a very alarming signal. 😀 They hired some consultants who came to the conclusion that the traditional T&M market NI was operating in simply didn't have left much more air in it to continue to support the growth NI had been getting used to. And strategic decisions were made behind the scene. Not to much of that has been openly communicated yet, but the effects have been quite obvious in the past few years. NI has deprioritized the PC based test and measurement hardware, completely abandoned any motion ambitions, marginalized their vision ambitions and put much of the traditional DAQ hardware into legacy mode. And their whole sales organization has been completely revamped. No field sales offices anymore, highly centralized technical support by typical call center style semi-outsourced places. Behind the scene they do large scale business and have increased their sales further since that alarming consultancy report. So somehow it seems to work. One reason they may not have been very public about these changes is probably that it did change their old model of relying very heavily on external Alliance Members for actual application support of all their customers. In a few strategic industries they now have moved in to deliver full turn key systems themselves directly to the customer. For the typical Alliance Member that probably doesn't directly mean loss of business, since the customers and projects NI serves in this way are accounts that only very few Alliance Members would dare to even consider to look at, as the volume of the business transaction is simply very huge. However it certainly has other effects for all Alliance Members. The contact with NI has been getting very indirect with all the regional sales offices having vanished and the efforts from NI to compensate that with other means haven't gotten much further than marketing presentations with lots of nice talk up to this point. As to LabVIEW: It's demise has been promised since it was first presented. First because it was clearly just a toy that no engineer ever could take seriously, then because NI didn't push for an international standard to formalize the LabVIEW G language, later because they didn't want to open source it. I'm not sure any of these things would have made a significant difference in either the positive or negative direction. It's clear that LabVIEW is nowadays a small division inside NI that may or may not find enough funding by the powers to be, to maintain a steady development. If you look at the software track record of NI it doesn't look to well. They bought many companies and products such as HIQ, Lookout with Georgetown Systems, DasyLab, and quite a few more, and none of them really exists nowaday. Of course a lot of them such as DasyLab were in fact simply buying out competition and it was clear from the start that this product has not a very bright future in the NI stall. Lookout was marketed for quite some time, a lot of its technology integrated into LabVIEW (LabVIEW DSC was directly build on top of much of Lookouts low level technology and the basis for the low level protocols used in Shared Variables and similar things). LabWindows/CVI is lingering a semi-stasis existence for several years already. It's development can't quite keep pace with the main contenders in the market, GCC and Visual Studio. In view of this, acquisitions like Digilent and MCC may look a bit surprising. On the other hand it might be a path to something like a HP/Agilent/Keysight diversification. NI itself moves into the big turn key semiconductor testing business (and EV testing market), one of these other companies takes over the PC based LabVIEW, DAQ, and instrument control business.
-
That's always debatable. From a technical point of view I fully agree with you. LabVIEW is a very interesting tool that could do many more things if it had been managed differently (and also a few less than it does nowadays). For instance I very much doubt it would have ever gotten to the technical level it is nowadays if a non-profit organization had been behind LabVIEW. The community for LabVIEW is simply to diverse. The few highly technical skilled people in LabVIEW world with a very strong software engineering background, who could drive development of such a project in an Open Source model, do not reach critical mass to sustain its continued improvement. On the other end of the scale you have a huge group who want to use LabVIEW because there is "no programming involved", to parodize some NI marketing speak a bit. Maybe just maybe, an organization like CERN could have stepped in just as what happened with KiCAD. KiCAD lingered for a long time as a geeky Open Source project with great people working on it in the typical chaotic Open Source way. Only when an organization like CERN put its might behind it, did the project slowly move into a direction where it could actually start to compete on features and stability with other packages like Eagle PCB. It also brought in some focus. CERN is (or at least has been) quite a big user of LabVIEW so it could have happened. CAD development moved in the meantime too, and while KiCAD nowadays beats every CAD package that was out there 20 years ago hands down, the current commercial CAD platforms offer a level of integration and highly specialized engineering tools, that require a lot of manual work when tried in KiCAD. Still, you can design very complex PCBs in KiCAD nowadays that would have been simply impossible to do in any CAD package 20 years ago, no matter how much money you could have thrown at it back then. But LabVIEW almost certainly would not cross compile to FPGA nowadays, and there would be no cRIO hardware and similar things to which it almost seamlessly compiles to, if it had not been for NI. On the other hand, LabVIEW might actually be a common teaching course at schools, much like Python is nowadays on the ubiquitous Arduino hardware, if NI had decided that they want to embrace LabVIEW being a truly open platform. The reality is, that we do live in a capitalistic system, and that the yearly earnings is one of the highest valued indicators for success or failure of every product and company. Could LabVIEW have been and being managed differently? Of course! Could it have survived and sustained a steady and successful development that way? Maybe!
-
There is a standard digital signal available in the FPGA environment that allows resetting the device. You can assert this pin from your FPGA program. So one way would be to add to your FPGA program a small loop that polls the external digital signal (preferably with some filtering to avoid spurious resets) and then feed that signal to the FPGA Reset boolean signal.
-
NI didn't say they would be porting NXG features to 2021, but to future versions of LabVIEW. Technically such a promise would have been unfulfillable, since at the time the NXG demise was announced, LabVIEW 2021 was basically in a state where anything that was to be included in 2021 had to be more or less fully finished and tested. A release of a product like LabVIEW is not like your typical LabVIEW project where you might make last minute changes to the program while testing your application at the customer side. For a software package like LabVIEW, there is a complete code freeze except for breaking bug fixes, then there is a testing, packaging and testing again cycle for the Beta Release, which typically takes a month or two alone, then the Beta phase of about 3 to 4 months and finally the release. So about 6 months before the projected release date, anything that is not considered ready for prime time is simply not included in the product, or sometimes hidden behind an undocumented ini file setting. Considering that, the expectation to see any significant NXG features in LabVIEW 2021 was simply blue eyed and irrational. I agree with you that LabVIEW is a unique programming environment that has some features that are simply unmatched by anything else. And there are areas where its age is clearly showing such as lack of proper Unicode support, and related to that the lack of support for long path names. Personally I feel like I could tackle the lower level part of full Unicode support in LabVIEW including full Unicode path support quite easily if I was part of the development team, but have to admit that the higher level integration into front panels and various interfaces is a very daunting task that I have no idea how I would solve it. Still, reworking the lower level string and path management in LabVIEW to fully support Unicode would be a first and fundamental step to allow the other task of making this available to the UI in a later stage. This low level manager can exist in LabVIEW even if the UI and higher level parts don't yet make use of it. The opposite is not possible. That is just one of many things that need some serious investment to make the whole LabVIEW platform again viable for further development into the future. This example also shows that some of the work needed to port NXG features back to LabVIEW require first some significant effort that will not immediately be visible in a new LabVIEW version. While such a change as described above is definitely possible to do within a few months, the whole task of making whole LabVIEW fully Unicode capable without breaking fundamental backwards compatibility, is definitely something that will take more than one LabVIEW version to eventually fully materialize. There are a few lower hanging fruits that can help prepare for that and should have been done years ago already but were discarded as "being already fixed in NXG" but the full functionality just for full Unicode support in LabVIEW is going to be a herculean task to pull off, without going the path of NXG to reinvent LabVIEW from scratch (which eventually proved to be an unreachable feat). My personal feelings about the future of LabVIEW are mixed. Not so much because LabVIEW couldn't have a future but because of the path NI as a company is heading. They have been changing over the last few years considerably, from an engineering driven to a management driven company. While in the past, engineers had some real say in what NI was going to do, nowadays it's mostly managers who see Excel charts, sale numbers and the stock market exchange as the main decision making thing for NI. Anything else has to be subordinated to the bigger picture of a guaranteed minimum yearly growth percentage and stock price. The traditional Test & Measurement market NI has served for much of its existence is not able to support those growth numbers anymore. So they are making heavy inroads into different markets and seem to consider the traditional T&M market by now just as a legacy rather than a significant contributor to their bottom line.
-

Can Queues be accessed through CIN?
Rolf Kalbermatter replied to Taylorh140's topic in Calling External Code
Well, ultimately everything LabVIEW does is written in C(++). Some (a very small part of it) is exported to be accessible from external code. Most goes a very different and more direct way to calling the actual C code functions. Functions don't need to be exported from LabVIEW in order to be available for build in nodes to be called. That can all happen much more directly than through a (platform depending) export table. -
Can Queues be accessed through CIN?
Rolf Kalbermatter replied to Taylorh140's topic in Calling External Code
No! Your guesswork got you in many ways wrong. AZ and DS memory spaces is an old Mac OS Classic programming distinction. AZ memory could be automatically relocated by the OS/kernel unless it was explicitly locked by the user space application. DS memory stays always at a fixed memory location. It also meant that when you try to access AZ memory and didn't lock it first with AZLock() you could badly crash if the OS decided that it needed that space and moved the memory (possibly into a cache file) during the time you tried to access that memory block. With modern virtualized memory manager hardware support in modern OSes such as Windows NT and MacOS X, this distinction got superfluous. In user space memory nowadays always behaves as appearing at fixed virtual memory address location. Where it is actually stored in real memory (or a disk cache file) is all handled transparently by the OS virtual memory manager supported by a powerful hardware memory management unit directly integrated in the CPU. As soon as NI sacked support for MacOS Classic in LabVIEW, they also removed consequently the AZ memory manager completely. In order to support old legacy C code and CINs using the AZ memory manager functions explicitly, the exports still exist but simply are linked to the corresponding DS counterparts where existing, and for those that have no DS counterpart like the Lock and Unlock functions they simply call an empty function that does nothing. The actor framework as far as I know does not use explicit C code for anything but simply builds on the existing LabVIEW OOP technology so I'm not quite sure what you refer to here. The old LVOOP package used a technique similar to what was used in the old CINs for the queues, semaphores, notifiers and rendevous functions, to store the "class" data for a specific object instance in a sort registry to implement some sort of class support before the native LabVIEW OOP was introduced, but that wasn't really using any build in queues or similar functionality internally (as that build in functionality didn't fully exist at that time either). As to using a LabVIEW created DLL running in a seperate application instance, this is actually more complicated than you might guess. That is one aspect that I find makes the use of LabVIEW created DLLs for use in LabVIEW itself extra maintenance intense. If the DLL was created in the same LabVIEW version (or compiled to be executable in a newer runtime version than build since LabVIEW 2017), LabVIEW will load the DLL into the current application instance. If the versions don't match and the option to execute the DLL in a newer runtime version wasn't enabled when building that DLL, LabVIEW will startup the according LabVIEW runtime system, load the DLL into it and setup interprocess marshalling to execute every call to this DLL through it. Needless to say that this has some implications. Marshalling calls across process boundaries costs time and resources so it is less performant than when it is all happening in process. And as you noted, the application instance separation will prevent access of named resources such as queues between the two systems. And this possible marshalling is so transparent to a normal user that he may never ever guess why his queue he created through the DLL call doesn't share data with another queue he "obtained" in the native LabVIEW code. Logically they are totally different entities but the fact if they are or not may depend on subtle differences of what LabVIEW version was used to create your DLL and what LabVIEW version you call it from. As to handles I'm not quite sure what PDF you refer to. The whole handle concept originates from the Mac OS Classic days. And MacOS had handles that could be directly created by external code through calls to the MacOS Classic Toolbox. LabVIEW had special primitives that could refer to such handles so that you did not need to copy them always between the external handle and a LabVIEW handle. That support was however very limited. You basically had a Peek and Poke function only with a handle input and an offset in addition to the value. This functionality never made sense on non Mac OS Classic platforms although I believe the primitives still existed there but where hidden. No need to confuse the user with an obscure feature that was totally useless on the platform in question. Even on Mac OS it was hardly ever used except maybe for a few hacky NI interfaces themselves. Almost all of this information has mostly just archeological value nowadays. I'm explaining it here to save you from going down some seemingly interesting path that has absolutely no merits nowadays. -
Can Queues be accessed through CIN?
Rolf Kalbermatter replied to Taylorh140's topic in Calling External Code
I understand and admire your reverse engineering effort 😀. My answer was partly directed to the OPs claim that the Occurrence API was documented. It's not (at least officially although the accidental leak from early LabVIEW days could be counted as semi official documentation). You're right that those functions you mention as lacking from those headers didn't even exist back in those days. They were added in the meantime in later versions. The additional 50MB of code in LabVIEW.exe aren't just useless garbage. 😀 (And only a fraction of what LabVIEW gained in weight over those 30 years since all the manager core is now located in external DLLs). That also points out another danger of using such APIs. They are not fixed unless officially documented. While NI generally didn't just go and change existing functions for the fun of it, they have only gone to extreme lengths to avoid doing that for functions that are officially documented. Any other function is considered fair game to be changed in a later LabVIEW version if the change is technically necessary and not doing so would require a big extra effort. This is also the main reason they haven't done any documentation of new functions (with very few exceptions such as PostLVUserEvent() ) since the initial days. Once officially documented, that API has to be considered cast in stone and any change to its prototype or even semantical behaviour is something that is basically considered impossible unless absolutely unavoidable for some reason. -
Can Queues be accessed through CIN?
Rolf Kalbermatter replied to Taylorh140's topic in Calling External Code
It means you COULD theoretically interact with Queues from your own C code. In reality the function name alone is pretty useless. And there is NO publically available documentation for these functions. Theoretically if you are an important enough account for NI (requires definitely 7 digits or more yearly sales in US$ for NI) are willing to sign over your mother, wife and children in an NDA document in case you breach it, you may be able to get the headers for these APIs. In practice the only people with access to that information do work in the LabVIEW development team and would likely get into some serious problems if they gave that to someone else. If you really need it, there is a workaround though that comes with much less financial and legal trouble but can get a bit of a maintenance problem if you intend to use it in multiple LabVIEW versions and platforms: Create a LabVIEW library that wraps the Queue functions you are interested in into some VIs, create a DLL from those VIs and export them as function, then call those functions from this DLL from within your C code. -
Can Queues be accessed through CIN?
Rolf Kalbermatter replied to Taylorh140's topic in Calling External Code
No, it's not odd! Occurrences exist in LabVIEW since at least version 2.5. And back then NI sort of made a slip by distributing the full internal extcode.h file that exposed pretty much every single function that LabVIEW exported and could be accessed from a CIN (the only way to call external code back then). They fixed that in subsequent releases of 2.5.x (which was a pre release version of LabVIEW for Windows 3.0). Much of what was declared in that header was fairly useless anyways, either because it only was usable with other parts of LabVIEW that were not accessible from external code, or because the functionality was to complex that it could be inferred from just the header alone. NI never officially documented the Occurrence functions but someone with access to those OOOOOOLD headers can simply take them from there, which this poster probably did. There is one caveat though: While those functions probably remained the same, the documentation posted is most likely from those 2.5 headers and might be not entirely accurate anymore with the current prototype of the functions as LabVIEW exports them nowadays. The Queues, Semaphores and Notifiers that came out with LabVIEW 4 or 5, were indeed CIN based. The CIN implemented the entire functionality using internally Occurrences for the signal handling to allow low cost CPU waits. Around LabVIEW 6 or 7 the full CIN code for the Queues and Notifiers was revamped and fully moved into the LabVIEW kernel itself and integrated as built in nodes. Semaphores and Rendezvous were reimplemented in LabVIEW code using internally Queues. Since there are no headers floating around on the internet from LabVIEW 7 or later dates, the declarations for the Queues and Notifiers are nowhere to be found although with enough time at hand and ignorance of the LabVIEW license terms, one could in fact reverse engineer them. The problem with that is that you can never quite be sure that you got it all right even if it doesn't crash at the moment. That makes this a pretty useless exercise for real use of these APIs and for just some hobby usage, the effort is both too high and requires way to specialistic knowledge. Only crazy nerds disassemble code nowadays and only super crazy nerds do that with an executable of the size of LabVIEW. 😀 -
Input registers are a totally different entity than holding registers and the Modbus protocol uses different function codes to read them. And a third function code to write to the holding registers. The LabVIEW VIs hide this function code from the user but you have to use the correct read function to cause the correct registers to be read.
-
Most problems about Modbus communication are related to the different address notations that are commonly used and the fact that some are 0 based while others are 1 based. I also find the distinction between registers, holding registers, coils, and discrete inputs rather confusing. Basically discrete inputs are boolean inputs, coils are boolean outputs and registers are 16 bit inputs and holding registers are 16 bit outputs. Then there is the fact that two registers can often be used together as a 32-bit register or a 32-bit floating point number but as far as the Modbus protocol is concerned need to be treated as 2 consecutive 16-bit values. The valid address range for each of these four types is 0 - 0xFF00 But there is an alternative address writing called entity form. Here the first digit indicates the type of register (0 - coils, 1 - discrete input, 3 - input register, 4 - holding register) and the next four digits indicate the entity address which is 1 based. There are many LabVIEW libraries to do Modbus, but most of them do use the standard address and function code input. Not sure which library you exactly use, but that 256 needs some checkin. 0x200 would be 512 in decimal notation.
-
Exchanging data between applications
Rolf Kalbermatter replied to emcware's topic in LabVIEW General
There is and it is called Interapplication Communication. Which one to use depends on the platform and your familiarity with a specific method. - File IO (multiplatform, trivial to setup, difficult to manage as you have to deal with concurrency of two applications trying to access the same file) - DDE (Windows only, ultra ancient and much older than legacy, don't ever use it if you can help it) - Shared memory (super high throughput, complicated to use, pretty different APIs and methods on each platform) - (D)COM (Windows only, complicated to use from anything else than C(++). - Pipes (Standard method on Unix, LabVIEW supports it on Unix platforms only, Windows has pipes too but it is a fairly obscure and seldom used feature) - TCP/IP (multiplatform, native support in LabVIEW, almost as high throughput as Shared Memory when both sides are on the same machine since the network socket uses internally shared memory to transfer the data between the two endpoints, can also work over the network where client and server are on different machines) - If both sides are LabVIEW based, you can also use the VI Server interface. That goes over TCP/IP too under the hood, but gives you a fairly easy method to directly access VIs in the other process. The TCP/IP method is by far the standard method nowadays. It is ubiquitous on pretty much every platform, from the tiny embedded controller up to super duper ultra high performance computers. It has a few minor challenges such as proper network setup, the very distinctive server/client model and if you do not want to have to configure the client and server in some ways for their IP address and port number, you need additional complicated services that let you discover the according resources on the network. Most of them do however cause more trouble than they solve, so for your home grown kitchen sink automation, the easiest is to simply leave these things configurable in an ini file or something. -
don't be too quick to install LV2019 SP1 f4
Rolf Kalbermatter replied to Antoine Chalons's topic in LabVIEW General
Does the Patch update somehow also contain VIPM? Seeing that it is a patch it probably doesn't but it's worth checking. When you install packages through NIPM you can usually select sub packages that are or are not installed. Default is to install everything but if there is a selection possibility (the Full LabVIEW installer gives you an option to deselect VIPM), then you can control what gets really installed. -
don't be too quick to install LV2019 SP1 f4
Rolf Kalbermatter replied to Antoine Chalons's topic in LabVIEW General
How about deselecting VIPM installation in the package when installing? -
Swiss too, The Emmentaler cheese has rather big holes usually. It's the proverbial Swiss cheese, although in the US, Swiss cheese is something different. 😀
-
And I incidentally just had an application that I had inherited from someone and needed to debug where GetValuePointer.xnode would return with an error 7 : File Not found, when executed in a build app. Rather than digging into xnode handling and find out why on earth it was returning such an error (for a reportedly valid pointer created with DSNewPtr) I simply replaced the whole thing with a call to StrLen and MoveBlock and was done with it!
-
It's only for Linux 64-bit a 64-bit value. And it's seems a bit of a GCC choice, while Microsoft chose to keep long as a 32-bit integer (and not support long long for some time instead insisting in their _int64 private type). And while not sure about the original Sun Solaris versions which might only have existed as 32-bit anyways, the later Linux kernel based versions however almost certainly use the same logic as the other Linux versions, although Sun had a tendency of trying to customize it when they could, and sometimes even when they shouldn't :-).
-
Not likely. The efficiency in the Transpose function comes from the fact that LabVIEW really creates something that is called a sub array. This is not a real array but a data structure that contains flags, offset, stride and similar attributes and a pointer to the original array data. Many functions in LabVIEW are able to operate on both arrays and sub arrays. A transposed array simply stores the fact that the array data is actually transposed in the flags and then any function that sees it knows to exchange the row and column value in the original array. If a function doesn't support the sub array flavor it simply calls a function that converts the sub array into a real array, eventually imposing the penalty of the transpose operation anyhow, but many functions can simply work with such sub arrays directly. A graph for instance has the ability to transpose the 2D array data already, so if it receives a transposed sub array it simply inverts the transpose setting of the graph for this array data. For the indexing into the array the fact that the array is transposed should not really make a big difference as the real data is still in the original order (if it wasn't, the whole operation would not only use double the memory but be significantly slower as shuffling the data around is taking some performance).
-
Note that "long order" is an int32 under Windows in any bitness, but an int64 under Linux for 64-bit! And the i32 portion in v might be actually in the higher order half on Big Endian platforms. For current LabVIEW versions that is however only relevant for VxWorks RT targets. All other supported platforms are Little Endian nowadays.
-
There are many companies offering technologies that are based on optical fiber sensors. One I have helped in the past was FBGS in Belgium, with this software https://fbgs.com/components/illumisense-software/ .
-
FTDI232HQ I2C communication in labview
Rolf Kalbermatter replied to rk123's topic in LabVIEW General
-
Open source alternatives to TestStand?
Rolf Kalbermatter replied to pawhan11's topic in LabVIEW General
The zero feedback is a common problem. Or if you get feedback it is often about "if you could add this and that feature, please" which feels rather "beggish" and often the "please" is even missing. Considering that the whole thing is out in the open as open source so anyone who would care can get his hands dirty and get that feature built in themselves, is quite disheartening. And extra bonus would be if the result would be shared back with the community. 😀