hooovahh
-
Posts
3,477 -
Joined
-
Last visited
-
Days Won
299
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by hooovahh
-
Oh there are plenty of USB to Serial converters that will show up and work and you can use them using the standard VISA calls. There are also UART TX and RX converters to RS-232 like the MAX232 or the one you linked to. But is your device actually RS-232 serial? I'm not so certain but again I've never used that hardware. Read up on the documentation. Either way you can come up with something that works.
-
Crosspost I've never used this product, or MyRIO at all, sorry.
-
 Have you thought about the fact that this might not be related to LabVIEW at all? Look at the Windows system event logs and see if there is something happening around the time of the crash. Is there any unknown devices in device manager? Is there any devices that might have the wrong driver loaded? Not a lot to go on here but I'm pretty certain I've ran LabVIEW programs in 7 Ultimate but don't have one on hand to test with at the moment. Oh and how about disabling a bunch of NI startup services and programs and seeing if it is more stable?
Have you thought about the fact that this might not be related to LabVIEW at all? Look at the Windows system event logs and see if there is something happening around the time of the crash. Is there any unknown devices in device manager? Is there any devices that might have the wrong driver loaded? Not a lot to go on here but I'm pretty certain I've ran LabVIEW programs in 7 Ultimate but don't have one on hand to test with at the moment. Oh and how about disabling a bunch of NI startup services and programs and seeing if it is more stable? -
[Discuss] Get Reference To All Controls
hooovahh replied to Dave Graybeal's topic in Code Repository (Certified)
Not that there isn't valuable information to be pulled from this code, but in the last 8 years many things have changed in LabVIEW to make this process easier. First there is native recursion, as well as indexing and conditional tunnels instead of nested loops. But there is also the Traverse for GObjects on the palette under Application Control >> VI Scripting. Getting references to controls based on the given label is done with a vi in the vi.lib TRef Find Objects By Label.vi in \vi.lib\Utility\traverseref.llb\TRef Find Object By Label.vi and is added to the palette with the Hidden Gems package. Then there is my attempt at doing this with an XNode posted here. You may want to look into using one of these functions from NI, or one written with modern techniques. They have better performance, and probably more features. -
how to make VI like "+" ,"-" functions in Labview
hooovahh replied to thingsful's topic in LabVIEW General
If you are looking to protect your IP you can apply a block diagram password. Hackers have ways of defeating them but it will keep out the majority of developers from copying your code. -
Questions Regarding SVN and Project File Organization
hooovahh replied to MrShawn's topic in Source Code Control
I was suggesting just use the TortoiseSVN client, and not bother with any other toolkits. JKI and ViewPoint make a couple and while they work fine, I generally just am more comfortable using Windows Explorer. That is again for all things other than a rename, which I have used ViewPoint for, but I try to just avoid renaming unless necessary. As for the lock commit of controls. One thing that helps with this (but I'm not sure eliminates it) is making sure all VIs are set to "Separate compiled code from source file". There is some code that will perform this on a project or folder of VIs, here is a start. This should be on for all SCC options for a couple reasons. I still think that if Dev A edits a type def control, then all the other VIs that use it will have unsaved changes for Dev A. But if Dev B is working on a VI that uses that control, then Dev A has no obligation to update that VI, save, and commit it. They just have to edit the control and commit. Once Dev B does an update and gets the new control, the VI they can edit will have unsaved changes at which point they should save it and commit. In practice this ends up with alot of "Continue Saving Without Prompts" for Dev A (since they can't get locks on those VIs which are effected by the control edit -
Questions Regarding SVN and Project File Organization
hooovahh replied to MrShawn's topic in Source Code Control
No advice in the merge topic other than don't do it. LabVIEW files are obviously binary in nature, and merge doesn't work well. That being said some developers do implement a merge paradigm in LabVIEW and SVN. LabVIEW has some file compare tools to see what changes have changed from one revision to another but I have no idea how well they work in a SCC. SVN also can work in the Lock/Commit paradigm where VI files will be read-only until you have requested a lock from the server (look into needs-lock). At which point you can edit the file and commit changes but no one else can. If they attempt to get a lock SVN will say what user has the lock at which point you can ask them if they are still working on it. Dividing up the application into code modules and assigning a developer their set of code usually minimizes the number of times you need to ask a developer about their part of the code, but it happens. BTW I just suggest Tortoise SVN, which is the Windows Explorer extension. If the file is read-only, LabVIEW will complain when you go to save, at which point a save dialog will come up. From here you can right click the file and choose to get the lock, cancel the save dialog, and resave the VI (which shouldn't be read-only any more). Some other toolkits help in things like a rename. If you need to rename or move a file, then LabVIEW needs to be aware of the change (the project and files that link to it) and SVN needs to know it was renamed. Some of these 3rd party tools like ViewPoint can do this but it is generally a pain. As for file structure. Code that is reuse, and not part of the project needs to be found by a single common location. My advice is either the vi.lib or user.lib. You take your common code, package it up with VIPM, and then have all your project code link to that common stuff there. The source to the VIPM packages can be in a separate reuse SVN repository, but your code only ever links to the code from the installed location of user.lib. It can be more steps to make changes, since instead of changing the code in user.lib you should change the package source, build a new package, release it, then install it. Where previously you would be just used to editing the VIs as they are. Another alternative I've heard of but am less of a fan of, is to checkout the reuse repository to your user.lib. Then you can edit the reuse source and commit it back to SCC. This has advantages and disadvantages of course -
Attached is 2013. I think I understand what you want but I'm just thinking. In some cases the number of rows might exceed the resolution on the monitor. One way to always keep the number of rows accessible is with a vertical scrollbar. Besides users understand how to resize a window, and if they only see 3 rows of 100, they know to resize the window to add more rows. Or if a column can't be fully viewed they may make the window wider. It is a design choice and will effect the user experience. You might also notice I set a minimum window size so you could just make that larger. It really depends on how much data you typically display. My solution is just one and you may know more about the users of your software and understand their needs better than I do. Still I think you could use my demo and programatically resize the window to show the set number of rows you want too. Hooovahh MCLB Test 2013.zip
-
Okay thanks for more details on what you are doing and trying to do. Attached is a demo of code that shows what I typically do in these situations. The UI has a splitter setting the upper half to a single pane that the Multicolumn Listbox (MCLB) is fit to. The pane also is set to scale objects while resizing. I then have an event triggered when the pane is resized which resizes the columns. At the moment it has 100 pixels for the 1st column, 90 for the 3rd, 60 for the 4th, and what ever is left is the second. I also setup panes for the buttons below so the right button sticks right, and the left sticks left. I also added a New Data button for generating new random data which stays in the center due to more panes. The thing to notice about this type of solution is that there is zero code handling resizing or moving of controls. This is all done by LabVIEW and even happens when the VI isn't running. This means there is not math or code figuring out how big or where a control should be making some parts of the development process easier. Working with panes can be a pain and some shy away from this solution but the improvements on performance and ease of use once you master working with panes is why I typically use this method. Hooovahh MCLB Test.zip
-
VIPM keeps a cache of all versions, of all packages installed, locally. So if you've ever installed the package, and then installed a new one, then from VIPM you should be able to right click the package and choose to install a different one. In 2017 both will show up as able to be installed, and in 2013 only the one compatible one will show up.
-
It isn't quote clear what you are asking for. Do you simply want a list box that fits to a pane? If so use splitters to split up the UI into sections which can be resized independently.
-
Solved - OpenG Zlib max file size 2.00 GB?
hooovahh replied to Grunkles's topic in OpenG General Discussions
Years ago I showed how you could call the 7-zip command line EXE to have it perform functions that are hard of impossible with the native LabVIEW zip, or OpenG. I suspect that the 64 bit built EXE could perform the compression without any issue and can be called using the System Exec. Beyond that I'm guessing you already know about TDMS defragging, and how it can save on TDMS file sizes. After a defrag most of the data will be binary, and won't compress much anyway. I'd suggest defragging first, and then zipping. If your size doesn't go down in the zip it might not be worth the extra effort. -
So I have the need for a stack light, Red, Green, Yellow and I'd prefer something that can be controlled over a wired network via TCP. I swear I remember seeing something but now that I'm looking for it I can't find much. I found this place which is fine but I'm curious if others have had success in using stack lights like these and have any that are recommended. Thanks.
-
It isn't just that these special controls need to be there, but they also need to be connected to the connector pane the right way. Making a new VI does this automatically. It is somewhat like a DLL call. To call functions dynamically, the interface needs to be known, like what kind of controls are found at what location. Removing these removes the ability to call the functions from the NI API. This is similar to calling any subVI where if the interface changes you need to relink the VI to call it properly and some times rewire the VI. If you are new to LabVIEW you might want to check out some of the free training links at the bottom of this page. There's lots to learn for sure.
-
I think this is a bug. Also you can see the behavior without even running the VI. Just put the VI into run mode with CTRL+M and the behavior can be seen. Might want to crosspost over on the NI forums to get more attention. Some NI employees check LAVA (the cool ones at least) but you'll likely get more attention and possible a CAR posting it there.
-
Running a LabVIEW EXE from the Console
hooovahh replied to John Lokanis's topic in Calling External Code
Do you know what a non-disclosure agreement is? Well you agree to one when you sign up for a LabVIEW beta, and you can be subject to whatever NI feels that are legally allowed to come after individuals for. One such restriction is to not discuss beta topics outside of approved areas. This can have a real negative impact on NI's business. LAVA is about minimal censorship and unless you, or NI complain I won't be editing your post, but if I were you I'd edit your post, or ask them to be edited. -
Do you know what a non-disclosure agreement is? Well you agree to one when you sign up for a LabVIEW beta, and you can be subject to whatever NI feels that are legally allowed to come after individuals for. One such restriction is to not discuss beta topics outside of approved areas. This can have a real negative impact on NI's business. LAVA is about minimal censorship and unless you, or NI complain I won't be editing your post, but if I were you I'd edit your post, or ask them to be edited.
-
Sound really cool and I hope it takes off. But based on my travel allotment for work, I won't be making it.
-
I get your point, and there is large amounts of debate over similar topics. Should I not use Variable=Variable++ since not all developers know this is short hand for incrementing a variable? To me the delete from array with nothing wired is used for getting the last element, but I get not everyone associates this function with that feature. But I suppose if you really feel strongly about this you could make a VIM that just has this one primitive in it.
-
There already is a primitive that does this. The Delete From Array returns the last element in the array if nothing is wired to the length and index. There was a thread on LAVA years ago about which was a faster method, and a few versions of LabVIEW the method you showed was faster, but in most the delete from array is faster. And it already has a quick drop dfa.
-
Most front panels are removed automatically when building an EXE or DLL. I'm unsure of what the rules are but basically if the VI doesn't have settings to show it then they are removed. Password protecting the VIs seems to be sufficient for most tools network developers, but yes there is a risk of cracking them open. But even removing block diagrams and front panels, doesn't mean the VI can't be called similar to a compiled DLL. You might not know what is going on inside but it can be called with inputs and an output be returned. It may also be possible to load a VI of the same name in memory and have your functions link to the new one (assuming they aren't in libraries or classes). Protecting LabVIEW IP is a tricky one for sure. Even things like code obstruficators are rendered useless with block diagram cleanup most of the time.
-
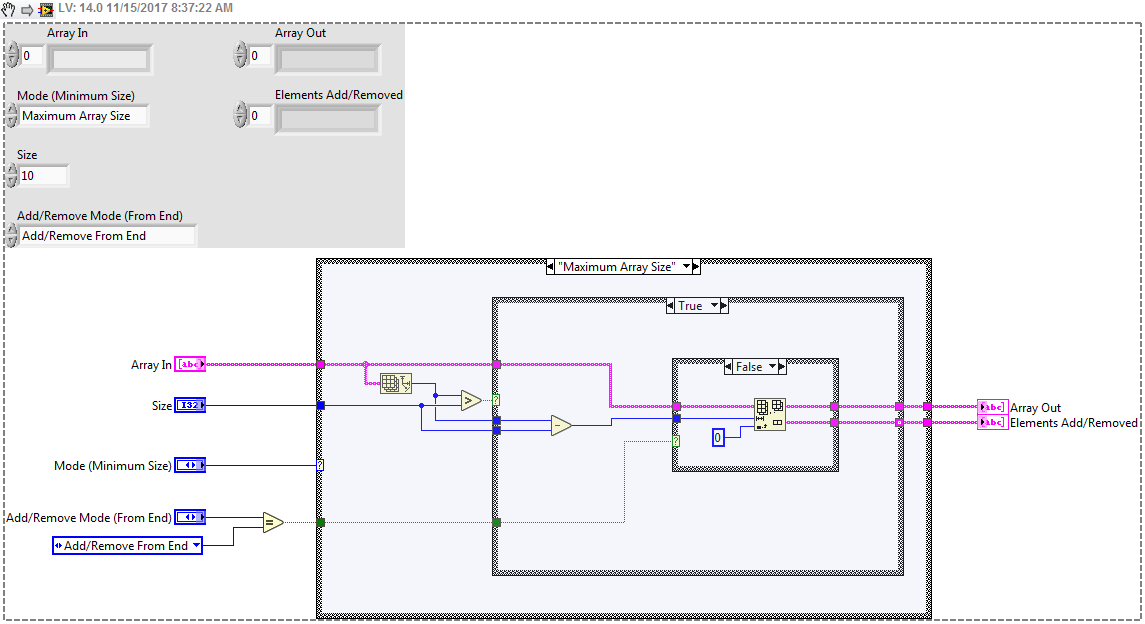
Very neat and postage stamp sized. There are apparently lots of different ways to perform this and I have yet another way that I've been doing. This is part of my Force 1D Array Min or Max Size VIM that is part of my array package found here. I am curious what is the fastest, and under what conditions one works better than another. Also somewhat relevant is my Circular Buffer XNodes I made here. This one uses the shifting method, but tried to be a little more efficient with things like not shifting if it wasn't needed, and if a shift was needed to keep the shifted data so a consecutive read wouldn't require a shift or split and build.

-
Thanks for the advice. On my system all of the string character sets I tried had the same result, summing their parts, as NI's method.
-
So attached is my first attempt. I did things a little different than you described. For any one set of font settings I didn't generate the size of each printable character. I only get the size of each character in the string and cached the result. If that character for that set of settings was already generated it uses it. At the moment it only supports Left to Right text, without offsets (unlike the normal method) but that could be added. Also I included a test VI which after you run it a few times clearly generates text that is always faster than the built in method for a set of random strings. If you open up the font range obviously it is less likely to have a cached value for your characters and will take longer. Also my test runs the cached code twice, in the hopes I could see the difference when some text hasn't been cached but when you run it with 1000 random strings of random sizes it becomes noise quickly. Get Text Rect Cached.zip