Leaderboard




Popular Content
Showing content with the highest reputation since 08/01/2025 in Posts
-
So a couple of years ago I was reading about the ZLIB documentation on compression and how it works. It was an interesting blog post going into how it works, and what compression algorithms like zip really do. This is using the LZ77 and Huffman Tables. It was very education and I thought it might be fun to try to write some of it in G. The deflate function in ZLIB is very well understood from an external code call and so the only real ever so slight place that it made sense in my head was to use it on LabVIEW RT. The wonderful OpenG Zip package has support for Linux RT in version 4.2.0b1 as posted here. For now this is the version I will be sticking with because of the RT support. Still I went on my little journey trying to make my own in pure LabVIEW to see what I could do. My first attempt failed immensely and I did not have the knowledge, to understand what was wrong, or how to debug it. As a test of AI progression I decided to dig up this old code and start asking AI about what I could do to improve my code, and to finally have it working properly. Well over the holiday break Google Gemini delivered. It was very helpful for the first 90% or so. It was great having a dialog with back and forth asking about edge cases, and how things are handled. It gave examples and knew what the next steps were. Admittedly it is a somewhat academic problem, and so maybe that's why the AI did so well. And I did still reference some of the other content online. The last 10% were a bit of a pain. The AI hallucinated several times giving wrong information, or analyzed my byte streams incorrectly. But this did help me understand it even more since I had to debug it. So attached is my first go at it in 2022 Q3. It requires some packages from VIPM.IO. Image Manipulation, for making some debug tree drawings which is actually disabled at the moment. And the new version of my Array package 3.1.3.23. So how is performance? Well I only have the deflate function, and it only is on the dynamic table, which only gets called if there is some amount of data around 1K and larger. I tested it with random stuff with lots of repetition and my 700k string took about 100ms to process while the OpenG method took about 2ms. Compression was similar but OpenG was about 5% smaller too. It was a lot of fun, I learned a lot, and will probably apply things I learned, but realistically I will stick with the OpenG for real work. If there are improvements to make, the largest time sink is in detecting the patterns. It is a 32k sliding window and I'm unsure of what techniques can be used to make it faster. ZLIB G Compression.zip5 points
-
4 points
-
We're back again this year. Free 24 hours of virtual LabVIEW presentations. Come join us! https://www.glasummit.org/ We're also looking for presenters. I know some of you all have a lot of opinions...3 points
-
Are you seriously expecting anyone to install a random executable on their system from an unknown publisher, provided by an anonymous person on the web, where one can't even get a proper link in Google to the actual company page? Sorry, but anyone doing that should not be allowed near 5m of a computer system!3 points
-
The recovery loop forcing is most likely related to the installation of DAQmx and other NI driver software that make under the hood use of NI-PAL and friends which is really part of the NI-PXI driver software stack. This driver goes fairly deep into the Windows PCI hardware driver stack and newer Windows versions tend to enable the newest features in the PCI chipsets. Some of these features did not even exist in the standard when DAQmx and NI-PAL that come with the standard install of LabVIEW 2020 were released. So if you want to install an older version of LabVIEW on a recent hardware, it is actually best to choose a custom install and disable installation of all hardware drivers and then install the latest version of the drivers you actually need that are still compatible with your LabVIEW version. That's of course cumbersome and the long term solution is indeed to move to a newer LabVIEW version altogether. But be aware that this problem will keep occurring. The times where hardware improvements were automatically always fully backwards compatible are definitely over. The PCI standard got so complicated over the years, and covers much more than just the traditional PCI slots that are almost unseen in modern computers. Pretty much every modern bus from USB3 and higher to Thunderbolt, all kinds of memory interfaces, and many more is nowadays using PCI technologies in one way or the other. Improving that without causing potential backwards compatibility problems got an almost impossible task. And each of the software component manufacturers from hardware firmware, to BIOS and chipset firmware to Windows drivers and vendor drivers such as NI-PAL would need to test their thing with everything else to be sure it still works. Which of course is impossible, so you end up with these issues. For LabVIEW itself I managed to install and use LabVIEW 2009 on Windows 11 without any real problems. I'm convinced that even LabVIEW 7.1 would be possible, although that most likely would require some careful hand holding and sweet talking to the installer to convince it to go fully through with it. And it might show some visual artefacts when running it under Windows 11. Hardware drivers on the other hand are a different story. The NI drivers go fairly deep into the system to allow high performance data acquisition and similar things and that has a big potential to run into compatibility trouble on newer hardware than what was available at the release date of the driver.2 points
-
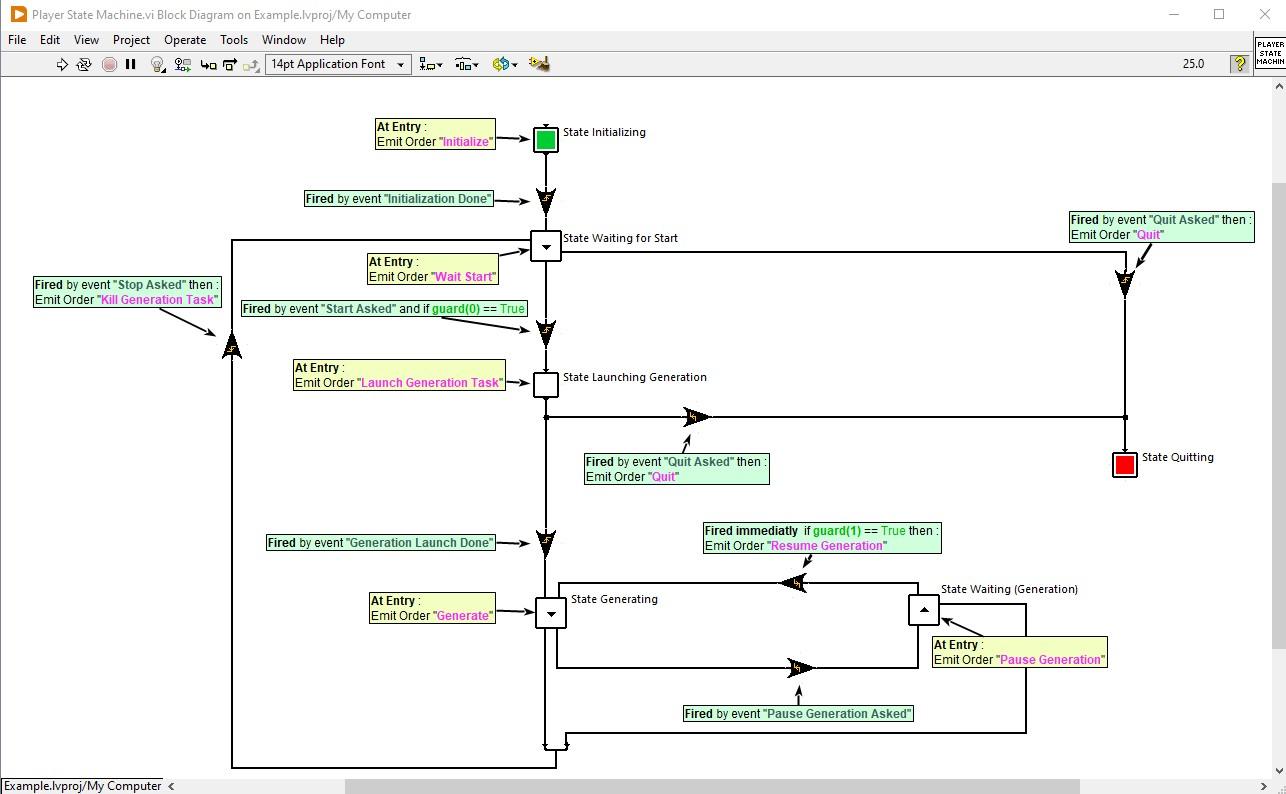
Hi there ! If this subject interest you, I'm currently working on a new State Machine Toolkit for LabVIEW. You can find some shorts videos about it here : https://www.youtube.com/@EmmanuelGeveaux Or some posts about it here : https://www.linkedin.com/posts/emmanuel-geveaux-93836130a_labview-statemachines-ugcPost-746286803261... This toolkit will be Open-Source, free for students, education purpose and within LabVIEW Community Edition use. I'd be happy to ear any feedback on those videos and posts. Best regards Emmanuel
 2 points
2 points -
This year I went to NI Connect (the new NI Week) for the first time in 7 years. I thought I would be the exception and see all those that have gone year after year. But it turns out that many of us this was our first year back, or some last year was their first year back since COVID. In general I think this is a good sign, that things are moving in the right direction. NI has some new leadership that has a LabVIEW focus, and at least at the moment appear to want to push adoption. Reversing the subscription only is a welcome change, but for many it hurt the inertia of business. Once a ship starts moving in the wrong direction it takes a while to come back. Or put another way, respect is lost in buckets and gained in drops. Plenty of businesses have likely moved away from LabVIEW and NI because of poor decisions, that in my opinion, were so NI would look more valuable for an Emerson sale. I'm in the Detroit area, and plan to retire doing LabVIEW. At the moment I think I can do that. Not long ago I didn't think that would be the case. We were just blindly paying the SSP each year. The subscription only model, made management here reevaluated things. We took a few years off. Then perpetual licenses came back again so we renewed. I think we will likely get a new perpetual license every 4 years or so. This will hurt NI since this means less users on the newest release finding issues. Building back trust will take time here, and this will likely play out in a similar way around the world for other companies.2 points
-
It is not that LabVIEW MAY unregister the reference, but that it WILL unregister the reference as soon as the top level VI in whose hierarchy the reference was created goes idle. This is by design and the only way to prevent that is to either keep that hierarchy active until any other user of that refnum has finished or delegate creating of the refnum to the place where it is needed, for instance through a LV2 style global maintaining the reference in a shift register and when being called for the first time it will create the refnum if the shift register contains an invalid refnum. True Actor Framework design kind of mandates that all refnums are created in the context of where they are used not some other global instance that may or may not keep running for the time some Actor is using the refnum.2 points
-
Hi everyone, Just want to share our open source project "Labview Python Bridge". Connect labview apps with python apps in realtime with multi-processing data queues. https://github.com/jmor2000/labview_python_bridge If anyone has any questions or suggestions for new developments / features, let me know. Cheers Jeff2 points
-
Absolutely echo what Shaun says. Nobody banned them. But most who tried to use them have after some more or less short time run from them, with many hairs ripped out of their head, a few nervous tics from to much caffeine consume and swearing to never try them again. The idea is not really bad and if you are willing to suffer through it you can make pretty impressive things with them, but the execution of that idea is anything but ideal and feels in many places like a half thought out idea that was eventually abandoned when it was kind of working but before it was a really easily usable feature.2 points
-
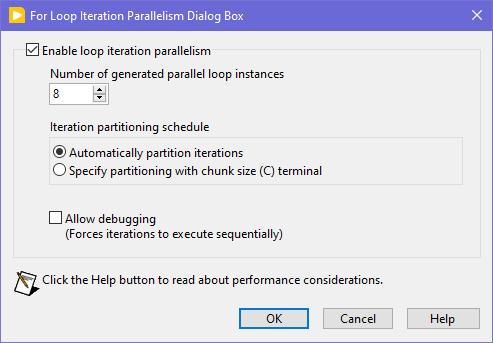
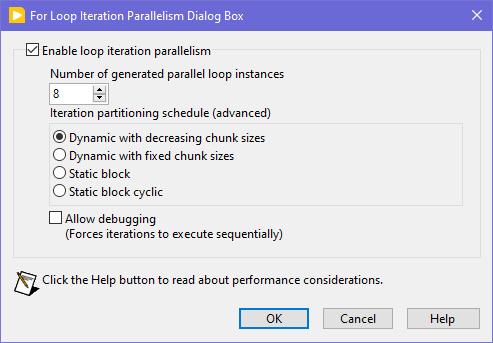
Seems like this one has "escaped everyone's grasp" too. ParallelLoop.ShowAllSchedules=True Because was only checked from the password-protected diagram of ParallelForLoopDialog.vi (LabVIEW 20xx\resource\dialog). Present since LabVIEW 2010. When activated, allows to apply more advanced iteration partitioning schedule. In other words, instead of this you will get this Сould this be useful? I can't say. Maybe in some very specific use-cases. In my quick tests I didn't manage to get increase in any productivity. It's easy to mess up with those options and make things worse, than by default. Also can be changed by this scripting counterpart.
2 points
-
Look at this new download on VIPM https://www.vipm.io/package/bjm_lib_request_power/2 points
-
You want an ability to override the Equality or Comparison operators? I'm unsure, whether it really existed in OpenG packages, but now you have those neat malleable VIs, that let you do that: Search Unsorted 1D Array , Sort 1D Array , Search Sorted 1D Array. They have an additional input to specify your own equals or less function in a form of a custom comparison class or a VI refnum. There's an article to help: Creating a Custom Sorting Function in LabVIEW2 points
-
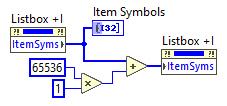
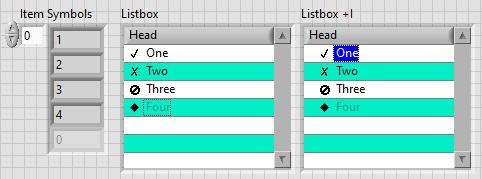
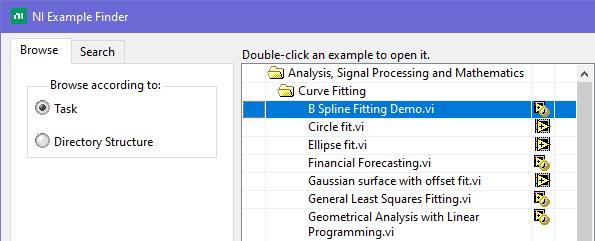
This is exactly what was said in that ancient thread: Tree control in labview. So if you add 65536*N to the Item Symbols property of the Listbox and have the "Enable Indentation" option activated, you shift the symbol/glyph and the text N levels to the right. Could be useful for simple 'parent-child' relationships, if you don't want to use a Tree. And still it's used in Find Examples / NI Example Finder window:
2 points
-
I've generally been recommending using at least 2025 because the project dependency list is no longer saved in the project file (it got recalculated at loading anyways), making GIT commits cleaner. And the in-place save for previous (introduced with 2024) is really nice to have. I have been using 2026Q1 for my development, including a major refactoring of my HAL architecture. I've had very few issues, almost all of which were fixed by clearing the object compile cache regularly (something I have a habit of doing anyways since at least 2016). And just to throw it out there, we are expecting 2026Q3 to drop any day now. No promises from NI on a date, but we are in Q3 now.1 point
-
You should contact the developer. It may use features not available in earlier versions and it is a source control nightmare maintaining subtly difference versions.1 point
-
I think there is a future and NI has significantly increased their activity and promotion for it (I guess one could be sarcastic and say that considering that NI's promotion of LabVIEW and active support of the community was pretty much zero just 3 years ago, anything more than zero is significant). It will however not reach the stage that Dr. T once optimistically proposed as "LabVIEW everywhere". But that is not necessary. LabVIEW has still some interesting features and advantages and there won't be any programming environment ever that suits everybody. The license change is welcome but not to significant, I think, as the new(old) perpetual license is basically quite beyond reasonable in my opinion. LabVIEW was expensive in the old days already but the new perpetual license cost is in my opinion simply to high (it's more than double of what it was before they tried to force feed the subscription). If I had to pay it myself, I would most likely stop with LabVIEW and simply use the Community Edition as a hobby. However, you should anyhow never build your future on just one leg. LabVIEW can be an interesting and even viable option, but with LabVIEW alone you never could and never will be able to earn a keeping. You need additional expertise. LabVIEW shines in combination with hardware control, so having a good understanding on electronics, electricity, communication protocols, interoperability with other systems is what makes you stand apart in a world of other programmers. The actual world doesn't run on blockchain, LLMs, marketing and stock exchange, even if that seems what a large amount of people believe, since it promises quick profits. But the hype of today is the old story of tomorrow, since there is already another hype to chase then. Almost all the AI hypers on social media today, were trying to peddle their cr*pto hype a few years ago, and will all quickly move to the next hype once AI has been falling down from the hype (which it actually has done already more than once in the past, but most people seem to have a short memory or simply haven't been around long enough to remember). Of course, I have about 10 more years I need to look forward too, so for me it is quite easy. There is enough of LabVIEW around to keep me full time busy with that until then, (but I like to also do some hardware and luckily can do that too). For someone younger, you definitely need to have some options open.1 point
-
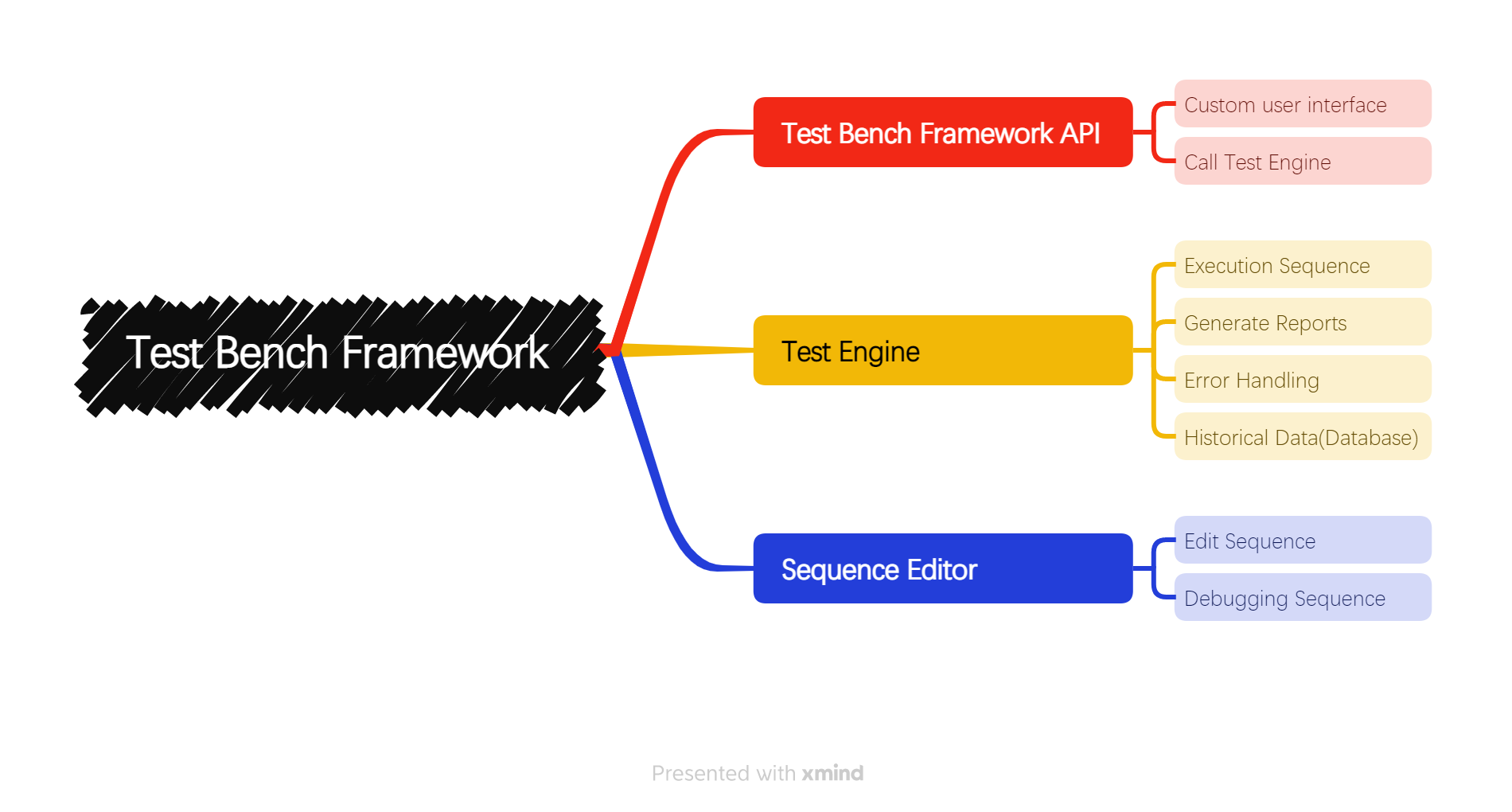
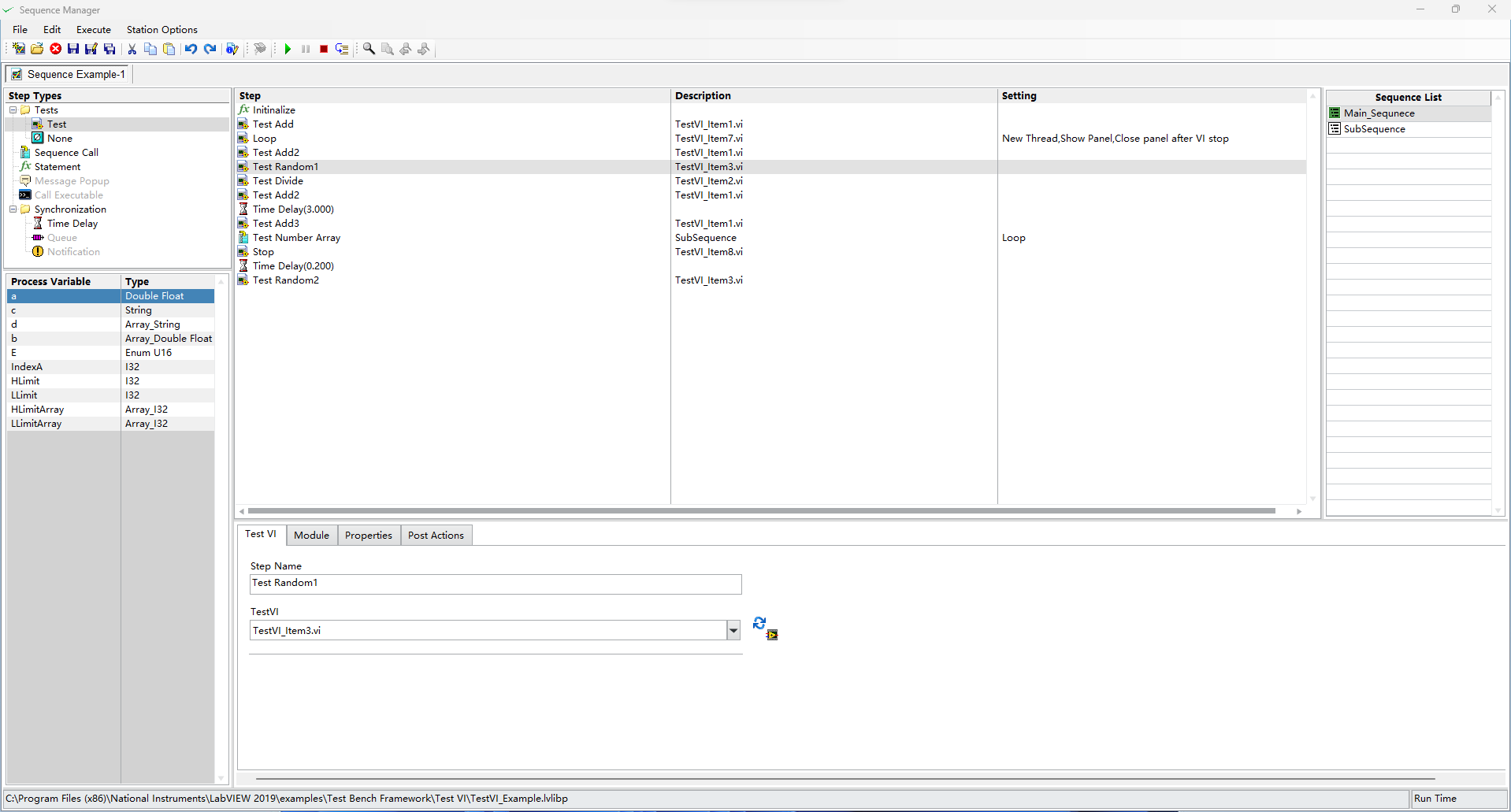
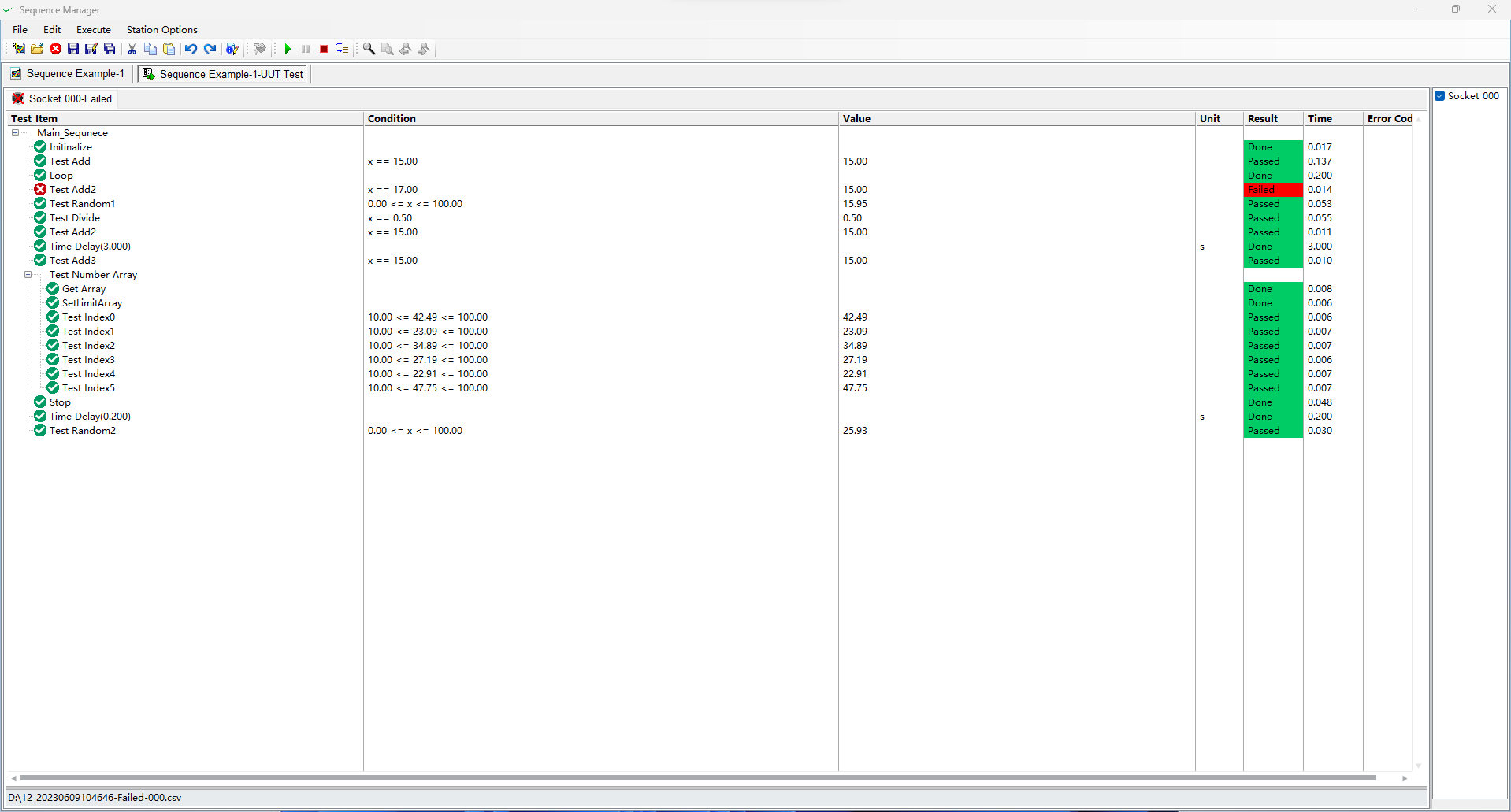
I used LabVIEW to develop a toolkit for ATE software. The toolkit is called "Test bench Framework", which includes a test sequence editor and a test engine.This toolkit features the ability to execute several different sequences in parallel.If you are interested in this kit please contact me, thank you! This toolkit is over 10MB in file size and cannot be published on VIPM, so I uploaded it to Github.Test-Bench-Framework . I used the TestStand icon inside my own sequence editor and wondered if there would be any copyright issues involved.But it's not commercially available yet.
1 point
-
My part of the world! Unfortunately, I don't have any connections to the realm you are talking about. But I would look at Northern Kentucky University (just across the Ohio river) as they have a good CS program (or at least used to). There is also Miami University (not to be confused with the one in Florida), Wright State University (where I got my MSE), and University of Dayton about an hour north of here in the Dayton area. University of Kentucky is about 2 hours south (Lexington, Kentucky), which is about the same distance from Ohio University (Athens) or THE Ohio State University (Columbus).1 point
-
@Rolf Kalbermatter my team and I still use in some systems here! In fact this very last week we have needed to add some lua stuff to an old project.1 point
-
They aren't banned. They are just very hard to debug when they don't work and have some unintuitive behaviours. I have Toolbar and Tab pages XControls that I use all the time and there is a markup string xcontrol here. If you are a real glutton for punishment you can play with xnodes too
1 point
-
You can 'renew' your LabVIEW CE license this way if you haven't tried it: Go to https://www.ni.com Hover over your user icon in the upper right and select "My Account". Scroll down to "Products and Services" and select "View my products". Scroll down to find your LabVIEW Community Edition and select "Renew" from the drop-down menu to the right. Apologies if you've already tried this and still had issues. Maybe someone else will find it useful.1 point
-
There should be a forum on the dark side for that, but anyway, here you go. LabGRAD_21.zip1 point
-
For fun. 😄 "Science isn't about why; it's about why not!" - Cave Johnson1 point
-
yes1 point
-
Reentrant execution may be a safe option. Have to check the function. The zlib library is generally written in a way that should be multithreading safe. Of course that does NOT apply to accessing for instance the same ZIP or UNZIP stream with two different function calls at the same time. The underlaying streams (mapping to the according refnums in the VI library) are not protected with mutexes or anything. That's an extra overhead that costs time to do even when it would be not necessary. But for the Inflate and Deflate functions it would be almost certainly safe to do. I'm not a fan of making libraries all over reentrant since in older versions they were not debuggable at all and there are still limitations even now. Also reentrant execution is NOT a panacea that solves everything. It can speed up certain operations if used properly but it comes with significant overhead for memory and extra management work so in many cases it improves nothing but can have even negative effects. Because of that I never enable reentrant execution in VIs by default, only after I'm positively convinced that it improves things. For the other ZLIB functions operating on refnums I will for sure not enable it. It should work fine if you make sure that a refnum is never accessed from two different places at the same time but that is active user restraint that they must do. Simply leaving the functions non-reentrant is the only safe option without having to write a 50 page document explaining what you should never do, and which 99% of the users never will read anyways. 😁 And yes LabVIEW 8.6 has no Separated Compiled code. And 2009 neither.1 point
-
Well I referred to the VI names really, the ZLIB Inflate calls the compress function, which then calls internally the inflate_init, inflate and inflate_end functions, and the ZLIB Deflate calls the decompress function wich calls accordingly deflate_init, deflate and deflate_end. The init, add, end functions are only useful if you want to process a single stream in junks. It's still only one stream but instead of entering the whole compressed or uncompressed stream as a whole, you initialize a compression or decompression reference, then add the input stream in smaller junks and get every time the according output stream. This is useful to process large streams in smaller chunks to save memory at the cost of some processing speed. A stream is simply a bunch of bytes. There is not inherent structure in it, you would have to add that yourself by partitioning the junks accordingly yourself.1 point
-
With ZLib you just deflateInit, then call deflate over and over feeding in chunks and then call deflateEnd when you are finished. The size of the chunks you feed in is pretty much up to you. There is also a compress function (and the decompress) that does it all in one-shot that you could feed each frame to. If by fixed/dynamic you are referring to the Huffman table then there are certain "strategies" you can use (DEFAULT_STRATEGY, FILTERED, HUFFMAN_ONLY, RLE, FIXED). The FIXED uses a uses a predefined Huffman code table.1 point
-
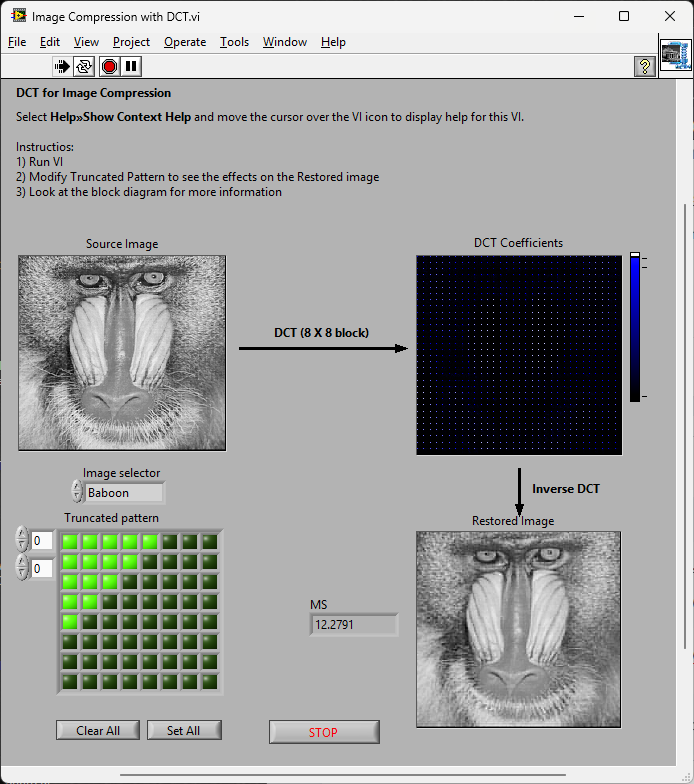
There is an example shipped with LabVIEW called "Image Compression with DCT". If one added the colour-space conversion, quantization and changed the order of encoding (entropy encoding) and Huffman RLE you'd have a JPG [En/De]coder. That'd work on all platforms Not volunteering; just saying
1 point
-
The Weather Station example that ships with LabVIEW shows a bit of this. but the data is not Base64, its just a pure characters,
1 point
-
From what I can remember, for LV 5.0.x and older RTE (i.e., a loader plus small subset of resources) was included into the EXE automatically during the build process. For LV 5.1.x there was a choice: to include RTE into the build or to use an external RTE. And since LV 6.0 only an external RTE was supposed. I could say more, such a trick is still possible for all modern versions on all three platforms (Win, Mac, Linux). The latest version I tested it on, was LV 2018, but I'm pretty sure, the technique hasn't changed much. I can't remember, from which version NI started to use Visual Studio 2015, but since then each EXE requires The Universal CRT, that is contained in Microsoft Visual C++ 2015 Redistributable. One could install such a distro on a clean machine or copy all these files from the machine, where such a CRT is already installed. Now besides of those the application will also require this minimal subset of folders/files (true for LV 2018 64-bit): On Linux it goes much easier (true for LV 2014 64-bit): For LV 2018 64-bit with a "dark" RTE it also wants And for Mac OS you can embed RTE into the application with this script: Standalone LabVIEW-built Mac Application with Post-Build Action. Of course (and I'm sure everyone understands that), the technique described above, is applicable to very simple 'a la calculator' apps and not very to not at all for more or less complex projects. The more functions are called, the more dependencies you get. If something from MKL is used, you need lvanlys.dll and LV##0000_BLASLAPACK.dll, if VISA is used, you need visa32.dll, NiViAsrl.dll and maybe others, and so on and so forth.1 point
-
I have always used this library to prevent the screensaver and windows lock from occurring. Our IT locks down the computer so the screensaver, lock screen, cannot be changed. This library bascially tells Windows it's in Presentation mode, e.g., slideshow, watching a movie, etc, such that the screen will not got to screensaver or lock screen.1 point
-
@hwkim418 There are many ways you can go about this. Here's a few examples using JSONtext. (VI saved in LV 2019) object_deserialization.vi
1 point
-
You might have more success posting this on the Discord. Most of the conversations happen there these days.1 point
-
I don't know what drivers are used under the hood, but I've recently used G-Audio to interface to the mic/speakers for a LabVIEW application I was working on.1 point
-
My problem was on a windows machine but I managed to solve it; I found that using LVCompare also segfaulted on the same file, but did not segfault with the -nofp command line option. With this I was able to confirm the specific file that both LVMerge and LVCompare were segfaulting on, and systematically delete half the code and re-test whether LVCompare would crash. After a few hours I was able to track down the offending piece of code to a random chart; I'm honestly still not sure what was causing them to segfault, but deleting and replacing the chart fixed the issue. Hope this helps someone else out there!1 point
-
Thanks, I'll be honest, I'm allergic to Discord. Vehemently so. To the point where I refuse to use it. Just seems like a lot of unfiltered noise to this old man. I'm gonna play with NodeRed and see if it's the tool of choice. And oh, back in the day I was a National Instruments Alliance Member. Dunno if that's still a thing or not. Cheers,1 point
-
Hi My advice for managing multiple versions of LabVIEW is always the same : >>> Install only one LabVIEW version per partition if you also need to install any driver, toolkit or module. Or need other software that integrates with LabVIEW in some way. No exceptions. I do have VMWare installed with Windows XP to be able to open ancient LabVIEW versions like 6.1 or read the old CHM help files, accepting the sluggish performance of the VM environment. I avoid using it for anything 'serious'. To manage the span between LabVIEW 2018 and 2024 I would divide the disk into two partitions and install two copies of Windows and then install LabVIEW. To manage multiple partitions and selecting which to boot from by default, I recommend installing EasyBCD. But you don't have to. Windows creates a simple multiboot menu itself. There are other options too. But they require some dedication going into the art of multiboot management. ¤ You can install Windows on an external USB3 connected disk, SSD or FlashDisk. Microsoft abandoned the concept in 2020. But a program called Rufus revived the concept and now there are many tools that gives this as an opportunity. Works splendidly even with Windows 11. ¤ Some laptops ( and desktops of course ) support easy change of the disk. Sometimes using a replaceable disk craddle instead of the DVD drive. Good luck1 point
-
Aren't DVR's just LabVIEW's take on pointers?1 point
-
Discussion forums like LAVA and ni.com are challenged these days by LLMs that can answer in a well structured manner very quickly and handle follow-up questions on the spot. Forums have their stenghts, but when it comes to basic questions that LLMs can find a lot about, spread across multiple forums, the LLMs win. It is a bit of a catch 22 though, as the LLMs need the forums alive to stay up to date 😮 ------------------------------ Here is Grok answering you question of what a DVR is: DVRs as References: In LabVIEW, DVRs (Data Value References) are a mechanism to access data by reference rather than by value. This means that instead of creating copies of the data (as is typical in LabVIEW's dataflow paradigm), a DVR provides a pointer-like reference to a single memory location where the data resides. This avoids unnecessary data duplication, which can be critical for large datasets or performance-sensitive applications. Avoiding Copies: By using DVRs, you can manipulate the same data in memory without creating copies, which is especially useful for large arrays, clusters, or other complex data structures. This reduces memory usage and improves performance. Parallel Operations and Race Conditions: When multiple parallel operations (e.g., parallel loops or VIs) access the same DVR, there is a potential for race conditions if the access is not properly synchronized. LabVIEW provides the In-Place Element Structure to safely access and modify DVR data. This structure ensures that only one operation can read or write to the DVR at a time, preventing race conditions. Without this, simultaneous read/write operations could lead to unpredictable results or data corruption. Key Points to Add: Thread Safety: DVRs are not inherently thread-safe. You must use the In-Place Element Structure (or other synchronization mechanisms like semaphores) to avoid race conditions when multiple parallel tasks access the same DVR. Use Cases: DVRs are commonly used in scenarios where you need to share data between parallel loops, modules, or processes without copying, such as in real-time systems or when managing shared resources. Limitations: DVRs are only valid within the application instance where they are created, and the data they reference is freed when the reference is deleted or the application stops. --------------------- Before DVRs we typically had to resort to cloning of functional globals (VIs), but DVRs make this a little more dynamic and slick. You can have a single malleable VI operate on multiple types of DVRs too e.g., that opens up a lot of nice reuse. If you have an object that requires multiple circular buffers e.g. you can include circular buffer objects in the private data of that object, with the circular buffer objects containing a DVR to an array acting as that buffer... -------------------- Here is ChatGPT comparing functional globals with DVRs: Functional Globals (FGs) and Data Value References (DVRs) are both techniques used in programming (particularly in LabVIEW) to manage shared data, but they offer different approaches and have different strengths and weaknesses. FGs encapsulate data within a VI that provides access methods, while DVRs provide a reference to a shared memory location. Functional Globals (FGs): Encapsulation: FGs encapsulate data within a VI, often a subVI, that acts as an interface for accessing and modifying the data. This encapsulation can help prevent unintended modifications and promote better code organization. Control over Access: The FG's VI provides explicit methods (e.g., "Get" and "Set" operations) for interacting with the data, allowing for controlled access and potential validation or error handling. Potential for Race Conditions: While FGs can help avoid some race conditions associated with traditional global variables, they can still be susceptible if not implemented carefully, particularly if the access methods themselves are not synchronized. Performance: FGs can introduce some overhead due to the VI calls, but this can be mitigated by using techniques like inlining and careful design. Example: An FG could be used to manage a configuration setting, with a "Get Configuration" and "Set Configuration" VI providing access to the settings. Data Value References (DVRs): Shared Memory Reference: DVRs are references to a memory location, allowing multiple VIs to access and modify the same data. This is a more direct way of sharing data than FGs. Flexibility: DVRs can be used with various data types, including complex data structures, and can be passed as parameters to subVIs. Potential for Race Conditions: DVRs, like traditional globals, can be prone to race conditions if not handled carefully. Proper synchronization mechanisms (e.g., queues, semaphores, or action engines) are often needed to prevent data corruption. Performance: DVRs can be very efficient, especially when used with optimized data access patterns. Example: A DVR could be used to share a large array between different parts of an application, with one VI writing to the array and another reading from it. Key Differences and Considerations: Control vs. Flexibility: FGs offer more control over data access through their defined interface, while DVRs offer more flexibility in terms of the data types and structures that can be shared. Race Condition Mitigation: While both can be susceptible, FGs can be designed with built-in synchronization mechanisms (like action engines), while DVRs require explicit synchronization mechanisms to prevent race conditions. Performance Trade-offs: DVRs can offer better performance in many cases, especially when dealing with large data sets, but this can be offset by the complexity of managing synchronization. Code Readability and Maintainability: FGs can make code more readable and maintainable by encapsulating data access logic, but poorly designed FGs can also lead to confusion. In summary: Use Functional Globals when: You need controlled access to data, want to encapsulate data management logic, or need to ensure some level of synchronization. Use Data Value References when: You need to share data efficiently between multiple parts of your application, need flexibility in the data types you are sharing, or when performance is critical and synchronization can be handled externally. It's worth noting that in many cases, a combination of both techniques might be used to leverage the strengths of each approach. For example, a DVR might be used to share data, while a functional global (or an action engine) is used to manage access to that data in a controlled and synchronized manner.1 point
-
We use the MPSSE.dll LABview driver from Benoit. We are trying the i2c read 1 byte and multi bytes. We expect ack for all bytes except the last byte with nak. During read, we understand that the I2C master drives the ack/nak. However, ack and nak happens randomly. Any body have any suggestions Thank you Dan1 point
-
MAT files are now just H5 files(HDF). Look at the library https://h5labview.sourceforge.io/ and find the example for writing a MAT file. You just need to add a special header in the beginning. I assume the dlls needed will work on Windows server, but am not sure.1 point
-
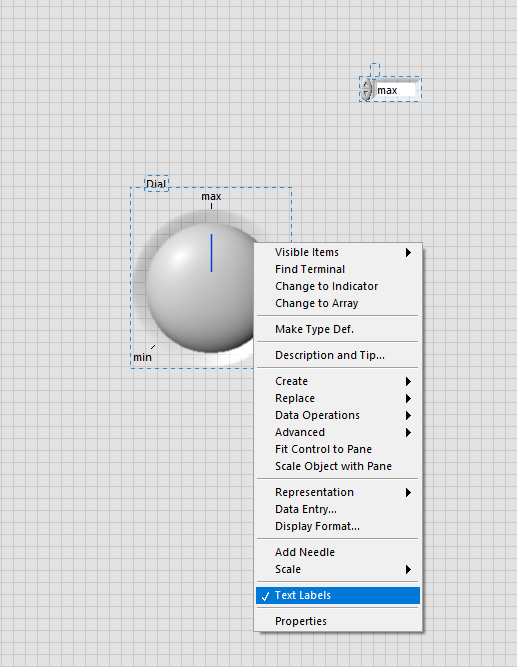
You can add text labels to a dial. It does not turn it into an enum but sort of works like you would expect (change the data type to U8).
1 point
-
I don't have good examples to share, but here are a few helpful links for you: NI has an article dedicated to DVRs, which also explains the fundamental idea: http://www.ni.com/product-documentation/9386/en/ Here is a short video that explains how to use a DVR and some of the pitfalls: https://www.youtube.com/watch?v=VIWzjnkqz1Q Of course, you'll find lots of topics related to DVRs on this forum.1 point
-
Here is a quick and dirty edit. It allows for column separators to be moved, but I noticed that on resize it will set the column widths. So this means if you manually move the columns, and then resize the control it may change the columns in an unexpected way. But at that point you can manually move the separators again. I only have 2017 and 2018 so this is for 2017 and newer now. Variant_Probe-2.4.3-0.ogp1 point
-
Thanks Mads.1 point
-
Looks like someone beat me to it! Oh well, I already exported it (also for 2009, incidentally) so I'll post it here in case it'd be more convenient to use a regular VI file. 0 to -4096.vi1 point
-
Hi All, I'm looking for a good resource that explains LabVIEW's Execution System / Thread Allocation / Thread Priority system. As a background to the reason for my request: I have an application with over 50 parallel loops running at fixed but configurable times. Twenty of these loops are calling a .net Dll and are thus not in a Timed Loop (there is a known issue according to NI support with calling a .net dll in a timed loop where the call time is large ie. upwards of a second). The remaining loops are performing other data acquisition. Each loop is what I call a Task Controller - it looks after a specific piece of hardware, taking requests for data (via queues), performing data acquisition and then pumping the result back to the requester. In order to seperate the timing of the functionality (and allow multiple requesters access to the same data), this process is not sequential but occurs in parallel loops. So there is a lot of parallel activity going on. I notice that as more of these loops fire up, the slower the remaining loops are. The CPU usage tends to stay around 7-8% during this time irrespective of how many loops are executing. Note that the .net dll calls (up to 20) are reasonably slow calls and each could take up to 6 seconds to execute. The .net dll has been written to handle multi-threading. The PC is a hyper-threaded quad core (ie 8 logical cores) @ 3.3GHz. Kinda a meaty machine. I should also mention that the majority of the VIs are re-entrant. The only non-rentrant VIs are some FGVs and a few User Interface VIs that reference the data in these FGVs. And before you ask the FGVs are simply Get/Set for a handful of cluster points. So I figure it's a simple case of thread starvation. Every VI is currently set to the Standard Execution System (via Same as Caller) with Normal Priority. I figure that adjusting these settings on the top level Task Controller vis may assist in spreading the load to the remaining available, but not executing, threads. The SubVIs under each Task Controller will continue to use the Same As Caller setting, allowing me to seperate logically each Task into appropriate Execution Systems. Any thoughts?1 point
-
Start with NI's article "How Many Threads Does LabVIEW Allocate?" Also see the LabVIEW help for "Multitasking, Multithreading, and Multiprocessing." If you divide your code across execution systems instead of leaving them all at "Same as Caller" you should see the work distributed across more threads, and probably better performance and higher CPU use.1 point
-
The candles are starting to flicker to life... I read that and immediately wondered why the first case causes a broken run arrow and the second doesn't. (Hey, it was in CAPS... it was easy to skip the preceeding sentences.) Then the word "object" in the PRTC context help hit me over the head. From my end user perspective, previous versions of Labview don't make a distinction between classes and objects. (For example, the To More Specific Class prim has 'Target Class' as an input that in reality accepts an object.) Despite my attempts to differentiate between the two when posting, in my head I often use the terms interchangably. I'll have to work hard to change my way of thinking. I'd give you more kudos if I could...
1 point