
Mads
-
Posts
471 -
Joined
-
Last visited
-
Days Won
33
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Mads
-

Issues building applications in LabVIEW 2023 Q3
Mads posted a topic in Development Environment (IDE)
Having mostly completed a major update of one of our largest projects I wanted to evaluate if we should take the step from LabVIEW 2022 Q4 32 bit to LabVIEW 2023 Q3 f2 64 bit before release...Unlike many we seem to rarely experience issues when upgrading (7-2022...), but this time I've hit a wall. I had read about how people have problems with buidling applications with VIMs in 2023Q3, but there seems to be all kinds of other issues going on. At first builds would fail with Bad VIs, but clearing the compile cache removed that. Now instead, LabVIEW hangs on "Initializing build", then crashes after a while. I've reinstalled/fixed the full LabVIEW installation, mass compiled everything including the entire VI lib etc...but to no avail. I see a lot of users say they have moved back to 2023 Q1, or plan to wait for 2024 (will there even be a new release in 2024 I wonder...), but are there users out there that do get things to work fine, even with RT Linux targets and 64 bit? I'll reinstall once more and this time try the 32 bit version...but if things still do not work I think we'll skip 2023 and hope for better days in 2025(?). -
How far from the goal are you now, and have you identified where the time is spent? If you e.g. just manually launch the LabVIEW application and flag when it does its first action, how much of the minute is spent already and how much time does the rest of its tasks use? You say you want the program to be launched by Windows as quickly as possible too, how much time does it take for Windows to launch it now compared to any other simple application/service you can set up?
-
When I first saw the compount add I though that must be use because it is quicker than multiplying by 3, but in the tests on my machine it is the slower. With the replace logic though it does not matter anymore. A digression: Branch prediction is an interesting phenomenon when dealing with optimizations. In this particular case it did not come into play, but in other cases there might be a benefit in making consecutive operations identical 🙂 : https://stackoverflow.com/questions/289405/effects-of-branch-prediction-on-performance
-
You beat us well @ShaunR 🙂 Normally I would use replace in situations like this too, to get the advantage of the preallocated memory. I improved some of the OpenG array functions that exact way (which is now included in Hooovah's version), but lately I've gotten so used to the performance and simplicity of conditional indexing that I did not grab for it here 🤦♂️.
-
A bit quicker it seems is to use conditional indexing, like this: On my machine I got the following results (turned off debugging to avoid it interfering with test and removed the display of input as I would occationally get memory full errors with it): Original: 492 ms ensegre original: 95 ms ensegre with multiply by 3 instead of 3 adds: 85 ms Conditional indexing: 72 ms There might be even better ways..The efficiency of conditional indexing is often hard to beat though. demo_rev1.vi

-
On a related note GDevCon 4 just ended in Glasgow with a record number of attendees....👍 (Maybe that is partly because the alternatives are not as good/many anymore, but let me be optimistic for a while...) If Emerson does not want to kill or starve LabVIEW, maybe there is a nice future beyond 10 years as well. Retirement age is steadily getting pushed upwards though so personally it would be nice if things went on for another 25 years, or even better; allowed our kids to make a career working with G everywhere in 2050😀
-
Where do y'all get your (free) artwork for UI elements?
Mads replied to David Boyd's topic in User Interface
We use the nuvola icon set for a lot of things. -
Found it, here:
-
The link only points to Jordan's profile, but he might have been involved back then yes...
-
I had noted a simple recipe earlier from here somewhere for manually installing lvzlib.so (OpenGZip 4.2beta) on Linux RT 2020 and newer now that the "Custom Install" option no longer exists / works in NI Max, but I seem to have lost it and cannot find it again. Do anyone know where that discussion was, or has the recipe?
-
When it comes to "Remove Duplicates" the performance of OpenG is a bit of a curious case (unless I am just overlooking something obvious). The original OpenG function builds the output arrays one element at a time, but still (in my LabVIEW 2022 at least) outperforms the alternatives I make where I reuse the input array. The latter use less memory it seems, as expected, but it is as if LabVIEW has become smarter when there are repeated build operations (but not for the functions we have gone through previously...(yes debugging is disabled..) 🤨 The attached version is a simplified one of the original suggested revision. As mentioned it does seem to use less memory than the original OpenG, but is still slower 😞 Remove duplicates.zip
-
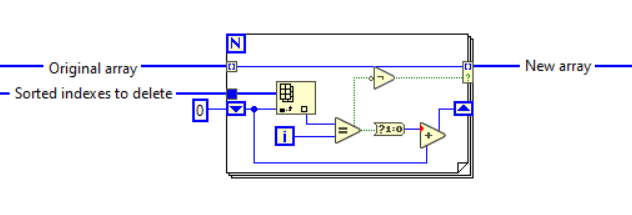
Not sorting the array we are processing, sorting the array of elements to delete. That is done just to facilitate the filtering algorithm, it does not affect the array that is to be processed. (Unless the sort has somehow gotten misplaced somewhere in the code that has been bounced around here...)
-
?
-
Performance mainly becomes an issue when the task at hand is heavy. I do not think saving microseconds on a small array/filter list is worth losing milliseconds or seconds when the array gets large. So that would be the rationale for simply ignoring the "quick on small arrays, slow on large" and choosing the one that is the fastest in the worst cases. However - there is one case where this can become an argument *for* keeping the other algorithms too; namely when you have to repeatedly run through small array/filtering jobs....🤨 Life is never easy😬 The "Revised version" is the best middle ground; quicker than all on most small and medium arrays, and still 2x times quicker than OpenG on worst case scenarios. The Rev2 one is 10 times quicker then...but in truly worst case scenarios you typically end up writing customized algorithms instead of using generic libraries anyway...(I would then often skip the deleted array indexes output to get things even quicker e.g.).
-
An inversion error snuck in, if you look at the code and invert the inversion its right 🙂 Attached here... Filter 1D test - fixed.zip
-
The old read me file says that only 8 functions were changed so I took a look at one of them now: Filter 1D array Improvement when filtering every 5th element in a 100k array: 2.4x Improvement when filtering every 100th element: 2.2x Improvement when filtering every 1000th element: 1.8x OK, but not that impressive... However, looking at the algorithm I saw that there are repeated 1D Array searches for the whole array of elements to filter, that is costly. So I threw in a new alternative where that search is based on the sorted search instead. That makes a big difference when the number of items to filter is big, for the test cases above the results on my computer were Improvement when filtering every 5th element in a 100k array: 227x Improvement when filtering every 100th element: 22x Improvement when filtering every 1000th element: 3x Now the last algorithm changed two things, it uses both conditional indexing and sort/search sorted array. The sorting bit could just as well be added to the original revision...I guess the reason why OpenG still does not use conditional indexing is to be backwards compatible (very far now though...), and then the in-built sorted search would not be available either. That could be replaced by a binary search function that was available back then too though. Filter 1D test.zip
-
Looks good @hooovahh, feel free to use it / the inspiration 🙂 in your VIMs. PS. Twelve years ago (!) I made other optimized implementations of many of the OpenG functions and posted them here. I could not find them though, but I attached it here now. I am sure some of them are not that much quicker anymore / have better alternative implementations now, but some of them probably are better. I have not gone through them again yet. 1509324986_OpenGArrayRevisedR4LV2011.zip
-
You cannot. The costly method (more so the larger the array and the number of deletes are) is to do repeated deletes (decrementing delete indexes as you go if you do it in order e.g., see attached example code). It is costly in both memory and speed due to reallocation on every round. (The same goes for array building; do not do it one element/subarray at a time, pre-allocate the full size then replace (or use auto-indexing in for loop to have LabVIEW pre-allocate automatically)). For multiple deletes nowadays I suspect conditional array indexing will most often be the most (or at least quite) efficient way to handle it. Something like this (NOTE this particular example assumes sorted (and non-empty) delete indexes!): If the evaluation of which elements to delete can be done within the loop the logic gets simpler... Doing a quick test on my computer, comparing it with deletes of half the elements in an array of 100k elements (extreme case), this cuts the time of the operation from a whopping 3 seconds to 0,4 ms (OpenG does multiple deletes from the end instead of start, that is only marginally better (1,5 sec) than deletes from the start (3 sec), as you can see in the example code). Before effective conditional indexing in for-loops was added to LabVIEW a more efficient algorithm (still, but only very slightly) would involve shifting array elements (using replace, which is very fast and does not allocate) we want to keep to the front, then taking the subarray with the new size in one operation. I have added that to the attached example. Methods of deleting multiple array elements.vi
-
Including solicitation of interest from potential acquirers
Mads replied to gleichman's topic in LAVA Lounge
Perhaps it would be better if Elon bought NI and shifted the focus back to "the software is the instrument (and the car, and the rocket...and everywhere)"😀 Bringing the electric car from tiny boring cars to where it is today is a journey the G-language deserves as well. -
@Jordan Kuehn, have you been able to get this listed as an option in the software install list, or did you use another channel to get the package onto the device? I assumed you could add a ldirectory of ipk files as a local feed, and that that would allow you to see it as an option in the software install menu of the RT image, but I could not get that to work...If you did, how did you do that? I tried adding a local folder as a feed...but the package did not show up in the list of available software. And if this is the way we are supposed to go, is there a way to make one package with support for both arm and x64 e.g., or would you always need separate ipk files?
-
You are trying to avoid a soft reboot as well I assume, not just a power cycle..(which would not be necessary anyway). You can issue a killall lvrt command through the ssl interface and it will restart the application, so if you replace the executable then do that you migth suceed (have not tried), here are two related threads: https://forums.ni.com/t5/NI-Linux-Real-Time-Discussions/quick-software-restart/td-p/3407711 https://forums.ni.com/t5/Real-Time-Measurement-and/Running-a-Real-Time-executable-from-inside-the-CRIO/td-p/3570063
-
I think that is the point he is trying to make though (based on the title of the thread); that LabVIEW should let us specify which plot we are working on when setting a property without it being overruled by what is done elsewhere as long as that is not actually on the same plot. If e.g. you have one location where you want to set the property of plot 2 and you also have some code in parallel working on a a property of plot 4 they should be able to declare/access the separate plots *without the risk of a race condition*. I agree with @infinitenothing, it is a bad design (I have not checked if anyone has already asked for a change of that in the idea exchange though. It would be a good idea to post there.)
-
In our commercial software such dialogs and event logs never expose anything in other than an understandable description of what did not go as planned, and if possible a suggestion on what to do to fix it (the code will evaluate events at key locations and produce user friendly interpretations). The only thing included in the dialog that has to do with the underlying code is the error code specified as a sub-code of a more user friendly overall code (which is what they can also see described in the user manual) and source that tells what the software was trying to do. When support gets involved we have other means to dig out the underlying details (task specific event logging, debug-windows etc.).
-
A related discussion on this is available on the JSONtext Issues page, here: https://bitbucket.org/drjdpowell/jsontext/issues/7/what-should-null-mean-when-extracting-data
-
Bundling Values from ini file into complex Cluster
Mads replied to rareresident's topic in LabVIEW General
One option, perhaps not as flexible as you want but still: OpenG Configuration file VIs can read the ini-file and convert it to clusters, which could then be converted to json using e.g. @drjdpowell's JSONtext... To get up and running with a more flexible solution (i.e. without the need for defined clusters) you could probably pick and merge parts from those two libraries.