ensegre
-
Posts
596 -
Joined
-
Last visited
-
Days Won
26
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ensegre
-
I've had good experiences (in the past, who uses TV cameras nowadays anyway?) with this analog->USB converter (link to a random eshop, no recommenadation). You then see the camera as IMAQdx like any vanilla webcam.
-
hm, no, I haven't yet had to upgrade any installation with vision to 2017.
-
I have a fresh 2017 on windows with vision and both VIs are in. Are you sure it is not an installation problem?

-
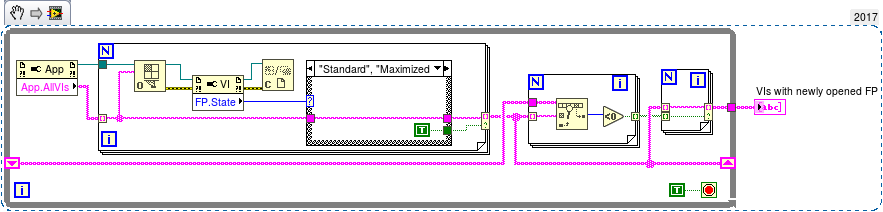
interesting idea. With some modifications like firing only the first time the FP is Standard or Maximized it should do what the OP is asking, and work for clones too. I presume that the cost of dropping it in every BD is minimal and could automated with scripting. Going a step further, such a drop-in could even hold the opening of the FP till it receives a notification in return, that the cosmetic job has been done by the actor which handled it.
-
Maybe not the smartest or more efficient answer. I would think at this: I'd run it periodically and generate a notification for every one of the newly open FPs. Names are identificative as long as no two VI can be in memory with the same name. Now there is the problem of clones, as I was asking here. One suggestion given in the thread points to the fact that the naming scheme of clones is known, only their number a priori is not.
-
Appreciated, thanks.
-

VI server method to get refs of all clones?
ensegre replied to ensegre's topic in Application Design & Architecture
I see... Thanks both. -
I thought there was an easy, built in, VI server way of doing the following, but I haven't found one. Am I missing something trivial? So I have one application instance, spawning clones of a certain VI. I would like to get an array of the VI refs of all of these clones. I thought I could via some property like Application:All VIs in memory, but I haven't found any suitable. All VIs in memory gets only the base VI names. Missing that, I resort to register all my clones in a FGV as they startup, , and consult the FGV at will. Is there a more linear way? RegisterMovieWriters.vi I also note that I have to associate each VI ref with its clone name in the FGV, otherwise plain refs to different clones match as equal in lookups.
-
quick test, seems to work ok in my project on windows. Noob question about vipm: I can't install the vip on linux, as it was build with vipm-2017. How can I build the package from the sources with vipm-2014, which is the latest available for linux (jki said no schedule for a new release). "Open Package Build Spec" LV_muParser.vipb gives me a blunt "VI Package Builder was unable to open the build spec due to an error".
-
No big deal, they are all very simple. The full message from mupGetErrorMsg() is already more informative, beyond that I can't imagine. See my go at it: mupCheckError.vi
-
Indeed the other day I spent some time debugging an elusive crash-LV-second-time-button-is-clicked, which turned out nothing but a mistake attempting to destroy a stale muparser handle. A trivial issue: some of your VIs are broken because of the input varValue moved to position 3 of the conpane on Eval_SglVar_SglRef, I imagine a last minute change for uniformity.
-
I see. Yes, the difference with e.g. a camera is that you can think at scenari where multiple access could make sense. Discipline would be required nevertheless to handle races, even if a lock mechanism is built in, for instance I wouldn't see the sense of updating variables and evaluating completely asynchronously.
-
well, a disciplined programmer shouldn't do that. I think the same could be said for anything else living on some other handle wire. Camera sessions i.e....
-
wishlist: comprehensive error handling using http://beltoforion.de/article.php?a=muparser&hl=en&p=errorhandling, to locate expression syntax errors
-
I might incorporate the toolbox in a project (because it does booleans), and I found out that I would use the evaluation of multiple expressions within a single parser. mupLib/mupEvalMulti does it, but there is no equivalent mupExpr Eval function. What do you think about adding these two to the lvclass? (LV17 but I can backconvert) Besides, you named one Eval_MuliVar.vi, probably a typo. Eval_MulVarMulRes.vi MultiEval.vi mupExpr MultiMulti example.vi
-
Immediate crash "Fatal Internal Error 0x00000001 : "VariableManager.cpp", line 85" opening on linux VIs with controls bound to shared variables (project created in Windows). Something must be going on with the compiled cache, because eventually I can open the VIs (binding reset to none) at third attempt after two crashes.
-
Ah, that makes sense, thanks. As for me I don't have yet an use case for a numeric port; maybe others do.
-
I was about to write: but at least the NI TCP examples work for me, perhaps they use specific open ports? So it turns out I was reaching these examples out of their <LV>/examples/ location, not out of the Example Finder, because "NI Service Locator is not running". That link doesn't talk about linux, nevertheless put me on the track to (re?)install nisvcloc from the rpm. Suddenly my Messenging stuff works on this machine too, weird...
-
I'm evaluating the library for a project of mine, starting from minimal applications. I'm testing on LV17, one windows and two linux machines. My beginnings are fine on windows and on one of the two linuxes, while on the second one they boil down to errors like: which I get from Test Client.vi from the couple in <LV>/examples/drjdpowell/Messenging/TCP example/. On linux I'm with v1.8.3.82, limited by vipm2014. I suspect a simple network configuration difference, but I'm still too lost in the bowels of the library to attempt debugging. Any hint?
-
Discovered, studying it, impressed by its quality and comprehensiveness. Just a really really minor thing which irks me - "varient" misspelled in a couple of places.
-
Is the VI you sent at all related? I don't see any read, any blower, any excel. Nor a for loop, for what matters. Besides I don't have any of this Digilent/LINX VIs. Not knowing the hardware, I can't say if calling in parallel two "Digital Write" and one "Set Duty cycle" is legal or is supposed to cause errors. What I can read from the code is only that since you have "Enable automatic error handling" enabled on in your VI properties (Execution), any error generated by the two bottom subVIs will pop up a dialog. What is for that toolset Error 5001 I don't know.
-
ok thanks Rolf. Impressing how NI didn't invest in this aspect across the years.
-
Doh, you're right, I wouldn't have thought at. Thx! [is that a VI somewhere in /resource/, which could be hacked?]
-
[zombie thread alert] I landed on this thread, realizing that not much seems to have really changed in this corner since 2006. I guess one answer will still be "LV uses internally PICC". But one thing: anyone still knows what is this Control Parts dialog, and whether it is stiil available in more modern LV? Not even to think about programmatic access to this data...
-
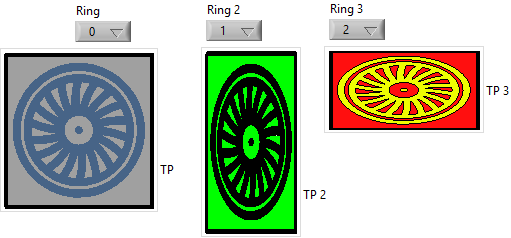
Ok; still unfeature to some extent, but I'm getting there: ThreeStateTurbo.ctl At least as an indicator, it's quite a solution. The trick was to create a stacked set of customized radiobuttons. As for a control, since one can just click on the topmost, one cannot really chose the state of the ring; but one could think at an Xcontrol for that. Also, to size it you have to drag the correct handle (that of the stack group, not that of the container nor of the individual button), but that is manageable. This is what put me on the track: Btw with all this I'm rambling through undocumented unfeatures of custom controls. svg, wmf and emf and quirks. Transparency. Construction and scalability in 32 and 64 bit, windows and linux. DSC polygonal booleans with subparts. Multisegment DSC pipes. Not really "learning", just discovering quirks. I should write a separate post someday...