ShaunR
-
Posts
5,028 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
Make sure your hard disk is up to the speeds you require. You can use these VIs to benchmark your disk.
-

Error accessing site when not logged in.
ShaunR replied to ShaunR's topic in Site Feedback & Support
Confirmed. Thanks. -
Yup. No ideal solutions for a fast, searchable time series database. The best I have used so far is SQLite. It can have 32k columns so does for most things I have to deal with. Inserting 32k into a row at a time isn't all that quick, though. 10k points is usually an acceptable trade-off for dumping graphs.
-
Locally, SQLite. Remotely, MySQL/MariaDB.
-
Error accessing site when not logged in.
ShaunR replied to ShaunR's topic in Site Feedback & Support
The problem is back again. Sorry, there is a problem Something went wrong. Please try again. Error code: EX145 -
Yes. that works. I've checked through the SVN log and nothing has changed in the code from the last time it was run (over a year ago) so I'm not sure why this happened unless the default project refnum no longer returns the root. Thanks for looking into it
-
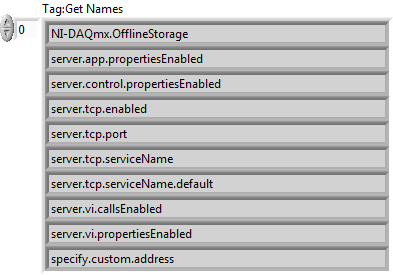
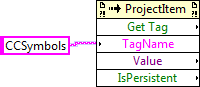
I have a test harness that I haven't run for a while that uses the CCSymbols tag to lookup the conditional symbols of a project. It seems this no longer works and returns an empty variant. There is also a GetSymbols.vi located in "<LabVIEW Version>\resource\plugins\Utility\IfDef.llb" which also no longer functions and returns an empty array. I've executed GetSymbols.vi on LabVIEW versions 2009 through to 2017 and none of them work. (I'm pretty sure it uses the same property node). Investigating further, I have retrieved a list of tags and the only tags that seem to be available are these. I'm sure there were more than this and CCSymbols was among them. Can anyone confirm or deny this? Does anyone have an alternative way of getting the symbols?

-
It's the thing you point to when someone says they've found a bug
- 9 replies
-
- 1
-

-
- over budget
- over time
- (and 2 more)
-
I don't have a problem with that (the old saying the last 10% of a project is 90% of the work ). I just treat it as refactoring and optimization. It's the documentation that grinds me down - Help files,user manuals, application notes et.al.I'd rather have one Technical Author on a project than 2 extra programmers.
-
You probably have javascript disabled or an addon blocking the javascript. 2 people have registered today so the site is working correctly.
-
There is this. I don't know what it is like but it may be a start.
-
This isn't really an issue with agile development-a project can last decades as long as the Product Owner keeps feeding the loop. It used to happen a lot with linear (e.g. waterfall) style projects but agile, with iterative development!, means you get concrete and tested software regularly throughout the life-cycle. That's good for merging changing requirements which keeps things fresh and interesting as well as no "oh god I hope it passes acceptance because there is only two weeks left" after months of work. I haven't used linear development for over a decade.
-
Each executable is a "Single Process" so the variable is only relevant in that executable. The same with "Global Variables". You have two main options for sharing between processes. Network (TCPIP, UDP et.al) or memory mapped files..
-
For standard USB, the malicious code needs to be executed. People get caught out on Windows because they have autorun enabled. Turn that off and a program needs to be executed. Of course, if the malicious code is called "setup.exe" on an NI DVD/USB, you will run it. I've said before. The two things you should always do when getting anew PC is to turn off autorun and set the default operation for VBS scripts to "Open" rather than the default "execute". That defeats auto-infection by most malware even if it is present. To add to the horrors of USB, try Googling for BashBunny and LanTurtle. When a USB device proffers itself as an ethernet adapter it can take over DNS, download code, spy on all internet traffic, steal windows credentials and is immune to virus scanning.
-
That sounds like the start of a great thread topic
-
Snippets are code. There are many examples in that thread and the litmus is to take them out and see how much sense the thread makes, You can't rely on them purely as images anymore because all the icons have changed! (e.g " Here I've used it just to shift each waveform"). I've always hated snippets but if LabVIEW.NET ( ) can accept all the old ones like LabVIEW does now and .NET ones can be dropped into LabVIEW,proper, as is. Then it may mean there is no reason to have different topics at all.
-
That's my point. The UI didn't just get a rewrite. LabVIEW, as it is now, is slowly being grandfathered in favour of LabVIEW.NET. All the community contributed code will eventually be obsolete and the forums are example led not white-paper led!
-
Except that all the primitives have changed so it is not just a UX "option". It is, to all intents and purposes, a different language and examples, snippets and demos aren't synonymous even if they were in an "architectural" sense.
-
It's because the session times out. There are many quirks like the button not operating, attachment uploads fail and of course the autosave....doesn't. If you "gesture back" or press back then all is lost and I too have written a novel as a reply and lost the lot..usually at least once a week. Refreshing and pasting is also problematic when there are quotes that you've replied to.
-
Down sampling required to find barcode
ShaunR replied to Karin Hellqvist's topic in Machine Vision and Imaging
You are probably just after a sharpen. sharpen.vi
-
Another SVN user here (Tortoise SVN client side). Only two functions are ever used, Commit and Revert
-
The create event was required to type the queue dependent on wire type so it had to be first and, because it was always created, it had to be destroyed if it was superfluous. If the disable structure propagates the type now rather than sticking as a string regardless of the control type, then I like that very much There where a couple of race conditions that were responsible for the complexity. So I'll play with yours in the HAL Demo to make sure, but it looks good. There maybe a bug in that part of the code, but it probably isn't what you think. The same VI is also used to send events. For example. If you look at the "SOUND.VI" in the HAL Demo you will see this When retrieving the event we don't want to create huge numbers of event refs in tight loops. We touched on the reason for the register inside the VI rather than requiring the user to explicitly use one in the VIM thread. I also don't like the separate "generate" event but I think only a VIM wrapped in a polymorphic VI could alleviate that and bring it up-to-par with the Queue version (see below). On consideration. Maybe I can see a way without a polymorphic vI, now that type propagation works better. It needs to reliably work when indicators are wired as well as controls and it didn't before. The corollary of this is the Queue VI which is in all my applications.A single, self initialising VI (from the developers perspective) that can act like "channels" between diagrams and services as well as just on the same digram . It too has benefited from "VIMifying" and no longer requires the developer to use flatten/unflatten to/from string - which was an ostrich approach to the type genericism. The thing that prevented the same treatment for events was the event refnum indicator which was intransigent when changing the data type and just broke any VI it was used in until it was replaced. Not any more Nice work.
-
Indeed. But I think most people couldn't be bothered and used variants or put up with coercion dots, so it is rare.
-
Error accessing site when not logged in.
ShaunR replied to ShaunR's topic in Site Feedback & Support
This problem has returned. Sorry, there is a problem Something went wrong. Please try again. Error code: EX145 -
..... revamping of [some] polymorphic reuse libraries. I've never used polys in that in that way for reasons I have said detailed many times before, so they wont be replacing any of mine. I think the incidence of that use case is overstated and probably only applicable to things like OpenG. A much needed simpler adapt to type XNode is a better comparison than a polymorphic alternative, IMO.