LogMAN
-
Posts
720 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by LogMAN
-
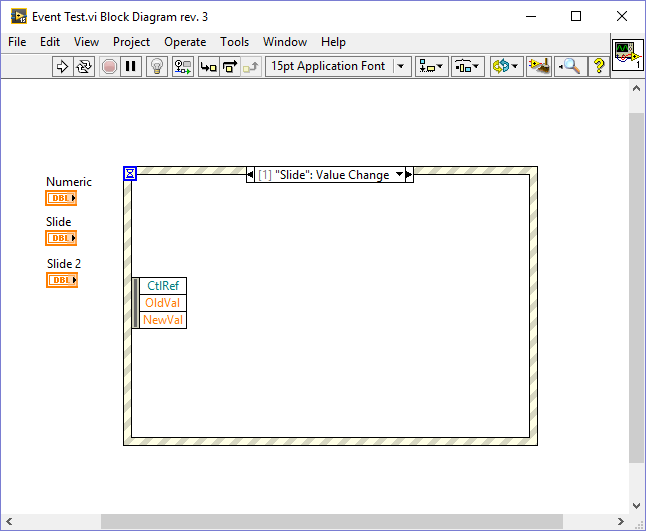
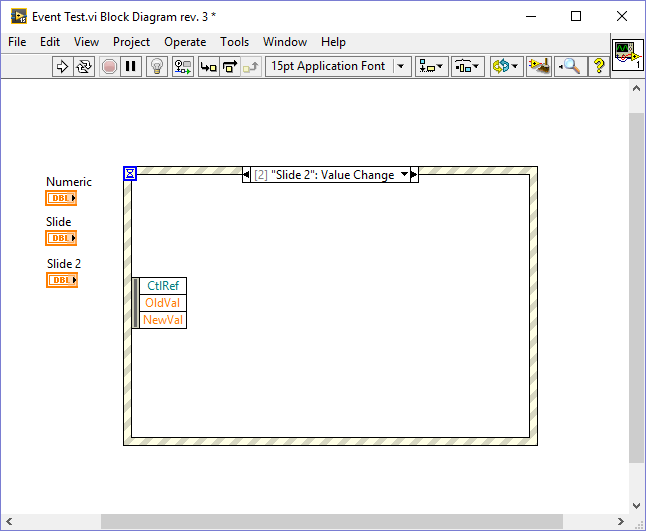
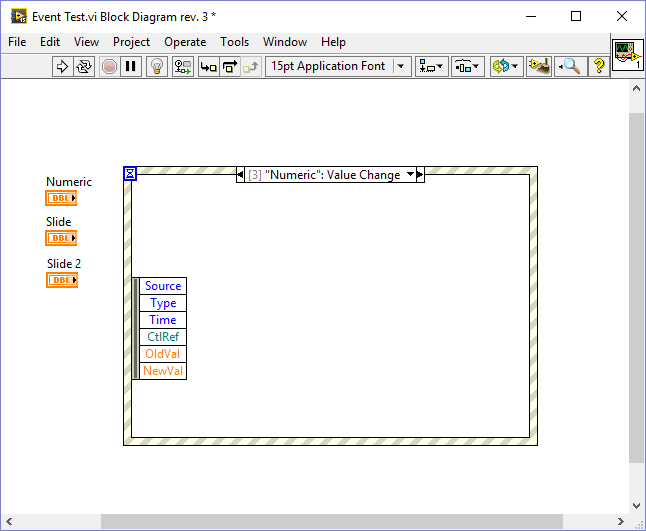
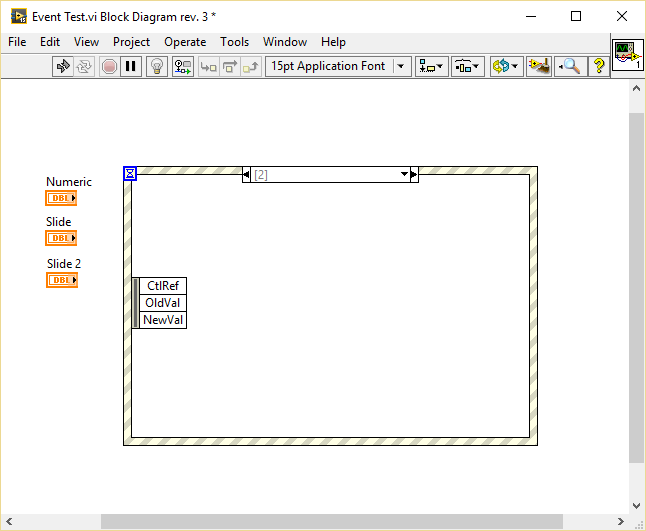
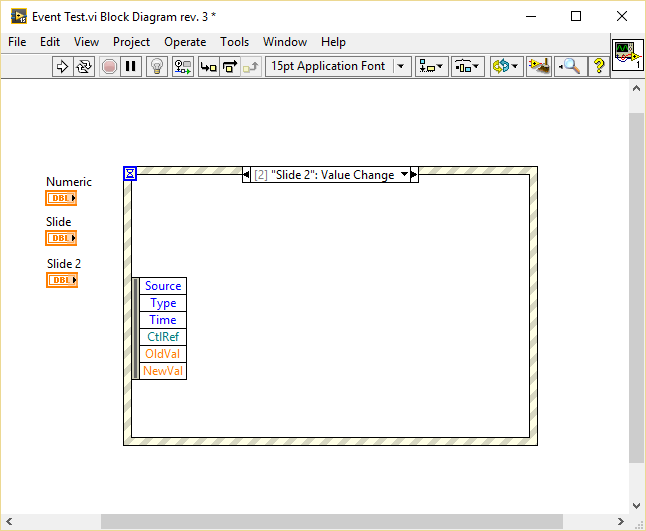
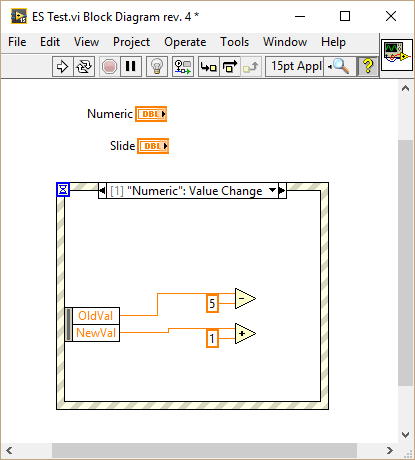
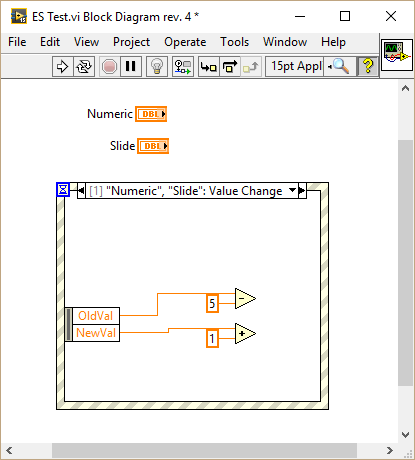
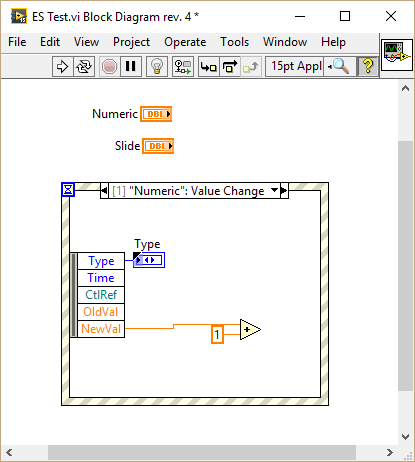
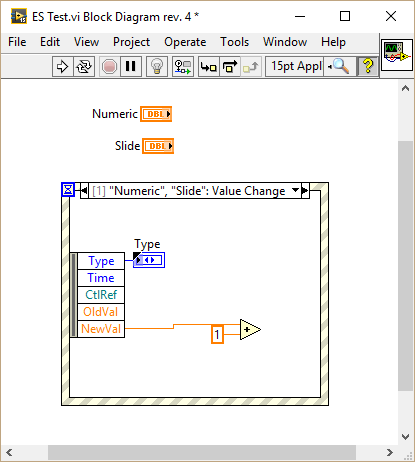
I have been playing around with this and found some interesting behavior. In the following VI I created a value changed event for a slide, duplicated it to another slide and finally to a numeric: As you can see the generated event differs depending on the type of the selected control: Duplicating events to a control of the same type retains the data node. Duplicating events to a control of different type resets the node. I wasn't able to reproduce your behavior because I generally put the control inside the event case that handles the Value Changed event. I only duplicate events which are of the same type or those which are working generically for example by connecting the CtlRef element, in which case I hide all other elements thus I don't get the bug. One more thing: If you duplicate an event without assigning a control right away (just confirm with OK) and later assign a control of the same type as the source event (a slide in my case), the node of the resulting event will be reset:

-
I don't remember them resetting when duplicating events. At least this is working fine in LV2015, so maybe it is specific to LV2013? Only when adding new events the nodes get reset, which is indeed quite annoying.
-
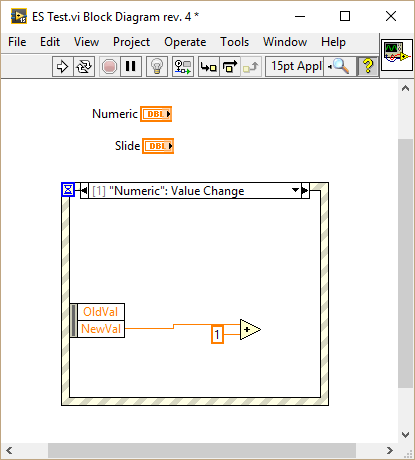
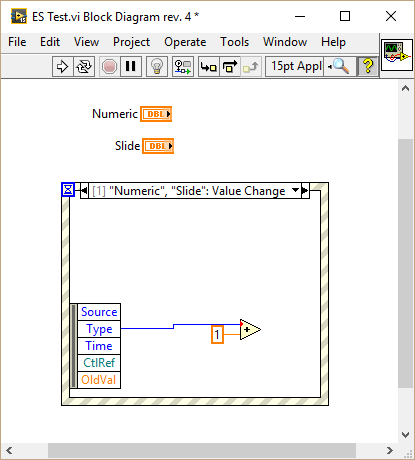
Thanks for letting us know. I wasn't aware of that even though I tend to hide unnecessary event data, adding more events later. Now that I know about it Murphy's law will most likely cause a lot of my code to break during the next weeks I have tested your VI in LV2015 SP1 and can confirm that behavior as well. This bug happens actually as long as there are at least two values available before adding a new event: It is also not limited to the "New Value" data. It seems the node is connected via index (which as far as I know from VI scripting is how everything is connected). When a new event is added the original event data node gets restored and the index is not updated properly. However if all visible nodes are connected there is no issue: Surprisingly there is also no issue if the very first element is connected: My guess: LabVIEW only checks if the very first node is connected and for some reason assumes none of them is used, therefore decides to reset the node. Hope they provide a fix for LV2015 too
-
Yes, I tried sub-modules and decided against them. Not sure about Hg or SVN The obvious reason to use sub-modules is to maintain some "common" repository for use in multiple projects. The OpenG libraries are a perfect example of such libraries. Unfortunately there are a some things which made them less useful to me than first thought: 1. Folder hierarchy Each of those libraries are organized in their own hierarchy of folders, most of which you don't need in your current project. In my case everything is organized in LabVIEW projects using virtual folders where the actual hierarchy on disk is much less complex (typically one folder for each library). So, when reusing a library it would be great to get the same hierarchy in the "owning" project in order to maintain consistency. Since my reuse libraries are organized without library files (*.lvlib), they are just a bunch of VIs on disk, which makes them hard to import into each project because I would have to recreate the hierarchy over and over again. VI packages solve this problem elegantly in my case. 2. Palettes Reusable libraries commonly provide a bunch of VIs, most of which you don't (or shouldn't) use in the owning project. One great example is the array manipulation palette of the OpenG libraries which contains a lot of instances for few polymorphic VIs. Being able to select between a few polymorphic VIs on a palette is way easier than searching through the project to find the appropriate VI. For QuickDrop users like me the search function is very useful. By having all polymorphic instances in the project the search results are useless as all instances are returned as results (depending on the naming schema). Without palettes everyone is forced to search through the project, which is very time consuming. 3. Maintenance The ability to change code "on the fly". You can fix bugs during development of your own project and therefore improve multiple projects at once. While this is true there is also a great chance to break consistency between projects because someone decided to do an "improvement" that is incompatible to other projects. This is actually my main reason against sub-modules. Example: Add VIs from a sub-module to a library file in the owning project, push the sub-module, pull it into another project, welcome to coding hell. 4. Independence: By splitting reuse libraries into separate repositories and providing them as packages you gain control over each one of those libraries individually. During development of those libraries you can focus on the tasks it is supposed to do instead of having to consider the "big picture". In my experience this is a big burden taken from the shoulders of each developer. I already have to consider about 1k+ VIs in a single project while I don't have to consider the 1.5k+ VIs in our reuse libraries. And these are just "tiny" projects compared to the ones I have seen others do. When one of our reuse libraries is missing a feature I do a feature request. When something is not working as expected I do a bug report. Both of which can be implemented and analyzed on their own pace. If I need them done "now", I'll take charge of the feature request or bug report myself. Of course these are just my experiences based on our workflow. It could be an entirely different case for you.
-
Atlassian/Git with SourceTree as client. Also getting Atlassian JIRA soon™ Git because it doesn't require server connection and is the fastest to work with in our case. SourceTree because its easy to learn and useful for users with terminal phobia.
-
I'm doing two downloads at a time (standard setting in FileZilla) and never got banned.
-
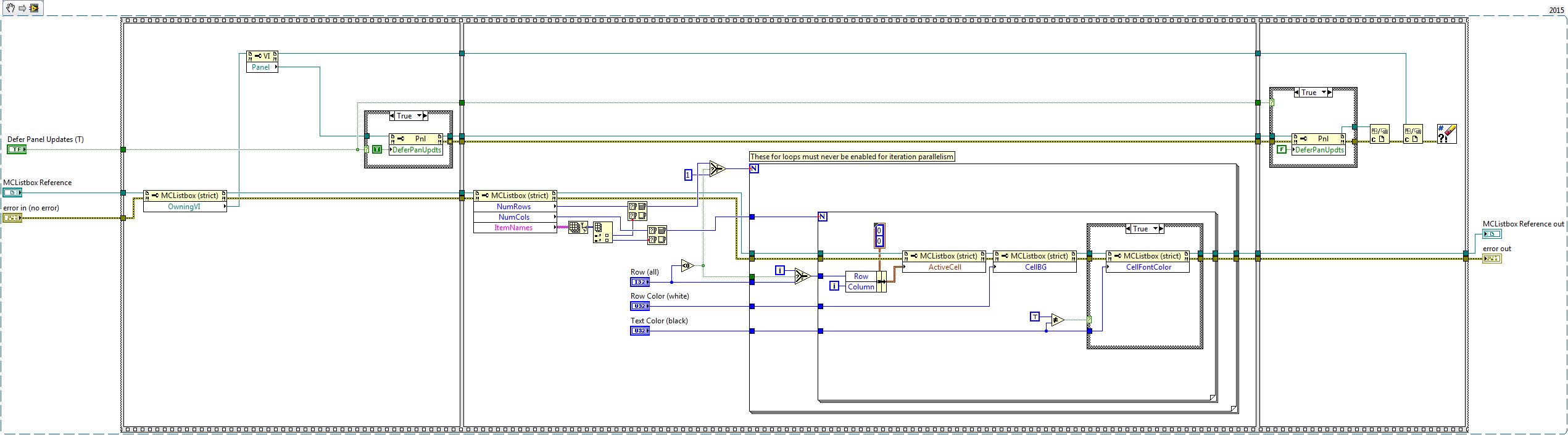
Sure there is, here you go: Edit: Having multiple colors in the same cell is not possible.
-
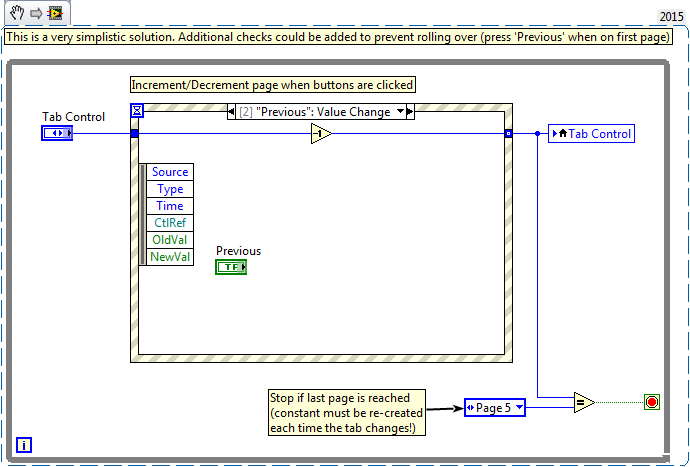
 You can use tabs like regular numbers. Increment to get to the next page, decrement to get to the previous one. This is an example: Of course you need to add additional checks to prevent the "Previous" button to skip from page 1 to page 5 and things like that.
You can use tabs like regular numbers. Increment to get to the next page, decrement to get to the previous one. This is an example: Of course you need to add additional checks to prevent the "Previous" button to skip from page 1 to page 5 and things like that.
-
Controls and VIs work for me. Other items can be checked by first casting the generic project item to the desired type. Here is an example to check if the private data of a class changed. Other types can be added similarly: I searched a bit for libraries and the project file but couldn't come up with a solution. Any ideas?
-
Sure there is. Use a property node on the VI reference and select Modifications >> VI Modifications Bitset This is the description from the help: Here is an example based on the VI from the topic you mentioned:
-
database What Database Toolkit do you use?
LogMAN replied to drjdpowell's topic in Database and File IO
We use SQLite for all local configuration and MSSQL for public/shared data. For SQLite we use your SQLite library (can't say it often again: Thank you very much for that great library!), for MSSQL we use the NI Database Connectivity Toolkit. Big data like graphs (raw data) are generally stored in TDMS files, and in a few rare cases as binary files or even XML files. -
I think the lack of feedback is caused by general confusion about the status quo. I'm sure many people still use the library, though there haven't been any update since 2011: https://sourceforge.net/projects/opengtoolkit/ <= Also that is the right spot for your changes The project is open source, so if you are really committed to get involved, this is what I think you should do: 1. Contact the admins over at SourceForge to either merge your changes or grant you write access. 2. In case you get no reply within say... one or two month, consider the project abandoned and fork it. (you are not limited to SourceForge, use the platform that is to your liking) I think there are a couple of people here at LavaG that would participate in the project if someone would just start being active and committed to the project again.
-
Nope. Home works for me; I'm still logged in (FF-48). Seems to be something on your end. Maybe your browser is confused about the "new" layout. Have you tried clearing the login cache?
-
How to turn off diagram dancing in LV2016
LogMAN replied to ShaunR's topic in Development Environment (IDE)
You don't understand: This IS the compact view (though the icons looked way smaller on a 4K monitor)... how very strange... Seriously though for long-term user like us it doesn't look very appealing, but it might help attract new customer/user in the future. Nowadays everything is about how it looks, so NI would be stupid not to develop in that direction. Also there is one bright side: Now everyone got a reason to make use of QD. Not sure if this is what you meant, but it looks like a bug(feature). Do this: Create a new VI, place a structure (while loop), insert one or two functions IN the structure (no need to connect them), select both (all) and begin dragging so they come close to an edge of the structure, while still holding the left mouse button (dragging) press and hold space (sometimes you'll have to keep moving the mouse and let go of space) This is how you grow your diagrams now -
Problem for sending 2 CAN frame with different interval
LogMAN replied to GU Haojie's topic in LabVIEW General
I have done this in the past with (multiple) NI-USB 8473 and invested hours and hours just to try and keep the frames synced. It's impossible to keep the frames on a certain interval as the OS and the USB will kill your timing. My application experienced delays of more than 400 ms for frames that required intervals of 20 ms! Long story short: Do yourself a favor and use an XNET compatible PCI card, they support periodic CAN frames by design. You can just drag files in your editor when posting, there is a field just below where you enter your text
-
Tested it and it does not work (VIPM 2014). Also tried to created my own package, changed the description manually and got the same result: Might have something to do with the Community Edition though, I'm pretty sure this was possible at work where I got the Professional Edition. Edit: Could not hold myself back and activated the Pro Edition - The issue is gone! So, your problem is only with the Community Edition.
-
Improved performance with additional tunnels?
LogMAN replied to Rüdiger's topic in Application Design & Architecture
Wild guess: LabVIEW uses the "Delete From Array" function in case 0 to dispose of used elements as soon as possible. For cases 1 and 2 it uses "Index Array", thus does not free the memory (the original array is just passed to the output tunnel and freed afterwards in one go). Case 3 is less efficient as the final 2D-Array takes time to build (requires re-allocation in memory in worse case). Maybe ask NI support? Oh wait... -
I have made the same experience in the past, tried many things and finally moved the examples folder under LabVIEW sources for a couple of reasons: The example folder contains LabVIEW VIs only (in my case that is), so it makes sense to put them under LabVIEW sources. API sources can be arranged differently than "regular" projects, if there are good reasons for it. However this should be made standard for all APIs! Depending on how many configurations you have to manage (about 20 with regular changes in my case), it is less painful to just accept the standard behavior, than trying to convince VIPM to do otherwise. Or more accurately: You can do this with VIPM, but it is a pain to do for every single package, let alone multiple projects! Re-writing the *.vipb requires you to do it every single time, which you will eventually forget! You could potentially use the VIPM API, if you REALLY want to do things your way (never used it though)
-
They do exist in files created with VIPM 2014 and they work the same (just checked and got the same changes) "ID" and "GUID" are both GUIDs, so unless they are calculated based on the configuration data (which makes absolutely no sense), they are just unique identifiers (at least in VIPM 2014). There might be other changes involved, like comparison of the Modified_Date with the actual file date, but there is no chance to know for certain unless JKI tells us. So in my opinion this is a bug (even though we are technically not supposed to change the files manually). Most changes are of cosmetic nature, the others are only relevant to a very small amount of users. So unless there is a great new feature or a fix to a critical bug, there is no reason to upgrade imo.
-
SourceForge is to my knowledge still the host for all OpenG packages: https://sourceforge.net/projects/opengtoolkit/files/
-
The palettes are auto-generated based on the source directory defined in the Build Information tab. I suppose it is set to <ProjectRoot>, so change it to <ProjectRoot>/Source/LabVIEW and the palettes should be correct.
-
It has not been mentioned in the release notes, but "things" change all the times I have yet to install and test the new version (no need, because if it isn't broken don't fix it...), however I would like to suggest a way for you to check it yourself: Keep the original file and change one character in your description in VIPM, then compare the two files. If there is a checksum there will be an obvious change in one line. If that's not the case you might have broken the package by saving the file in the wrong encoding (UTF-16 instead of UTF-8). Maybe try another editor (Notepad++ is what I work with mostly).
-
What is your issue? Put COMPorts_EnumCleaner.vi onto your block diagram and you are ready to go. In all cases you need Administrator privileges. If you want to run the code from within LabVIEW (by running the VI), you'll have to start LabVIEW as Administrator too.
-
Run the program as Administrator.
-
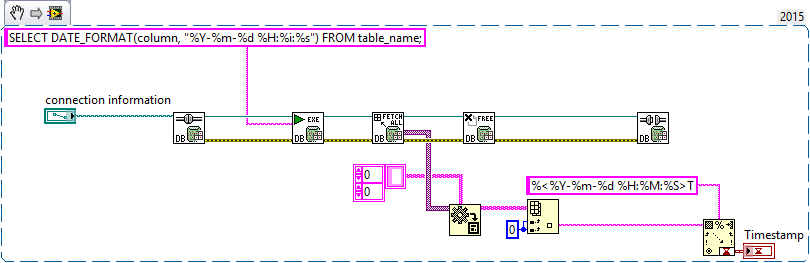
You can execute any SQL query using the Execute Query VI from the Advanced palette. Here is an example I just put together (untested of course):

.png.7332a3e69ced8604c3d9bba8a97ce807.png)
.png.3de6421d600be24d30662aab2d7b7720.png)