LogMAN
-
Posts
720 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by LogMAN
-
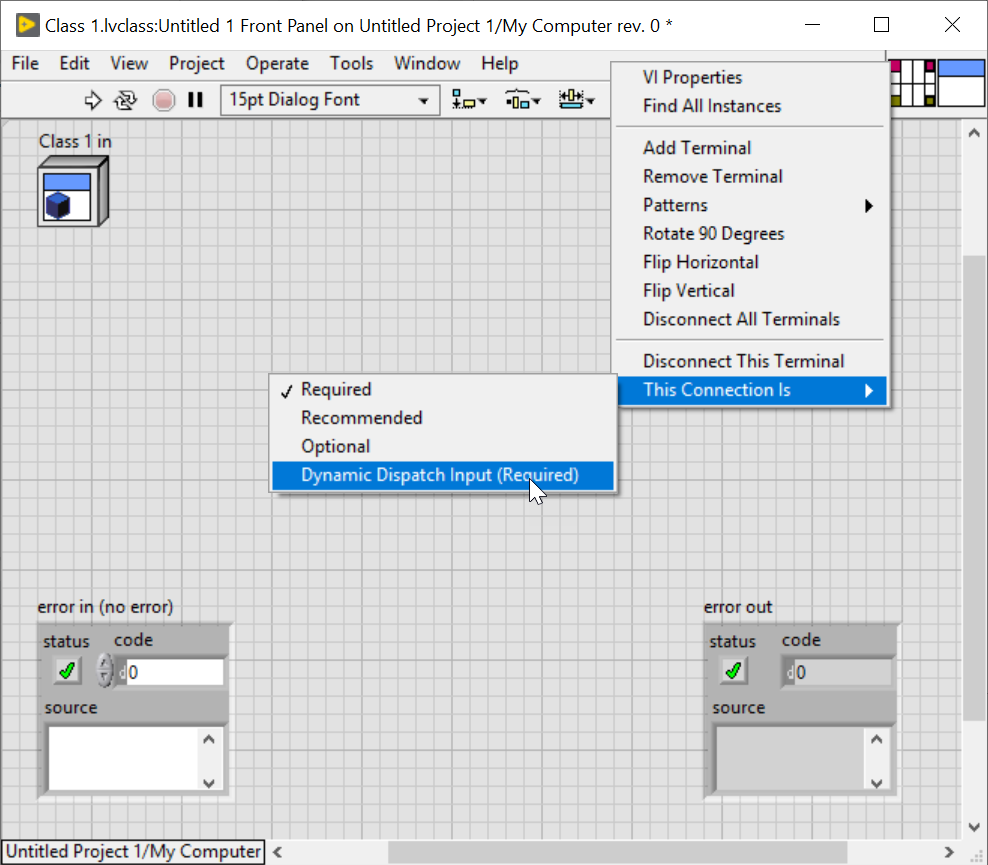
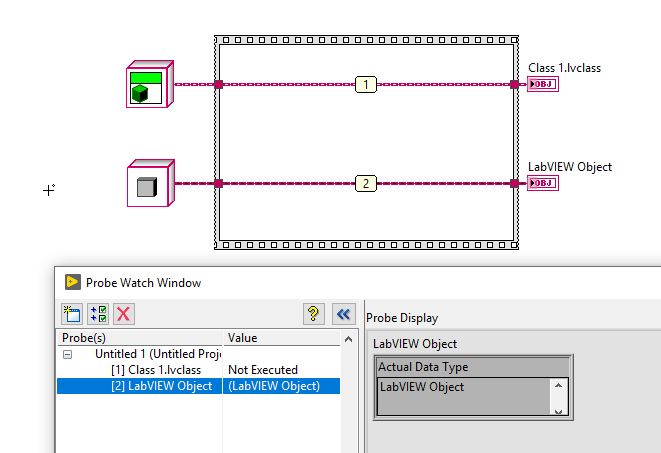
 You can change your terminals to dynamic dispatch at any time by choosing This Connection Is > Dynamic Dispatch Input/Output (Required) at the terminal block. You'll find that this option is only available for class inputs and outputs. To change your VI from static dispatch to dynamic dispatch, simply change both - input and output terminals - to dynamic dispatch.
You can change your terminals to dynamic dispatch at any time by choosing This Connection Is > Dynamic Dispatch Input/Output (Required) at the terminal block. You'll find that this option is only available for class inputs and outputs. To change your VI from static dispatch to dynamic dispatch, simply change both - input and output terminals - to dynamic dispatch.
-
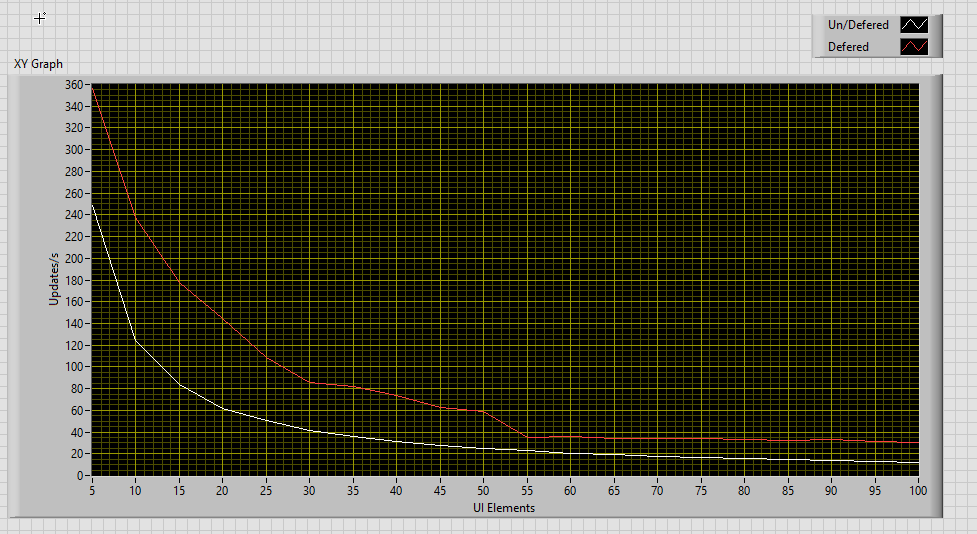
Not necessarily. Controls, Indicators and local variables have "built in logic to prevent front panel updates when continuously updating the same value. This prevents front panel re-draws". You can achieve similar results by deferring FP updates. Of course, writing to the control or indicator directly is the most efficient solution, because they "do not need to de-reference pointers, nor make copies of the data in memory". For your specific case, perhaps you can update the UI less frequently to reduce CPU load. Displaying a new value every 100 ms is more than sufficient for most applications. If you have a lot of graphs, pictures, etc., consider reducing the amount of data and update them only when necessary.
-
Here is a KB article regarding the differences between controls and indicators, local variables and property nodes: Control/Indicator, Local Variable, and Value Property Node Differences There is also an article that explains the different threads in LabVIEW and what they are used for: How Many Threads Does LabVIEW Allocate?
-
The front panel should be visible during the test to ensure that it is actually redrawn. It should also contain the necessary number of indicators to make both cases are comparable. If you reuse the same reference multiple times and defer panel updates, it only measures the iteration time of the For-loop + a single redraw, which is not the same as updating the UI on every loop iteration. Here is a version of your VI that has 100 boolean indicators on the front panel and is visible during test (it is also important to have all indicators visible on screen during test): MethodPerformance.vi On my PC the differences are much smaller with this version (if you set the number of elements to 1, the number of updates is roughly the same).
-
You need at least four characters. Try "DLLs".
-
Did you enable foreign key constraints? You need to set PRAGMA foreign_keys = ON Otherwise foreign key constrains are ignored. https://www.sqlite.org/pragma.html#pr>agma_foreign_keys
-
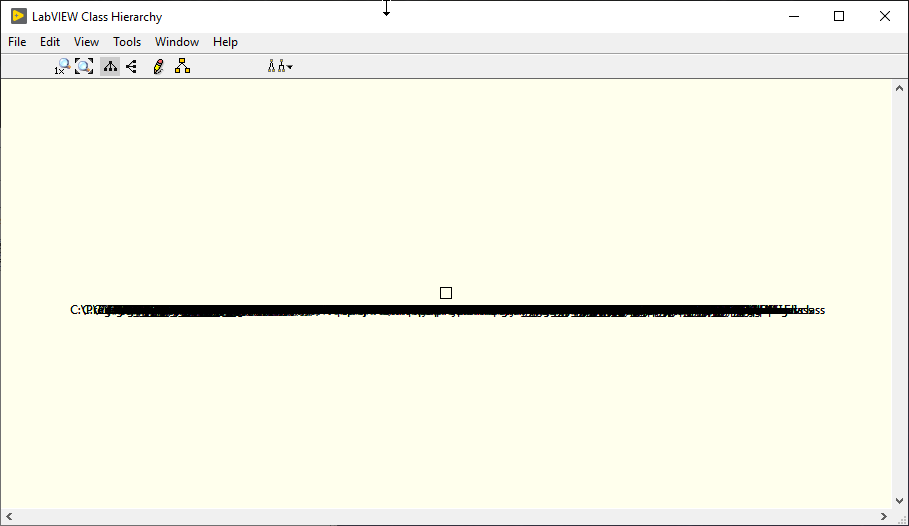
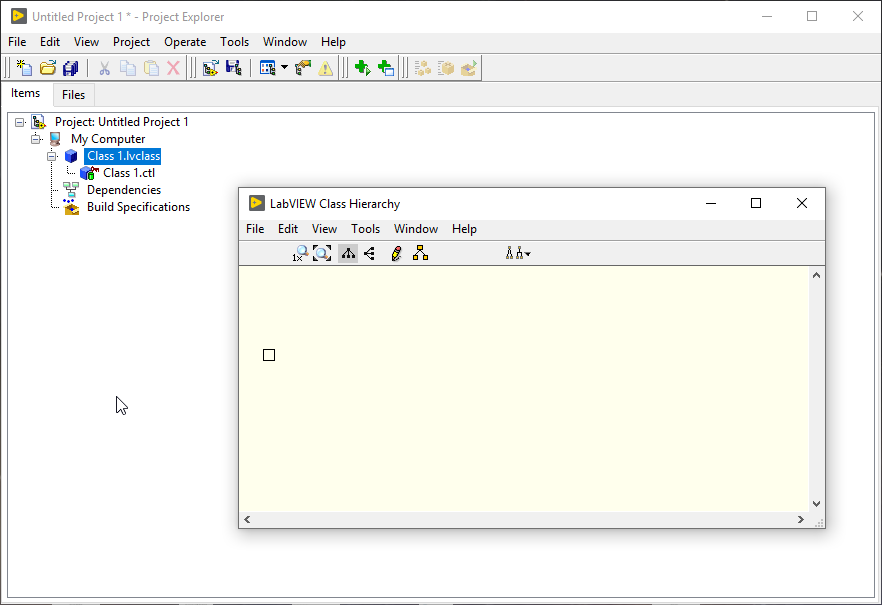
Tested on two machines, same version, same issue. Selection box is an issue only on one machine, though. Found another strange behavior: When using View >> Always Show Labels and View >> Actual Size, this happens: 😕 Thanks, that fixed it for me too. However, only after opening the Launcher.vi. It didn't work by simply opening the example project. Than again, restarting LabVIEW unfixes it. Turns out, it sort of works when you open the class hierarchy window from inside a VI (an empty VI works as well). Steps to reproduce: Start LabVIEW Create new project Add new class to the project Open the class hierarchy window => notice that the window is broken Create a new VI Open the class hierarchy window => fixed 🤷♂️
-
Got (the same?) issue with LV 2019 Version 19.0.1f1 (32-bit): One thing I noticed, if you try to box-select inside this window, it behaves irrationally, like a panel that was moved to far on the X or Y axis. Maybe that's a clue?
-
Class probing Erratic Behavior in LV2019
LogMAN replied to Michael Aivaliotis's topic in Object-Oriented Programming
I see the same issue with Version 19.0.1f1 (32-bit).
-
http://www.ni.com/product-documentation/7900/en/ "LabVIEW 7.0 or earlier used a 64-bit double (DBL) to represent time, yielding 15 digits of precision. The number of seconds between 1st Jan 1904 (the timestamp Epoch or year zero) to 1st Jan 2000 is 3027456000. Representing this as a DBL would use 10 out of the 15 digits of precision. That leaves a very small resolution space to perform hardware timings using most of the resolution by simply going from 1904 to today. Representing time as a DBL was not ideal since it did not meet industry requirements."
-
Most of them are actually LabVIEW specific and do not change based on OS settings. I suppose these are used to make LabVIEW look the same on all platforms. Some of them also emit special behavior. For example, 0x01000037 (system owner) is an opaque color that automatically adjusts the color of an element to the color of its owning container. Changing the color of the container then also changes the color of the contained element without having to address it individually. Maybe this is also useful for XControls.
-
There are, actually, quite a few: https://labviewwiki.org/wiki/Color#Environment_colors
-
It's a dataflow programming language that supports both functional and Object Oriented programming paradigms. Like C++ but not confusing LabVIEW will likely never be popular by the definition in this video, because it is not just a programming language but an ecosystem of hard- and software. It requires a lot of trust in NI and partners. You'd have to compare it to other proprietary programming languages with similar ecosystem for it to be "popular" in comparison. The first thing that comes to mind is interoperability. Calling external code from LabVIEW and vice versa still requires a decent amount of Voodoo (see the SQLite Library or OpenG ZIP as prime examples). To my knowledge there is no "plug-n-play" solution for these kinds of things. This is when the second best solution is often good enough. NI is of course interested in making LabVIEW more popular to grow business. As users we should be interested in making it more popular so that NI and the community can cope with ever-growing requirements and to open up new (business) opportunities. At the same time there is also a risk of growing too fast. The more popular LabVIEW gets, the more LabVIEW is used for tasks it wasn't originally designed for. This will inevitable result in more features being added which increases complexity of the entire ecosystem. If this process is too fast, chances are that poor decisions lead to more complex solutions, which are more expensive for NI to implement and maintain in the future. At some point they have to rethink their strategy and do some breaking changes. I assume this is where NXG comes into play. Is this good or bad? I don't know. It probably depends
-
Bitbucket sunsetting support for Mercurial
LogMAN replied to Francois Normandin's topic in Source Code Control
There is a forum where they want to discuss conversion tools, best practices et cetera: https://community.atlassian.com/t5/Bitbucket-articles/What-to-do-with-your-Mercurial-repos-when-Bitbucket-sunsets/ba-p/1155380 At git-scm they suggest using hg-fast-export. git-remote-hg seems to be popular as well. Someone wrote a script to automate the migration process to GitHub without using GitHub import. Although I'm not sure how well it performs it can be worth a try: https://magnushoff.com/blog/kick-the-bitbucket/ -
Thanks for the heads up, this completely went by me. Here is the official blog post from Bitbucket if anyone is interested: https://bitbucket.org/blog/sunsetting-mercurial-support-in-bitbucket
- 54 replies
-
- 1
-

-
- alignement
- dialog
- (and 3 more)
-
Poll on Architecture and Frameworks
LogMAN replied to drjdpowell's topic in Application Design & Architecture
I wish it were that easy. Yes, they all adequately describe what's being talked about, but only when used in the same context. For example, what do you mean by "code complexity"? The amount of code in a single VI? => i.e. visual code complexity The way code is structured? => i.e. semantic code complexity (not sure if semantic is the right word for it. What I mean is code that is prone to interpretation by other programmers) The way code is executed? => i.e. running time complexity The number of possible code paths? => i.e. cyclomatic complexity It is my understanding that the first two points are about "readability", the third is "time complexity" and the last "code complexity". Good point. "accidental complexity" confused me as well, but the more I thought about it, the more it made sense (good for me, I know). In my opinion "accidental complexity" is a good way to describe how architectures and frameworks can go sideways very easily if decisions inadvertently lead to additional complexity (code complexity, system complexity, whatever). I don't think it's an official term though. Then again, English is my second language. I'll use that as an excuse 😋 -
Poll on Architecture and Frameworks
LogMAN replied to drjdpowell's topic in Application Design & Architecture
As @Daklu mentioned, "complexity" is being used for various perspectives in this thread. Maybe this entire discussion should also be moved to another thread? Here is a definition for "complexity" I find helpful at times like this: The important part is "difficult to re-create". Now let me pick up the example from before: By this definition of complexity, DQMH is indeed more complex than the Actor Framework because it produces many more potential outcomes (its operating state space is larger). The keyword in this example is "determinism": Priority messages in DQMH are nondeterministic (less deterministic is probably a better definition). Priority messages in AF are deterministic. A subtle yet important difference. Of course, here we are looking at the complexity of the framework itself, not the complexity of the user's code. When designing the architecture of a software, optional features like this should be taken into account. If determinism is a key requirement, AF is certainly a better choice than DQMH (not taking other key requirements into account). Let's assume we went with DQMH. This decision can lead to higher costs in the future if determinism turns out to be important and priority messages are being used a lot. In this case there are multiple options: Keep using DQMH and work around the problem with a custom solution => see sunk-cost-fallacy. Switch to another framework like AF You might think "that's never going to happen to me" => see Murphy's law If options were truly optional they would be extensions, not part of the core framework. The fact that priority messages are part of the core framework is a strong indicator that it is not possible to create the same behavior with the API. Thus, it is not optional but an important feature of the framework. As a user certainly, yes. -
According to the activity log @Rolf Kalbermatter is the only active user for at least the past 6 years (log ends there): https://sourceforge.net/p/opengtoolkit/activity/?page=1&limit=100 @jgcode compiled a nice list some time ago. Not sure if all of these are done yet: Here are some ideas that come to mind: Allow the community to participate in the project (create and maintain tasks/issues/features, add maintainers, add admins, etc...) Bring back openg.org (could be a different domain) and allow the community to contribute to the site via pull requests Split the monolithic repository into separate repositories for each project for best practice (and to prevent linking between projects) Convert the SVN repository to Git to allow offline branching, pull requests, etc... Use tags when releasing new versions, this allows everyone to use a prior version if needed. Add documentation for how to deploy new versions (the building process). Add documentation about which LV versions to use and what tests to perform before opening a pull request. Use a single license for all projects. Add a CLA to ensure the license holds for all contributions Work on Feature requests, bugs and change request (there are a lot) Share your thoughts SF is a good place for a small team of developers, working on their project. Users are only meant to report issues and make feature requests. All development is taken care of by the admins/maintainers. Although there are ways to do pull requests, they are very inconvenient and tend to scare potential contributors away. In my own experience, there are a few ways to revive a project like this: Get the original admins back to the project (unlikely, they left for their own reasons) Add new admins/maintainers who have full authority over the project => Requires at least one responsive admin / SF is difficult for contributors (compared to GitHub) Do what @Michael Aivaliotis did. Archive the original code base, move to a simpler platform and build on top of what is currently available. Option 3 is most likely to bear fruit.
-
Here are some common files that could be helpful: The contribution guidelines are shown for pull requests: https://help.github.com/en/articles/setting-guidelines-for-repository-contributors LabVIEW versions, build instructions and the release process are commonly placed in a README file: https://help.github.com/en/articles/about-readmes The license can be managed in a similar fashion: https://help.github.com/en/articles/licensing-a-repository All of these files, if they exist, add to the GitHub experience. For example: https://github.com/microsoft/vscode
-
They do: https://help.github.com/en/articles/setting-your-commit-email-address
-
@Michael Aivaliotis You are right, organizations are the only way to group projects. Just as @JKSH said, a prefix is very helpful in finding things. Looks like you figured it out
-
I suggest informing all active contributors, that way everyone involved has a chance to push their changes before import. The import script supports branches. If you upload your current status as a branch (inside the /branches/lvzip/ folder), it will be detected and imported. Once the repository is uploaded to GitHub you can simply continue working on the branch using Git. You have a chance to match it with your GitHub account (see 'authors-transform.txt'). This is only possible during transformation, however.
-
The simplest way is to add "@users.noreply.sourceforge.net" to make them valid addresses that don't collide with any existing GitHub user (GitHub and SF both support these). It should be sufficient for this task. Here is my version: https://gist.github.com/LogMANOriginal/c4109873a5d524387d3fb46f5b83aa0a I agree. From what I can tell the reason it didn't work correctly is because each project has its own branch/tag subfolder. None of the standard systems support these (including git-svn). Find below a solution that can handle them. Done, see below. Sorry, my explanation wasn't very clear. My point is, that the original commit message actually doesn't have these URLs inside (see SF vs. GitHub). It was probably added during the Atlassian conversion process. Here you go: https://gist.github.com/LogMANOriginal/fa1e59703c41e27758bcb935f15bea21 The script must be placed in an empty folder next to 'authors-transform.txt'. It must be marked as executable (runs in bash, not sh). svn and git must be installed of course. Then start the script via './openg_import.sh' and it should work (unless it breaks of course). It does a few things: Lookup all projects, branches and tags Import all projects into dedicated Git repositories Cleanup the Git repository (i.e. tags are imported as branches, so they need to be fixed) The output are 39 bare git repositories, one for each project with full history, branches, tags and commits. Enjoy 😉
-
It is good to finally see some movement in OpenG. Git and GitHub are also the right choices (Bitbucket would probably also work). Even novice programmers will be able to participate this way. 👍 That said, the current repository has a few problems: No tags No branches All projects in one repository Changed commit messages (the links in the commit messages are non-functional) It is possible to transform an SVN repository into a Git repository while maintaining all tags and branches and updating the committers (because Git uses email addresses and SVN doesn't). Here are some instructions I used in the past for such jobs (instructions are for Linux of course): https://epicserve-docs.readthedocs.io/en/latest/git/svn_to_git.html For OpenG this process is a bit more complex because of the way the repository is structured (i.e. tags inside folders for each project), so the scripts must be adjusted to take this into account. I also suggest splitting the project into multiple repositories during this process to improve maintainability (unless there is a reason why it needs to be one repository). I could prepare the scripts to automate this process if you are interested.
-
Poll on Architecture and Frameworks
LogMAN replied to drjdpowell's topic in Application Design & Architecture
You are right, frameworks do have significant learning curves. Still, if a framework can (potentially) satisfy your needs, even if it looks very complex, you shouldn't be afraid to take a closer look. You can probably filter out most of the frameworks by reading the readme. No need to learn and compare all of them (unless you are scientifically interested of course 😉). Very interesting, thanks for sharing! Among other things, he lists quite a few frameworks, some of which haven't been mentioned yet (see timestamp 19:32). I couldn't find the slides, so here is my attempt to restore the links: Composed System STREAM (bitbucket) Dave Snyder Lap Dog API (GitHub) Delacor DQMH (product page) James Powell Messenger Library (bitbucket) JKI State Machine Object (built on JKI State Machine) (GitHub) Mark Balla Message Routing Architecture (LAVA) NI Actor Framework (part of LabVIEW) NI Distributed Control and Automation Framework (DCAF) (product page) S5 ALOHA Application Framework (product page) Event Source Actor Package (NI forums)