Jordan Kuehn
-
Posts
696 -
Joined
-
Last visited
-
Days Won
21
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Jordan Kuehn
-
That's an interesting question. I'm not sure how I originally found Lava years ago. Probably a google search result since the NI.com search is/was terrible.
-
 Nice. 1996...
Nice. 1996... -
Agreed, DSC should stand on its own for customers that need a SCADA system. I would be willing to bet the vast majority of people using NSV Events have no need for anything else in the DSC Module. At the very least give us a runtime that is free and only has the NSV Events. Thanks for the links! That looks like it would work, but requires a significant investment in time as well as using CVI...
-
I know this thread is a bit old, but relevant to my question. I'm essentially asking the same question that MatthewHarrison asked at the end regarding shared variable events without the DSC module. One twist, I've once made this work via bound front panel controls and registering for a value change event of that control. This was in LV2014. Now I'm looking to do it again with another customer that doesn't want to pay for DSC and it's not working in LV2015SP1. Does anyone have any input on getting this to work in either environment?
-
Switch some forums to question & answer format.
Jordan Kuehn replied to Michael Aivaliotis's topic in Site News
What it you broke the section into 2 sub-fora? One designed for Q&A and the other for discussion. The line is a little blurry, but most people can tell if their post will incite more of one or the other. -
Switch some forums to question & answer format.
Jordan Kuehn replied to Michael Aivaliotis's topic in Site News
Is it possible to have the thread author choose? -
LAVA site upgraded - Feedback welcome.
Jordan Kuehn replied to Michael Aivaliotis's topic in Site News
Well I thought the unread posts would auto-update, now it looks like just the All Activity stream does that. -
LAVA site upgraded - Feedback welcome.
Jordan Kuehn replied to Michael Aivaliotis's topic in Site News
One thing I really like is that some of the feeds (unread content) update automagically now. -
Without derailing too much, I've not found great use for the crio waveform library as my applications aren't this straightforward typically (though I imagine it could be used for this application). Is there something I'm missing?
-
Please respond to the various replies ^. A sample file would go a long way.
-
Check the discussion here. The initial post mentions host->target FIFO, but I mistakenly started a discussion regarding target->host FIFO. Size of buffers is not addressed, but Ned is correct to bring that up as well as frequency of data transfer. You should be pulling data frequently enough to need the check I illustrated with the screenshot, otherwise you are likely overflowing the buffer.
-
Try re-saving your excel file as a .csv file.
-
I haven't tried to make this work on RT, but definitely plan to. Thanks for spending some time diagnosing the existing problems.
-
Correct, no intent to mock, sorry if it came off that way. It was redundant to message me specifically when your question was being addressed publicly, where others also gain the benefit of an answer.
-
Also, I got a very similar question from the same person in a PM. I wonder how many PMs he/she sent out...
-
Active plot order does not match actual plot order
Jordan Kuehn replied to codcoder's topic in LabVIEW General
Also instructions on how to reproduce. If they can't do that first you won't get far. -
I don't think any cloud platform will solve the problem with having to manually join your metadata to your raw data. Perhaps generate a file to go with the data as you produce it. Also, none of these are LabVIEW specific and as you've seen free only gets you limited space. In short, to my knowledge there is nothing that will do much more than what you are currently using.
-
If you are currently using Dropbox, why don't you simply save and edit your work in the dropbox folder. Then you can share the specific folder containing your work with your professor. The same link should work as you update the contents of the folder. You can store your database in that folder as well.
-
Do you happen to have a SSD?
-
This last part doesn't seem to be working. The path control and any other test controls I drop down don't seem to be recognized. I've started working my way through your configuration code, but I thought I might check and see if there is a simple mistake I've made. Edit// Looks like some work is still to be done to get generic objects/controls to display as images. I've worked on that some and made it work. There are some other things I want to do as well. Perhaps I'll post my changes when I'm done, though don't count on me to take things over.
-
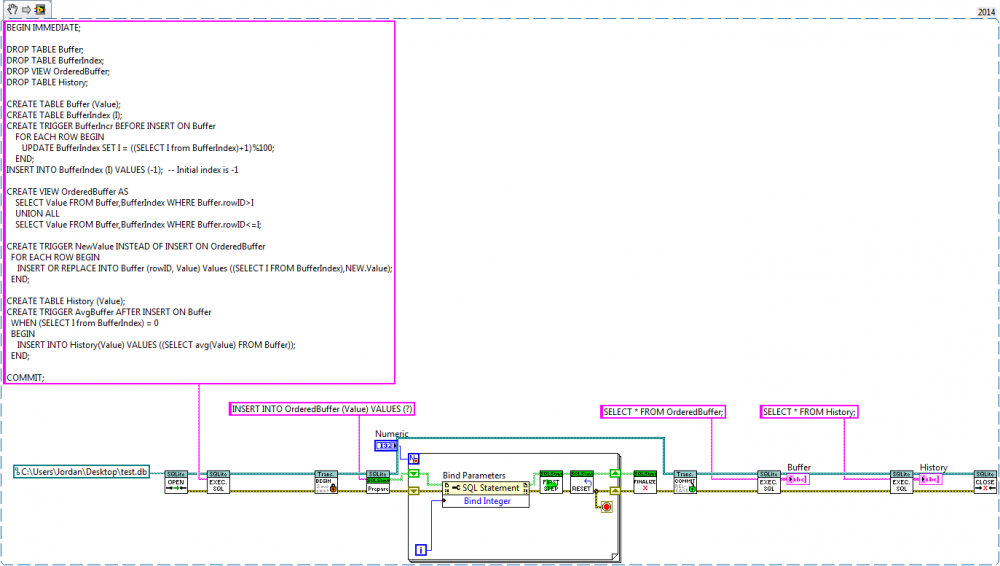
The combined schema from drjdpowell's suggestions with the trigger I alluded to at the end. Works well enough right now while I'm playing around with it. I like the streamlined View and Inserts and simple interface with LV. Thanks for the help. BEGIN IMMEDIATE; -- wrap initial work in a single transaction DROP TABLE Buffer; DROP TABLE BufferIndex; DROP VIEW OrderedBuffer; DROP TABLE History; CREATE TABLE Buffer (Value); CREATE TABLE BufferIndex (I); CREATE TRIGGER BufferIncr BEFORE INSERT ON Buffer FOR EACH ROW BEGIN UPDATE BufferIndex SET I = ((SELECT I from BufferIndex)+1)%100; END; INSERT INTO BufferIndex (I) VALUES (-1); -- Initial index is -1 CREATE VIEW OrderedBuffer AS SELECT Value FROM Buffer,BufferIndex WHERE Buffer.rowID>I UNION ALL SELECT Value FROM Buffer,BufferIndex WHERE Buffer.rowID<=I; CREATE TRIGGER NewValue INSTEAD OF INSERT ON OrderedBuffer FOR EACH ROW BEGIN INSERT OR REPLACE INTO Buffer (rowID, Value) Values ((SELECT I FROM BufferIndex),NEW.Value); END; CREATE TABLE History (Value); CREATE TRIGGER AvgBuffer AFTER INSERT ON Buffer WHEN (SELECT I from BufferIndex) = 0 BEGIN INSERT INTO History(Value) VALUES ((SELECT avg(Value) FROM Buffer)); END; COMMIT;

-
1. I would download from NI directly or host the installer and download from there on the remote PC. Not a direct transfer. 2. We have had no issues using the RAD for RT and FPGA updates. What did you discover? 3. 4. 5. This has proven useful when we migrated several dozen tools from LV 2010 to 2013. Host PCs were used as backups at times during the migration, and sometimes they were of differing versions between tool and PC. Of course, other things may break instead... Props for successfully making a change of this magnitude remotely. We update our tools remotely, but always after testing the procedure on a couple that are in the shop for maintenance. Not really an option for this application.
-
That looks very promising! I'll give it a try. I thought that using a VIEW might be a good approach for retrieval. Thanks! I've used your toolkit as well and will probably use it for this implementation.
-
ORDER BY looks like it would work if I also include a tick count or something with my data. Works for me on the retrieval side, and that is a nice aspect to the DB. On the insertion side, I suppose I could create an auto-increment variable in the DB that would modulo with my buffer size and provide the rowid to UPDATE. I also like the idea of setting up triggers to say, average my buffer and store a point in another table each time it wraps around.
-
That's a fair point and yes it behaves more like a fixed length fifo that crawls along in memory rather than a ring buffer. The UPDATE command would require some note-keeping of where the pointer(s) are on the LV side, but does sound like the *correct* way to do this. I would like to be able to insert element(s) and read the entire buffer already in order in LV without doing that. I think a VIEW would perhaps be the way to go for the retrieval side, I'm not sure about the insertion. As far as not using a db, that's also a fair point and I may not ever wind up using this for my stated purpose, but I think it could still be useful especially when combined with additional tables that perform some historical logging and such. At the very least it's getting me to explore the sqlite toolkits more.