Rolf Kalbermatter
-
Posts
3,974 -
Joined
-
Last visited
-
Days Won
282
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-
 VISA can access also IEEE488 devices. The relevant settings can almost all be accessed through VISA properties.
VISA can access also IEEE488 devices. The relevant settings can almost all be accessed through VISA properties. -
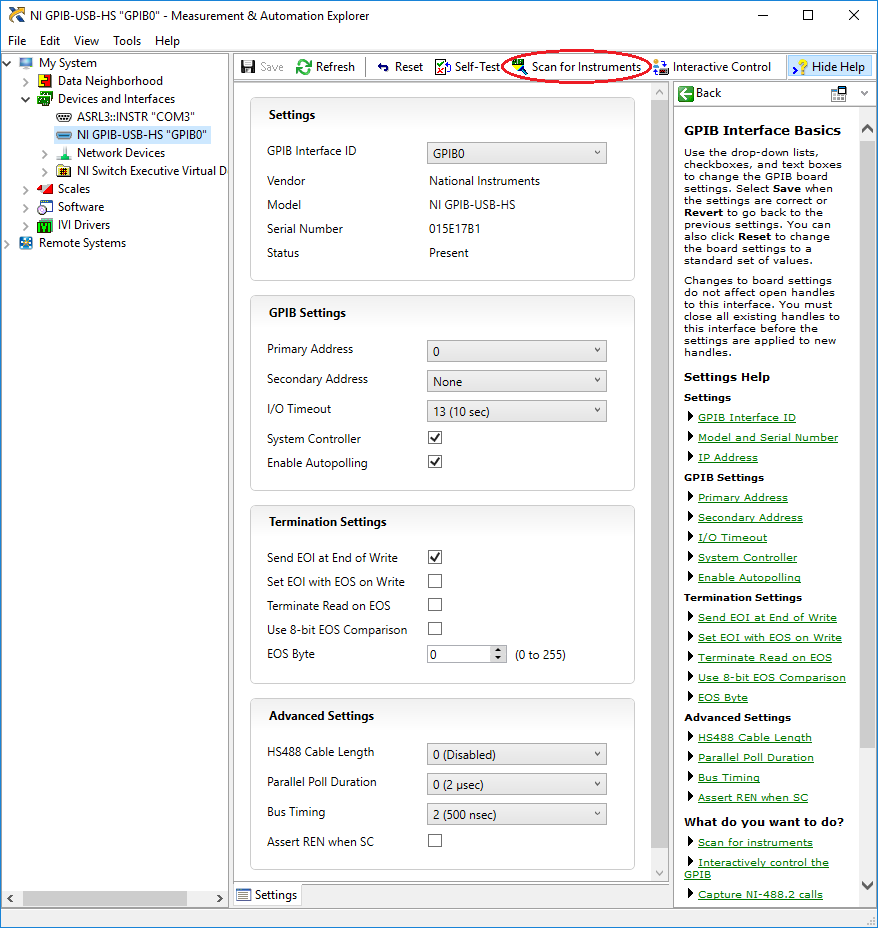
The manufacturing year is irrelevant. When that device was designed in 1981 or before, that’s the technology it uses. Your device may contain a new firmware which fixes a bug or two but certainly not with new improved functionality. As to those settings they absolutely positively must exist in NI-Max. They are functionality of the NI-488.2 driver and have absolutely nothing to do with your specific device. Or are you using something else than a NI GPIB interface to connect to the device? This is what you should see for your GPIB controller in MAX: As you can see there are a number of settings that could be relevant. Considering the age of the device I would guess playing around with Bus Timing (make it slower as the old GPIB controller used in that device might not really be up to snuff with modern GPIB timing), and Assert REN when SC (assert remote enable hardware handshake) might actually have an influence. There should be a similar section with options when you select your device instead in the device tree. But I couldn't find an image of that easily and I haven't used GPIB in several years so can't quickly get a screenshot from one of my machines. As to the GPIB section in the manual there is absolutely nothing that resembles anything IEEE 488.2. They only mention IEEE488 and the little they have in there is absolutely not 488.2 compatible in any shape or form. HP used to fill 10-20 pages and more about all the different GPIB capabilities and features of their devices and several 100 pages about the commands you could use! 😀 The GPIB standard may be technically several magnitudes less challenging than PCIe, to just name one, but you needed to know more about the different capabilities of the device and your controller to make it work. IEEE 488.2 was an attempt to define a common set of features a device and controller should use and also to define some basic commands and their syntax (such as *IDN?).

-
Hmmm, that's one old piece of hardware. I found a manual here: https://www.opweb.de/deutsch/firma/Data_Precision/herunterladen/Data_Precision--8200--service--ID8215.pdf and its covere page has a copyright of January, 1981. Instruments from that time do not comply to IEEE 488.2 at all since that standard simply did not exist then. That only was released in 1987. Accordingly GPIB instruments where using all kinds of weird GPIB settings, including instruments from the GPIB inventor HP itself. You may have to actually go into NI-MAX and change settings for the instrument or even the GPIB controller itself, that listen to names like "enable readdressing" and other possible settings. This was way into the 90ies the main issue about connecting legacy GPIB instruments to a computer. The fact that the few available GPIB controller chips all had their quirks and bugs, that had to be worked around in the instrument firmware, did not make it more simple.
-
LabVIEW "live" USB
Rolf Kalbermatter replied to Neil Pate's topic in Application Builder, Installers and code distribution
This used to be trivial to do up to LabVIEW 5, a little more complicated in up to LabVIEW 7.1 and got really difficult with LabVIEW 8.x. I have never tried to do it with any LabVIEW 20xx version. While it still should be mostly possible for pure software applications that do not use any hardware, both NI and 3rd party, it would be a major pita to try to do it with most of the NI drivers nowadays. Possibly that the application Hooovah proposes can help with that but otherwise I don't really see any possibility to do it reliably. Part of the message does indeed sound like they might refer to actually replacing the Windows shell (usually Explorer.exe) with the LabVIEW executable. That is another possible approach but combining that with an USB portable app installation would really mean that the whole system would have to boot up from the USB device. Shell replacement in itself is not that complicated (it comes down to replacing/adding HKEY_Current_User\Software\Microsoft\Windows NT\CurrentVersion\Winlogon\Shell with the path to your executable that you want to perform as Windows UI instead of the Explorer desktop). The problem is during development/debugging where you do not really want to have that setting active. Generally you want to have a protected way to SystemExec() explorer.exe anyhow from within your own shell. -
Well of course does LabVIEW have to retain the HWND of the container where it places the ActiveX Window. And this is simply a specfically allocated window handle for the container since an ActiveX control requires a parent window when being instantiated and LabVIEW for obvious reasons does not want to hand the full front panel HWND as that would give the ActiveX Control every possibility to mess with the LabVIEW owner drawn front panel (as you know LabVIEW controls, except the ActiveX and .Net Container are not implemented using window controls with their own HWND as with other standard Windows applications, but are fully owner drawn by LabVIEW itself). I still think that the approach with peeking into the object pointer to retrieve information, while being fun to do if you love this low level stuff, is an absolute and big NO-NO for anything that is supposed to leave your mancave.
-
VCS / Development Toolchains in 2020
Rolf Kalbermatter replied to JB_1592's topic in Source Code Control
I have a fair amount of experience with SVN and a smaller amount with GIT. At our company we still use SVN, not because it is super perfect but because it simply works. I have not managed to get myself into a real mess with SVN. The worst that can happen in my experience is that some operation doesn't terminate properly and you have to do a manual cleanup to be able to continue. Enter GIT and that changes dramatically. It's very easy to do just about anything in GIT, including mistakes. And I can not count the number of times in which I spend several hours of unraveling some mess I caused by selecting the wrong GIT action for some reason. The fact that the naming of the different GIT actions is sometimes rather ambiguous and the parameters can be mind boogling complex doesn't hel that either. The few times I did something wrong in TortoiseSVN I simply went into the command line and entered a few simply enough commands through svn.exe and all was well. TortoiseGIT is very easy to do things wrong and the GIT command line, .... well it feels like having to do a one year study to even understand the basics of it. 😀 -
How to stop LabVIEW indicator from flickering?
Rolf Kalbermatter replied to nitulandia's topic in LabVIEW General
That's because if you do any overlay of anything in LabVIEW, LabVIEW will be forced to fully redraw the entire control every single time rather than trying to use optimized region update APIs in Windows. And the graphics driver for your video card seems to have some trouble with proper region drawing. Of course full redraw will be usually considerably slower so it isn't a perfect solution at all. -
How would you do HTTPS without TLS? And it depends about use of LabVIEW. For a general in the field IoT application I wholeheartedly agree. Trying to build such a system in LabVIEW is going to be reinventing the wheel using a high end CAD tool while you can take ready made wheels from the shelf. If it is however part of final step during inline testing of a product, with the whole test system controlled by LabVIEW, it may be useful, although calling a Python script would still most likely be much easier and maybe a few milliseconds slower than fully integrated in LabVIEW. But then the specification sounds a little bit bogus. Rather than requiring that the firmware needs to be written securely to the device, it should simply state the protocol that the device can support. Security in a (hopefully) closed in house network really shouldn't be a concern, otherwise you have a lot more trouble to be concerned about than if the firmware is written securely to the device.
-
So is your link to the DUT over public internet or an internal network? If the first, the client may want to reconsider if that is the way to do firmware updates, if the second, someone seems to be utterly paranoid. I don't think it is to useful to use the TLS functionality for this. This is on TCP/IP level an are you seriously doing firmware updates over TCP/IP? Or are you rather using HTTPS instead which could have been done with the HTTP(S) client functionality since about LabVIEW 2014 already. If you need more specific control you might have to go with something like the Encryption Compendium instead. https://lvs-tools.co.uk/software/encryption-compendium-labview-library/
-
It could make sense if the PostgreSQL DLLs were compiled with Microsoft Studio 2010 or 2012 or similar (not sure which Visual Studio version is used for compilation of LabVIEW 2015) and set to use dynamic linked MS C Runtime library. It is old enough to not be standard on a recent Windows 10 installation and not new enough to not be tightly coupled with a specific Microsoft Visual C runtime version. Since about Microsoft Studio 2015, the Visual C runtime has stayed at version 14.x and doesnt with each new version require a new runtime. It's still possible that a newer Visual Studio application won't work with an older runtime but the opposite works usually without a glitch.
-
Calling arbitrary code straight from the diagram
Rolf Kalbermatter replied to dadreamer's topic in LabVIEW General
Not really safety precautions. Most C(++) compilers will strip by default all symbols from linked non-debug code, unless these symbols are needed for certain puposes like function export tables. While these functions also return a pointer to some sort of export table, they are not official export tables, just as virtual tables in C++ aren't really export tables. The name is unneeded as far as the compiler is concerned, so they get all stripped. This has certain anti reverse engineering reasons as someone distributing a release version isn't usually interested in letting its users reverse engineer their software (just check your license agreement you entered into when installing LabVIEW 😀) but the main reason is really that these symbols simply blow up the executable image size for no useful reason and it's an easy thing to do by the linker. The functions with retained symbol names in there are usually functions that are also exported in the official export table. GetCIntVIServerFuncs() existed before LabVIEW 8.0 and was/is mostly related to functions needed by various VI Server interfaces. The first version of VI server was a very small set of exported functions that got called by a CIN. This was then changed into the fully diagram accessible VI server interface as we know it now around LabVIEW 5. Sometimes the LabVIEW compiler needs to create callbacks into the LabVIEW kernel. Initially this was done through direct calls of exported functions but that was changed for several reasons to call a special internal export interface. Hiding things was likely more a byproduct than the main reason for this, making this interface more uniform among the different platforms was likely more important. The C Interface supposedly took this idea further and here hiding LabVIEW internas might have been part of the decision. But because this privately exported function table is highly inflexible and can only be amended to in subsequent LabVIEW versions but never modified without creating serious trouble with version compatiblity, I think it's not something they would want to use for everything. The advantage is that you do not really need to use dynamic link functionality for this except for the one function to get at this interface, so there is one simple function that will use platform specific dynamic loading and everything else is simply a function pointer call into a table at a specific offset. A COM like interface would be much more flexible in terms of version compatibility and NI uses that in some parts even across platforms despite that real COM isn't supported on non-Windows platforms, but it is also a lot more complicated to create and use even when you program everything in C++. -
Calling arbitrary code straight from the diagram
Rolf Kalbermatter replied to dadreamer's topic in LabVIEW General
I'm aware of the limitation with this function. It not only wants to run in the UI thread but also doesn't allow to specify the context it should be running under, so will likely always use the main application context (which could be fine really, as each project has its own context). And that with the missing context is logical since this function existed before LabVIEW 8.0 which introduced (at least publically) application contexts. I think the mentioned C interface has to do with the function GetCInterfaceFunctionTable(), exported since around LabVIEW 8.0, but that is a big black hole. From what I could see, it returns a pointer to a function pointer table containing all kinds of functions. Some of them used to be exported as external functions in LabVIEW too. But without a header file declaring this structure and the actual functions it exports, it is totally hopeless to think one could use it. As most of the functions aren't really exported from LabVIEW in other ways they also didnt retain the function name, like all those other functions in the official export table. But even with a name it would be very tedious to find out what parameters a function takes and how to call it especially if it needs to be called in conjunction with other functions in there. -
replicate cURL --form file=@<filepath> <URL> behavor
Rolf Kalbermatter replied to Ansible's topic in Calling External Code
Sorry I'm not a curl expert. So you could you explain a bit what all these parameters mean and which of them causes problems? -
Calling arbitrary code straight from the diagram
Rolf Kalbermatter replied to dadreamer's topic in LabVIEW General
I think CallInstrument() is more promising although the documenttion I found seems to indicate that it is an old function that is superseded by something called C Interface in LabVIEW. But I haven't found any information about that new interface. /* Legacy C function access to call a VI. Newer code should consider upgrading to use the C Interface to LabVIEW. */ /* Flags to influence window behavior when calling a VI synchronously via CallInstrument* functions. The following flags offer a refinement to how the former 'modal' input to CallInstrument* functions works. For compatibility, a value of TRUE still maps to a standard modal VI. Injecting the kCI_AppModalWindow flag will allow the VI to stack above any Dlg*-based (C-based LV) windows that may be open as well. Use kCI_AppModalWindow with caution! Dlg*-based dialogs run at root loop, and VIs that run as app modal windows might be subject to deadlocking the UI. */ const int32 kCI_DefaultWindow = 0L; ///< in CallInstrument*, display VI's window using VI's default window styles const int32 kCI_ModalWindow = 1L<<0; ///< in CallInstrument*, display VI's window as modal const int32 kCI_AppModalWindow = 1L<<1; ///< in CallInstrument*, display VI's window as 'application modal' /* Legacy C function access to call a VI. Newer code should consider upgrading to use the C Interface to LabVIEW. */ /* @param viPath fully qualified path to the VI @param windowFlags flags that influence how the VIs window will be shown @param nInputs number of input parameters to send to the VI @param nOutputs number of output parameters to read from the VI @return error code describing whether the VI call succeeded The actual parameters follow nOutputs and are specified by a combination of parameter Name (PStr), type (int16*) and data pointer. @example CallInstrument(vi, kCI_ModalWindow, 2, 1, "\07Param 1", int16_Type_descriptor_in1, &p1, "\07Param 2", int16_Type_descriptor_in2, &p2, "\06Result", int16_Type_descriptor_res, &res); @note This function does not allow the caller to specify a LabVIEW context in which to load and run the VI. Use a newer API (such as the C Interface to LV) to do so. @note Valid values for windowFlags are: kCI_DefaultWindow (0L) kCI_ModalWindow (1L<<0) kCI_AppModalWindow (1L<<1) */ TH_SINGLE_UI EXTERNC MgErr _FUNCC CallInstrument(Path viPath, int32 windowFlags, int32 nInputs, int32 nOutputs, ...); -
They might actually be simply left overs from the LabVIEW developers before the Call Library Node gained the Minimum Size control for string and array parameters in LabVIEW 8.2. The old dialog before that did not have any option for this, so they might just have hacked it into the right click menu for testing purposes as that did not require a configuration dialog redesign, which might have been the main reason that this feature wasn't released in 8.0 (or maybe earlier already). There are many ini file settings that are basically just enablers for some obscure method to control a feature as it is still under development and once that feature is released the ini key does nothing or enable an option somewhere in the UI that is pretty much pointless now.
-
LabVIEW RT - Linux RT PXI - xinetd -System.in and System.out
Rolf Kalbermatter replied to Ryan Vallieu's topic in Linux
A bit of a wild guess but there is a function MgErr FNewRefNum(Path path, File fd, LVRefNum *refNumPtr) exported by the LabVIEW kernel which takes a File, a Path (which could be an empty path as the File IO functions don't really use it themselves) and returns a file refnum that you can then use with the standard File IO functions. Now File is a LabVIEW private datatype but under Windows it is really simply a HANDLE and under Linux and MacOSX 64-bit it is a FILE*. So if you can manage to map your stdio fd somehow to a FILE* using some libc functions FILE *file = fdopen(fd, "w"); you might just be lucky enough to turn your stdio file descriptor into a LabVIEW refnum that the normal LabVIEW Read File and Write File nodes can use. Also note that libc exports actually stdin, stdout and stderr as predefined FILE* handles for the specifc standard IO file descriptors so you may not even have to do the fdopen() call above. After you are done with it you should most likely not just call LabVIEW's Close File on the refnum as it assumes that the file descriptor is a real FILE* and simply calls fclose() on it. Maybe that is ok depending how you mapped the file descriptor to the FILE* but otherwise just use FDisposeRefNum(LVRfNum refnum) on the refnum and do whatever you need to do to undo the file desriptor mapping. -
Calling arbitrary code straight from the diagram
Rolf Kalbermatter replied to dadreamer's topic in LabVIEW General
No not really. I mean something quite different. Given a VI create a sort of function wrapper around it that works as a C function pointer. For that we would need something like MgErr CallVIFunc(VIDSRef viRef, int32 numInParams, VIParams *inParams, int32 numOutParams, VIParams *outParams); with both parameters something like an array of typedef struct { LStrHandle controlName; int16 *typedesc; void *data; } VIParams; That way one could do a C function wrapper in assembly code that then converts its C parameters into LabVIEW parameters and then calls the VI as function. These are not actual functions that exist but just something I came up with. I'm sure something similar actually exists! -
Calling arbitrary code straight from the diagram
Rolf Kalbermatter replied to dadreamer's topic in LabVIEW General
That's a bit ambitious! 😀 I would rather think something in the sense of the Python ctypes package to allow arbitrary function calls to DLLs including callbacks and such. We just need to find a method that does the opposite for this: calling a VI as C function pointer. 😀 -
Common Error and Fix - LabVIEW caught fatal signal
Rolf Kalbermatter replied to Jim Kring's topic in LabVIEW Bugs
Are you using LabVIEW 7.1????? If you use a newer version this should not fix any problem as this specific problem was actually fixed in LabVIEW 7.1.1. The problem was that the LabVIEW enumeration of directory entries assumed that the first two returned entries were the . and .. entries. Since LabVIEW 7.1.1 the Linux version doesn't have that assumption (the Windows version still had at least until recently and that can cause different problems when accessing a Samba mounted directory). -
LabVIEW Resource Template Viewer
Rolf Kalbermatter replied to Sparkette's topic in Code In-Development
Well resources are really a MacOS Classic thing. LabVIEW simply inherited them and implemented their own resource manager so they could use it on non-Macintosh systems too. So that explains why the ResTemplate page seems to nicely describe the LabVIEW resources. It doesn't, it only describes the Macintosh resources and many of them are used in LabVIEW too. As to the resource templates, I looked at them way back in LabVIEW 5 or 6 and my conclusion was that most of them described the same types that a Macintosh resource file would describe too, but NI mostly left out the LabVIEW specific types. And it's not surprising, nobody was ever looking at them, so why bother? 😀 -
Trying to get at the data pointer of control objects, while maybe possible wouldn't be very helpful since the actual layout, very much like for the VI dataspace pointer has and will change with LabVIEW versions very frequently. Nothing in LabVIEW is supposed to interface to these data spaces directly other than the actual LabVIEW runtime and therefore there never has been nor is nowadays any attempt to keep those data structures consistent across versions. If it suits the actual implementation, the structures can be simply reordered and all the code that interfaces to external entities including saving and loading those heaps translates automatically to and from standardized (that includes changing multibyte data elements to Big Endian format) data. The MagicCookieJars used to be simply global variables but got moved into the Application Context data space with LabVIEW 8.0. I'm not aware of any function to access those CookieJar pointers. They did not exist prior to LabVIEW 8 as any code referencing a specific CookieJar was accessing them directly by its global address and I suppose there isn't any public interface to access any of them since the only code supposedly accessing them sits inside the LabVIEW runtime. The only external functions accessing such refnums either use well known, undocumented manager APIs to access objects (IMAQ Vision control) or use UserData refnums based on the object manager (has nothing to do with LabVIEW classes but rather with refnums) that reference their cookie-jar indirectly through the object class name. MCGetCookieInfo() requires a cookie jar, the actual refnum and returns the associated data space for that refnum. What that data space means can be very different for different refnums. For some it's simply a pointer to a more complex data structure that is allocated and deallocated by whatever code implements the actual refnum related functionality. For others it is the data structure itself. What it means is defined when creating the cookie jar, as the actual function to do so takes a parameter that specifies how many bytes each refnum needs for its own data storage. For interfaces managing their own data structures it simply uses sizeof(MyDataStructPtr) or more generally sizeof(void*) for this parameter, for interfaces that use the MagicCookie store for their entire refnum related data structure, they rather use sizeof(MyDataStruct) here. These interfaces all assume that the code that creates the CookieJar and uses those refnums is all the same code and there is no general need to let other code peek into this, so there is no public way to access the CookieJar. In fact if you write your own library managing your own refnums, you would need to store that cookie jar somewhere in your own code. That is unless you use object manager refnums. In that case things get even more complicated.
-
Anyone have any success installing LabVIEW with Wine?
Rolf Kalbermatter replied to Sparkette's topic in LabVIEW General
Well they do have (ar at least had) an Evaluation version but that is a specially compiled version with watermark and/or limited functionality. The license manager included in the executable is only a small part of the work. The Windows version uses the FlexLM license manager but the important thing is the server binding to their license server(s). Just hacking a small license manager into the executable that does some verification is not that a big part. Tieing it into the existing license server infrastructure however is a major effort. And setting up a different license server infrastructure is most likely even more work. That is where the main effort is located. I have a license manager of my own that I have included in a compiled library (shared library part not the LabVIEW interface itself) and while it was some work to develop and making it work on all LabVIEW platforms, that pales in comparison to what would be needed to make an online license server and adding a real e-commerce interface to it would be even more work. -
Anyone have any success installing LabVIEW with Wine?
Rolf Kalbermatter replied to Sparkette's topic in LabVIEW General
LabVIEW on non-Windows platforms has no license manager built in. This means that if you could download the full installer just like that, there would be no way for NI to enforce anyone to have a valid license when using it. So only the patches are downloadable without a valid SSP subscription, since they are only incremental installers that add to an existing full install, usually replacing some files. That's supposedly also the main reason holding back a release of the Community editions on non-Windows platforms. I made LabVIEW run on Wine way back with LabVIEW 5.0 or so, also providing some patches to the Wine project along the lines. It was a rough ride and far from perfect even with the Wine patches applied but it sort of worked. Current Wine is a lot better but so are the requirements of current LabVIEW in terms of the Win32 API that it exercises. That NI package manager won't work is not surprising, it is most likely HEAVILY relaying on .Net functionality and definitely not developed towards the .Net Core specification but rather the full .Net release. I doubt you can get it to work with .Net prior to at least 4.6.2. -
openG Configuration Library, error post build
Rolf Kalbermatter replied to nrosenberg's topic in OpenG General Discussions
Generaly speaking this is fine for configuration or even data files that the installer puts there for reading at runtime. However you should not do that for configuration or data files that your application intends to write to at runtime. If you install your application in the default location (<Program Files>\<your application directory>) you do not have write access to this folder by default since Windows considers it a very bad thing for anyone but installers to write in that location. When an application tries to write there, Windows will redirect it to a user specific shadow copy, so when you then go and check in the folder in explorer you may wonder why you only see the old data from before the write. This is since on reading in File Explorer, Windows will create a view of the folder with the original files in the folder if they exist and showing the shadow copy files version only for those files that didn't exist to begin with. Also the shadow copy is stored in the user specific profile so if you login with a different user your application will suddenly see the old settings. Your writeable files are supposed to either be in a subdirectory of the current users or the common Documents folder (if a user is supposed to access those files in other ways, such as data files generated by your application), or in a subdirectory inside the current user or common <AppSettings> directory (for configuration files that you rather do not want your user to tamper with by accident). They are still accessible but kind of invisible in the by default invisible <AppSettings> directory. The difference between current user and common location needs to be taken into account depending if the data written to the files is meant to be accessible only to the current user or to any user on that computer. -
Actually, I'm using the System Configuration API instead. Aside from the nisysconfig.lvlib:Initialize Session.vi and nisysconfig.lvlib:Create Filter.vi and nisysconfig.lvlib:Find Hardware.vi everything is directly accessed using property nodes from the SysConfig API shared library driver and there is very little on the LabVIEW level that can be wrongly linked to.