ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
Those aren't typo's and errors. They are tests to see if we are paying attention.
-

Serial Communication Question, Please
ShaunR replied to jmltinc's topic in Remote Control, Monitoring and the Internet
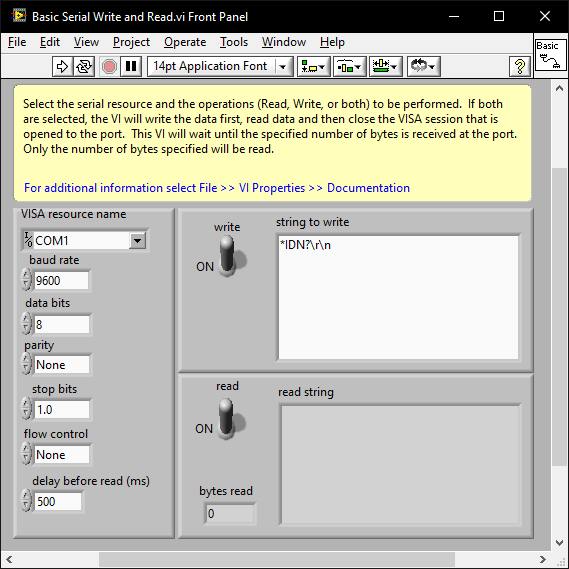
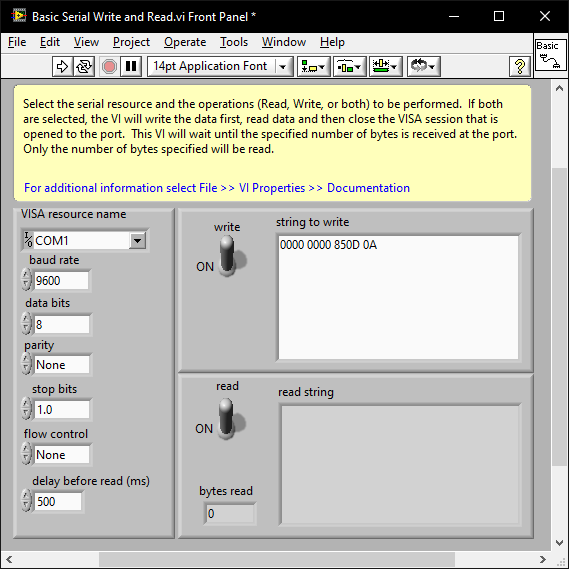
When you know the baud and parity etc; issues that result in the instrument not responding at all are almost always the termination character. Initalise the com port and try a few term chars (CR,LF, CR+LF). ensegre's example turns off the term char. You may just need to add 0D0A to the array. There are examples shipped with LabVIEW and you can also play around with VISA using the NI MAX software. Note that if you right click on the string control and select "Hex Display" you can enter the hex values:
-
Seeking Architectural Guidance: Implementing a Plugin-Based System
ShaunR replied to LEAF-1LEAF's topic in LabVIEW General
VI server. Simple and easy to implement with no framework dependencies. Define a distinction between Services and Plugins (plugins don't contain state, services do). Use a standardised uniform front panel interface between plugins. I use a single string control (see this post) and events for returns. An alternative is a 2d array of strings which is more flexible. Each plugin is contained in it's own LLB which contains all of it's specific VI's. Just list the llb's in the directory for plugins to load. Replace the LLB to upgrade; delete to remove. Names starting with an underscore (either in the LLB name, directory name or file name) are ignored and never loaded. They are effectively "private". A scheme to prevent unknown plugins being loaded. -
Dadreamer is talking about minutes per change though. I still think the symptom is probably exacerbated by XNodes but probably not the fundamental problem.
-
Do you see the unresponsiveness in dadreamer's example?
-
Editing a constant in your test VI only results in a pause for about 1.5 secs on my machine. It's the same in 2025 and 2009 (back-saved to 2009 is only 1.3MB, FWIW). I think you may be chasing something else. There was a time when on some machines the editing operations would result in long busy cursors of the order of 10-20 secs - especially after LabVIEW 2011. Not necessarily XNodes either (although XNodes were the suspect). I don't think anyone ever got to the bottom of it and I don't think NI could replicate it.
-
1.8 MB?
-
You're about to solve JSON decoding.
-
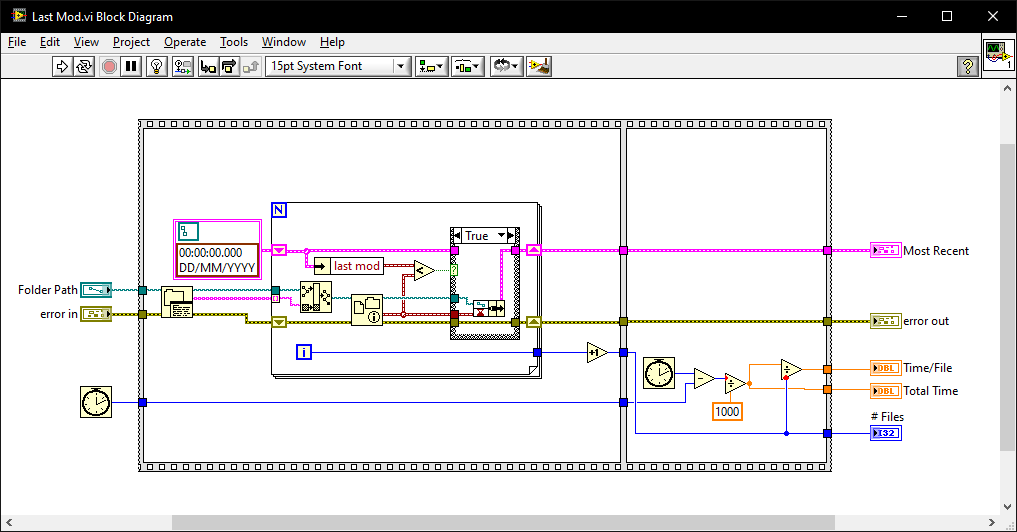
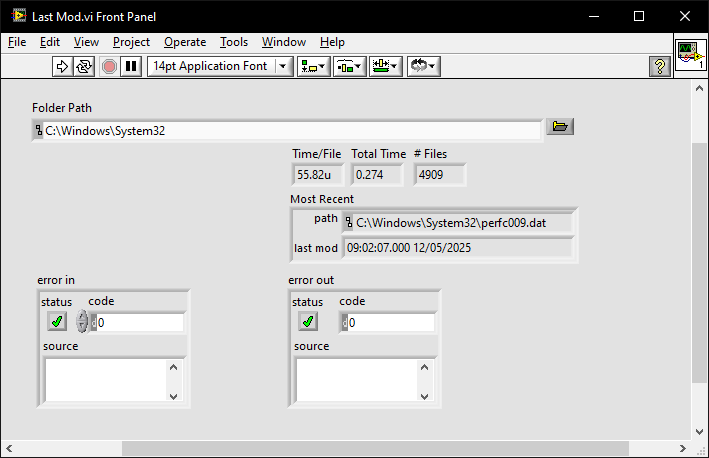
Find most recently created or modified image(file)
ShaunR replied to mooner's topic in LabVIEW General
Heathen My go. Last Mod.vi
-
We are on a hiding to nothing as we can't create objects. I abandoned those thoughts over a decade ago (maybe even 2 decades ago ). It is feasible with scripting but so slow and won't work in built applications. The half-way house is to use scripting to make the labview prototypes for typdefs and handlers then load dynamically as plugins but it's a lot of infrastructure just to propagate what are hopefully rare changes. I did play with that (hence my question to hooovahh) but in the end went for a string based solution to avoid it altogether. What happened to AQ's behemoth of a serializer? Did he ever get that working?
-
That's the easy bit. It's much easier getting stuff into other forms than it is reconstituting them because we can't create objects and primitives. This is why JSON libraries have very straightforward encoders that can take any type but you have all sorts of awkward VI's for getting them out into LabVIEW again. If you are going to use JSON strings you might as well not use LabVIEW types at all . Add the Network Stream endpoint to it and you're good to go. Getting it back out again is where you will find the problems unless, of course, the device uses strings too (SCPI)
-
Have you played with scripting event prototypes and handlers from JSON strings?
-
LabVIEW network streams are fine. I wouldn't worry about the transport too much. Network Streams have a nice way of integrating into API's. What I was looking at were network events where you don't have to synchronise prototypes throughout a system on different machines (changing an event prototype usually breaks an Event Structure). Everything for my events is a string so this is not a problem but it makes parsing tricky. This was one of the reasons I wanted "Named Events" (events can be named like queues can) but they botched the downstream polymorphism. I was wondering whether you had found an elegant way of serialising events (a bit like protocol buffers but without the compiler).
-
IC. so you have created a cloning mechanism of User Events - reconstruct pre-defined User Event primitives locally with the data sent over the stream?
-
Yes. It is the "send user event" that I'm having difficulty with. User events are always local and require a prototype so how do you serialise a user event to send it over a stream?
-
How does this work?
-
You can script with text files with #1. Just adding a feature to delay N ms gets you most of the way to a full scripting language (conditionals and for-loops are what's left but a harder proposition). However, for a more general solution I use services in #2 with queue's for inputs and events for outputs. There was a discussion ages ago at whether queues were needed at all since LabVIEW events have a hidden queue but you can't push to the front of them (STOP message ) and, at the time, you couldn't clear them so I opted for proper queues. So, architecturally, I use "many to one" for inputs and "one to many" for outputs.
-
OK. This is how I design systems like this. 1. TCP. Each subsystem has a TCP interface. This allows spinning up "instances" then connecting to them even across networks. You can rationalise the TCP API and I usually use a thin LabVIEW wrapper around SCPI (most of your devices will support SCPI). You can also use it to make non SCPI compliant devices into SCPI ones (your Environmental Chamber - EC - is probably one that doesn't support SCPI). If you do this right, you can even script entire tests from a text file just using SCPI commands. 2. Services. Each subsystem offers services. These are for when #1 isn't enough and we need state. A good example of this is your Environmental Chamber. It is likely you will have temperature profiles that control signals and measurements need to be synchronized with. While services may be devices (a DVM, for example), services can also be synchronization logic that sequences multiple devices. If you put that logic in your EC code, it will fix that code for that specific sequence so don't do that. Instead use services to glue other devices (like the DVM and EC) into synchronization processes. Along with #1, this will form the basis of recipe's that can incorporate complex state and sequencing. In this way you will compartmentalize your system into reusable modules. First thing you should do is make a "Logging" service. Then when your devices error they can report errors for your diagnostics. The second thing should be a service that "views" the log in real-time so you can see what's going on, when it's going on. (This is why we have logging levels). 3. Global State. If you have 1 & 2 this can be anything. It can be a text file with a list of SCPI commands (#1). It can be a service you wrote in #2, Test Stand, web page or a bash/batch script. This is where you use your recipe's to fulfill a test requirement. 4. You will need to think carefully about how the subsystems talk to each other. For example. Using SCPI a MEAS :VOLT:DC? command returns almost instantly (command-response pattern). However for the EC you may want to wait until a particular temperature has been reached before issuing MEAS :VOLT:DC?. The problem here is that SCPI is command-response but the behavior required is event driven. One could make the the TCP interface (#1) of the EC accept MEAS :TEMP? where the command doesn't return unless the target setpoint has been reached. However, this won't work reliably and requires internal state and checks for the edge cases though. So it may actually be better in #2. There are a number of ways to address these things using #1, #2 or #3 and that is why you are getting the big bucks. You will notice I haven't mentioned specific technologies here (apart for TCP). For #1 you shouldn't need anything other than reentrant VI's and VI Server. For #2 you can use your favourite foot-shooting method but notice that you are not limited to one type and can choose an architecture for the specific task (they don't all have to be QMH, for example). For #3 you don't even have to use LabVIEW.
-
You actually have 2 levels with LLB's (semanticly) and that's more than enough for me. I also don't agree with all the private stuff. Protected should be the minimal resolution so people can override if they want to but still be able to modify everything without hacking the base. This only really makes sense in non-LabVIEW languages though so protected might as well be private in LabVIEW. And don't get me started with all that guff on "Friends" But in terms of containers, external users can call what they like as far as I'm concerned but just know only the published API is supported. So making stuff private is a non-issue to me. If I'm feeing generous and want them to call stuff then I make it a Top Level vi in the LLB. Everything else is support stuff for the top level VI's so call it at your peril. I still maintain PPL's are just LLB's wearing straight-jackets and foot-shooting holsters.
-
*prerequisite. Packed libraries are another feature that doesn't really solve any problems that you couldn't do with LLB's. At best it is a whole new library type to solve a minor source code control problem.
-
There isn't anything really special about lvlibs. They are basically containers with a couple of bells and whistles. If you look at them with a text editor you will see it's basically a list of VI's in an XML format. The main reason I use them is that they can be protected with the NI 3rd Party Activation Toolkit. A secondary reason I use them is for organisation and partitioning. It would be frowned upon by many but I use lvlibs for the ability to add virtual directories and self populating directories for organisation and contain the actual VI's in llb's for ease of distribution. I don't see them as a poor-mans class, rather a llb with project-like features.
-
This is the modern 2020's equivalent of "works for me".
-
I find it interesting that spam really wasn't an issue until the forums were upgraded. I run old software on my website and I've noticed a reduction in spam attempts as time goes on and the scanners update to newer exploits. I was getting spam through the on-site contact form as they were bypassing the CAPTCHA. It's prevented with a simple .htaccess RewriteCond but when I recently upgraded the website OS I turned it off. It took a month for a scanner to find it and start spamming and it only sent every hour. A few years ago it took something like 30 minutes and they sent every 5 minutes. By far the most effective methods to stop spam are Checking for reverse DNS resolution. Checking against known blacklists (like spamhaus.org). Offering honeypot files or directories (spider traps). #2 tends to have a low false positive rate but [IMHO] even 1 false positive is unacceptable for mail - although might be acceptable for a forum. I also wrote a spam plugin for my CMS which basically did the above first 2 things and a couple of other things like checking against a list of common disposable email addresses, checking user agents and so on. The way those things work is they tend to ban the IP address for an amount of time but I didn't want to ban someone that was trying to send an message through the site maybe because an email had bounced ; so I turned it off.
-
If that's the case then is this just a one-time, project-wide, recompilation? Once relinked with the new namespaces then there shouldn't be any more relinking and recompiling required (except for those that have changed or have compiled code as part of the VI).
-
Wasn't separate compiled code meant to resolve this issue? Is it just that some of the VI's were created before this option and so still keep compiled code?