ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-

Updating to new version of LabVIEW
ShaunR replied to Bjarne Joergensen's topic in Development Environment (IDE)
Bearing in mind Antoine's comment with which I wholeheartedly agree with, I would suggest upgrading to 2020 now and plan for deliverables with SP1 or later as and when they arrive. You can have multiple versions installed side-by-side on a machine and you want time to find any upgrade issues with your current codebase and gradually migrate with fallback to your current version if things go wrong. Reasoning for 2020 is that that it supports HTTPS - which none of the previous versions do out-of-the-box and is essential nowadays. 2020 is, by now, a known entity in terms of issues and work-arounds whereas waiting for 2021 you will be at the cutting edge - where production systems never want to be unless it facilitates a show-stopping feature requirement. -
/usr/bin/ldd or /usr/sbin/ldd depending on the distro. But the fact that it isn't in your environment path maybe a clue to the problem.
-
If yo think it's a linking problem then ldd will give you the dependencies.
-
That's not very American. Where's the guns?
-
The DLL I used didn't have this feature exposed and I only got as far as identifying the board info before I lost access to the HackRF that I was using. However. From the hackrf library, it seems you call hackrf_init_sweep then hackrf_start_rx_sweep. I guess the problem you are having is that the results are returned in a callback which we cannot do in LabVIEW. So. There are two options. Implement your own sweep function in LabVIEW or write a dll wrapper in <insert favourite language here> that can create a callback and return the data in a form that LabVIEW can deal with. I have a project in another language that unifies hackRF and the dongle SDR's into a standard interface so it creates the callback for the HackRF but I haven't revisited it for a few years and it's status at the time was that it covered similar functionality between the devices-so no sweep function.
-
-
This is the problem that WinSxS solves, as you probably know. The various Linux packaging systems aren't much help here either. There is, of course, a binary version control under Linux that utilises symlinks-usually the latest version is pointed to though. That is where we end up trying to find if the version is on the machine at all and then creating special links to force an application to use a particular binary version with various symlink switches to define the depth of linking. It's hit-and-miss at best whether it works and you can end up with it seeming to work on the dev machine but not on the customers as the symlink tree of dependencies fails. That resolution needs to be handled much better before I re-instate support for the ECL under Linux again. And like Rolf says, that has to be done again in 6 (I argue weeks, not months) for the release of a new version in order for the application to continue working when there have been zero changes to the application code.
-
It never will be until they resolve their distribution issues which they simply do not even acknowledge. Even Linus Torvalds refuses to use other distro's because of that. What Windows did was to move common user space features into the kernel. The Linux community refuses to do that for ideological reasons. The net result is that application developers can't rely on many standard features out-of-the-box, from distro-to-distro, therefore fragmenting application developers across multiple distro's and effectively tieing them to specific distro's with certain addons. Those addons also have to be installed by the end-user who's level of expertise is assumed to be very high.
-
NI abandons future LabVIEW NXG development
ShaunR replied to Michael Aivaliotis's topic in Announcements
There's your problem, right there. AF. If you are going to use this type of architecture, I suggest using DrJPowels framework instead The key to multiple simultaneous actor debugging is hooking the messages between them; not necessarily the actors themselves. -
Which is the best platform to teach kids programming?
ShaunR replied to annetrose's topic in LabVIEW Community Edition
An often overlooked platform for kids is Squeak. (Adults could learn a thing or two as well ) -
I think there is a compromise here that would help with contending with Python, if it's not too late - make Linux repositories available for older LabVIEW versions. I remember vaguely that there was one for 8.6. So if there were, say, repositories of versions older than 5 years; it would be a route for people to get into LabVIEW and enable makers, students, and the terminally curious to code in LabVIEW without impacting the current sales. But be careful what you wish for. The probable solution to the demands for free stuff will ultimately end up as LabVIEW-as-a-service.
-
It is presented as G code...when loaded into LabVIEW. All that is being proposed is for the on-disk representation to be in a format that normal SCC can deal with rather than a proprietary binary format that prevents us from incremental differencing. Projects et. al. have already gone this route. The suggestion is to extend it to the VI's themselves. We know that VI's *can* be represented in forms such as XML from some of the under-the-hood tools we have seen. The current state of affairs in how SCC's deal with LabVIEW source is the equivalent of using SCC for C/C++ object code, and the NI graphical solution is far too manually intensive. As for the rest of Santa's list. Most of it is "gibs free stuff"
-
NI abandons future LabVIEW NXG development
ShaunR replied to Michael Aivaliotis's topic in Announcements
Getting there
-
NI abandons future LabVIEW NXG development
ShaunR replied to Michael Aivaliotis's topic in Announcements
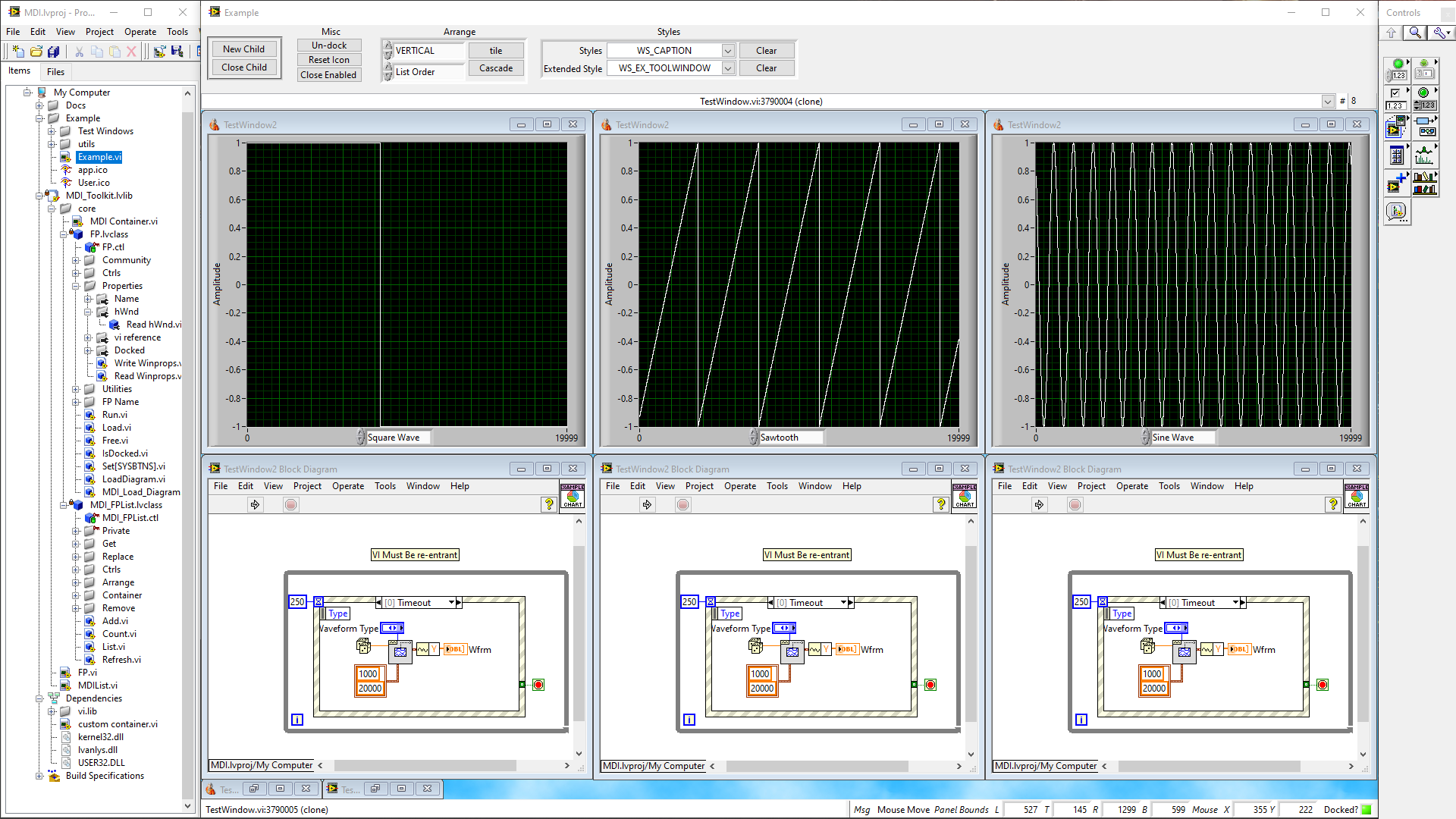
Agreed. I was just staring at the MDI toolkit. If I can get the diagram windows reference I can probably create a region where we can contain multiple VI FP's and their diagrams along with things like tile, minimise etc. Might have to create a hack by using the Subpanel's ability to show diagrams but maybe worth having a look at for giggles. -
NI abandons future LabVIEW NXG development
ShaunR replied to Michael Aivaliotis's topic in Announcements
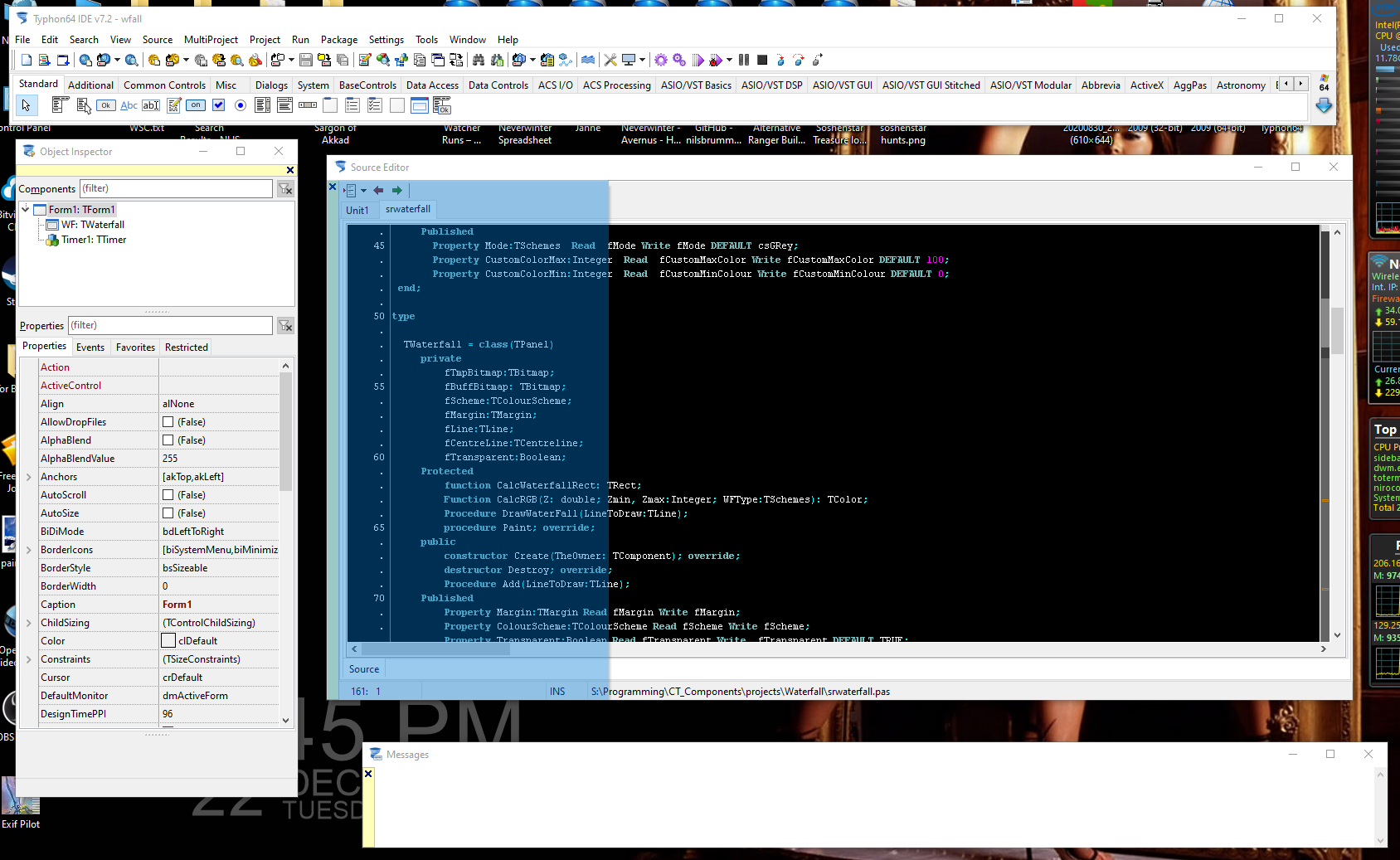
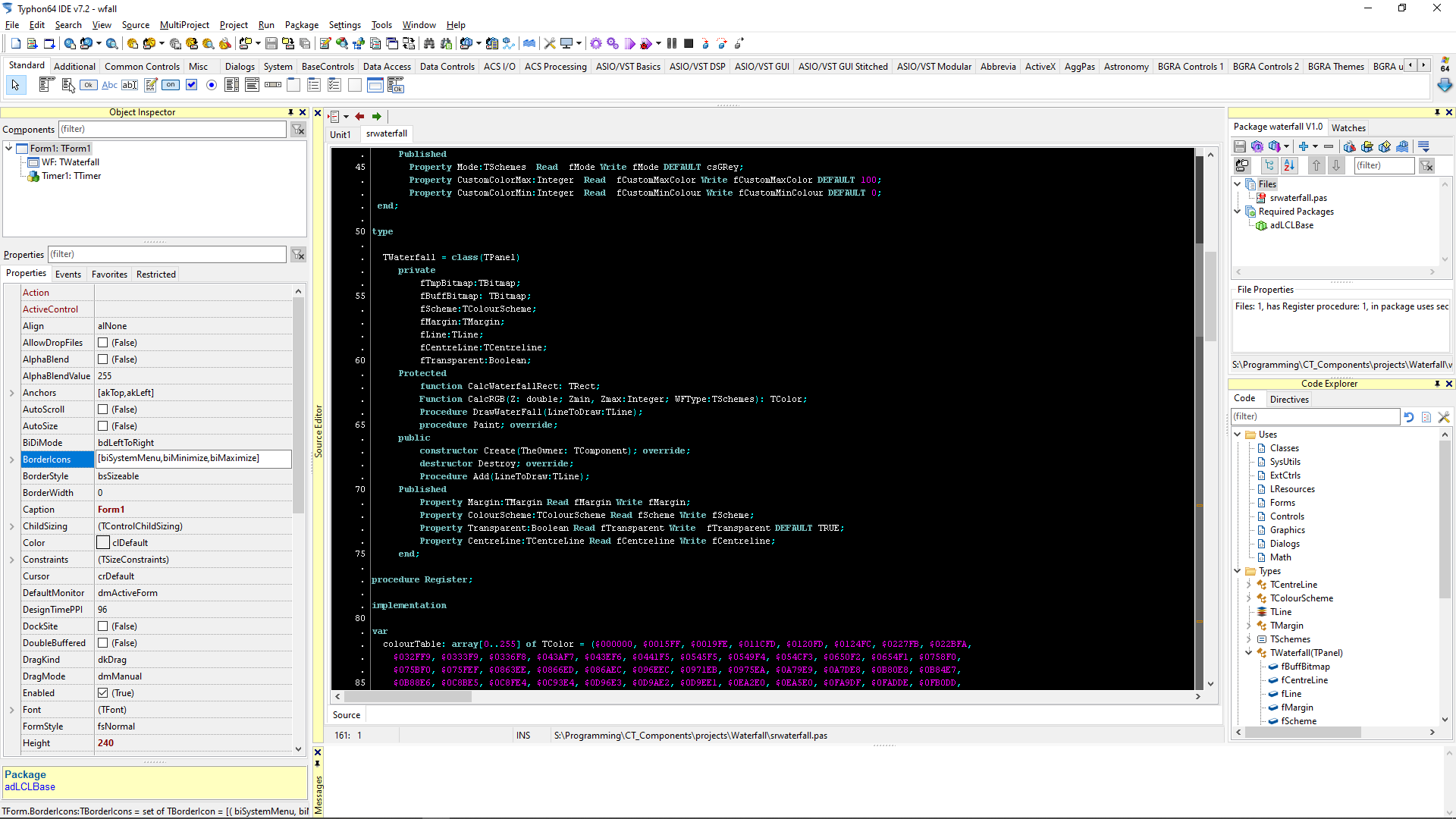
Interesting... I don't like the single VI view. I like to view multiple VI diagrams and panels when debugging and editing. I also don't like the menubar only reflecting the currently selected item ala Mac - it trips me up all the time. However. The toolbars are another matter. You can kind of do the above by docking palettes and Project Explorer to the desktop sides (which is what I do). What you can't do is dock to the top and bottom of the desktop or dock the context help or dock windows to each other. I really like the way Codetyphon/Lazarus works for toolbars etc. Each is a separate window (like LabVIEW toolbars) but you can dock and nest. So. Out of the box you have something like: You can grab the yellow bar below the title-bar and dock it to other windows (the blue shaded area in the source view shows you where it plans to put it, for example). You can do this with any window (there are a lot of them) to create split bars and even tabbed, split bars. Ultimately. You end up with (my preferred layout) which is: It's only a tabbed page view in the middle which is a pain switching back and forth between FP design and source but the way it handles the ability to make your own IDE layout is great.
-
Poll: Should the CLA Exam require applied knowledge of OOP?
ShaunR replied to Mike Le's topic in LabVIEW General
I was once told by an engineer (I think he might have been a Senior Engineer) that it was ok and even desirable to allow broken trunks in the Source Control. He read it in a book, apparently. Glad he wasn't on my project. -
Poll: Should the CLA Exam require applied knowledge of OOP?
ShaunR replied to Mike Le's topic in LabVIEW General
Actually. Yes. Elitist zealotry deserves mocking. Because it is not what is being tested in a CLA exam: How a CLA achieves that is not dependent on OOP. -
Poll: Should the CLA Exam require applied knowledge of OOP?
ShaunR replied to Mike Le's topic in LabVIEW General
I've never read such a load of clap-trap on this forum. -
NI abandons future LabVIEW NXG development
ShaunR replied to Michael Aivaliotis's topic in Announcements
You can kind of do that with VI Server, Wireshark and a lot of determination It's not very secure and not at all documented though. Now. If we could connect to VI server with wss and ... <thoughts for another time> -
Is a baked-in Actor Framework on the drawing board?
ShaunR replied to Bob W Edwards's topic in Object-Oriented Programming
Deal. I would have also have accepted Streams, .NET, Citadel and a few others -
Is a baked-in Actor Framework on the drawing board?
ShaunR replied to Bob W Edwards's topic in Object-Oriented Programming
If they removed classes I wouldn't be too upset Good trade-off. -
Is a baked-in Actor Framework on the drawing board?
ShaunR replied to Bob W Edwards's topic in Object-Oriented Programming
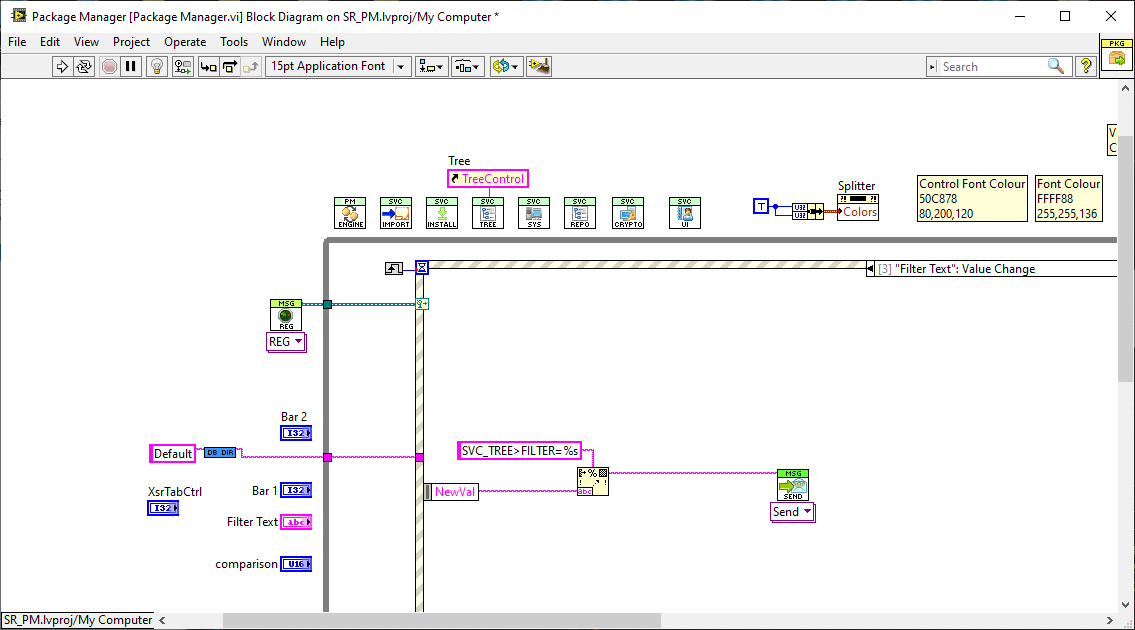
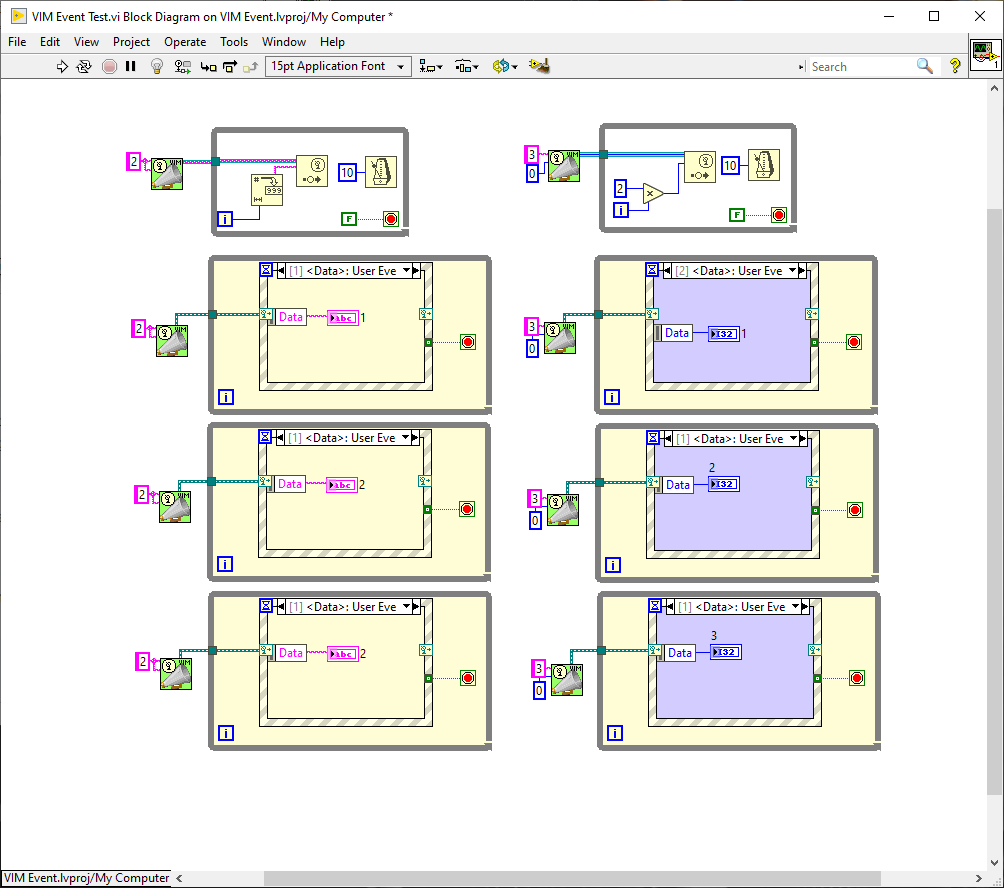
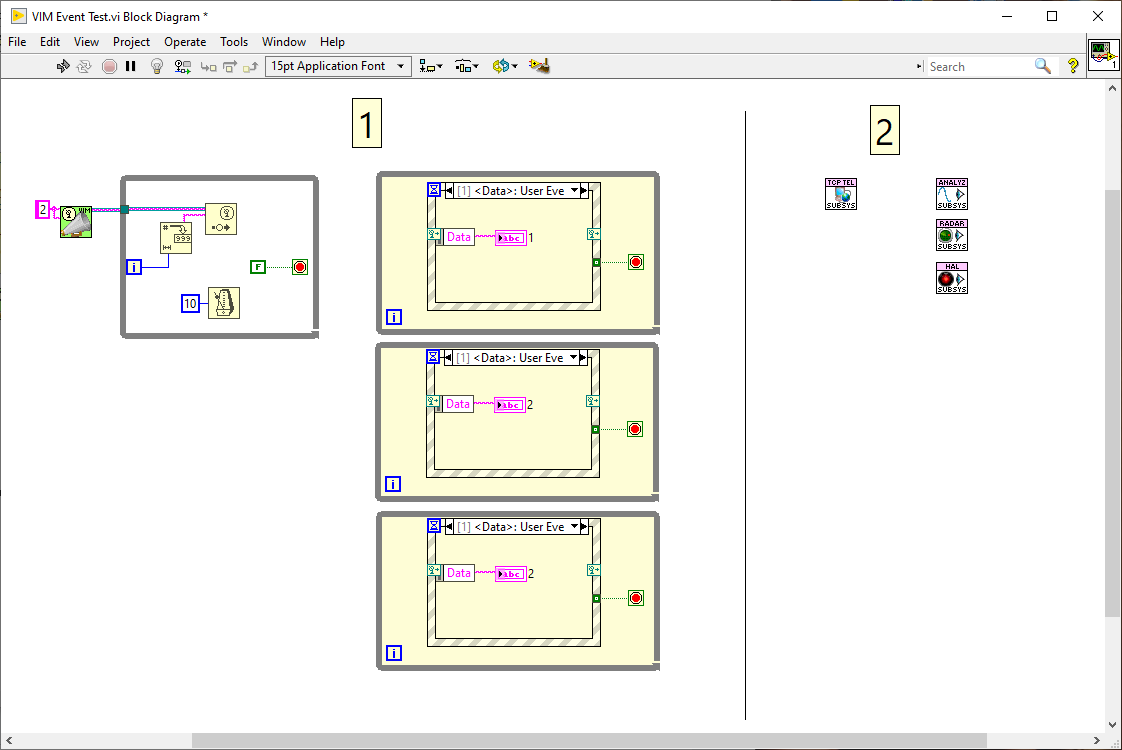
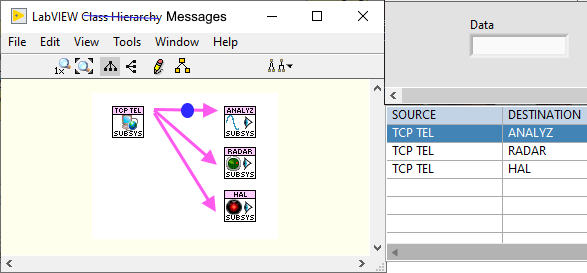
Well. I settled on string messages with a syntax similar to SCPI .The issue then becomes how to disassemble the strings and turn them back into the types. When I demo'd the above concept using "Named Events" (Anyone remember the HAL Demo?) I had to use a split-string VI with case statements in the Event structure to do this. That could be alleviated by LabVIEW's in-built cluster mechanics in the Event Structure but then we move away from strings to clusters. So whilst strings would flatten the interoperability, clusters would bring us back to the lack of interoperability that you describe. I've maintained for a long time that strings are the ultimate variant and they can be transmitted across networks and/or to other languages to boot. In this paradigm I chose string formats of the form SENDER>TARGET>OPERATION>PAYLOAD (e.g. "MAIN>SOUND>PLAY>FILE>operatio.wav"). The first two elements are the source and destination - more specifically the Sender's VI name and the intended Recipients VI Name. That could be hidden and removed with the proposed event implementation above since LabVIEW would have that knowledge and it is used used purely for filtering the messages (events are one-to-many). It also meant that I moved away from QSM's to EDSM's (Event-driven State Machines) and "Services" and "Listeners". Services provide application-wide functions and access to resources that were typically singletons such as Comms, logging, database access , Sounds etc while Listeners simply observed the messages and do their own thing, often utilising the Services. So I guess you could consider Services and Listeners as sub-classes of the generic "Actor" term. The result of that is you end up with standard Services with no static linking to the application-pluginable, if that's a word - and could be imported to other projects just by laying the icon in the main diagram or dynamically loaded (dependencies excepted, of course). Once loaded, the developer just had to send it messages to use and subscribe to messages to get info and feedback. They could also be tested and used in isolation which makes LabVIEW life so much easier. As an example. you can clearly see the Services (along the top) in the following application that I started a while back (and may pick up again with the news NXG is shelved). The Listeners are the pages in the Tab control.
-
Is a baked-in Actor Framework on the drawing board?
ShaunR replied to Bob W Edwards's topic in Object-Oriented Programming
Thinking a bit more about this. We already have an editor where we could add the messages rather than usurping the dynamic terminal. After all. It's really just pulling in and simplifying dynamic events so that no primitives are needed and adding a viewer for the message paths. The only outstanding question is what do we do about generating the events to remove the last primitive (Generate User Event)? The more I look at this, the easier it becomes to implement
-
Is a baked-in Actor Framework on the drawing board?
ShaunR replied to Bob W Edwards's topic in Object-Oriented Programming
It's a good idea but it's an awful implementation. You can smell that it's awful from the amount of infrastructure replication from diagram to diagram so eventually it all looks the same with minuscule differences. That's *not* reuse! Scripting isn't the answer here. A better approach would be similar to the "Named Events" that I once played with. Of course, I don't have the ability to draw wires between the producers and subscribers in there that Jeff can do, but the Event Structure becomes housing for your code populated with the appropriate events and data terminals dependent on your message-either in another loop on the diagram or in a completely separate VI (we'll call Actor ). So. With the above in mind. Say we didn't even want to have the VIM node (which is just really defining the message or, more practically, the user events and data terminals that appear in the Event Structure) and we could just pop-up on the Event Dynamic Registration terminal and define our message. That could then be available throughout all our code (we can argue about scope later). So Like Jeff, 1 is the "expanded" code and 2 is the iconised abstraction. Now. Of course. Jeff uses wires and we could use wires here too to represent the message paths between the loops and icons if we were NI devs. But if we are going to use another interface, lets just use it to view the message paths. Rather than straight-jacketing the developer to the alternate view and lot's of [slowly scripted] boiler plate code, we are viewing the actual programmed code and can debug the messages. (the blue dot is the probe and the probe content are on the right). All the complexity has been hidden and simplified-which is what we want. Now we have a system that is in the same spirit as the hierarchy and class windows and very little boiler plate code. Additionally, "actors" can be launched dynamically and we can still debug them. The LabVIEW developer only needs to lay down a loop with an event structure and pop-up on the Dynamic Registration terminal to create or subscribe to messages. When subscribing, the events and the data types are propagated in the structure just like normal user events. We could even use the Dynamic Registration on the right side to send messages back to the producer or other subscribers. If the latter were the case, then the producer in the examples shown, could simply be a value wired to the right-hand side Dynamic Terminal of an event case (in the timeout case with 10ms wired) instead of the Generate User Event shown.
-
NI abandons future LabVIEW NXG development
ShaunR replied to Michael Aivaliotis's topic in Announcements
Unicode, as I outlined earlier, is the only thing in that list that needs to be prioritised. Comparing 2 VI's in LabVIEW becomes moot if they switch to XML (as I also outlined). .NET can go hang - it's not cross platform - and we can already pass NuLL pointers, it's just not a LabVIEW type.